SuperGLUE!自然语言处理模型新标准即将公布
Posted 麻省理工科技评论APP
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了SuperGLUE!自然语言处理模型新标准即将公布相关的知识,希望对你有一定的参考价值。
自然语言处理(NLP),是机器学习领域的一个分支,专门研究如何让机器理解人类语言和相关文本,也是发展通用人工智能技术亟需攻克的核心难题之一。
不久之后,纽约大学、华盛顿大学、剑桥大学和 Facebook AI 将联合推出一套新的自然语言处理(NLP)评估基准,名为 SuperGLUE,全称是 Super General-Purpose Language Understanding。
该系统是现有 GLUE 基准的升级版(所以前面加上了 Super)。研究人员删除了原本 11 项任务中的 9 项,更新了剩下 2 项,同时加入了 5 项新的评估基准。新版本将更契合未来 NLP 技术的发展方向,难度也是大幅增加,更具挑战性。
(来源:Nikita Nangia)
这套系统的数据集、工具包和具体评估标准预计将于 5 月初公布。不过从最新发布的 SuperGLUE 论文中,我们可以先睹为快。
什么是 GLUE?
实现 NLP 的方法有很多,主流的方法大多围绕多任务学习和语言模型预训练展开,由此孕育出很多种不同模型,比如 BERT、MT-DNN、ALICE 和 Snorkel MeTaL 等等。在某个模型的基础上,研究团队还可以借鉴其它模型的精华或者直接结合两者。
为了更好地训练模型,同时更准确地评估和分析其表现,纽约大学、华盛顿大学和 DeepMind 的 NLP 研究团队在 2018 年推出了通用语言理解评估基准(GLUE),其中包含 11 项常见 NLP 任务,都是取自认可度相当高的 NLP 数据集,最大的语料库规模超过 40 万条,而且种类多变,涉及到自然语言推理、情感分析、阅读理解和语义相似性等多个领域。
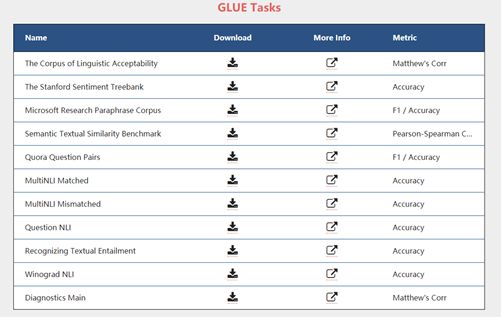
图 | GLUE的11项任务
不过GLUE基准才发布一年,已经有很多 NLP 模型在特定任务中超过了人类基准,尤其是在 QQP、MRPC 和 QNLI 三项任务中:
QQP 是“Quora 问题配对”数据集,由 40 万对 Quora 问题组成,模型需要识别两个问题之间的含义是否相同。
MRPC 是“微软研究释义语料库”,与 QQP 类似,模型需要判断两个形式不同的句子是否具有相似的意思(即释义句)。
QNLI 任务基于“斯坦福问答数据集(SQuAD)”,主要考察模型的阅读理解能力。它需要根据维基百科中的文章来回答一些问题,答案可能存在于文章中,也可能不存在。
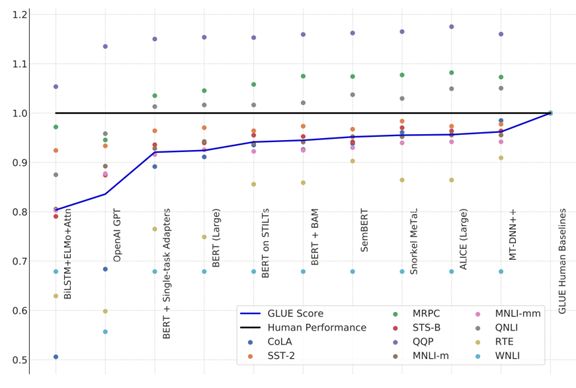
图 | NLP 模型在三项任务中普遍超过了人类基准,越靠右侧的模型分数越高
目前综合分数最高的是微软提交的 MT-DNN++模型,其核心是多任务深度神经网络(MT-DNN)模型,并且在文本编码层整合了 BERT。仅次于它的是阿里巴巴达摩院 NLP 团队的 ALICE Large 模型和斯坦福的 Snorkel MeTaL 模型。
从上面图中我们也能看出,得益于 BERT 和 GPT 模型的引入,模型在很多GLUE 任务的得分都已经接近人类基准,只有 2-3 个任务与人类有明显差距。
因此,推出新的评估基准势在必行。
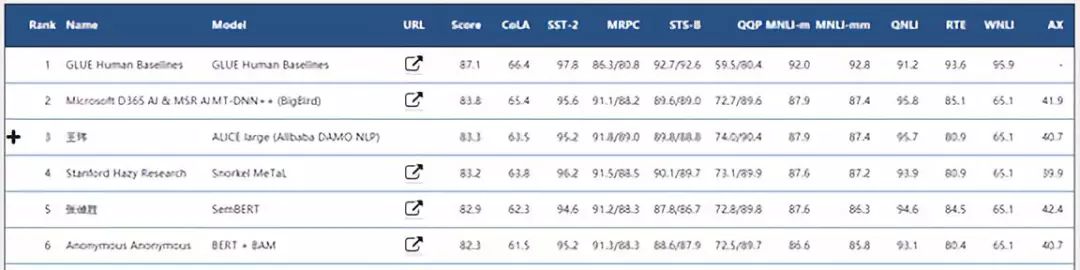
图 | GLUE排行榜前五名
从 GLUE 到 SuperGLUE
新的 SuperGLUE 遵从了 GLUE 的基本原则:为通用语言理解技术的进步提供通俗,但又具有挑战性的基准。
在制定这个新基准时,研究人员先在 NLP 社区公开征集任务提案,获得了大约 30 份提案,随后按照如下标准筛选:
