数据结构之布隆过滤器
Posted 程序猿技术
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据结构之布隆过滤器相关的知识,希望对你有一定的参考价值。
数据结构之布隆过滤器
您可能从未听说过Bloom Filter,但是这个巧妙的算法在Google的BigTable数据库中使用,以节省时间,无需搜索不存在的数据。
在编程中,也许在生活中,有一些众所周知的权衡。您通常可以将空间交换一段时间,因为您可以通过更多的存储空间来解决问题,您可以更快地运行空间。还有一个鲜为人知的权衡,它更为复杂。一般来说,您可以确定时间。这是许多随机算法的基础,其中返回的解决方案不确定,但与相同数量的确定性计算相比,它是快速的。
这些想法吸引了许多程序员,他们为了自己的利益而完全被算法研究所吸引,但他们也有实际的应用。以Bloom Filter当前热门话题为例。这可能听起来像一个创意摄影师可能会放在镜头前的东西,但它实际上是一个有趣的算法混合空间和确定性的时间交易。它可以告诉您是否在超快速时间之前看过某个特定的数据项 - 但它可能是错的!
Google的BigTable数据库使用Bloom过滤器来减少对尚未存储的数据行的查找。Squid代理服务器使用一个来避免查找不在缓存中的东西等等......


Burton Bloom于1970年发明的算法非常简单,但仍然很巧妙。它依赖于使用许多不同的散列函数。
哈希函数是一种函数,它将获取一个数据项并对其进行处理以生成值或键。例如,您可以简单地为字符串中的每个字符添加代码值,并将结果mod返回给定值。散列函数总是从相同的数据生成相同的散列值,但实际上通常可以为两个不同的数据值生成相同的散列值。也就是说,哈希值对于给定的数据项不是唯一的,并且您无法反转哈希函数来获取数据值。哈希函数是多个确定性函数。良好的散列函数还具有其他所需的属性,例如在输出范围内尽可能均匀地散布获得的散列值,但暂时只关注基本散列函数。
Bloom过滤器以位阵列Bloom [i]初始化为零开始。要记录数据值,您只需计算k个不同的散列函数,并将生成的k值作为索引处理到数组中,并将每个k数组元素设置为1.对于遇到的每个数据项重复此操作。
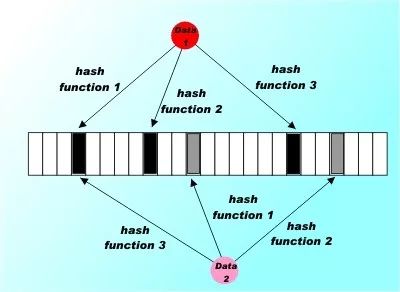
在这种情况下,三个散列函数用于为每个数据项设置位数组中的三个元素。请注意,如图所示,这两个数据项都设置了第4个元素。
现在假设一个数据项出现了,你想知道你以前是否已经看过它。您所要做的就是应用k哈希函数并查找指示的数组元素。如果它们中的任何一个为零,您可以100%确定您之前从未遇到过该项目 - 如果您将该位设置为1。
但是,即使所有这些都是一个,您也不能断定之前已经看过数据项,因为所有位都可以由应用于多个其他数据项的k个哈希函数设置。您可以得出的结论是,您之前可能遇到过数据项。
请注意,无法从Bloom过滤器中删除项目。原因很简单,您不能取消设置似乎属于数据项的位,因为它也可能由另一个数据项设置。
如果位阵列大部分是空的,即设置为零并且k个散列函数彼此独立,那么假阳性的概率,即当我们实际上没有时看到我们已经看到数据项的概率很低。
例如,如果只设置k位,您可以得出结论,误报的概率非常接近于零,因为唯一的错误可能性是您输入的数据项产生相同的k哈希值 - 这不太可能哈希函数是独立的。
随着位阵列填满,假阳性的概率逐渐增加。当然,当位阵列已满时,查询的每个数据项被识别为之前已被看到。因此,您可以清楚地交换空间以获得准确性和时间。
有趣的是,Bloom过滤器还可以交换空间精度。如果你认为存储一个n字节字符串需要n个字节,那么在Boom过滤器中它只需要k位和k个比较,但是有可能存在误报。随着k增加,所需的存储量随着比较次数的增加而增加,并且假阳性的可能性降低。
与任何最佳值的权衡情况一样。近似假阳性(即错误)率是:
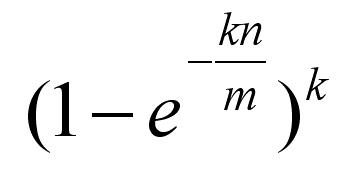
其中k是散列函数的数量,m是位数组的大小,n是存储在位数组中的项数。
使用它可以计算给定m和n的最优k,即:
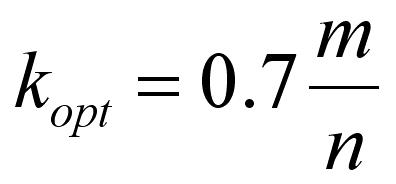
因此,例如,如果位数组有1000个元素,并且您已经存储了10个数据项,则最佳k为70.您还可以计算出位数组的大小,以便为固定n提供任何所需的错误概率(假设最佳k):
![]()
