俞士汶朱学锋:面向自然语言处理的机器词典的研制
Posted 汉语堂
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了俞士汶朱学锋:面向自然语言处理的机器词典的研制相关的知识,希望对你有一定的参考价值。
书 议 文 思
面向自然语言处理的机器词典的研制∗
俞士汶 朱学锋
摘 要 北京大学计算语言学研究所积30余年之努力,研制了一部面向自然语言处理的机器词典,即《现代汉语语法信息词典》(以下简称GKB)。基于GKB,又衍生了一系列成果,进而集成为综合型语言知识库。文章扼要介绍GKB 及相关成果,并总结从事大型语言工程的实践经验,期望这些经验不仅对语言工程的实践者,而且对探索学科交叉融合的学者都有参考价值。
关键词 自然语言处理 语言工程 现代汉语语法信息词典 综合型语言知识库 交叉学科
收到《辞书研究》编辑部的约稿函,要求为改版后的2019年第2期撰稿,既感到荣幸,又感到惶恐。我们认为《辞书研究》是纸质型辞书的园地,主要关注传统辞书的理论、方法等创新性成果,我们是外行,恐难胜任。不过,又觉得应当承担这个任务,因为30多年来,研制面向自然语言处理的机器词典,需要的语言知识主要来源于辞书。撰写拙文,除了表达饮水不忘掘井人的感谢之情外,我们也期望利用这个机会,对语言工程的实践经验做一个总结,以具体案例阐述自然语言处理技术为什么需要语言知识,需要什么样的语言知识及如何将语言学家的及辞书中的语言知识转换成计算机能够运用的形式。
自然语言处理的任务是实现计算机对人类语言文本的自动分析与生成,分析相当于“读”,生成相当于“写”。数字计算机在非数值领域的最早应用便是发端于70年前的机器翻译;而自然语言理解——自然语言处理的最高境界,仍是当前人工智能研究努力攻克的难关。智能机器人最重要的能力之一就是理解和运用人类的语言。2017年国务院发布的《新一代人工智能发展规划》明确指出突破自然语言理解的重要性。自然语言处理是发展中的技术,经历了先以规则方法为主,继之以统计方法为主的发展阶段(俞士汶 2003;宗成庆 2013),当前基于神经网络的深度学习已成为前沿(约阿夫·戈尔德贝格 2018)。不同类型的方法的结合可能为自然语言处理提供最好的效果。实际系统常常兼收并蓄,博采众长。
自然语言处理运用计算机技术,划到理工科,其处理对象是人类语言,也是文科中的语言学的研究对象。语言学中也有一个分支,即计算语言学。计算语言学和自然语言处理都是文理结合的交叉学科,其对象、目标、原理和方法大致相同。如果要加以区分,可以认为自然语言处理侧重于应用研究,以构造实用系统为目标;计算语言学则侧重于理论研究,为自然语言处理系统提供语言模型、实现算法和工程方案。
关于语言模型,可以这样理解: 因为人类语言过于复杂,需要根据研究的目标,对其进行简化、变换,使其形式化,得到数学模型;计算语言学则进一步将数学模型改造为可用程序在计算机上实现的形式。例如,要计算机协助人判断两个文本是否相似,就要将文本模型化。如例(1)、例(2):

