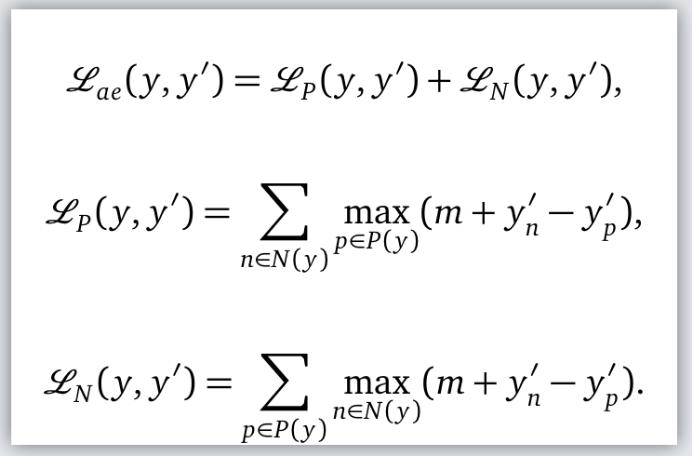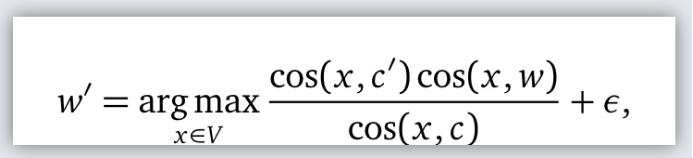独家 | NAACL19笔记:自然语言处理应用的实用理解(多图解&链接) Posted 2021-04-12 数据派THU
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了独家 | NAACL19笔记:自然语言处理应用的实用理解(多图解&链接)相关的知识,希望对你有一定的参考价值。
本文长度约为3000字 ,建议阅读10 分钟
本文介绍了NLP在文本相似性、文本分类、序列标注和语言生成中的重要成果。
继续这个系列文章的第一部分
(https://medium.com/orb-engineering/naacl-19-notes-practical-insights-for-natural-language-processing-applications-part-i-5f981c92af80)
,我们调查了NLP任务中最近的一些重要成果,比如文本相似性、文本分类、序列标注、语言生成。
2019NAACL中的文章“Correlation Coefficients and Semantic Textual Similarity”
( https://www.aclweb.org/anthology/N19-1100)
对使用余弦相似性计算词向量的相似性提出了质疑。它的核心想法是,考虑把一个单词或者句子
在词相似度下,违反正态性假设使得余弦相似度特别不适合于GloVe词向量。对FastText和word2vec,皮尔逊系数和秩相关系数(Spearman,Kendall)的结果具有可比性。然而,余弦相似性对于句子向量(句子中单词词向量的质心,一种计算句子特征的基本方法)是次优的,即使对于FastText也是如此。它是由表现为异常值的停词引起的。在这种情况下,秩相关测度在经验上更可取。
“Rethinking Complex Neural Network Architectures for Document Classification”
( https://www.aclweb.org/anthology/N19-1408)
和它的后续文章
(https://arxiv.org/pdf/1904.08398v1.pdf)
在四个数据集(Reuters, Arxiv APD, IMDB, Yelp)上对比了最先进的文本分类模型。作者的框架Hedwig
(http://hedwig.ca/)
使用了PyTorch实现这些模型。正如预期的那样,微调(Fine-tuned)BERT分类器的效果最好,但其他的发现令人惊奇。第二好的模型是一个简单的bi-LSTM分类器
(https://github.com/castorini/hedwig/tree/master/models/reg_lstm)
,经过适当正则化,用max-pooling来降维得到一个文档特征向量。它的表现超过了一些复杂结构的模型,比如hierarchical attention networks (HAN)
(https://github.com/castorini/hedwig/tree/master/models/han)
或者XML-CNN
(https://github.com/castorini/hedwig/tree/master/models/xml_cnn)
