Span 抽取和元学习能碰撞出怎样的新火花,小样本实体识别来告诉你!
Posted 阿里云云栖号
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Span 抽取和元学习能碰撞出怎样的新火花,小样本实体识别来告诉你!相关的知识,希望对你有一定的参考价值。
近日,阿里云机器学习平台PAI与华东师范大学高明教授团队、达摩院机器智能技术NLP团队合作在自然语言处理顶级会议EMNLP2022上发表基于Span和元学习的小样本实体识别算法SpanProto。这是一种面向命名实体识别的小样本学习算法,采用两阶段的训练方法,检测文本中最有可能是命名实体的Span,并且准确判断其实体类型,在仅需要标注极少训练数据的情况下,提升预训练语言模型在命名实体识别任务上的精度。
论文:
Jianing Wang, Chengyu Wang, Chuanqi Tan, Minghui Qiu, Songfang Huang, Jun Huang, Ming Gao. SpanProto: A Two-stage Span-based Prototypical Network For Few-shot Named Entity Recognition. EMNLP 2022
背景
大规模预训练语言模型的广泛应用,促进了NLP各个下游任务准确度大幅提升,然而,传统的自然语言理解任务通常需要大量的标注数据来微调预训练语言模型。例如,对于命名实体识别任务,模型的训练需要一定数量的语料来学习Token与Label之间的依赖关系。但是在实际应用中,标注数据资源比较稀缺,传统的序列标注方法很难达到较好的效果,因为其需要解决实体识别中的标签依赖(Label Depnedency)关系,同时也无法应对实体嵌套(Nested Entity)问题。因此,我们研究一种基于Span和元学习的小样本实体识别技术。特别地,我们关注于解决N-way K-shot的实体识别场景。下图所展示了一个2-way 1-shot实体识别任务:

在上述2-way 1-shot任务中,包含了若干个Support Set和Query Set,每个Support Set只包含2个类别的实体(即上图的PER和LOC,除了非实体的“O”类别),且每个类别的标注实体数量只有1个。
算法概述
为了解决上述小样本命名实体识别问题,SpanProto采用两阶段方法,即将实体识别任务分解为两个阶段,分别是Span Extraction和Mention Classification。模型框架图如下所示:

Span Extraction
首先,SpanProto使用与类别无关的Span抽取器,抽取出可能的命名区间。在这个工作中,我们参考了Baffine Decoder和Global Pointer的技术,设计了Global Boundary Matrix,显式让模型学习到实体区间的边界信息。在这个Matrix中,每一个坐标元素(i, j)恰好可以表示一个区间[i:j],如果这个区间是一个实体,那么元素将对应于1,如果这个区间不是一个实体,那么元素将对应于0:

Span Extraction模型采用下述基于Span的Cross-Entropy损失函数进行训练:

通过上述模型,SpanProto可以利用Global Boundary Matrix抽取出所有可能的实体。
Mention Classification
在Mention Classification模块中,SpanProto采用标准的Prototypical Learning技术给每个Span分配标签,即最小化每个Span表征与对应类别的原型的欧式距离。与此同时,我们考虑到命名实体识别的False Positive问题,即存在一些抽取的Span在当前Episode内没有合适的类别可以分配的情况。例如,在上图中,Span Extraction阶段模型会抽取出August 15. 1954为一个Span,它可能是一个“Time”类别的实体,但是在当前episode任务中其实只有PER和LOC,没有合适的标签给到这个Span。针对False Positive,我们采用Margin Learning方法,最大化这些Span表征与所有实体类别的原型向量的欧式距离:

整体算法流程
SpanProto整体算法流程图如图所示:

算法精度评测
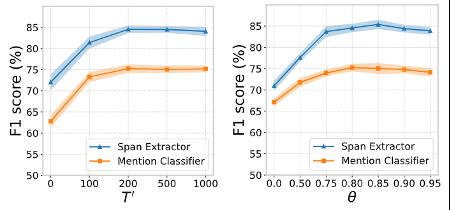
为了验证SpanProto算法的有效性,我们在Few-NERD这一标准评测数据集上进行了测试,效果证明SpanProto对精度提升明显:

我们也对算法的模块进行了详细有效性分析,我们可以发现Span Extraction和Mention Classification均对模型有一定贡献。

为了更好地服务开源社区,SpanProto算法的源代码即将贡献在自然语言处理算法框架EasyNLP中,欢迎NLP从业人员和研究者使用。
EasyNLP开源框架:https://github.com/alibaba/EasyNLP
参考文献
- Chengyu Wang, Minghui Qiu, Taolin Zhang, Tingting Liu, Lei Li, Jianing Wang, Ming Wang, Jun Huang, Wei Lin. EasyNLP: A Comprehensive and Easy-to-use Toolkit for Natural Language Processing. EMNLP 2022 (accepted)
- Juntao Yu, Bernd Bohnet, Massimo Poesio. Named Entity Recognition as Dependency Parsing. ACL 2020: 6470-6476
- Ning Ding, Guangwei Xu, Yulin Chen, Xiaobin Wang, Xu Han, Pengjun Xie, Haitao Zheng, Zhiyuan Liu. Few-NERD: A Few-shot Named Entity Recognition Dataset. ACL/IJCNLP 2021: 3198-3213
- GlobalPointer:用统一的方式处理嵌套和非嵌套NER. https://spaces.ac.cn/archives/8373
论文信息
论文名字:SpanProto: A Two-stage Span-based Prototypical Network For Few-shot Named Entity Recognition
论文作者:王嘉宁、汪诚愚、谭传奇、邱明辉、黄松芳、黄俊、高明
论文pdf链接:https://arxiv.org/abs/2210.09049
本文为阿里云原创内容,未经允许不得转载
以上是关于Span 抽取和元学习能碰撞出怎样的新火花,小样本实体识别来告诉你!的主要内容,如果未能解决你的问题,请参考以下文章
知识图谱深度学习AutoML,推荐系统与新技术结合将碰撞出怎样的火花?
当 RocketMQ 遇上 Serverless,会碰撞出怎样的火花?