入门解读 | 自然语言处理技术详细概览
Posted 贪心科技AI
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了入门解读 | 自然语言处理技术详细概览相关的知识,希望对你有一定的参考价值。
选自贪心学院NLP训练营
深度学习带来了AI狂潮,推动AI技术在近几年获得了长足的发展。但是,目前较为成熟的AI技术多集中在感知层,如语音和图像的识别。这些技术的发展为AI赢得了关注,开辟了早期市场。不过这些技术无法实现真正的“智能”。这之间的鸿沟就是对语言的理解。因此,未来10年,自然语言理解(NLP)技术将成为最重要,最受人关注的领域之一。不过,古话有云:“不积跬步,无以至千里。技术突破难以跨越式的出现,有赖于“巨人的肩膀”,因此本篇文章为大家介绍现在主流的NLP技术。
按照语言习惯,NLP技术从下到上可以分为3个层面:词法、句法、语义。
1. 词汇是语言的最小单元,因此词法技术可以被视为NLP技术的底层,也是其余NLP技术的基础。词法技术的核心任务是识别和区分文本中的单词,以及对词语进行一些预处理。因为词语具有确定的形式,所以通过规则匹配就可以做到比较准确的识别。但是现阶段的分词结果对语义的理解支持不够,如何更好的辅助语义理解,将是分词技术关注的重点。
2. 词汇组织成语句,句法技术顺理成章的成为NLP的第二个层面。句法是对语言进行深层次理解的基石,特别对于机器翻译非常重要。句法技术的主要任务是识别出句子所包含的句法成分以及这些成分之间的关系,一般以句法树来表示句法分析的结果。句法分析一直是NLP技术前进的巨大障碍,主要存在两个难点。一是歧义,自然语言存在大量的歧义现象。人类自身可以依靠大量的先验知识有效地消除各种歧义,而机器由于在知识表示和获取方面存在严重不足,很难像人类那样进行句法消歧。二是搜索空间,句法分析是一个极为复杂的任务,候选树个数随句子增多呈指数级增长,搜索空间巨大。因此,必须设计出合适的解码器,以确保能够在可以容忍的时间内搜索到模型定义最优解。
3. 不论是英语还是汉语,语言的目的都是为了表达含义。因此,语义理解是NLP技术的终极目标,可以说各种NLP技术都采用不同的方式为该目的服务。语义技术不同于上述两个层面,有明确的评判结果,只能通过一些具体场景来判断机器对语义的理解是否恰当。例如在文本关键词提取中,就可以通过对提取结果的分析比较,来衡量机器对浅层语义的理解能力。
接下来会依次介绍词法、句法中的关键技术,之后介绍目前较热的基于机器学习词向量与深度学习中的NLP技术。
1. 词法
词法技术的核心任务是识别和区分文本中的单词,其过程就是分词的过程,因此词法技术主要是各种分词技术。主要分为两大类,规则分词与统计分词。另外,不同语言的分词技术也不近相同,因为每个语言词法层面区别较大。比如英文中,通过空格即可区分词语。但是汉语中,词语是连在一起的,所以必须通过一定的技术才能做到区分,且区分精度较之英文稍差。以下主要介绍中文分词技术。
2. 规则分词
规则分词就是通过词典库+字符串匹配的方式对文本进行分词。因为词语具有确定的形式,所以这种分词方式能达到比较高的准确率。据SunM.S.和Benjamin K.T.(1995)的研究表明中文中90.0%左右的句子,正向最大匹配法和逆向最大匹配法完全重合且正确,只有大概9.0%的句子两种切分方法得到的结果不一样,但其中必有一个是正确的(歧义检测成功),只有不到1.0%的句子,使用正向最大匹配法和逆向最大匹配法的切分虽重合却是错的,或者正向最大匹配法和逆向最大匹配法切分不同但两个都不对(歧义检测失败)。基于上述结论,这种方法大约能正确切分90%的文本内容。同时,因为算法简单,这种方式具备较快的速度。
但是这种方式也具有明显的缺点,因为其基于词典切分,所以无法识别出词典中不存在的词语。除此以外,当存在多种切分方式的时候,无法判断应该使用哪一种切分方法,即歧义检测能力较弱。
实际应用中,常用该方法对文本进行初步分词,某些场景下,该方法甚至可以完全满足业务需要。
3. 统计分词(语言模型)
上文提到规则分词的两个缺陷:1)无法切分词典中的未登录词语,2)无法进行歧义检测。为了克服这两个缺点,需要引入统计学方法,也就是语言模型。
3.1 何为语言模型?
