自然语言处理481个公开数据集和基准任务整理分享
Posted 深度学习与NLP
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了自然语言处理481个公开数据集和基准任务整理分享相关的知识,希望对你有一定的参考价值。
自然语言处理( Natural Language Processing, NLP)以语言为对象,利用计算机技术来分析、理解和处理自然语言的一门学科,即把计算机作为语言研究的强大工具,在计算机的支持下对语言信息进行定量化的研究,并提供可供人与计算机之间能共同使用的语言描写。包括自然语言理解( NaturalLanguage Understanding, NLU)和自然语言生成( Natural LanguageGeneration, NLG)两部分。
自然语言处理包含很多子任务,比如中文自动分词(Chinese word segmentation),词性标注(Part-of-speech tagging),句法分析(Parsing),自然语言生成(Natural language generation),文本分类(Text categorization),信息检索(Information retrieval),信息抽取(Information extraction),文字校对(Text-proofing),问答系统(Question answering),机器翻译(Machine translation),自动摘要(Automatic summarization),文字蕴涵(Textual entailment)等等。
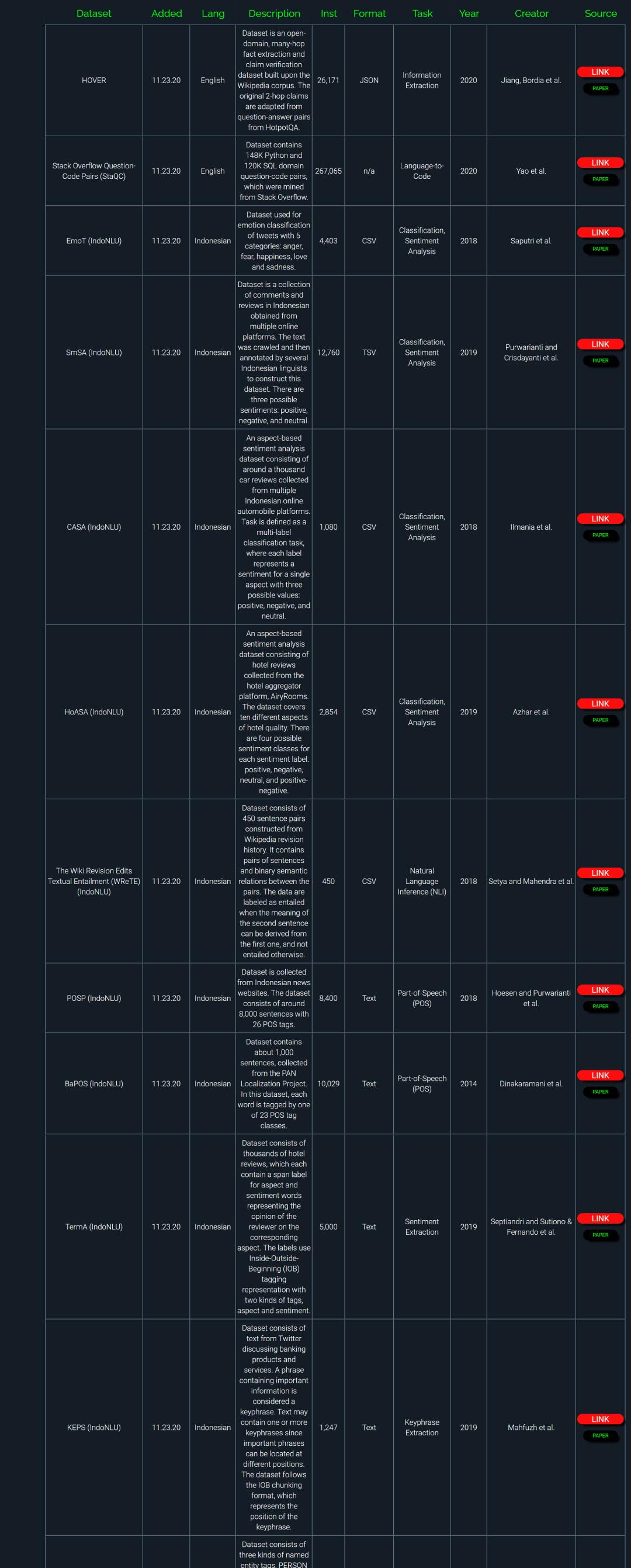
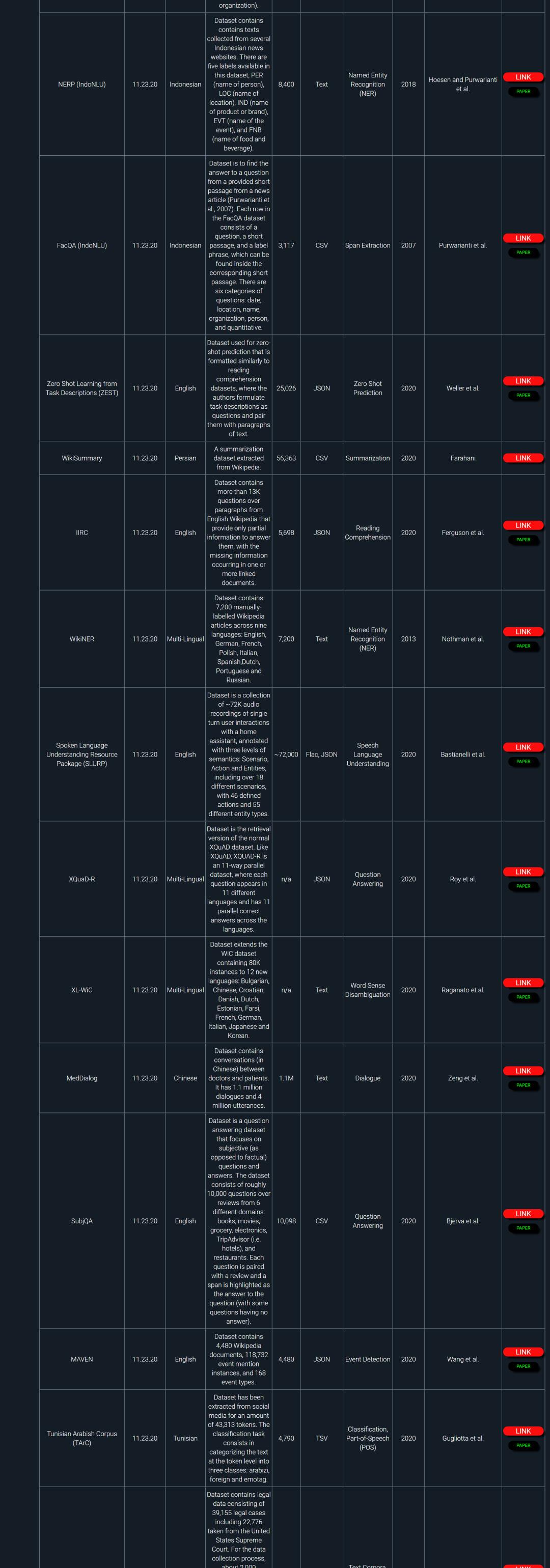
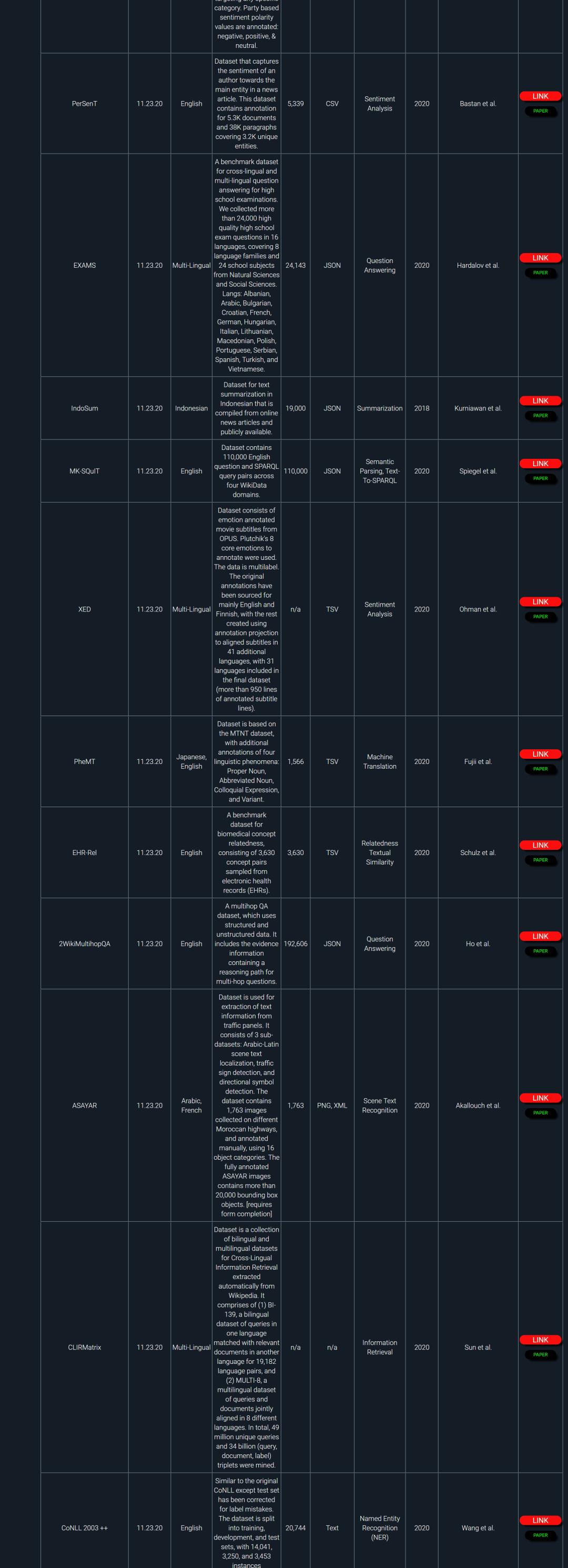