从以上实例的处理过程可以看出语言学知识对提高自然语言处理智能水平的重要性。在语言学知识中,词汇知识是最基本的。人学习语言要经常使用辞书类的工具书(纸质版或电子版)。人能够方便有效地利用辞书,因为人在阅读时不自觉地做了一件事,把按句连写的汉字串切分成了词语串,因而很容易挑出自己不懂的词语。对于大多数的应用场合,自然语言处理的第一步也是词语切分。可是,机器要完成这一步就不太容易。自然语言具有歧义性、模糊性及不规范性等特点,人在理解和运用自然语言时,对这些特点并不敏感,可是机器就不一样了。自然语言处理,包括词语切分这一步,必须跨越的第一个障碍便是自然语言的歧义性。例如,孤立的汉字串“白天鹅”可以切分成“白天 鹅”,也可以切分为“白 天鹅”,这就是歧义。但在例(7)、例(8)中:
(7) 白天鹅可以看家。 (8) 白天鹅飞过蓝天。
只能是其中的一种,在例(7)中是: “白天 鹅 可以 看家”。而在例(8)中,则是: “白天鹅 飞 过 蓝天”。即在具体的语境中,人是可以消解“白天鹅”的切分歧义的。如何实现呢? 需要给计算机配备一个知识库,以某种形式存储相关的语言知识和常识。
首先要有一个词表,包含“白、白天、鹅、飞、过、看家、可以、蓝天、天鹅”这些词语,基于词表对例(7)进行自动切分,可以得到“白 天鹅 可以 看家”或“白天 鹅 可以 看家”两个结果,但不会把“鹅可”“以看”等汉字串看作词,词表就是最简单的语言知识库。若知识库还包含“天鹅是飞禽,不会看家”“鹅是不会飞的家禽,能看家”“天鹅会飞”等常识,歧义便可消解,从两个结果中选择出一个正确的。
任何一个自然语言处理系统都有一个适配的语言知识库,语言知识库的规模和质量在很大程度上决定了自然语言处理系统的成败。这些语言知识附着在不同的语言单位上,如语素、词、短语、句子和篇章,涉及语言的形态、语音、词法、句法、语义乃至语用等不同层次。
20世纪80年代中期,我们从应用软件起步开始自然语言处理研究。当时研制了以词为基础、以语句为变换单位的中文输入软件(俞士汶1988)和基于测试集与测试点的机器翻译译文质量自动评估软件(俞士汶,姜新,朱学锋 1992;Yu Shiwen 1993)。这两款软件都配备了与程序分离的词典和语法规则库。研究实践揭示了语言知识库在自然语言处理系统中的重要性,我们便把研究重心转向语言知识库建设,研制了GKB。(俞士汶,朱学锋,王惠等 2003)关于这部机器词典,《20世纪我国重大工程技术成就》(常平 2002)一书中曾有介绍:“《现代汉语语法信息词典》是一部面向语言信息处理的大型电子词典。它按照语法功能和意义相结合的准则收录了7.3万余词语。依照语法功能分布的原则,建立了词类体系,完成了这7.3万余词语的归类。并在此基础上,分类描述每个词语的各种语法属性。”让我们感到荣幸的是,《辞书研究》也曾刊登过一篇评介GKB的文章(李晋霞,刘云 2004)。
GKB的研制始于1986年,至今已有30余年。最新版的GKB收录词语已超过8万。GKB采用数据库文件(二维表)格式描述词语的语法知识。文件的一个记录(行)描述一个词语,词语的各种属性信息则由文件的字段(列)刻画。GKB 针对词的每个类别建立一个文件,计26个。另建一个总文件,描述全部词语的与类别无关的共同属性。表1是GKB的总文件示例。GKB对每个词形首先区分词类,如“地道”分属形容词a和名词n,读音分别是di4dɑo5和di4dɑo4(1,2,3,4,5分别代表汉字的5个声调: 阴平、阳平、上声、去声、轻声)。“锁”“自动”虽只有一个读音,也分属不同词类,“锁”分属名词n和动词v,“自动”分属区别词b和副词d。属于同一词类的同一词形用“同形”字段区分不同词语或不同义项。动词v“扒”有两个读音,“同形”字段以A,B区分;名词“仪表”虽只有一个读音,但意义不同,也区分为两个词语,“同形”字段分别填以A,B。动词“支持”有两个义项,“同形”字段用1,2区分。