顾名思义,语言模型是对语言的建模,其核心目的是找到待评测数据中,最符合语言习惯的表达(概率最大)。该模型广泛用于NLP领域中的多项技术,包括信息检索、机器翻译、语音识别。用概率论的专业术语描述语言模型就是:为长度为m的字符串确定其概率分布,采用链式法则可以将公式化简为,如公式1所示。
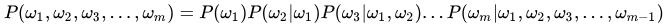
公式1: 链式法则计算长度为m的字符串的概率分布
3.2 n元模型
观察公式1易知,当文本过长时,公式右部从第三项起的每一项计算难度都很大。为解决该问题,有人提出n元模型(n-gram model)降低该计算难度。所谓n元模型就是在估算条件概率时,忽略距离大于等于n的上文词的影响,因此公式1的计算可简化为公式2。
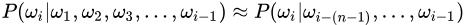
公式2:n元模型
当n=1时称为一元模型(unigram model),此时整个句子的概率可表示为:P(ω1,ω2,…,ωm)=P(ω1)P(ω2)…P(ωm)观察可知,在一元语言模型中,整个句子的概率等于各个词语概率的乘积。言下之意就是各个词之间都是相互独立的,这无疑是完全损失了句中的词序信息。所以一元模型的效果并不理想。
当n=2时称为二元模型(bigram model),公式2变为P(ωi|ω1,ω2,…,ωi-1)=P(ωi|ωi-1)。当n=3时称为三元模型(trigram model),公式3变为P(ωi|ω1,ω2,…,ωi-1)=P(ωi|ωi-2,ωi-1)。显然当n≥2时,该模型是可以保留一定的词序信息的,而且n越大,保留的词序信息越丰富,但计算成本也呈指数级增长。
一般使用频率计数的比例来计算n元条件概率,如公式4所示:
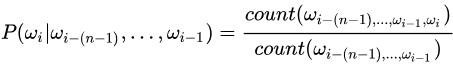
公式4: 使用频率计数的比例计算n元条件概率,count(ωi-(n-1),…,ωi-1)表示词语ωi-(n-1),…,ωi-1在语料库中出现的总次数。
n元模型的思想是把每个词看做是由词的最小单位的各个字组成的,如果相连的字在不同的文本中出现的次数越多,就证明这相连的字很可能就是一个词。因此我们就可以利用字与字相邻出现的频率来反应成词的可靠度,统计语料中相邻共现的各个字的组合的频度,当组合频度高于某一个临界值时,我们便可认为此字组可能会构成一个词语。
除了n元模型以外,比较著名的统计分词方法还有隐马尔可夫模型(HMM)和条件随机场(CRF)模型,它们是将分词作为字在字串中的序列标注任务来实现的。
通过这种方式,可以一定程度上弥补规则分词的缺陷,一是可以对词典中未出现的词进行划分,二是分词时考虑了上下文语境。但是这种方法也有明显的缺陷,即计算复杂度高,导致速度慢,并且需要很大的语料库作为训练数据。
3.3 混合分词
实际应用中,常使用规则分词+统计分词的方式,即混合分词的方式进行分词。这种组合既可以快速的对大部分文本进行分词,又可以对无法划分或存在歧义的文本进行速度慢但精细的划分。
3.4 分词无处不在
因为词语可以被视为语言表达的最小单元,因此,nlp各项技术中,几乎都会用到分词技术。并且,往往把分词作为数据预处理的一部分,为后续的任务服务。
4. 词性标注
词性是词汇基本的语法属性,通常也称为词类。词性标注是在给定句子中判定每个词的语法范畴,确定其词性并加以标注的过程。例如,表示人、地点、事物以及其他抽象概念的名称即为名词,表示动作或状态变化的词为动词,描述或修饰名词属性、状态的词为形容词。如给定一个句子:“这儿是个非常漂亮的公园”,对其的标注结果应如下:“这儿/代词 是/动词 个/量词 非常/副词 漂亮/形容词 的/结构助词 公园/名词”。
