自然语言处理为啥要分词
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了自然语言处理为啥要分词相关的知识,希望对你有一定的参考价值。
当然需要。 既然是“文本挖掘”,自然语言处理最基本的功能点肯定都要做: 新词发现、分词、词性标注、分类、自动提取标签、实体自动发现和识别。 最基本的这些功能点做了之后,可以用统计方法完成简单文本挖掘应用,统计方法比如: TF/IDF、Map/Reduce、贝叶斯。 再深入一些,就需要: 聚类(层次聚类、SVM、VSM)、情感趋势分析。 再想提高: 语法分析、句式判断。 但一般做到NLP最基本功能点+统计方法即可搞定一般的互联中国应用。 本回答由电脑中国络分类达人 董辉推荐 参考技术A 1. 自然语言处理(NLP,Natural Language Processing)就是让计算机能够理解人类的语言。也就是说,要让计算机像人一样能够阅读文字,理解文字背后的含义。2. 而在人的阅读过程中,只有理解了词语的含义,才能把握整个句子的含义。以此类比,要让计算机懂得人类的文本,就必须要让计算机准确把握每一个词的含义。因而在自然语言处理中,分词技术是非常基础的模块。 参考技术B 这个不难理解,字词和句段,正在语言交互应用中能呈现的意思是不一样的,同样的词多一字少一字,效果都会不一样。那自然语言处理就会将句段进行分词,分词在系统里边进行模型匹配可以提取很多有用信息,包括词性,词意、是否包含情绪等,这个就能将一句话分析的比较透彻,无限接近最真实的意思上。
自然语言处理之jieba分词
英文分词可以使用空格,中文就不同了,一些分词的原理后面再来说,先说下python中常用的jieba这个工具。
首先要注意自己在做练习时不要使用jieba.Py命名文件,否则会出现
jieba has no attribute named cut …等这些,如果删除了自己创建的jieba.py还有错误是因为没有删除jieba.pyc文件。
(1)基本分词函数和用法
首先介绍下分词的三种模式:
精确模式:适合将句子最精确的分开,适合文本分析;
全模式:把句子中所有可以成词的词语都扫描出来,速度快,但是不能解决歧义;
搜索引擎模式:在精确模式的基础上,对长词再次进行切分,提高召回率,适用于搜索引擎分词;
jieba.cut 以及 jieba.cut_for_search 返回的结构都是一个可迭代的 generator,可以使用 for 循环来获得分词后得到的每一个词语
jieba.cut 方法接受三个输入参数:
- 需要分词的字符串
- cut_all 参数用来控制是否采用全模式
- HMM 参数用来控制是否使用 HMM 模型
jieba.cut_for_search 方法接受两个参数
- 需要分词的字符串
- 是否使用 HMM 模型。

1 import jieba 2 seg_list = jieba.cut("我爱学习自然语言处理", cut_all=True) 3 print("Full Mode: " + "/ ".join(seg_list)) # 全模式 4 5 seg_list = jieba.cut("我爱自然语言处理", cut_all=False) 6 print("Default Mode: " + "/ ".join(seg_list)) # 精确模式 7 8 seg_list = jieba.cut("他毕业于上海交通大学,在百度深度学习研究院进行研究") # 默认是精确模式 9 print(", ".join(seg_list)) 10 11 seg_list = jieba.cut_for_search("小明硕士毕业于中国科学院计算所,后在哈佛大学深造") # 搜索引擎模式 12 print(", ".join(seg_list))

jieba.lcut以及jieba.lcut_for_search直接返回 list

1 import jieba 2 result_lcut = jieba.lcut("小明硕士毕业于中国科学院计算所,后在哈佛大学深造") 3 result_lcut_for_search = jieba.lcut("小明硕士毕业于中国科学院计算所,后在哈佛大学深造",cut_all=True) 4 print (\'result_lcut:\',result_lcut) 5 print (\'result_lcut_for_search:\',result_lcut_for_search) 6 7 print (" ".join(result_lcut)) 8 print (" ".join(result_lcut_for_search))

