最全中文自然语言处理数据集平台和工具整理
Posted 深度学习自然语言处理
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了最全中文自然语言处理数据集平台和工具整理相关的知识,希望对你有一定的参考价值。
阅读大概需要9分钟
跟随小博主,每天进步一丢丢
来自:深度学习与NLP
资源整理了文本分类、实体识别&词性标注、搜索匹配、推荐系统、指代消歧、百科数据、预训练词向量or模型、中文完形填空等大量数据集,中文数据集平台和NLP工具等。
本文内容整理自:https://github.com/InsaneLife/ChineseNLPCorpus
文本分类
新闻分类
今日头条中文新闻(短文本)分类数据集 :https://github.com/fateleak/toutiao-text-classfication-dataset
数据规模:共38万条,分布于15个分类中。
采集时间:2018年05月。
以0.7 0.15 0.15做分割 。
清华新闻分类语料:
根据新浪新闻RSS订阅频道2005~2011年间的历史数据筛选过滤生成。
数据量:74万篇新闻文档(2.19 GB)
小数据实验可以筛选类别:体育, 财经, 房产, 家居, 教育, 科技, 时尚, 时政, 游戏, 娱乐
http://thuctc.thunlp.org/#%E8%8E%B7%E5%8F%96%E9%93%BE%E6%8E%A5
rnn和cnn实验:https://github.com/gaussic/text-classification-cnn-rnn
中科大新闻分类语料库:http://www.nlpir.org/?action-viewnews-itemid-145
情感/观点/评论 倾向性分析
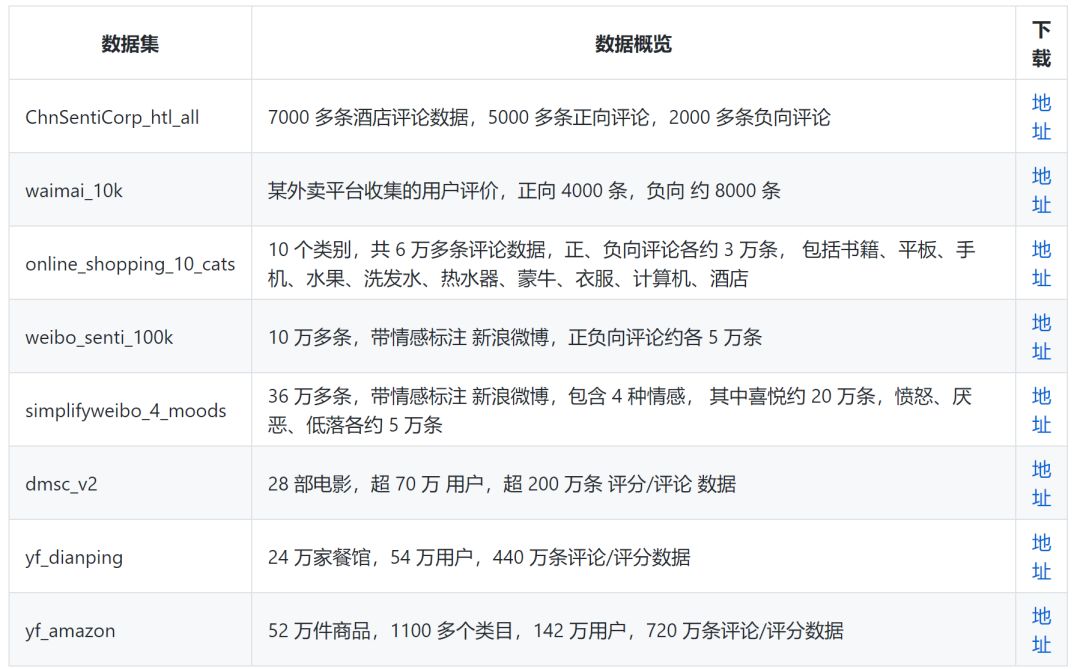
实体识别&词性标注
微博实体识别
https://github.com/hltcoe/golden-horse
boson数据
包含6种实体类型。
https://github.com/InsaneLife/ChineseNLPCorpus/tree/master/NER/boson
人民日报数据集
人名、地名、组织名三种实体类型
1998:https://github.com/InsaneLife/ChineseNLPCorpus/tree/master/NER/renMinRiBao
2004:https://pan.baidu.com/s/1LDwQjoj7qc-HT9qwhJ3rcA password: 1fa3
MSRA微软亚洲研究院数据集
5 万多条中文命名实体识别标注数据(包括地点、机构、人物)
https://github.com/InsaneLife/ChineseNLPCorpus/tree/master/NER/MSRA
SIGHAN Bakeoff 2005:一共有四个数据集,包含繁体中文和简体中文,下面是简体中文分词数据。
MSR: http://sighan.cs.uchicago.edu/bakeoff2005/
PKU :http://sighan.cs.uchicago.edu/bakeoff2005/
搜索匹配
OPPO手机搜索排序
OPPO手机搜索排序query-title语义匹配数据集。
链接:https://pan.baidu.com/s/1Hg2Hubsn3GEuu4gubbHCzw 提取码:7p3n
网页搜索结果评价(SogouE)
用户查询及相关URL列表
https://www.sogou.com/labs/resource/e.php
推荐系统
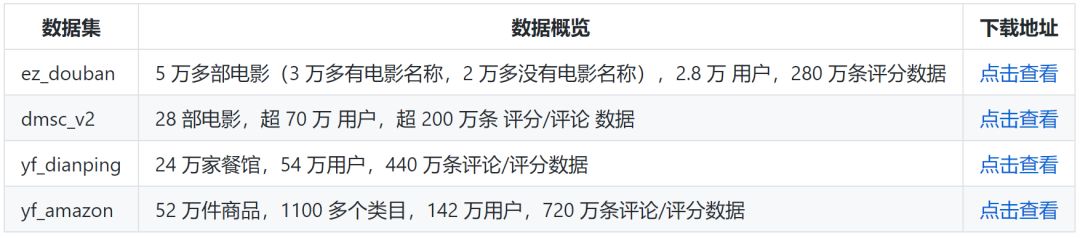
百科数据
维基百科
维基百科会定时将语料库打包发布:
数据处理博客
https://dumps.wikimedia.org/zhwiki/
百度百科