在中文中,一个词的词性很多时候都不是固定的,一般表现为同音同形的词在不同场景下,其表示的语法属性截然不同,这就为词性标注带来很大的困难;但是另外一方面,从整体上看,大多数词语,尤其是实词,一般只有一到两个词性,且其中一个词性的使用频次远远大于另一个,即使每次都将高频词性作为词性选择进行标注,也能实现80%以上的准确率。如此,若我们对常用词的词性能够进行很好地识别,那么就能够覆盖绝大多数场景,满足基本的准确度要求。
目前较为主流的方法是如同分词一样,将句子的词性标注作为一个序列标注问题来解决,那么分词中常用的手段,如隐含马尔可夫模型、条件随机场模型等皆可在词性标注任务中使用。除此以外,词性标注需要有一定的标注规范,如将词分为名词、形容词、动词,然后用“n”“adj”“v”等来进行表示。中文领域中尚无统一的标注标准,较为主流的主要为北大的词性标注集和宾州词性标注集两大类。
词性标注没有独立的应用场景,主要用于增加语义的精准表达,比如问答系统中,可以使用词性标注提高问题相似度判断的准确性。
5. 命名实体识别
与自动分词、词性标注一样,命名实体识别也是自然语言处理的一个基础任务,是信息抽取、信息检索、机器翻译、问答系统等多种自然语言处理技术必不可少的组成部分。其目的是识别语料中人名、地名、组织机构名等命名实体。由于这些命名实体数量不断增加,通常不可能在词典中穷尽列出,且其构成方法具有各自的规律性,因此,通常把对这些词的识别在词汇形态处理(如汉语切分)任务中独立处理,称为命名实体识别(Named Entities Recognition,NER)。NER研究的命名实体一般分为3大类(实体类、时间类和数字类)和7小类(人名、地名、组织机构名、时间、日期、货币和百分比)。由于数量、时间、日期、货币等实体识别通常可以采用模式匹配的方式获得较好的识别效果,相比之下人名、地名、机构名较复杂,因此近年来的研究主要以这几种实体为主。
命名实体识别当前并不是一个大热的研究课题,因为学术界部分认为这是一个已经解决了的问题,但是也有学者认为这个问题还没有得到很好地解决,原因主要有:命名实体识别只是在有限的文本类型(主要是新闻语料)和实体类别(主要是人名、地名)中取得了效果;与其他信息检索领域相比,实体命名评测语料较小,容易产生过拟合;命名实体识别更侧重高召回率,但在信息检索领域,高准确率更重要;通用的识别多种类型的命名实体的系统性很差。
同时,中文的命名实体识别与英文的相比,挑战更大,目前未解决的难题更多。命名实体识别效果的评判主要看实体的边界是否划分正确以及实体的类型是否标注正确。在英文中,命名实体一般具有较为明显的形式标志(如英文实体中的每个词的首字母要大写),因此其实体边界识别相对容易很多,主要重点是在对实体类型的确定。而在汉语中,相较于实体类别标注子任务,实体边界的识别更加困难。
中文命名实体识别主要有以下难点:
各类命名实体的数量众多。根据对日报1998年1月的语料库(共计2305896字)进行的统计,共有人名19965个,而这些人名大多属于未登录词。
各类命名实体的数量众多。根据对日报1998年1月的语料库(共计2305896字)进行的统计,共有人名19965个,而这些人名大多属于未登录词。
