基于深度学习的自然语言处理技术:边界在何方?
Posted DeepTech深科技
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了基于深度学习的自然语言处理技术:边界在何方?相关的知识,希望对你有一定的参考价值。
有人这样分类目前的人工智能:感知智能、运动智能、认知智能。感知智能是类似于人脸识别、图像识别这一类能够识别处理外界信息的技术;运动智能是机器人要操纵一个机器,能够根据输入做出相应的动作处理,而第三类认知智能更多的涉及到理解问题,用语言表达问题,做出长远的规划,做出决策。
在这三类智能里面,最复杂的也是人类所特有的认知智能,离不开自然语言处理技术的支持。
基于深层神经网络的深度学习方法从根本上改变了自然语言处理技术的面貌,把自然语言处理问题的定义和求解从离散的符号域搬到了连续的数值域,导致整个问题的定义和所使用的数学工具与以前完全不同,极大地促进了自然语言处理研究的发展。
在深度学习技术引入自然语言处理之前,自然语言处理所使用的数学工具跟语音、图像、视频处理所使用的数学工具截然不同,这些不同模态之间的信息流动存在巨大的壁垒。而深度学习的应用,把自然语言处理和语音、图像、视频处理所使用的数学工具统一起来了,从而打破了这些不同模态信息之间的壁垒,使得多模态信息的处理和融合成为可能。
总之,深度学习的应用,使得自然语言处理达到了前所未有的水平,也使得自然语言处理应用的范围大大扩展。
但近几年,虽说基于深度学习的自然语言处理取得了巨大的成功,但其局限性也逐渐显现:
1. 过去大部分的自然语言处理都是用数据驱动的方法,事实证明现在的自然语言理解还不够深,相当于说机器实际上只是理解了这个符号。我们的语言实际上是一种符号,现在的自然语言处理,实际上是理解了符号与符号之间的关系,我们有大量的数据来驱动训练这种理解,所以它能理解这种关系,但它不像人脑一样能够理解这个符号与真实的物理世界之间的关系。
2. 全世界有几千种语言,其中大量的语言是没有那么多数据的,资源稀缺问题比大部分人想象的要严重的多,在很多专业领域里面,也没有很多数据,工业界遇到的大部分问题只有极少或者完全没有标注数据,我们不可能有那么大量的数据来训练一个系统。
刘群是华为诺亚方舟实验室语音语义首席科学家,本科毕业于中国科学技术大学,在中国科学院计算机技术研究所获计算机硕士学位,在北京大学获计算机博士学位。曾担任中国科学院计算技术研究所研究院、自然语言处理处理研究组组长、爱尔兰都柏林城市大学计算机系终身教授、爱尔兰 ADAPT 研究中心自然语言处理主题负责人。
在 2019 年 8 月 24 日北京举办的第四届语言与智能高峰论坛上,刘群针对深度学习对于自然语言处理的贡献与边界展开了具体描述。刘群总结近年来给予深度学习的方法在自然语言处理中所取得的成功之处,列出那些曾经被认为很难但现在已经基本解决或接近于解决的问题;并讨论在这种方法目前面临哪些挑战,分析这些挑战中哪些是现在深度学习框架有希望解决的,而哪些是在深度学习框架下很难或者无法解决,需要探索新的解决途径的。
过去十年,自然语言处理领域影响最深远的研究深度学习技术的引入,深度学习解决了自然语言处理的哪些问题?还有哪些自然语言处理问题深度学习没有解决?
