元学习与自然语言处理
Posted AI论道
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了元学习与自然语言处理相关的知识,希望对你有一定的参考价值。
什么是元学习?
元学习的NLP应用
Domain Adaptive Dialog Generation via Meta Learning, ACL2019
https://www.aclweb.org/anthology/P19-1253/
https://github.com/qbetterk/sequicity.git
模型的详细过程如下。单个领域的损失Lsk有领域数据集中的每一个回复的损失累加得到,fine-tune模型Mk'也由此损失进行更新。元学习总体损失在不同的源领域精调后的结果叠加。这个过程也符合元学习经典框架MAML的思路。
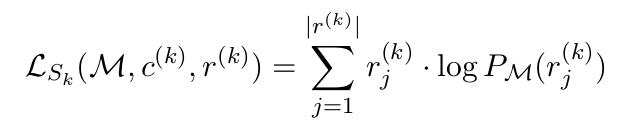
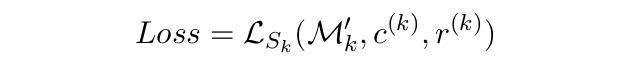
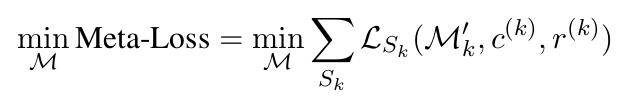
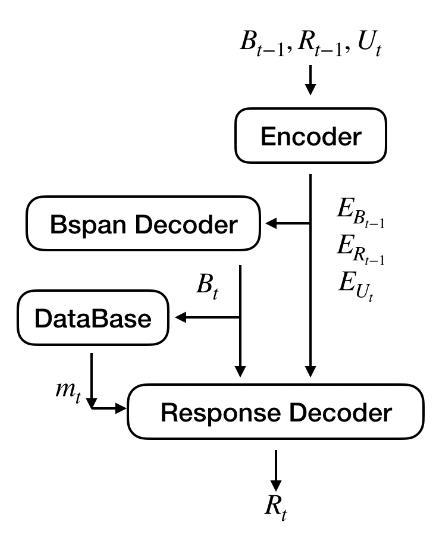
而论文也采用了传统的端到端序列建模方式构建对话生成模型。文章采用融合注意力机制的GRU模型作为编码器和解码器模型。如下图所示,DAML通过编码器建模时间步t-1的对话状态Bt-1、回复Rt-1与用户输入Ut,通过对话状态解码器和回复解码器生成t步的状态Bt与回复Rt。特别地,在回复生成过程中模型也使用了拷贝机制。
文章针对包含6个领域数据的SimDial数据集进行了实验,采用BLEU和Entity F1 score作为评测指标,也采用Adaption time衡量了模型在目标领域的fine-tune效率。对比模型包括ZSDG和传统的迁移学习。实验对比如下,
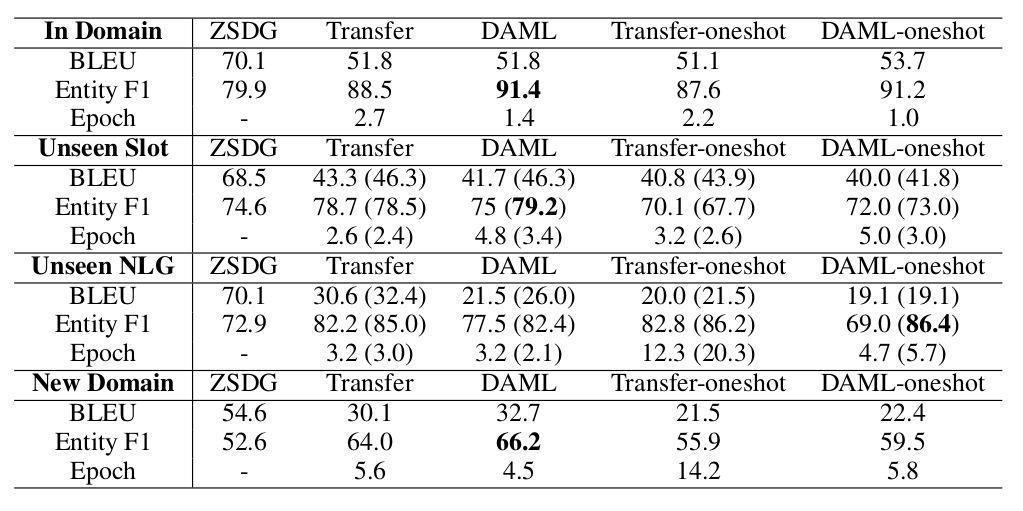
模型结果表明,DAML模型超越了普通的迁移学习和ZSDG成为新的state-of-the-art。
Personalizing Dialogue Agents via Meta-Learning, ACL2019
https://www.aclweb.org/anthology/P19-1542.pdf
https://github.com/HLTCHKUST/PAML