,因此质疑这项任务是否需要这么复杂。甚至,对于类别更多且相对稀疏的数据集(Reuters, Arxiv),在TF-IDF向量上训练的one-vs-rest逻辑回归和SVM的表现都超过了这两个复杂的模型。
“Mitigating Uncertainty in Document Classification”
(https://www.aclweb.org/anthology/N19-1316)
提出基于特征表示的度量学习和基于drop-out的文本分类深度学习模型不确定性度量方法(可能应用于高精度用例,如医学领域)。分类器的结构很标准:一个在训练好了的词向量数据集上(初始化为GloVe向量)的卷积神经网络,接着一个dropout层,一个全连接层和一个softmax层。Metric learning是用于训练词向量使得类内的欧式距离最小、类间欧式距离最大。Sₖ是第k类的一组样本点,rᵢ, rⱼ是第i、j个样本点的特征,D是欧式距离。
引入度量学习可以减小预测方差,提高准确预测的可信度。
基于dropout的方法结合降噪操作,利用多个dropout评估的信息熵来度量模型的不确定性。预测分类的输出向量y* = (y*₁,…,y*ₖ)是在卷积神经网络k times后应用dropout(以一定概率放弃被激活的神经元)。
为了降噪,把1/3的无法充分代表的类别去掉之后,类别分布的熵计算为不确定性分数。我们注意到variational dropout method方法仍然引起了激烈的理论讨论
(可以看https://www.reddit.com/r/MachineLearning/comments/7bm4b2/d_what_is_the_current_state_of_dropout_as/)
尽管如此,论文作者已经表明,该方法通过在20类文本分类任务中将25%的标记工作分配给人类专家,将macro-F1分数从78%提高到92%。
“Ranking-Based Autoencoder for Extreme Multi-label Classification”
( https://www.aclweb.org/anthology/N19-1289)
这篇文章提出了一种针对大量标签的文本分类任务的方法。这项任务在现实世界中有很多的应用,比如说,Orb Intelligence我们在做NAICS工业分类(北美产业分类系统)(是基于企业描述的文本做分类,有超过2200个分类层次)。该任务还具有标签之间的语义关系(类不是排他的)、类别不平衡和标签不完全性。
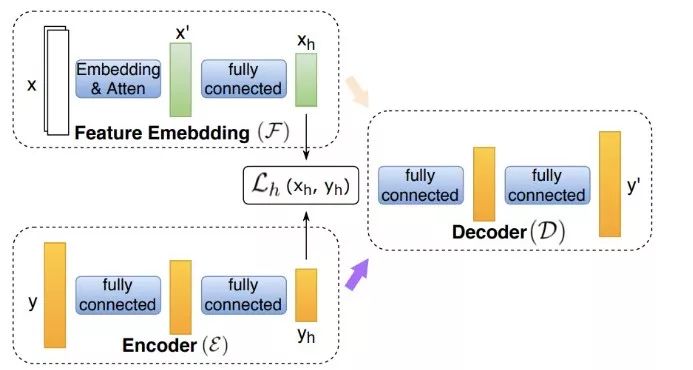
文章作者开发了一个新的深度学习方法Rank-AE如图1:
ℒ ₕ(xₕ,yₕ)是平方差误差。
这个架构可以在训练过程中捕捉到标签间的相关性。在推理过程中,标签的编码ℇ被忽略了。重建的损失ℒₐₑ(y,y’)由两个部分组成,分别对应正标签负标签。
首先,应用TF-IDF给词向量赋权重,第二,channel attention被设计成在单词嵌入中衡量不同的位(比方说,假设其中一些强调去掉术语“苹果”的商业意义,而另一个强调农业意义)。Channel attetion是通过excitation network实现(两个全连接层、非线性激活),以前这种方法只用在图像领域。