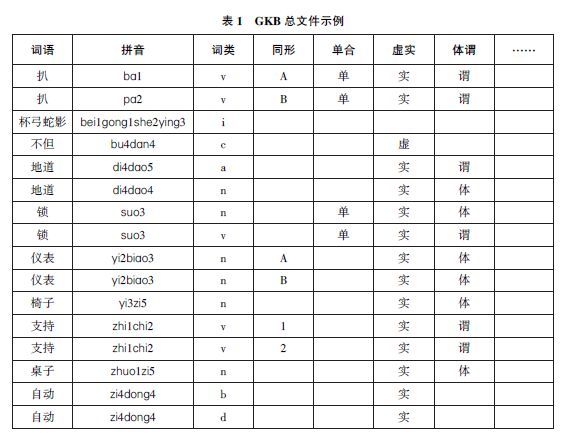
总文件中的“单合”字段表示该词语是单纯词还是合成词,“扒”“锁”是单纯词,其他则不是。“虚实”表示该词语是实词还是虚词,表1中的词语基本上是实词,只有连词c“不但”是虚词,而“杯弓蛇影”是成语i,既不是实词,也不是虚词,本字段就空着。“体谓”则指明实词中的体词和谓词。不同词类文件设立不同数量和名称的属性字段,反映各个词类的语法特点。表2是名词文件的示例。
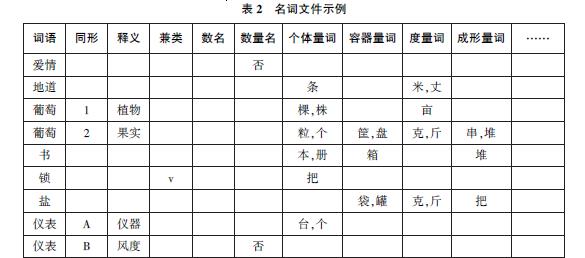
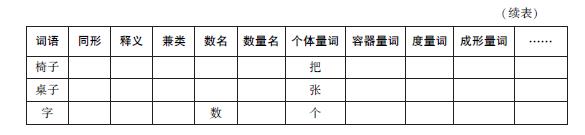
对于动词,还有必要更细致地描述某些字段所指示的语法属性,又分别建立了5个分文件。例如,动词库的“体谓准”字段的值若是“体”,表示该动词可以带体词性宾语,便再建一个体词性宾语动词分文件,进一步区分宾语的类型等特征,如“受事”“与事”“施事”及其格标。代词文件下也建了两个分文件。GKB共有34个文件。
1996年《中文信息学报》全文发表GKB的规格说明书,随即GKB 有了第一批用户。在GKB研制取得阶段性成果的同时,在中文信息处理技术发展需求的推动下,北京大学计算语言学研究所适时地启动了另一项更大规模的语言工程,即“综合型语言知识库”(CLKB)。(朱学锋,俞士汶 1996;俞士汶,穗志方,朱学锋 2011)CLKB为支持中文信息处理的原创性科学研究和应用技术开发做出了贡献,于2011年获国家科学技术进步奖二等奖。第一完成人俞士汶于同年获中国中文信息学会成立30年来首次颁发的终身成就奖。CLKB在2013年再次获北京大学颁发的产学研结合特别贡献奖。自1996年起直至2018年,包括GKB在内的CLKB的各项成果连续23年对外签约进行技术转让,从未间断。在信息技术领域,一项研究成果有如此长的生命期,是相当罕见的。CLKB包括6个语言知识库、10项规范与标准、4个核心工具软件和4个应用系统,它们相互支撑,形成一个紧密联系的有机整体。GKB是CLKB这座大厦的第一块基石。CLKB中的一些成果,如汉语短语结构规则库(俞士汶 2003)、现代汉语多级加工语料库STC(俞士汶,段慧明,朱学锋等 2002;俞士汶,段慧明,朱学锋等 2003) ( 以下简称“STC”)、汉语文本的词语切分与词性标注软件、汉语文本注音软件及未纳入CLKB的现代汉语语义词典(王惠,詹卫东,俞士汶 2003)等成果都是直接基于GKB发展起来的,是GKB的衍生成果。这里只介绍STC。
自然语言处理系统中的语言知识库可区分为两种类型。CLKB中的GKB是词典型的,把词语的各种知识显性地、结构化地罗列出来,但不反映词语在真实文本中的具体用法。语料库是另一种类型。语料库的基本构成是句子,句子无结构,只是一串字符,但其中每个词语的词类、意义、用法都是确定的,包含丰富的语言知识,不过,这些知识都是隐性的,进行语料加工与标注的目的就是使这些隐性知识显性化,以便于机器学习。(邱立坤,金澎,王萌 2017)无论统计机器学习还是当前成为研究热点的深度机器学习,针对求解结果标注好的语料都是必要的训练语料。词语切分、词性标注、命名实体识别、词义标注是自然语言处理的基本任务,也是更复杂的自然语言处理系统的组成部分。CLKB中的多级加工语料库就是为推动自然语言处理技术的发展而研制的,其中基本标注(包括词语切分、词性标注、命名实体标注、多音词注音)的语料有5200万字,同形(义项)标注的语料有2800万字。下例展示了语料逐级加工的结果。