嵌套情况复杂。一个命名实体经常和一些词组合成一个嵌套的命名实体,人名中嵌套着地名,地名中也经常嵌套着人名。嵌套的现象在机构名中最为明显,机构名不仅嵌套了大量的地名,而且还嵌套了相当数量的机构名。互相嵌套的现象大大制约了复杂命名实体的识别,也注定了各类命名实体的识别并不是孤立的,而是互相交织在一起的。
长度不确定。与其他类型的命名实体相比,长度和边界难以确定使得机构名更难识别。中国人名一般二至四字,常用地名也多为二至四字。但是机构名长度变化范围极大,少到只有两个字的简称,多达几十字的全称。在实际语料中,由十个以上词构成的机构名占了相当一部分比例。
类似的,命名实体识别也有3种方法:基于规则、基于统计与混合方法。
基于规则的命名实体识别:规则加词典是早期命名实体识别中最行之有效的方式。其依赖手工规则的系统,结合命名实体库,对每条规则进行权重赋值,然后通过实体与规则的相符情况来进行类型判断。当提取的规则能够较好反映语言现象时,该方法能明显优于其他方法。但在大多数场景下,规则往往依赖于具体语言、领域和文本风格,其编制过程耗时且难以涵盖所有的语言现象,存在可移植性差、更新维护困难等问题。
基于统计的命名实体识别:与分词类似,目前主流的基于统计的命名实体识别方法有:隐马尔可夫模型、最大熵模型、条件随机场等。其主要思想是基于人工标注的语料,将命名实体识别任务作为序列标注问题来解决。基于统计的方法对语料库的依赖比较大,而可以用来建设和评估命名实体识别系统的大规模通用语料库又比较少,这是该方法的一大制约。
混合方法:自然语言处理并不完全是一个随机过程,单独使用基于统计的方法使状态搜索空间非常庞大,必须借助规则知识提前进行过滤修剪处理。目前几乎没有单纯使用统计模型而不使用规则知识的命名实体识别系统,在很多情况下是使用混合方法,结合规则和统计方法。
命名实体识别目前多用于知识图谱中,知识图谱主要是构建实体之间的关系,因此非常依赖于命名实体识别技术。
6. 词语预处理
词语预处理的核心思想是排除文本中对语义表达无帮助或造成干扰的成分,常见于英文文本。
Capitalization:英文中有大小写,但是在大部分情境下,大小写完全不影响文本语义的表。而且,大小写会影响单词比较的结果。因此经常把文本都转换为小写,方便后续处理。但是,在命名实体识别任务中,大小写要非常注意,特别是一些机构和人名,往往采用首字母大写的格式。
Stopword:这个概念也来源于英文,当一个单词在文本中是用于连接句子的不同成分,而不影响其表达的时候,就可以称之为stopword,例如"the"、"and"等单词。同样,中文也具备类似的停用词,例如“的”、“在”等单词或字。
stemming/Lemmazation:这两项技术只存在于英文中,因为英文中有时态和语态。同一个单词在不同时态或语态情况下,具有不同的形式,这不会改变单词的语义,但会影响单词的比较和统计。例如,“leaf”单词具备“leaves”、“leafs”等不同表达。
词性标注也可以被视为一项词语预处理技术。
7. 句法
在自然语言处理中,机器翻译是一个重要的课题,也是NLP应用的主要领域,而句法分析是机器翻译的核心数据结构。句法分析是自然语言处理的核心技术,是对语言进行深层次理解的基石。句法分析的主要任务是识别出句子所包含的句法成分以及这些成分之间的关系,一般以句法树来表示句法分析的结果。从20世纪50年代初机器翻译课题被提出时算起,自然语言处理研究已经有60余年的历史,句法分析一直是自然语言处理前进的巨大障碍。句法分析主要有以下两个难点:
歧义。自然语言区别于人工语言的一个重要特点就是它存在大量的歧义现象。人类自身可以依靠大量的先验知识有效地消除各种歧义,而机器由于在知识表示和获取方面存在严重不足,很难像人类那样进行句法消歧。
搜索空间。句法分析是一个极为复杂的任务,候选树个数随句子增多呈指数级增长,搜索空间巨大。因此,必须设计出合适的解码器,以确保能够在可以容忍的时间内搜索到模型定义最优解。
句法分析(Parsing)是从单词串得到句法结构的过程,而实现该过程的工具或程序被称为句法分析器(Parser)。句法分析的种类很多,这里我们根据其侧重目标将其分为完全句法分析和局部句法分析两种。两者的差别在于,完全句法分析以获取整个句子的句法结构为目的;而局部句法分析只关注于局部的一些成分,例如常用的依存句法分析就是一种局部分析方法。
句法分析中所用方法可以简单地分为基于规则的方法和基于统计的方法两大类。基于规则的方法在处理大规模真实文本时,会存在语法规则覆盖有限、系统可迁移差等缺陷。随着大规模标注树库的建立,基于统计学习模型的句法分析方法开始兴起,句法分析器的性能不断提高,最典型的就是风靡于20世纪70年代的PCFG(Probabilistic Context Free Grammar),它在句法分析领域得到了极大的应用,也是现在句法分析中常用的方法。统计句法分析模型本质是一套面向候选树的评价方法,其会给正确的句法树赋予一个较高的分值,而给不合理的句法树赋予一个较低的分值,这样就可以借用候选句法树的分值进行消歧。
8. 句法分析语料
统计学习方法多需要语料数据的支撑,统计句法分析也不例外。相较于分词或词性标注,句法分析的数据集要复杂很多,其是一种树形的标注结构,因此又称树库。图1所示是一个典型的句法树。
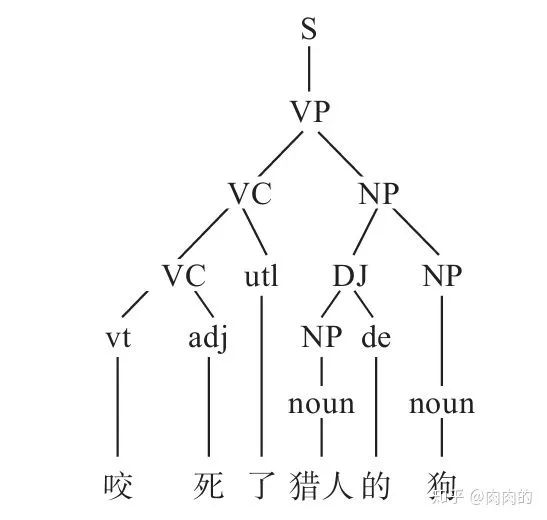
图1 句法树示例
目前使用最多的树库来自美国宾夕法尼亚大学加工的英文宾州树库(Penn TreeBank,PTB)。PTB的前身为ATIS(Air Travel Information System)和WSJ(Wall Street Journa)树库,具有较高的一致性和标注准确率。
中文树库建设较晚,比较著名的有中文宾州树库(Chinese TreeBank,CTB)、清华树库(Tsinghua Chinese TreeBank,TCT)、台湾中研院树库。其中CTB是宾夕法尼亚大学标注的汉语句法树库,也是目前绝大多数的中文句法分析研究的基准语料库。TCT是清华大学计算机系智能技术与系统国家重点实验室人员从汉语平衡语料库中提取出100万规模的汉字语料文本,经过自动句法分析和人工校对,形成的高质量的标注有完整句法结构的中文句法树语料库。Sinica TreeBank是中国台湾中研院词库小组从中研院平衡语料库中抽取句子,经过电脑自动分析成句法树,并加以人工修改、检验后所得的成果。
不同的树库有着不同的标记体系,使用时切忌使用一种树库的句法分析器,然后用其他树库的标记体系来解释。由于树库众多,这里不再讲述具体每一种树库的标记规范,感兴趣的读者可网上搜索自行查阅。图2所示为清华树库的部分标记集。
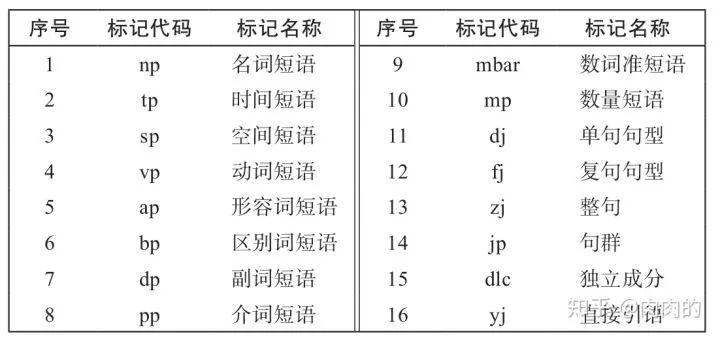
图2 清华树库的汉语成分标记集(部分)
9. 依存句法分析
依存句法分析是比较常用的句法依存技术,是通过分析语言单位内成分之前的依存关系解释其句法结构,主张句子中核心动词是支配其他成分的重心成分。而它本身却不受其他任何成分的支配,所有收支配成分都以某种关系从属于支配者。直观来讲,依存句法分析识别句子中的“主谓宾”、“定状补”这些语法成分,并分析各成分之间的关系。