任务本质:测试系统理解英语的能力。
任务难度:超出当前最先进模型的能力,但是人类可以解决。
可评估性:具备自动评判机制,并且能够准确对应人类的判断或表现。
公开数据:拥有公开的训练数据。
任务格式:SuperGLUE 输入值的复杂程度得到了提升,允许出现复杂句子,段落和文章等。
任务许可:所用数据必须获得研究和重新分发的许可。
在筛选过程中,他们首先重新审核了现有的 GLUE 任务集,从中删除了模型表现较好的 9 项任务,保留了 2 项表现最差的任务——Winograd 模式挑战赛(WSC)和文本蕴含识别(RTE)——它们还有很大的进步空间。
两项任务分别属于自然语言推理和阅读理解范畴。人类通常比较擅长这样的任务,甚至于不需要特殊训练就可以精通。比如看到这样两句话:
“这本书装不进书包,因为它太大了。”
“这本书装不进书包,因为它太小了。”
尽管两个句子包含两个含义截然相反的形容词,人类还是可以轻松理解,因为我们知道“它”的指代物不同。但上面那些NLP模型却表现的很糟糕,平均水平不足人类的 70%。而这其实就是 WSC 任务的主要内容。
最后,研究人员挑选(设计)了 5 项新任务,分别是 CB,COPA,GAP,MultiRC 和 WiC,主要测试模型回答问题,指代消解和常识推理的能力。
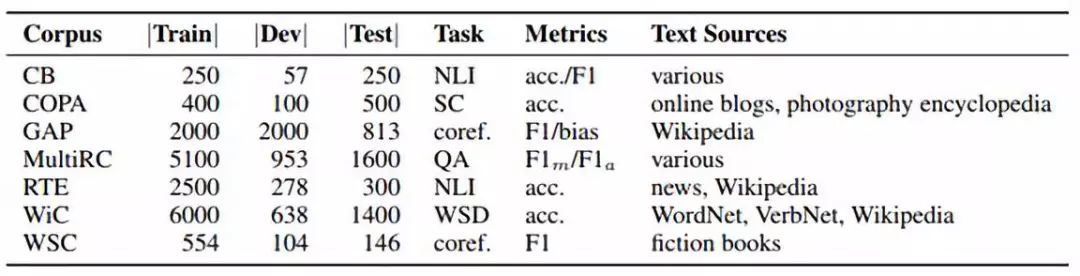
图 | 新版SuperGLUE任务集,其中RTE和WSC来自于现有的GLUE任务
研究人员认为,SuperGLUE 的新任务更加侧重于测试模型在复杂文本下的推理能力。
比如 WiC 要求模型在两段内容中,区分同一个单词的含义是否一致(听起来简单,但对于机器来说非常困难)。CB 和 COPA 都是考察模型在给定“前提”的情况下,对“假设”或“理由”的正确性进行判断,只不过有的侧重于分析从句,有的侧重于问答模式。
GAP 则要求模型对性别做出判断,能够通过“姐姐”,“哥哥”和“妻子”这样的词汇,分辨文本中“他”和“她”的指代对象。
MultiRC 任务更加复杂,模型需要完成阅读理解,然后回答问题。一个典型的例子是这样的:

图 | 搜索关键词“speedy recover”,几乎一眼就能找到答案,但机器未必知道
选择了新的任务之后,研究人员用主流 NLP 模型进行了测试。
最流行的 BERT 模型的表现勉强可以接受,但其量化之后的综合分数比人类低约 16.8%,说明机器距离人类基准仍有不小的差距,而且 SuperGLUE 确实比GLUE 难了不少。
图 | 现有模型在SuperGLUE上的表现
鉴于目前 SuperGLUE 还没有正式推出,我们还无法查看任务数据集和模型排行榜。在 5 月份推出 SuperGLUE 后,它可能还会经历一些微调,然后在7月份变为正式版本,供研发 NLP 模型的团队挑战。
目前来看,SuperGLUE 和 GLUE 之间的差距是可以接受的,新任务具有一定的挑战性,但并非遥不可及,足以为全球的 NLP 团队树立一个新的标杆。
https://w4ngatang.github.io/static/papers/superglue.pdf?nsukey=TDPD9drJFegoLhDSDalFBfkaib9JaEwIsW%2BhGfKfqrOaCoLPWIkhNVVvpUM1RPmFK6PNHEaQbw0C3gOE4%2BkdTfuD5HzAuc5ZW0UO3yN9wyXcJgXm%2BhVcJESlfxRoK5GP7hU%2FEaKkkN7SeokGh7LKIdybGgi4uzf0%2FwWgt3zJpDDWJ04riyxjeA9HpdLYK3ODqLRyCtej2sKBxkfDlIYIAg%3D%3D
以上是关于SuperGLUE!自然语言处理模型新标准即将公布的主要内容,如果未能解决你的问题,请参考以下文章
视觉SLAM总结——SuperPoint / SuperGlue
图像匹配天花板:SuperPoint+SuperGlue复现