除了任务型对话面临样本短缺的问题,个性话对话系统同样需要在较少的数据上迅速调整为针对特定用户的定制模型。论文依旧采用了MAML元学习框架,在不使用用户个人信息的情况下能将对话生成模型快速迭代。模型算法架构如下。对于所有用户数据Dpi,模型进行fine-tune,将网络参数优化为theta'pi。外层的元学习网络针对查询集上(论文中成为task的验证集)得到的损失进行元学习网络参数更新。

模型采用交叉熵作为单个任务的损失函数,如式4。模型元网络参数更新方式如式5。
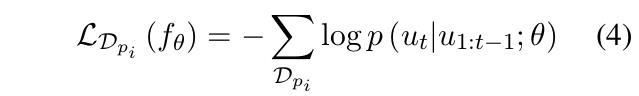
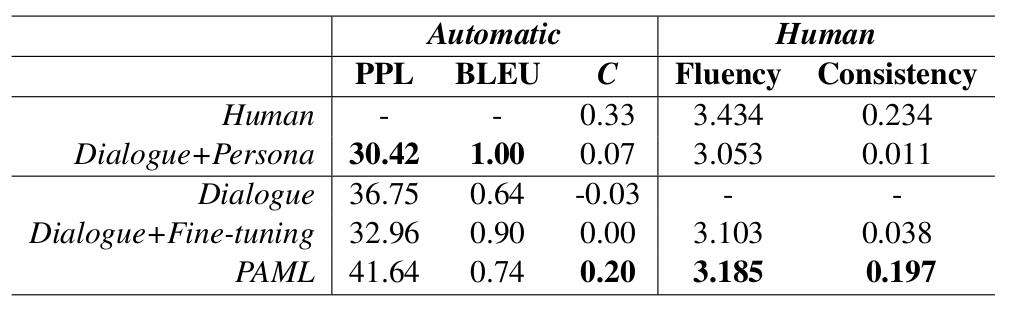
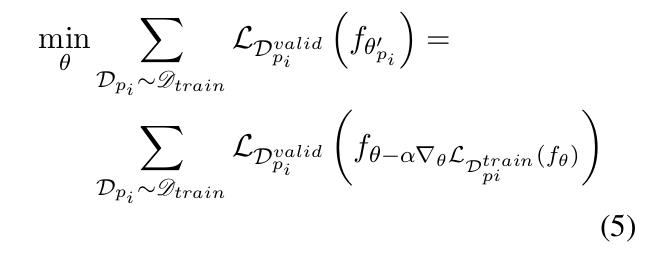 文章在Persona-chat数据集上进行了实验,通过用户描述的不同,划分出了针对不同用户的对话生成任务,并采用perplexity, BLEU和consistency作为自动衡量指标。模型在自动化指标与人工评测中均超越了普通的fine-tune模型,证明了其元学习框架的有效性。
文章在Persona-chat数据集上进行了实验,通过用户描述的不同,划分出了针对不同用户的对话生成任务,并采用perplexity, BLEU和consistency作为自动衡量指标。模型在自动化指标与人工评测中均超越了普通的fine-tune模型,证明了其元学习框架的有效性。
Meta Relational Learning for Few-Shot Link Prediction in Knowledge Graphs, EMNLP2019
https://www.aclweb.org/anthology/D19-1431.pdf
https://github.com/AnselCmy/MetaR
 模型的流程和核心算法可通过下图表达。模型需要针对所有任务都有效的一般关系知识元,即图中标识的RTr(关系知识元)。模型在查询集中通过GTr进行该任务的fine-tune。
模型的流程和核心算法可通过下图表达。模型需要针对所有任务都有效的一般关系知识元,即图中标识的RTr(关系知识元)。模型在查询集中通过GTr进行该任务的fine-tune。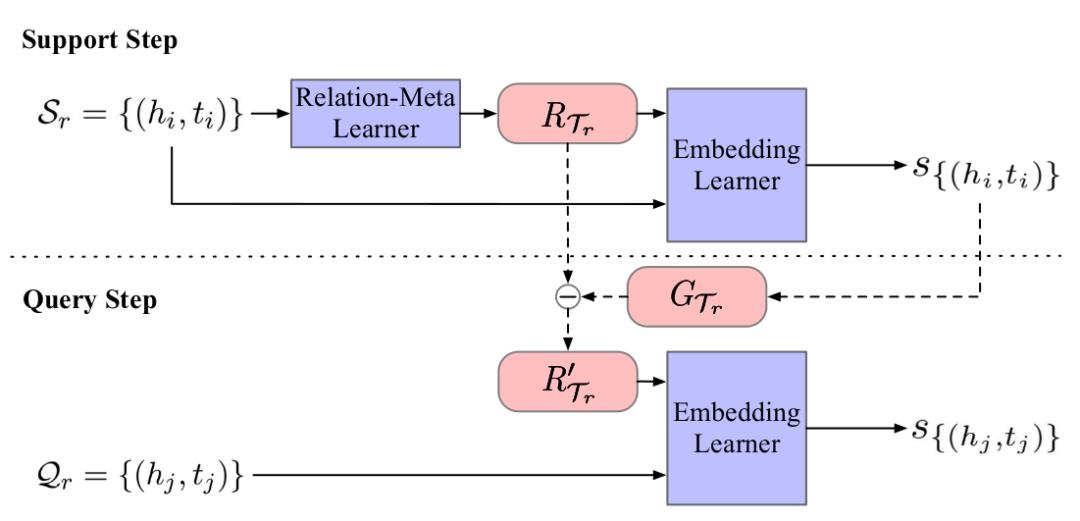