图3 依存句法分析示例
我的理解是句法依存分析可用于语料库较少时,对句子进行拆分,帮助语义理解。
10. 文本向量化
文本表示是自然语言处理中的基础工作,文本表示的好坏直接影响到整个自然语言处理系统的性能。因此,研究者们投入了大量的人力物力来研究文本表示方法,以期提高自然语言处理系统的性能。在自然语言处理研究领域,文本向量化是文本表示的一种重要方式。顾名思义,文本向量化就是将文本表示成一系列能够表达文本语义的向量。无论是中文还是英文,词语都是表达文本处理的最基本单元。当前阶段,对文本向量化大部分的研究都是通过词向量化实现的。与此同时,也有相当一部分研究者将文章或者句子作为文本处理的基本单元,于是产生了doc2vec和str2vec技术。
11. 词袋模型
词袋(Bag Of Word)模型是最早的以词语为基本处理单元的文本向量化方法。下面举例说明该方法的原理。首先给出两个简单的文本如下:
John likes to watch movies,Mary likes too.
John also likes to watch football games.
基于上述两个文档中出现的单词,构建如下词典(dictionary):
{"John": 1, "likes": 2, "to": 3, "watch": 4, "movies": 5, "also": 6, "football": 7, "games": 8, "Mary": 9, "too": 10, }
上面词典中包含10个单词,每个单词有唯一的索引,那么每个文本我们可以使用一个10维的向量来表示。如下所示:
[1, 2, 1, 1, 1, 0, 0, 0, 1, 1]
[1, 1,1, 1, 0, 1, 1, 1, 0, 0]
该向量与原来文本中单词出现的顺序没有关系,而是词典中每个单词在文本中出现的频率。该方法虽然简单易行,但是存在如下三方面的问题:
维度灾难。很显然,如果上述例子词典中包含10000个单词,那么每个文本需要用10000维的向量表示,也就是说除了文本中出现的词语位置不为0,其余9000多的位置均为0,如此高维度的向量会严重影响计算速度。
无法保留词序信息。
存在语义鸿沟的问题。
12. 词向量
近年来,随着互联网技术的发展,互联网上的数据急剧增加。大量无标注的数据产生,使得研究者将注意力转移到利用无标注数据挖掘有价值的信息上来。词向量(word2vec)技术就是为了利用神经网络从大量无标注的文本中提取有用信息而产生的。
一般来说词语是表达语义的基本单元。因为词袋模型只是将词语符号化,所以词袋模型是不包含任何语义信息的。如何使“词表示”包含语义信息是该领域研究者面临的问题。分布假说(distributional hypothesis)的提出为解决上述问题提供了理论基础。该假说的核心思想是:上下文相似的词,其语义也相似。随后有学者整理了利用上下文分布表示词义的方法,这类方法就是有名的词空间模型(word space model)。随着各类硬件设备计算能力的提升和相关算法的发展,神经网络模型逐渐在各个领域中崭露头角,可以灵活地对上下文进行建模是神经网络构造词表示的最大优点。下文将介绍神经网络构建词向量的方法。
通过语言模型构建上下文与目标词之间的关系是一种常见的方法。神经网络词向量模型就是根据上下文与目标词之间的关系进行建模。在初期,词向量只是训练神经网络语言模型过程中产生的副产品,而后神经网络语言模型对后期词向量的发展方向有着决定性的作用。