在原始的词向量矩阵上应用这两个自注意力机制,再用average pooling来得到特征向量x’。模型简化测试显示,Rank-AE在有噪声的数据集上以及复杂多分类文本数据集上受益于margin-ranking loss。论文中提供的注意力权重的事后分析对于解释哪些文本集对预测标签有贡献具有指导意义。
“Integrating Semantic Knowledge to Tackle Zero-Shot Text Classification”
( https://www.aclweb.org/anthology/N19-1108)
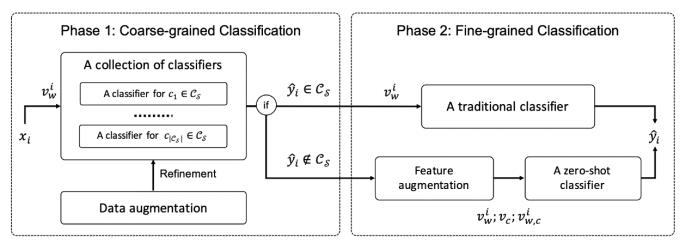
对零样本文本分类问题提出了一种先进的方法,零样本分类问题是指预测集中的分类在训练集中没有出现。在这种情况下,尽管我们假设我们至少有它们的名字,可能是简短的描述、类间分类甚至语义关系。这个方法有两个阶段(如图3)。
第一阶段,粗粒度分类:预测输入文本是否来自于可见或不可见的类别。此时,多分类问题被分解为多个one-vs-rest分类问题。作者使用了数据增强技术,来帮助分类器在没有访问标记数据的时候,对于不可见的类别更注意。然后第二阶段,细粒度分类,最终确定输入文档的类别。它可能使用:
只在可见类上训练的传统的多分类方法;
一个零样本分类方法。
已知特征向量xᵢ,类别向量c,零样本分类器以(xᵢ, c)为输入,学习预测p(ŷᵢ = c|xᵢ)的置信区间。基于语义知识的特征增广用于提供与文档和不可见类相关的附加信息,从而推广零样本推理。有关使用的数据增强和功能增强的更多详细信息:
1. 主题翻译:
从第一个可见类开始逐词 (表示为类名c的词向量) 翻译至新的不可见类c’,使用词的类比方法
(https://aclweb.org/anthology/W14-1618)
:
翻译词w保留词性(名词->名词,动词->动词 等)。翻译后的文档用于训练不可见类的零样本分类器。这些文档也用作可见类的二分类器(是否是可见类的分类器)的负样本。
DBpedia ontology数据集和20组新闻数据集上的试验显示,通过主题翻译的数据增强技术,对于不可见类的准确性提升了。另外,特征增强使知识从可见的类转移到不可见的类,从而实现零样本学习。该方法在各个阶段和总体上都达到了与竞争基线相比的最高精度。
Zalando Research的“Pooled Contextualized Embeddings for Named Entity Recognition”
( http://www.aclweb.org/anthology/N19-1078)
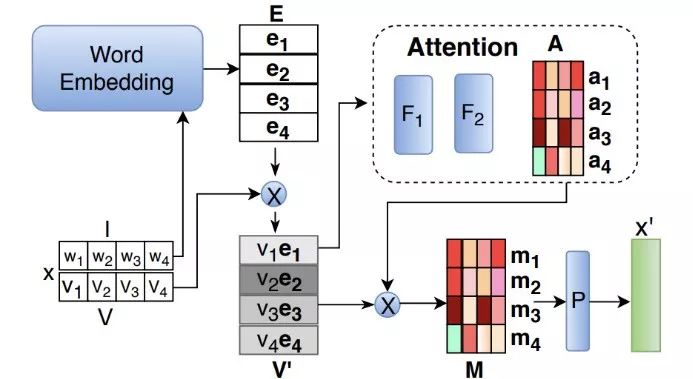
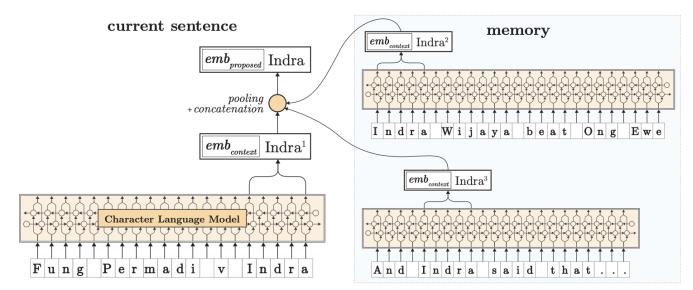
在大型语料库上下文所有句子中,利用字符级LSTM的上下文嵌入池化(最小/最大/平均),如图4。
图 4 对给定单词‘Indra’的上下文字符串嵌入特征(嵌入单词,1. 调用embed()方法,把结果放到这个单词的memory里;2. 然后把memory中所有上下文中这个单词的词向量做pooling操作;3. 最后,我们把原始的单词的词向量和上下文中pooled后的这个单词的词向量拼接起来)
最终的词嵌入是把原始上下文中的单词嵌入和pooled单词特征拼接起来,也是通过标准GloVe 或FastText来实现的词向量嵌入。试验证明,pooled上下文的嵌入提升了BiLSTM-CRF多语言命名实体识别,实现了新的SOTA表现,甚至超过了BERT-NER