添加用户自定义字典:
很多时候我们需要针对自己的场景进行分词,会有一些领域内的专有词汇。
- 1.可以用jieba.load_userdict(file_name)加载用户字典
- 2.少量的词汇可以自己用下面方法手动添加:
- 用 add_word(word, freq=None, tag=None) 和 del_word(word) 在程序中动态修改词典
- 用 suggest_freq(segment, tune=True) 可调节单个词语的词频,使其能(或不能)被分出来。
1 import jieba 2 result_cut=jieba.cut(\'如果放到旧字典中将出错。\', HMM=False) 3 print(\'/\'.join(result_cut)) 4 jieba.suggest_freq((\'中\', \'将\'), True) 5 result_cut=jieba.cut(\'如果放到旧字典中将出错。\', HMM=False) 6 print(\'/\'.join(result_cut))
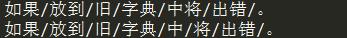
(2)关键词提取
基于TF-IDF的关键词抽取
import jieba.analyse
- jieba.analyse.extract_tags(sentence, topK=20, withWeight=False, allowPOS=())
- sentence 为待提取的文本
- topK 为返回几个 TF/IDF 权重最大的关键词,默认值为 20
- withWeight 为是否一并返回关键词权重值,默认值为 False
- allowPOS 仅包括指定词性的词,默认值为空,即不筛选
1 import jieba.analyse as analyse 2 import codecs 3 4 lines_NBA = codecs.open(\'NBA.txt\',encoding=\'utf-8\').read() 5 print (" ".join(analyse.extract_tags(lines_NBA, topK=20, withWeight=False, allowPOS=())))

另:
关键词提取所使用逆向文件频率(IDF)文本语料库可以切换成自定义语料库的路径:jieba.analyse.set_idf_path(file_name) # file_name为自定义语料库的路径
关键词提取所使用停止词(Stop Words)文本语料库可以切换成自定义语料库的路径:jieba.analyse.set_stop_words(file_name) # file_name为自定义语料库的路径
基于TextRank的关键词提取
1 import jieba.analyse as analyse 2 import codecs 3 4 lines_NBA = codecs.open(\'NBA.txt\',encoding=\'utf-8\').read() 5 print(" ".join(analyse.textrank(lines_NBA, topK=20, withWeight=False, allowPOS=(\'ns\', \'n\', \'vn\',\'v\'))))

(3)词性标注
jieba.posseg.POSTokenizer(tokenizer=None) 新建自定义分词器,tokenizer 参数可指定内部使用的 jieba.Tokenizer 分词器。
jieba.posseg.dt 为默认词性标注分词器。
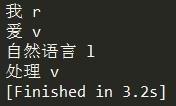
1 import jieba.posseg as pseg 2 words = pseg.cut("我爱自然语言处理") 3 for word, flag in words: 4 print(\'%s %s\' % (word, flag))
(4)并行分词
原理:将目标文本按行分隔后,把各行文本分配到多个 Python 进程并行分词,然后归并结果,从而获得分词速度的可观提升 基于 python 自带的 multiprocessing 模块,目前暂不支持 Windows
用法:
jieba.enable_parallel(4) # 开启并行分词模式,参数为并行进程数
jieba.disable_parallel() # 关闭并行分词模式实验结果:在 4 核 3.4GHz Linux 机器上,对金庸全集进行精确分词,获得了 1MB/s 的速度,是单进程版的 3.3 倍。
注意:并行分词仅支持默认分词器 jieba.dt 和 jieba.posseg.dt。
--------------------------------我是结束分割线 --------------------------------
注:本文参考寒小阳自然语言处理
以上是关于自然语言处理为啥要分词的主要内容,如果未能解决你的问题,请参考以下文章