13. CBOW模型和Skip-gram模型
CBOW模型和Skip-gram模型是现在比较成熟和常用的词向量模型。
CBOW模型如图4所示,由图易知,该模型使用一段文本的中间词作为目标词;同时,CBOW模型去掉了隐藏层,这会大幅提升运算速率。并且因为其去除了隐藏层,所以其输入层就是语义上下文的表示。
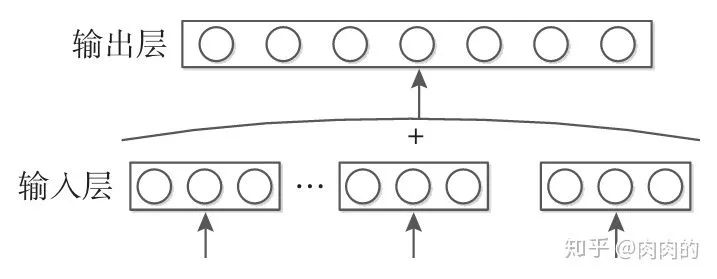
图4 CBOW模型结构图
CBOW对目标词的条件概率计算如图5所示:
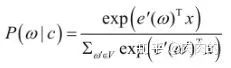
图5 CBOW对目标词的条件概率计算公式
CBOW的目标函数为∑(ω,c)∈DlogP(ω,c)。
与CBOW模型对应的,还有Skip-gram模型。这两个模型实际上是word2vec两种不同思想的实现:CBOW的目标是根据上下文来预测当前词语的概率,且上下文所有的词对当前词出现概率的影响的权重是一样的,因此叫continuous bag-of-words模型。如在袋子中取词,取出数量足够的词就可以了,取出的先后顺序则是无关紧要的。Skip-gram刚好相反,其是根据当前词语来预测上下文概率的。在实际使用中,算法本身并无高下之分,可根据最后呈现的效果来进行算法选择。
Skip-gram模型的结构如图6所示,Skip-gram模型同样没有隐藏层。但与CBOW模型输入上下文词的平均词向量不同,Skip-gram模型是从目标词的上下文中选择一个词,将其词向量组成上下文的表示。
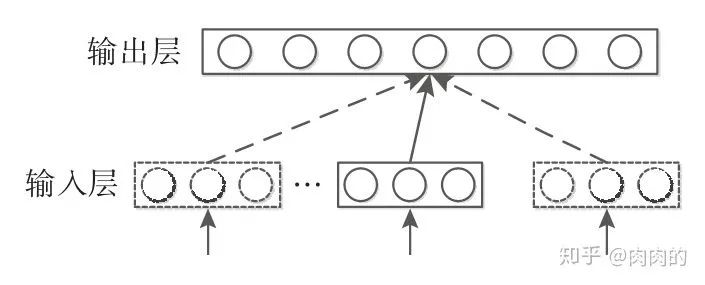
图6 Skip-gram模型结构图
对整个语料而言,Skip-gram模型的目标函数为图7所示:
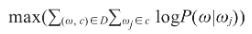
图7 Skip-gram模型目标函数
14. NLP中的深度学习
深度学习在NLP的应用多是循环神经网络(Recurrent Neural Networks,RNN),它能够通过在原有神经网络基础上增加记忆单元,处理任意长度的序列(理论上),在架构上比一般神经网络更加能够处理序列相关的问题,因此,这也是为了解决这类问题而设计的一种网络结构。
RNN背后的思想是利用顺序信息。在传统的神经网络中,我们假设所有的输入(包括输出)之间是相互独立的。对于很多任务来说,这是一个非常糟糕的假设。如果你想预测一个序列中的下一个词,你最好能知道哪些词在它前面。RNN之所以是循环的,是因为它针对系列中的每一个元素都执行相同的操作,每一个操作都依赖于之前的计算结果。换一种方式思考,可以认为RNN记忆了当前为止已经计算过的信息。理论上,RNN可以利用任意长的序列信息,但实际中只能回顾之前的几步。例如,想象你要把一部电影里面每个时间点正在发生的事情进行分类:传统神经网络并不知道怎样才能把关于之前事件的推理运用到之后的事件中去;而RNN网络可以解决这个问题,它带有循环的网络,具有保持信息的作用。
15. LSTM
长短时记忆网络(Long Short Term Memory network,LSTM)是一种特殊的RNN,它能够学习长时间依赖。它们由Hochreiter&Schmidhuber(1997)提出,后来由很多人加以改进和推广。它们在大量的问题上都取得了巨大成功,现在已经被广泛应用。
LSTM是专门设计用来避免长期依赖问题的。记忆长期信息是LSTM的默认行为,而不是它们努力学习的东西!
