自然语言处理历史最全预训练模型(部署)汇集分享
Posted 深度学习与NLP
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了自然语言处理历史最全预训练模型(部署)汇集分享相关的知识,希望对你有一定的参考价值。
什么是预训练模型?
预练模型是其他人为解决类似问题而创建的且已经训练好的模型。代替从头开始建立模型来解决类似的问题,我们可以使用在其他问题上训练过的模型作为起点。预训练的模型在相似的应用程序中可能不是100%准确的。
本文整理了自然语言处理领域各平台中常用的NLP模型,常见平台包括Tensorflow、Keras、Pytorch、MXNet、Caffe。分享给需要的朋友。
点击文末阅读原文,获取预训练模型下载链接。
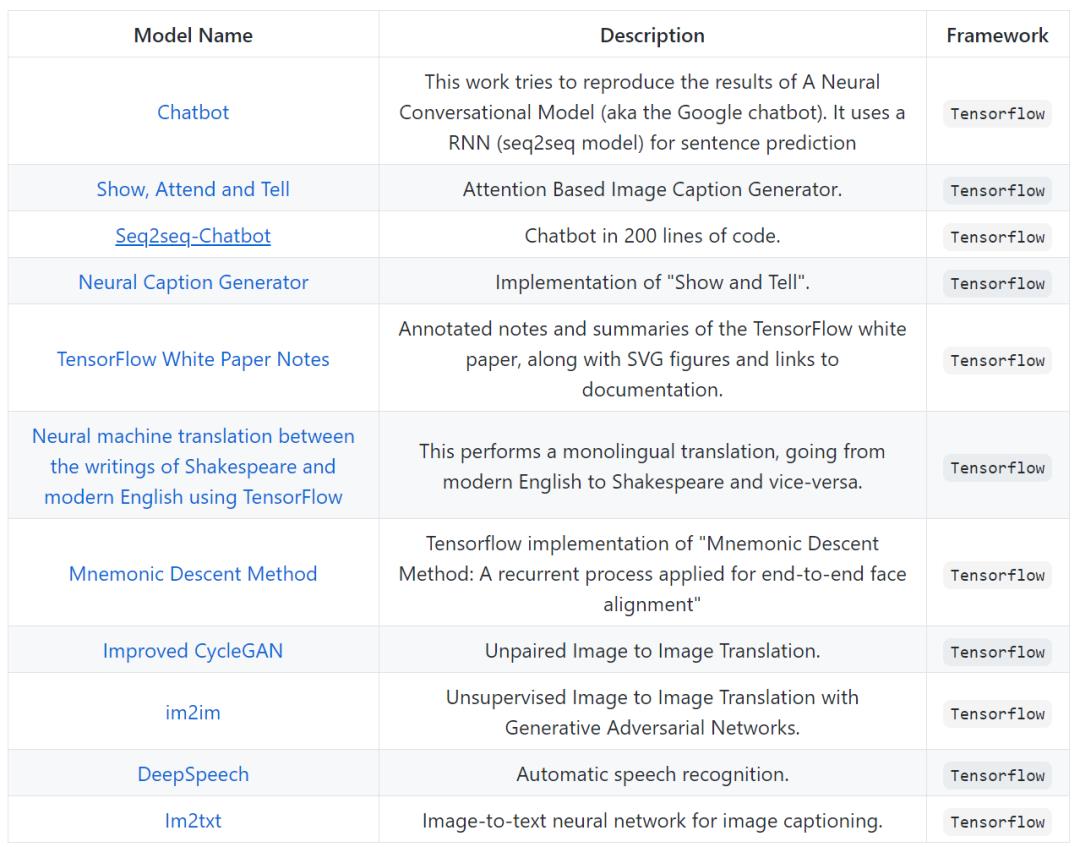
Tensorflow
Keras