S代表句子的编号(指语料库中的位置)。S⁃1是原始句子的汉字串。S⁃2是对S⁃1基本加工的结果: 汉字串切分成词语串,词汇知识显性化了: “大力”“支持”“楼兰”“的”“葡萄”等是词,这些词在GKB中都有,而“力支”“持楼”“兰的”等就不是词。并且标注了每个词的词类: d⁃副词,v⁃动词, vn⁃名动词, n⁃名词,u⁃助词,a⁃形容词,词类代码与GKB的一致。还标注了专有名词,ns⁃地名。S⁃3对S⁃2进一步标注“同形”信息。GKB中“葡萄”的“同形”区分为“1”和“2”。“葡萄/ n!2”表示这句中的“葡萄”是果实,而不是植物。
语料库加工越深入,显性化的知识就越多,也就能为机器学习提供包含更多的语言知识的训练语料。
集成GKB和STC,便可以进行词语的计量研究。GKB是一个二维表。用编程技术将文本文件STC也改造为二维表并不困难(这个数据库文件还包含词语在语料库中的位置信息,即句子及句中词序的编号)。两个数据库文件都有“词语”“词类”“同形”字段,利用“链接”操作便可以将GKB和STC集成为一个更庞大的数据库文件。二维表是一个平面。这相当于两个平面借助共同的轴将“词语”+“词类”+“同形”装配到了一起。有了这样的集成数据库,便可以计算词频、带词性的词频、义项频率乃至词的各种属性的频率等各种统计量。(俞士汶,朱学锋 2014;俞士汶,段慧明,朱学锋 2006)有了这些数据的支持,便可以提出常用词表的构造算法,可实现常用词表规模的动态调整,以满足对语料库的不同覆盖率的要求。(俞士汶,朱学锋 2014;俞士汶,朱学锋 2015)
(一) 语言知识库建设要适应学科与技术的发展
开发自然语言处理应用软件的实践让我们认识到语言知识对自然语言处理的重要性。从自然语言处理的角度观察,汉语有以下特点: (1)词缺乏形态变化,时态、语态和语气的表示都缺乏形式标记;(2)句子、短语、词、语素等语言单位的界限不清,句子与短语、短语与复合词都有基本相同的句法结构;(3)汉语的词类与句法功能之间没有简单的对应关系。(《朱德熙文集》编辑小组 1999)吕叔湘先生(1984)指出“有了形态变化,语法分析就比较容易进行。没有严格的形态变化,在语法分析上就比较容易引起问题。”凡自然语言都不存在形式和意义的简单对应关系,而汉语的上述特点增加了形式与意义对应的复杂性,中文信息处理系统尤其需要语言知识库的支持。基于以上认识,我们在20世纪80年代中期,便将研究重心放在了语言知识库的建设上。
现在,从事自然语言处理研究的学者普遍认识到语言大数据及面向机器学习的语料库标注的重要性。不过,在20世纪80年代中期,电子文本尚需手工输入,不存在可利用的语料库。当时自然语言处理主流技术是基于规则的,语言模型通常采用上下文无关语法及其多种扩展形式,如基于复杂特征集和合一算法的词汇功能语法LFG(Kaplan & Bresnan 1982)。同一时期,国内的汉语词组本位语法体系已经成熟。(《朱德熙文集》编辑小组 1999)天时、地利、人和促使我们首先研制以描述汉语句法知识为主要内容的通用型机器词典GKB,既适应中文信息处理技术发展的需求,又有利于发挥北京大学的学科综合优势。