刘群将其答案总结为:自然语言处理中的资源稀缺问题、可解释性问题、可信任性问题、可控制性问题、超长文本问题、缺乏常识问题,并将其与深度学习方法边界之间的关系联系起来。
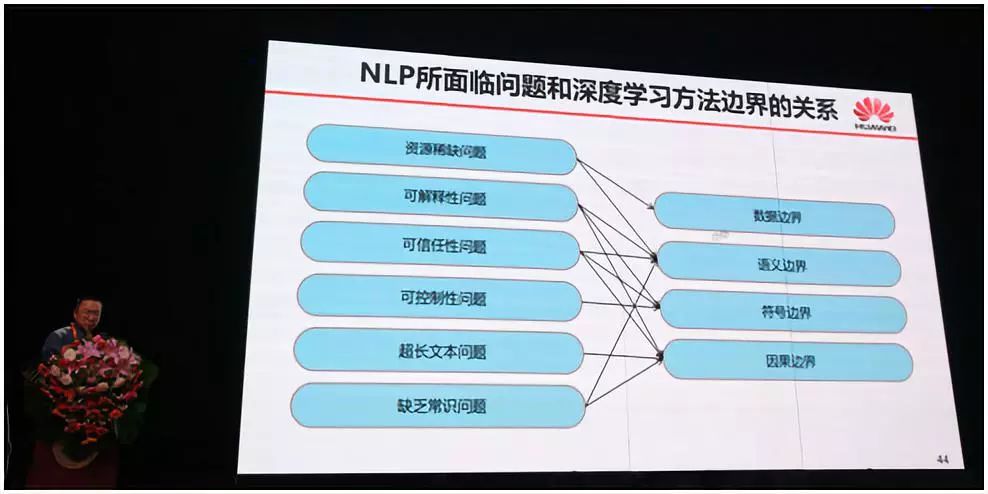
图 | 刘群正在峰会做分享(来源:DeepTech)
-语义边界,或者说知识的学习,或常识的学习问题。这是自然语言处理技术如何变得更“深”的问题。尽管常识的理解对人类来说不是问题,但是它却很难被教给机器。比如我们可以对手机助手说“查找附近的餐馆”,手机就会在地图上显示出附近餐馆的位置。但你如果说“我饿了”,手机助手可能就无动于衷,因为它缺乏“饿了需要就餐”这样的常识,除非手机设计者把这种常识灌入到了这个系统中。但大量的这种常识都潜藏在我们意识的深处,AI 系统的设计者几乎不可能把所有这样的常识都总结出来,并灌入到系统中。
-数据边界,即低资源问题。所谓无监督学习、Zero-shot 学习、Few-shot 学习、元学习、迁移学习等技术,本质上都是为了解决低资源问题。面对标注数据资源贫乏的问题,譬如小语种的机器翻译、特定领域对话系统、客服系统、多轮问答系统等,自然语言处理尚无良策。这类问题统称为低资源的自然语言处理问题。对这类问题,我们除了设法引入领域知识(词典、规则)以增强数据能力之外,还可以基于主动学习的方法来增加更多的人工标注数据,以及采用无监督和半监督的方法来利用未标注数据,或者采用多任务学习的方法来使用其他任务,甚至其他语言的信息,还可以使用迁移学习的方法来利用其他的模型。这是自然语言处理技术如何变得更“广”的问题。
刘群教授举了 WMT2019 的 Biomedical MT Task 的例子,在法语收录的医疗名词数据库中,仅有不到 8 万条语句,这对于传统深度学习的数据训练量来说是远远不够的!

图 | 信息抽取与文本分类(来源:MIT Technology Review)
目前很多地方都在用自然语言处理技术。
二十年前流行五笔输入法进行文档编辑等工作,那个时候拼音输入法受到冷待,其实很大的原因是因为自然语言处理技术没有很好的解决拼音转换字的这个预测的问题,当编辑者输入一串拼音时,需要编辑者一个字一个字的去选,但现在常见的拼音输入法,加持优秀的自然语言处理技术,输入一串拼音,基本上就选两三次便能打出满意的语句。另外还有比如百度谷歌的搜索技术,输入一个问题,便给出了推荐答案,不会给你一堆文章让你去查,这都是自然语言处理取得的一些非常大的一个进展的结果,它在不断地改善我们的生活。
就其中的多语言问题来说,在 RBMT (Rule-Based Machine Translation) 时代,开发多语言机器翻译系统代价极高,其中较为理想的中间语言(Interlingua)方案,由于系统过于复杂,成为“”不可承受之重”。在 NMT (Neural Machine Translation )时代,单一的多语言机器翻译系统被提出并被验证有效,中间语言的理想初步得以实现。
活动推荐:CNCC2019
2019 年 10 月 17-19 日,2019 中国计算机大会 (CNCC 2019) 将在苏州金鸡湖国际会议中心举办,由中国计算机学会 (CCF) 主办,苏州工业园区管委会承办。今年的大会主题为“智能+引领社会发展 (AI+ Leading the Development of Society)”,大会包含了:十五位国内外计算机领域知名专家、企业家的大会报告、三场大会主题论坛,七十余场前沿技术论坛,二十场特色活动,以及一百个科技成果展。
其中三个大会论坛主要围绕互联网 50 年、工业互联网、深度学习三个主题展开讨论。七十余场技术论坛由内容丰富、形式多样的多个计算领域的热点主题组成,如人工智能、大数据、区块链、量子计算、神经形态计算、工业互联网、信息安全、健康医疗、教育教学等。刘群教授将担任 CNCC 2019“自然语言对话:技术挑战与行业应用”分论坛的主席,与社会各界分享自然语言处理技术的更多前沿信息。
战略合作媒体
点击阅读原文查看大会详情↓
以上是关于基于深度学习的自然语言处理技术:边界在何方?的主要内容,如果未能解决你的问题,请参考以下文章
对比学习:《深度学习之Pytorch》《PyTorch深度学习实战》+代码