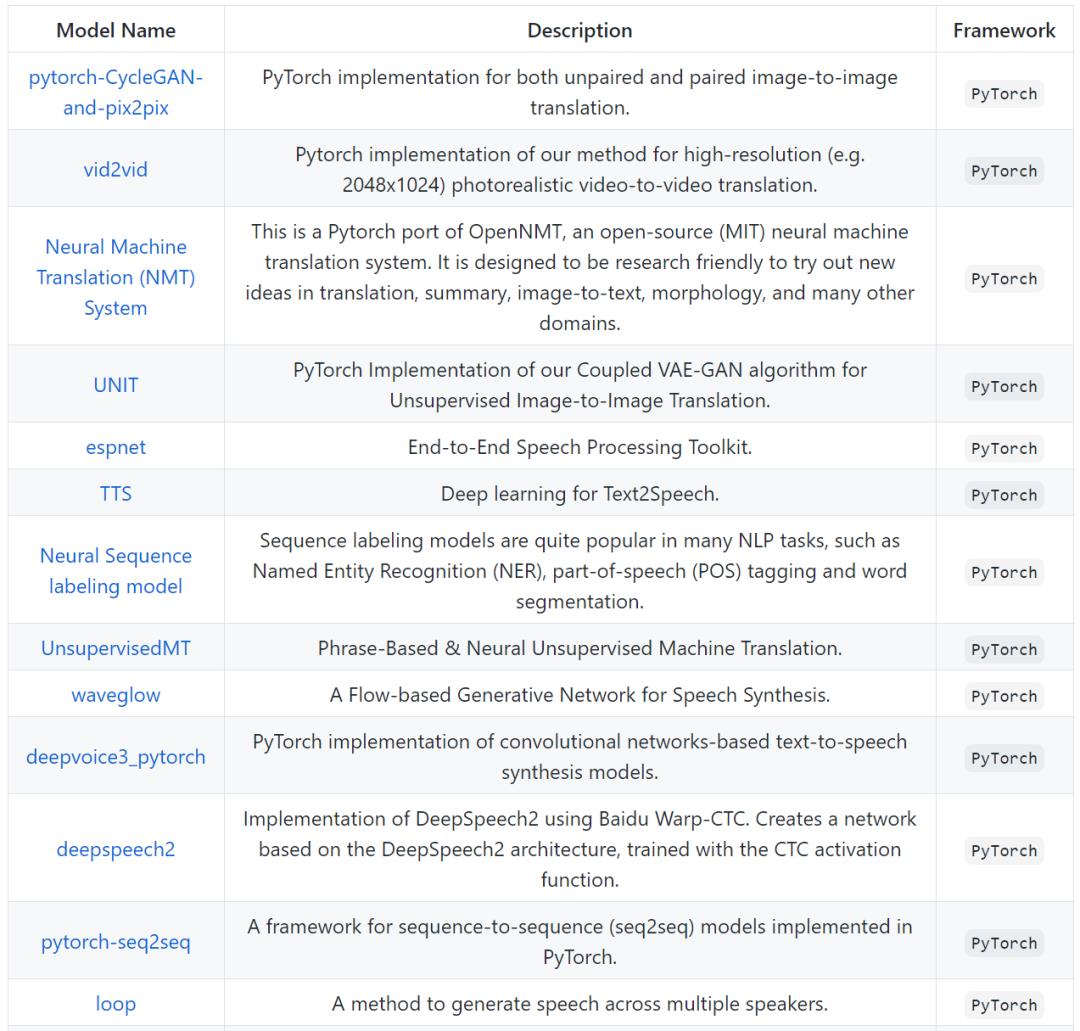
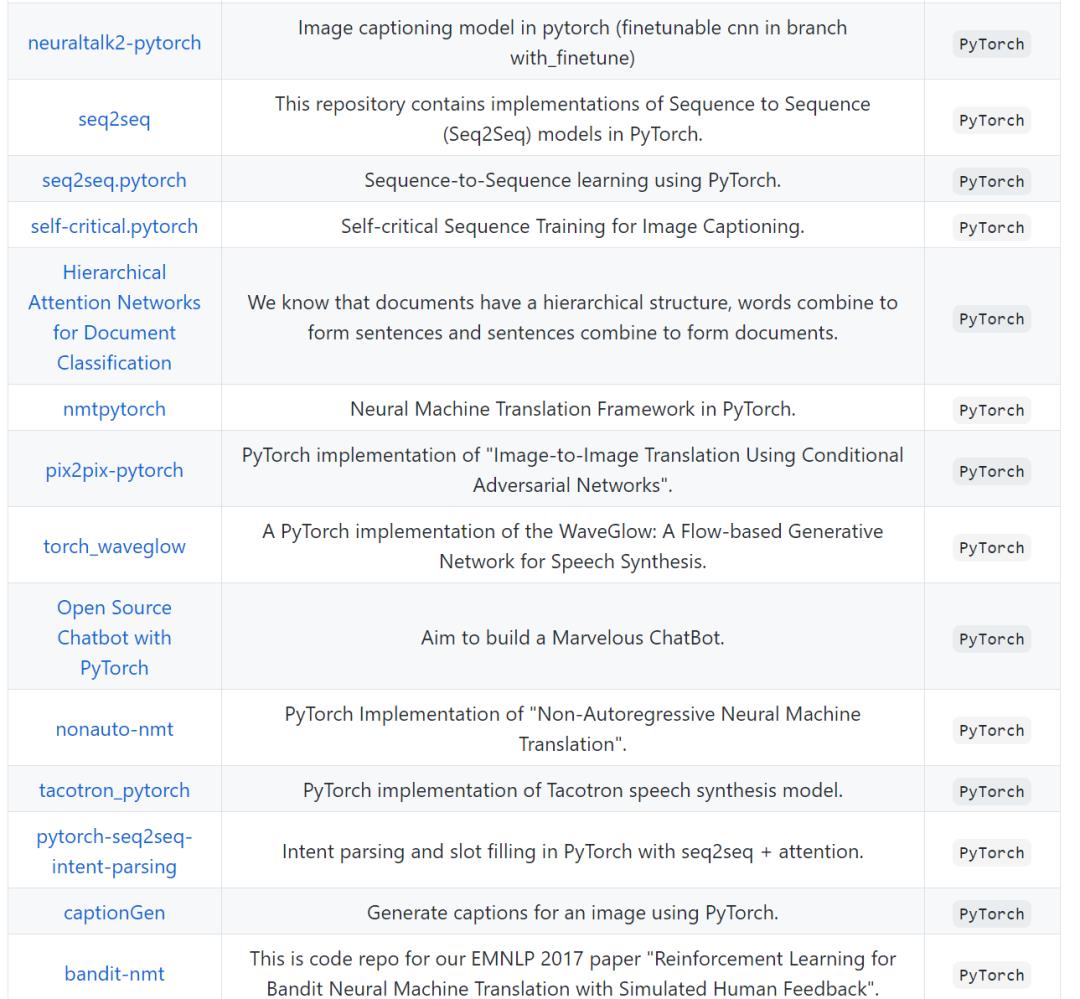
Pytorch
MXNet

Caffe

往期精品内容推荐



DeepLearning_NLP

深度学习与NLP
以上是关于自然语言处理历史最全预训练模型(部署)汇集分享的主要内容,如果未能解决你的问题,请参考以下文章