20世纪90年代统计自然语言处理技术兴起,大规模标注语料成为推动技术发展的基础资源。当时,GKB已经成形,又有了实现自动词语切分和词性标注的软件,更有人才资源的储备,我们便适时地对大规模语料进行基本加工及同形(义项)标注。
综合型语言知识库的建设从研制机器词典起步,后标注语料,先聚焦词法、句法知识,后增加语义知识;先汉语后多语;先关注通用领域再扩展到专业领域。以这样的节奏按部就班地进行,既适应技术的发展,又符合基础研究发展的内在规律。
(二) 要努力学习并善于运用语言学知识
机器词典应具备系统性、周遍性、规范性,还必须格式化、代码化。尽管机器词典的知识表示与书本型词典不同,但知识的内容却是不变的。在研制GKB和多级标注语料库时,我们学习、吸收语言学家总结的语言知识,特别是书本型词典所汇集的语言知识。语言学大师们的论著如《朱德熙文集》(《朱德熙文集》编写小组 1999)、《现代汉语八百词》(吕叔湘1984)、《现代汉语语法研究教程》(陆俭明 2003)及《现代汉语词典》(中国社会科学院语言研究所词典编辑室编 2005)等辞书常置案头,是语言知识的源头。
词类知识是自然语言处理所需要的最基本的语言知识,经过慎重选择、比较及实践,GKB 建立了面向自然语言处理的汉语词类体系。(俞士汶,朱学锋 2003)这个体系基本继承了朱先生建立的词组本位语法体系中关于词类的研究成果(《朱德熙文集》编辑小组 1999),但也并非全盘照抄,根据语言事实做了适当的调整和发展。朱先生认为“划分词类的根据只能是词的语法功能”,因此将区别词定义为“只能在名词或助词‘的’前边出现的黏着词”,将副词定义为“只能充任状语的虚词”。这样的定义清晰地反映了区别词和副词最重要的特点。利用这个定义可以把属于区别词和副词的大多数成员包括进来。但是,由于语言现象的复杂性和模糊性,这种严格的标准难以贯彻到底。参照朱先生对体词和谓词的论述,GKB把区别词的定义修改为“通常只在名词或助词‘的’前边出现的黏着词,主要用作定语”;把副词的定义修改为“基本上只能作状语(修饰动词和形容词)的实词”。事实上,模糊现象在语言中是普遍存在的。GKB采取了一些策略,应对语言中的模糊现象,以保障语言工程的顺利实施。(俞士汶,朱学锋 2017)
词语体系的建立及数以万计词语的归类是GKB全盘工作的基础,不过,GKB的主体是在归类的基础上,分类描述词语的语法属性。GKB关于词典结构的这一重要创新是受多种学科知识的启发。一是20世纪80年代中期流行的以复杂特征集和合一运算为特征的一些计算语言学理论,如LFG(Kaplan & Bresnan 1982)。二是数学知识。事物的分类与属性描述可以相互转化: 如果为所描述的对象确立n个属性(n≥1,值为“真”或“伪”),则最多可将对象的集合划分为2n个不同的类别。反之,若将对象的集合划分为N(N≥2)个不同类别,则至少需要确立[log 2 (N-1)+1]个不同的属性(方括号代表取整操作)。三是词组本位语法体系。朱先生说:“同类的词有共同性,并不是说同类的词语法功能全部相同; ……因为同类的词有不同的个性,所以大类之下可以分出小类来,例如动词里的及物动词和不及物动词。”(《朱德熙文集》编辑小组 1999)我们曾将动词划分为“及物”与“不及物”两个小类,但及物动词的宾语有3 种类型: 体词性的、谓词性的、准谓词性的。GKB便不在基本词类之下再划分小类,转而采用归类与属性描述相结合的策略。