只能自己爬,爬取得链接:https://pan.baidu.com/share/init?surl=i3wvfil提取码 neqs 。
指代消歧
CoNLL 2012 :http://conll.cemantix.org/2012/data.html
预训练:(词向量or模型)
BERT
开源代码:https://github.com/google-research/bert
模型下载:BERT-Base, Chinese: Chinese Simplified and Traditional, 12-layer, 768-hidden, 12-heads, 110M parameters
ELMO
开源代码:https://github.com/allenai/bilm-tf
预训练的模型:https://allennlp.org/elmo
腾讯词向量
腾讯AI实验室公开的中文词向量数据集包含800多万中文词汇,其中每个词对应一个200维的向量。
上百种预训练中文词向量
https://github.com/Embedding/Chinese-Word-Vectors
中文完形填空数据集
https://github.com/ymcui/Chinese-RC-Dataset
中华古诗词数据库
最全中华古诗词数据集,唐宋两朝近一万四千古诗人, 接近5.5万首唐诗加26万宋诗. 两宋时期1564位词人,21050首词。
https://github.com/chinese-poetry/chinese-poetry
保险行业语料库
https://github.com/Samurais/insuranceqa-corpus-zh
汉语拆字字典
英文可以做char embedding,中文不妨可以试试拆字
https://github.com/kfcd/chaizi
中文数据集平台
搜狗实验室
搜狗实验室提供了一些高质量的中文文本数据集,时间比较早,多为2012年以前的数据。
https://www.sogou.com/labs/resource/list_pingce.php
中科大自然语言处理与信息检索共享平台
http://www.nlpir.org/?action-category-catid-28
中文语料小数据
包含了中文命名实体识别、中文关系识别、中文阅读理解等一些小量数据。
https://github.com/crownpku/Small-Chinese-Corpus
维基百科数据集
https://dumps.wikimedia.org/
NLP工具
THULAC:https://github.com/thunlp/THULAC :包括中文分词、词性标注功能。
HanLP:https://github.com/hankcs/HanLP
哈工大LTP: https://github.com/HIT-SCIR/ltp
NLPIR: https://github.com/NLPIR-team/NLPIR
jieba分词: https://github.com/yanyiwu/cppjieba
下载一:中文版!学习TensorFlow、PyTorch、机器学习、深度学习和数据结构五件套!



后台回复【五件套】
下载二:南大模式识别PPT

后台回复【南大模式识别】
说个正事哈
由于微信平台算法改版,公号内容将不再以时间排序展示,如果大家想第一时间看到我们的推送,强烈建议星标我们和给我们多点点【在看】。星标具体步骤为:
(2)点击右上角的小点点,在弹出页面点击“设为星标”,就可以啦。
感谢支持,比心 。
。
投稿或交流学习,备注:昵称-学校(公司)-方向,进入DL&NLP交流群。
方向有很多:机器学习、深度学习,python,情感分析、意见挖掘、句法分析、机器翻译、人机对话、知识图谱、语音识别等。
记得备注呦
整理不易,还望给个在看!
以上是关于最全中文自然语言处理数据集平台和工具整理的主要内容,如果未能解决你的问题,请参考以下文章