(https://github.com/kyzhouhzau/BERT-NER)
,模型的实现是基于Flair框架
(https://github.com/zalandoresearch/flair)
。
“Pre-trained language model representations for language generation”
( https://arxiv.org/pdf/1903.09722.pdf)
这篇文章中,Facebook AI Research探讨了在seq2seq(编码器-解码器)结构中结合预训练向量的不同策略及其在机器翻译和抽象摘要中的应用。编码器和解码器都是Fairseq framework
(https://github.com/pytorch/fairseq)
中的tranformer实现的。考虑的策略包括:
实验表明,在这两种设置下,添加预先训练的特征对编码器网络非常有效(代价是训练速度慢5倍,而推理速度慢12-14%)。有趣的是,当有更多的标记数据可用时,效果改进会减少,这与第一部分讨论的预训练的样本效率是一致的。
第二部分到此结束。在第三部分中,我们将概述框架和各种有效的技术(注意力机制和自注意力机制、模型可视化和解释、对抗学习、知识提取、多模态学习)。
原文标题:NAACL ’19 Notes: Practical Insights for Natural Language Processing Applications — Part II
原文链接:https://medium.com/orb-engineering/naacl-19-notes-practical-insights-for-natural-language-processing-applications-part-ii-2a2a3dd42d1
编辑:黄继彦
校对:龚力
工作内容:需要一颗细致的心,将选取好的外文文章翻译成流畅的中文。如果你是数据科学/统计学/计算机类的留学生,或在海外从事相关工作,或对自己外语水平有信心的朋友欢迎加入翻译小组。
你能得到:定期的翻译培训提高志愿者的翻译水平,提高对于数据科学前沿的认知,海外的朋友可以和国内技术应用发展保持联系,THU数据派产学研的背景为志愿者带来好的发展机遇。
其他福利:来自于名企的数据科学工作者,北大清华以及海外等名校学生他们都将成为你在翻译小组的伙伴。
点击文末“阅读原文 ”加入数据派团队~
转载须知
发布后请将链接反馈至联系邮箱(见下方)。未经许可的转载以及改编者,我们将依法追究其法律责任。
点击“阅读原文”拥抱组织
以上是关于独家 | NAACL19笔记:自然语言处理应用的实用理解(多图解&链接)的主要内容,如果未能解决你的问题,请参考以下文章
大会 | 自然语言处理顶会NAACL 2018最佳论文时间检验论文揭晓
自然语言处理顶级会议ACL,EMNLP,NAACL, COLING论文质量有区别吗?
NAACL2021长序列自然语言处理, 250页ppt
AI&BlockChain:“知名博主独家讲授”人工智能创新应用竞赛精选实战作品之《基于计算机视觉自然语言处理和区块链技术的乘客智能报警系统》案例的界面简介功能介绍分享之自然语言处理技术
聚焦机器同传前沿进展,第二届机器同传研讨会将在NAACL举办
聚焦机器同传前沿进展,第二届机器同传研讨会将在NAACL举办