(三) 知识与技术的相互促进
20世纪80年代中期,中文信息处理技术刚开始上规模的研究,没有可利用的语料库,自动知识挖掘技术尚未开发。以投入专家知识的方式研制机器词典是最佳的建设语言知识库的技术路线。跨出的第一步是踏实的,其可靠的质量为后续的综合型语言知识库建设奠定了坚实的基础。那时研制机器词典虽说依靠专家,但已不是使用卡片的传统方式,而采用了当时已经成熟的关系数据库管理技术。之后又基于GKB,研发了一系列工具软件,包括词语切分与词性标注、自动注音、双语句对齐等,不仅使得语言知识库建设的自动化程度越来越高,而且这些工具软件也成为中文信息处理系统的组成模块。知识与技术的互动促进了中文信息处理技术的发展。
(四) 规模、质量与工程进度的权衡
机器词典的规模必须足够大。GKB收词8万多。如果将GKB的一个记录中的一个字段的值定义为一个信息单位,GKB的信息总数约360万个单位,规模可谓大也。质量是词典的生命线,每一个知识信息的填写都必须仔细斟酌、反复斟酌。但语言工程都有特定的阶段性目标,工程进度必须保证。因此,规模是逐步扩大的,对质量的要求又只能在发展过程中逐步提高。幸运的是,以GKB为基础的综合型语言知识库成形之后,一直得到应用。正因为得到应用,知识库的瑕疵得以不断剔除,质量得以不断提高。在GKB等知识库的维护中,词语归类的调整是分量最重的一件事。为了检验词语归类的质量,也为了让汉语词类研究跨上一个台阶,我们还将GKB的词语归类和《现代汉语词典》第5 版进行了比较。(俞士汶,朱学锋,邱立坤等 2017;邱立坤,赵慧,俞士汶等 2017)
能够在《辞书研究》上发表拙文,同辞书专家交流研制机器词典的心得是很有意义的。长期以来,人们都在谈论学科的交叉融合。然而,由于条件的限制,真正实现学科的交叉融合并不容易。我们是学理工科的,刚进入计算语言学领域时,无论对语言学本身还是对语言学与计算机技术的结合都很茫然。我们从事大型语言工程实践的体验或许对探索学科交叉融合的学者也有参考价值。我们认为,如果辞书专家了解了自然语言处理的需求,关注、参与甚至主导机器词典的建设,对于自然语言处理技术则善莫大焉。
谨向长期以来支持GKB和综合性语言知识库发展的基金项目、专家和朋友,以及所有奉献了智慧和辛劳的同仁致以真诚的谢意。
参考文献
1. 常平.20世纪我国重大工程技术成就.广州: 暨南大学出版社,2002: 30⁃31.
2. 李晋霞,刘云.新版《现代汉语语法信息词典详解》的贡献.辞书研究,2004(3).
3. 陆俭明.现代汉语语法研究教程.北京: 北京大学出版社,2003.
4. 吕叔湘.现代汉语八百词.北京: 商务印书馆,1984: 1⁃6.
5. 邱立坤,金澎,王萌译.面向机器学习的自然语言标注.上海: 机械工业出版社,2017(2).
6. 邱立坤,赵慧,俞士汶等.《现汉》与《语法信息词典》词类对应分析.中文信息学报,2017: 1⁃7.
7. 王惠,詹卫东,俞士汶.现代汉语语义词典规范.汉语语言与计算学报,2003,13(2): 159⁃176.
8. 俞士汶.中文输入中语法分析技术的应用.中文信息学报,1988,2(3): 20⁃26.