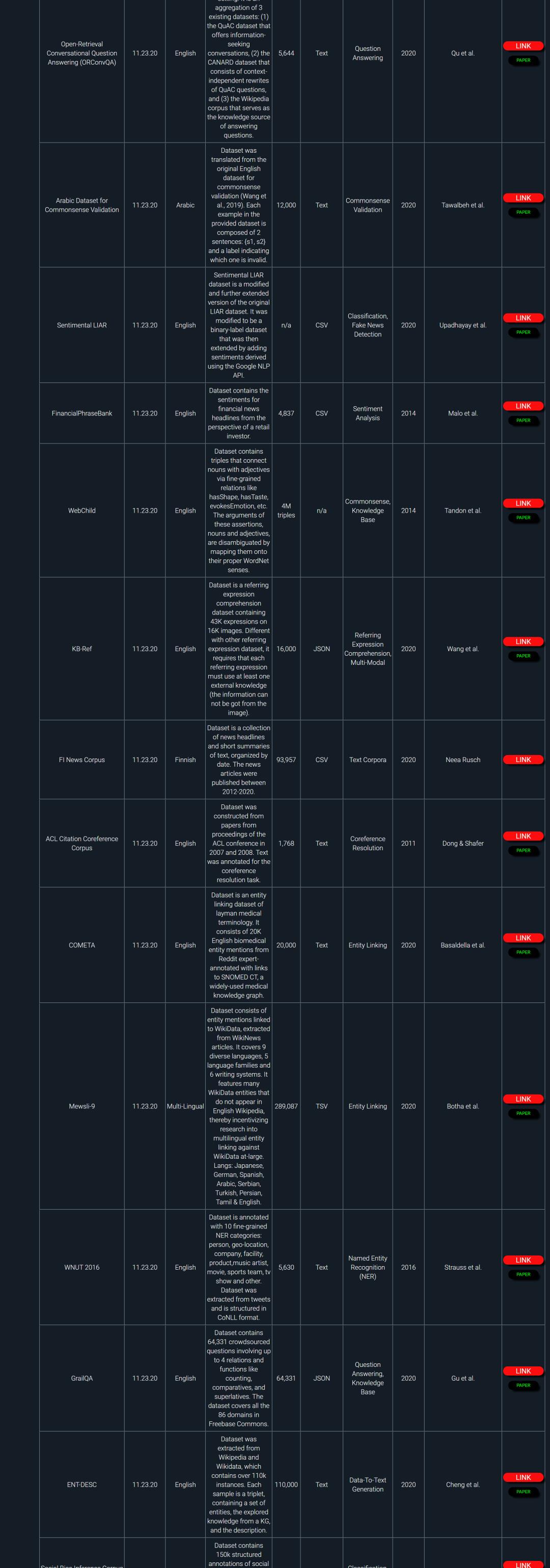
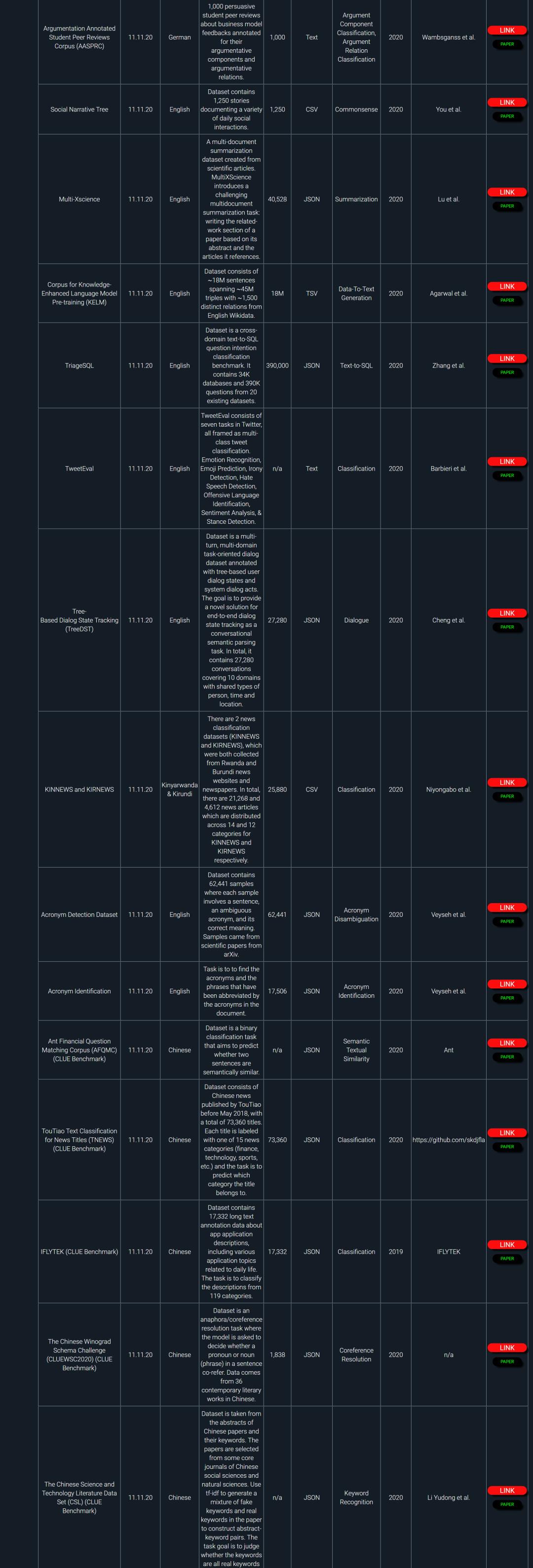
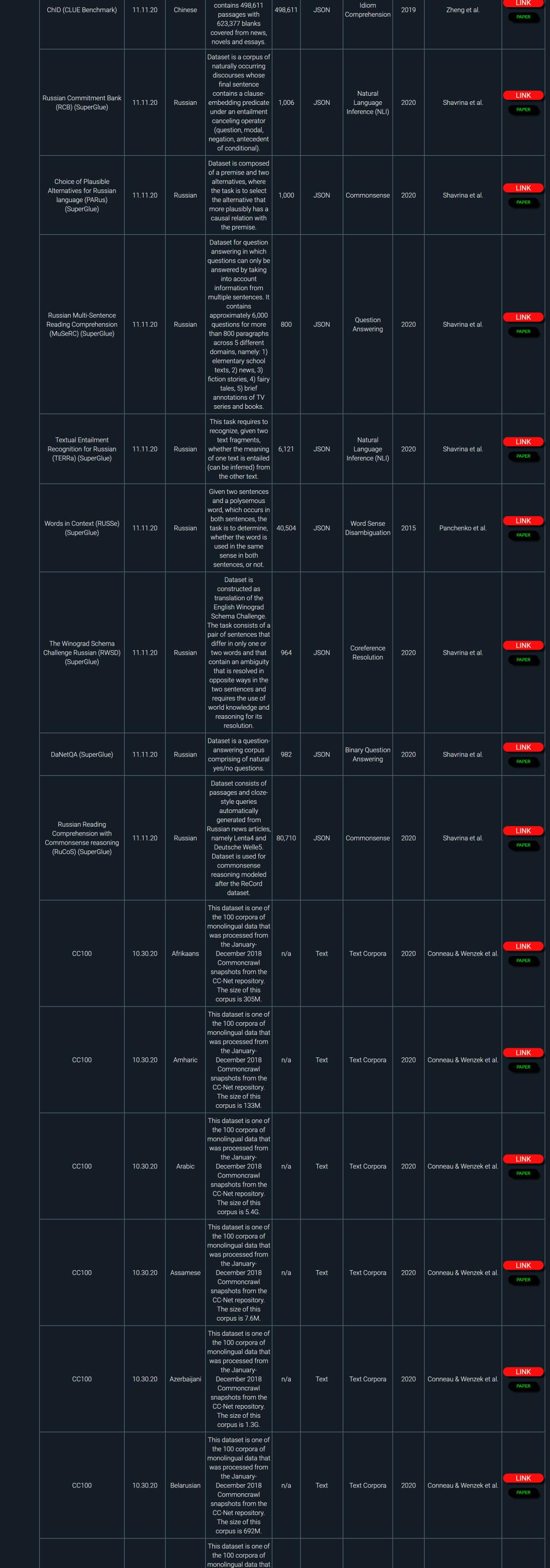
NLP领域非常多,同时又非常多公开数据集和基准任务。本资源整理了大概481个最新的自然语言处理公开数据集和基准任务。
部分数据截图


DeepLearning_NLP

深度学习与NLP
以上是关于自然语言处理481个公开数据集和基准任务整理分享的主要内容,如果未能解决你的问题,请参考以下文章