式1为基于头实体向量h与尾实体向量t通过全连接网络得到的关系向量R(hi, ti)。本篇论文通过与TransE相同的方式,即计算头实体、关系向量与尾实体的距离之模得到实体关联分数。损失函数由式4的合页损失函数得出,其中ti'为与hi不关联的实体。
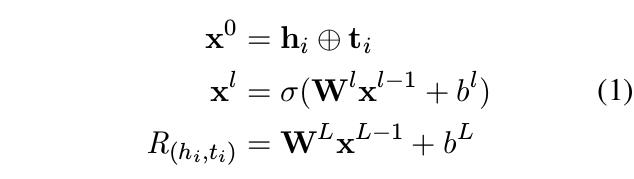
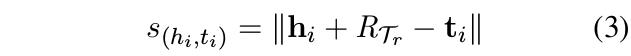
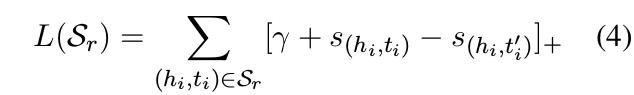
头实体与尾实体的关系模型通过基于L(Sr)的梯度GTr进行更新(式5)。通过式6,模型在每一个任务中进行精调。在查询集中,模型通过与支撑集相同的方式(式3-4)进行损失函数计算。在元学习训练中,元学习损失通过将所有任务上的查询集损失相加得到总体损失并优化元学习网络。
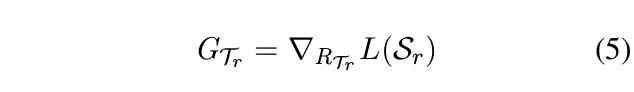
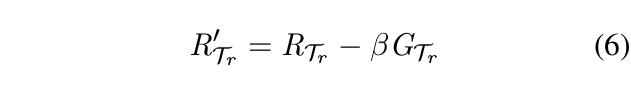
论文采用MRR, Hits@n衡量模型效果。由于少样本方面的已发表基准模型较少,论文仅比较了GMatching模型,对比两者在少样本学习方面的效果的优越性。文章针对NELL图谱与Wiki图谱进行了实验,并取得了较好结果。
最后打个小广告:
中国科学院深圳先进技术研究院自然语言处理组正在招收实习/硕士/博士同学,对NLP感兴趣的同学请发送简历至min.yang@siat.ac.cn噢!
We (NLP team at SIAT, Chinese Academy of Sciences) are hiring a few intern/master/PhD students. Send a resume to min.yang@siat.ac.cn if interested.
以上是关于元学习与自然语言处理的主要内容,如果未能解决你的问题,请参考以下文章
《深入浅出Python机器学习(段小手)》PDF代码+《推荐系统与深度学习》PDF及代码+《自然语言处理理论与实战(唐聃)》PDF代码源程序
CMU大学2019神经网络与自然语言处理NLP课程高清完整资源
分享《自然语言处理理论与实战》PDF及代码+唐聃+《深入浅出Python机器学习》PDF及代码+段小手+《深度学习实践:计算机视觉》PDF+缪鹏+《最优化理论与算法第2版》高清PDF+习题解答PDF+