9. 俞士汶主编.计算语言学概论.北京: 商务印书馆,2003.
10. 俞士汶.现代汉语短语结构知识库规格说明书.汉语语言与计算学报,2003,13(2): 215⁃226.
11. 俞士汶,段慧明,朱学锋等.北京大学现代汉语语料库基本加工规范.中文信息学报,2002,16(5):49⁃64;16(6): 58⁃65.
12. 俞士汶,段慧明,朱学锋等.北大语料库加工规范: 切分·词性标注·注音.汉语语言与计算学报,2003,13(2): 121⁃158.
13. 俞士汶,段慧明,朱学锋.词的概率语法属性描述研究及其成果.∥许嘉璐,傅永和主编.中文信息处理——现代汉语词汇研究.广州: 广东教育出版社,2006: 227⁃283.
14. 俞士汶,姜新,朱学锋.基于测试集与测试点的机译系统评估.∥陈肇雄主编.机器翻译研究进展.电子工业出版社,1992: 524⁃537.
15. 俞士汶,穗志方,朱学锋.综合型语言知识库及其前景.中文信息学报,2011,25(6).
16. 俞士汶,朱学锋,王惠等.现代汉语语法信息词典详解(第二版).北京: 清华大学出版社,2003: 19⁃136.
17. 俞士汶,朱学锋.综合型语言知识库与常用词库.∥王铁琨,李清山,亢世勇主编.辞书研究与辞书发展论集(第二辑).上海: 上海辞书出版社,2014: 17⁃36.
18. 俞士汶,朱学锋.语言模糊性与语言工程实践.∥黎千驹,冯广艺主编.模糊语言研究(第一辑).北京: 中国社会科学出版社,2014: 275⁃284.
19. 俞士汶,朱学锋.词汇计量研究与常用词知识库建设.中文信息学报,2015(3): 16⁃20.
20. 俞士汶,朱学锋,邱立坤等.两部词典的词类体系与词语归类之比较.∥亢世勇主编.辞书研究与辞书发展论集(第三辑).上海: 辞书出版社,2017: 31⁃46.
21. 约阿夫·戈尔德贝格著.基于深度学习的自然语言处理.车万翔等译.北京: 机械工业出版社,2018.
22. 中国社会科学院语言研究所词典编辑室编.现代汉语词典(第1、3、5 版).北京: 商务印书馆,1978,1996,2005.
23. 《朱德熙文集》编辑小组.朱德熙文集(第1 卷).北京: 商务印书馆,1999: 32⁃50,270⁃294,334⁃344.
24. 朱学锋,俞士汶.自然语言处理与语言知识库.∥罗振声,袁毓林主编.计算机时代的汉语汉字研究.北京: 清华大学出版社,1996: 107⁃118.
25. 宗成庆.统计自然语言处理(第2 版).北京: 清华大学出版社,2013.
26. Kaplan R M.Bresnan J. Lexical⁃functional Grammar: A formal System for Grammatical Representation.∥Bresnan J.(ed.) The Mental Representation of Grammatical Relations. Cambridge, MA: MIT Press,1982.
27. Yu Shiwen(俞士汶). Automatic Evaluation of Output Quality for Machine Translation Systems. Machine Translation ,1993(8): 117⁃126.
∗ 本文的雏形源自2018年于南京大学举办的第十届演化语言学国际研讨会,并将以英文刊载于Salikoko Mufwene教授的寿庆文集中。感谢华东师范大学中国语言文学系郑伟老师的邀稿及蔡雅菁对此文的协助。
致谢: 我在语言、认知和神经科学方面的研究,得到香港特别行政区政府GRF # 1560 1718及香港理工大学中文及双语学系的支持。
(北京大学计算语言学教育部重点实验室;北京大学计算语言学研究所 北京 100871)
本文原载于《辞书研究》2019年第2期
以上是关于俞士汶朱学锋:面向自然语言处理的机器词典的研制的主要内容,如果未能解决你的问题,请参考以下文章