因此,例如,如果您要存储10个数据项并且希望误报的概率大约为0.001,则需要一个包含大约138个元素且ak大约为10的数组。
一个更现实的例子是,当你存储100,000个项目并且需要假阳性的概率大约为0.000001时,你需要一个存储大约350K字节且k大约为20的数组。
为了确保您遵循Bloom过滤器实际工作的方式,让我们在C#中实现一个简单的版本。这不是生产版本,当然也没有优化。优化很大程度上取决于您使用它的原因。这个实现的作用是将注意力集中在实现一个好的Bloom过滤器的一些困难上。
第一个简单性是,我们可以使用提供的BitArray对象而不是自定义制作位数组。这可以在Collections命名空间中找到:
using System.Collections;
我们还可以创建一个Bloom过滤器类:
class Bloom
{
const int m = 1000;
const int k = 5;
BitArray bloom = new BitArray(m);
常量m和k设置位数组的大小和要使用的散列函数的数量。
在我们可以做任何其他事情之前,我们需要解决找到k哈希函数的问题。这很难,因为找到一个哈希函数很难找到k非常难。幸运的是,有许多简单的方法可以解决问题。首先,我们可以使用内置于每个字符串中的内置GetHashCode方法。虽然这不太可能被优化,但它应该足以用于哈希存储。
这给了我们一个哈希函数。生成k-1的最简单方法是使用哈希值作为随机数生成器的种子,并使用下一个k-1随机数作为附加哈希值。这并不理想,并且在实践中它倾向于产生布隆过滤器,其在误报方面与使用k / 2真实哈希值一样好。
完成几乎同样有效的工作的另一种方法是生成两个独立的散列值h0和h1,然后形成:
h[k]=h0+i*h1;
对于i = 2 ,,, k-1。这很容易但它需要两个独立的散列函数,这意味着必须在C#中实际编写一个。
查找k哈希值的简单随机数解决方案非常容易实现:
private int[] hashk(string s, int k)
{
int[] hashes = new int[k];
hashes[0] = Math.Abs(s.GetHashCode());
Random R = new Random(hashes[0]);
for (int i = 1; i < k; i++)
{
hashes[i] = R.Next();
}
return hashes;
}
当方法返回时,我们在准备使用的int数组中有k个哈希值。
Bloom类还需要另外两种方法。一个添加数据值:
public void AddData(string s)
{
int[] hashes = hashk(s, k);
for (int i = 0; i < k; i++)
{
bloom.Set(hashes[i] % m,true);
}
}
请注意BitArray使用Set方法将正确位置的位设置为true的方式,即为1或false,即0.当此方法返回时,哈希数组指示的所有位置都已设置为1。
最后一种方法是查找值以查看它是否已在过滤器中的方法:
public Boolean LookUp(string s)
{
int[] hashes = hashk(s, k);
for (int i = 0; i < k; i++)
{
if (bloom[hashes[i] % m] == false) return false;
}
return true;
}
这必须简单地扫描散列数组指示的位置,如果它们都是真的则返回true。请注意,唯一可以确定的是,如果找到错误的ie0 BitArray元素,那么您可以确定该字符串从未输入到过滤器中。
要尝试一下,你会做类似的事情:
Bloom MyBloom = new Bloom();
string data = "Hello Bloom Filter";
MyBloom.AddData(data);
并查找字符串:
string data = "Hello Bloom Filter";
MessageBox.Show(MyBloom.LookUp(data).ToString());
当然,在实际情况下,您会添加大量数据并查找大量数据。
如果您打算使用Bloom过滤器,那么首先编写两个良好的独立散列函数是值得的。然而,你也想要使用更接近机器的C(如果不是汇编程序)来实现它,以便从中获得最终的性能下降。



15
以上是关于数据结构之布隆过滤器的主要内容,如果未能解决你的问题,请参考以下文章