所有的循环神经网络都具有链式的重复模块神经网络。在标准的RNN中,这种重复模块具有非常简单的结构,比如一个层,如图8所示。
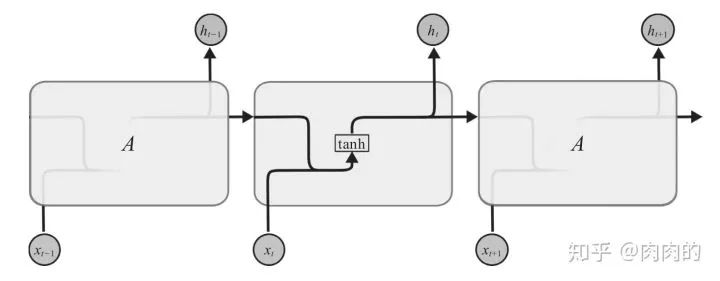
图8 tanh层
LSTM同样具有链式结构,但是其重复模块却有着不同的结构。不同于单独的神经网络层,它具有4个以特殊方式相互影响的神经网络层,如图9所示。
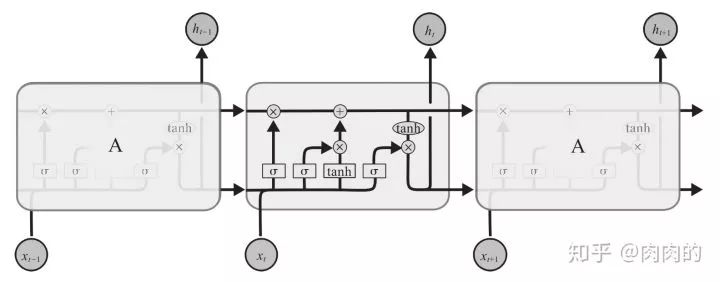
图9 LSTMs结构图
LSTM的关键在于单元状态,在图10中以水平线表示。
单元状态就像一个传送带。它顺着整个链条从头到尾运行,中间只有少许线性的交互。信息很容易顺着它流动而保持不变。
图10 LSTM组成部件
LSTM通过称为门(gate)的结构来对单元状态增加或者删除信息。
门是选择性让信息通过的方式。它们的输出有一个Sigmoid层和逐点乘积操作,如图11所示。
图11 门结构
16. Seq2Seq模型
对于一些NLP任务,比如聊天机器人、机器翻译、自动文摘等,传统的方法都是从候选集中选出答案,这对候选集的完善程度要求很高。随着近年来深度学习的发展,国内外学者将深度学习技术应用于NLG(Nature Language Generation,自然语言生成)和NLU(Nature Language Understanding,自然语言理解),并取得了一些成果。Encoder-Decoder是近两年来在NLG和NLU方面应用较多的方法。然而,由于语言本身的复杂性,目前还没有一种模型能真正解决NLG和NLU问题。
总结
本文粗略的介绍了NLP中的常见技术,只是起到抛砖引玉的作用,有兴趣的读者,可以阅读相关资料。因为本文创作时间有限,很多地方处理的不够细腻,希望读者理解。
参考文献
1. 贪心学院,www.greedyai.com
2. Pre-Processing in Natural Language Machine Learning: towardsdatascience.com/
3.《Python自然语言处理:核心技术与算法》
4. 依存分析:中文依存句法分析简介 - lpty的博客 - CSDN博客
5. 依存句法分析与语义依存分析的区别 - ZH奶酪 - 博客园
知乎原文链接 :
https://zhuanlan.zhihu.com/p/53564006
往期精彩文章:
1. (来自NLP训练营)
2. (来自NLP训练营)
3.
4.
5.
6.
7.
《自然语言处理训练营》相关信息,请点击下面原文链接,或者添加 "greedytech002" 来咨询。
以上是关于入门解读 | 自然语言处理技术详细概览的主要内容,如果未能解决你的问题,请参考以下文章
[新星计划]一文快速了解ClickHouse 战斗民族的开源搜索引擎(超详细解读+快速入门)