什么是一致性hash算法
Posted 大数据和人工智能技术
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了什么是一致性hash算法相关的知识,希望对你有一定的参考价值。
在公众号回复课程,免费获取JAVA全栈课程
作者 | 颜 群
先简单回顾一下“什么是hash算法?”
简答的讲,hash算法就是一种 映射算法,用于将字符串、对象、图像等映射成一串数字,如下:
(本文用 hash(x) 代表 计算x的hash值)
hash("hello world") 结果:101011101
hash(person对象) 结果:111111101
hash(图片.png) 结果:100000001
一致性hash最初用于解决分布式缓存问题
先分析一下,如果不用一致性hash算法,分布式缓存会存在怎样的问题。假设某个后台服务器是由“服务器1”、“服务器2”和“服务器3”三台搭建的集群。
现在有a.png、b.png和c.png三张图片,如何让三张图片 和三个服务器建立起一一对应的关系?(暂不考虑使用 独立的缓存服务器 等解决方案)
具体的讲,如何才能保证,a.png永远只缓存在服务器1里(而不会缓存到服务器2或服务器3里)?其他同理,如图所示。
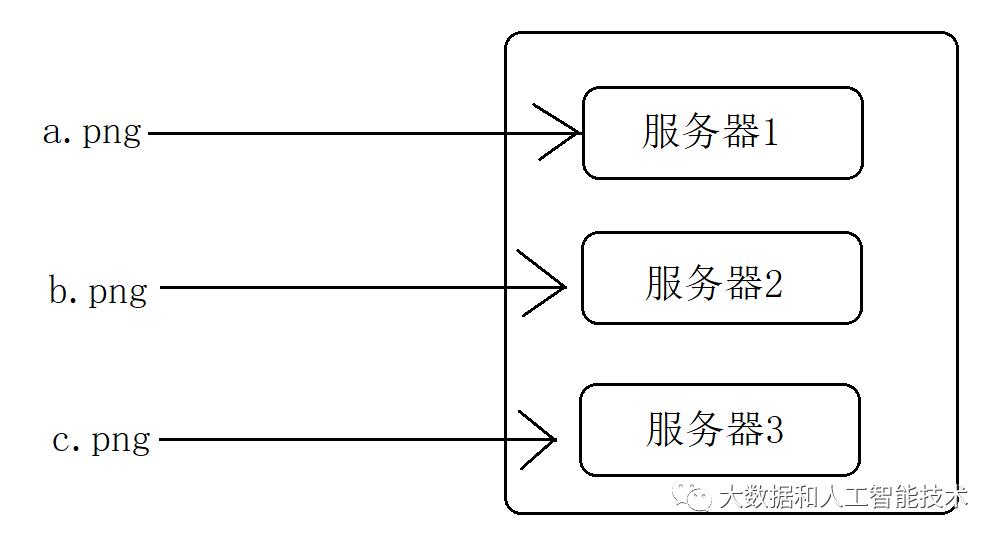
说明:这里只需要保证一对一关系即可,例如也可以让a.png映射到服务器2,唯一要保证的是:一旦映射建立后,就不能再改变指向。
一种很容易想到的办法就是:给图片和服务器分别做hash映射,如下。
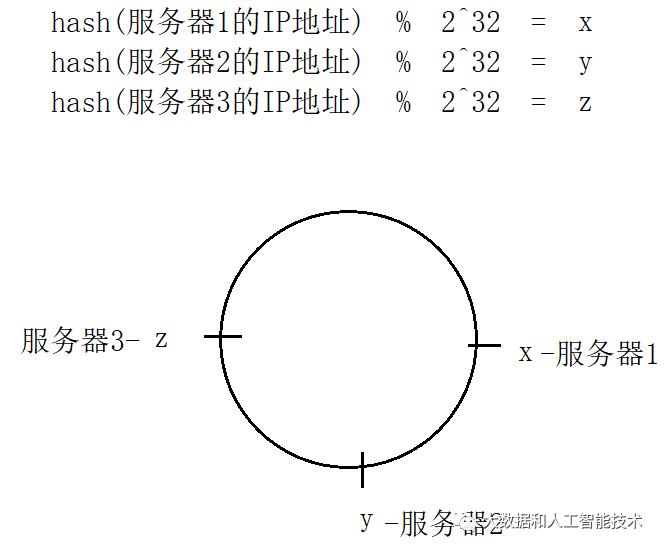
假设hash(a.png)的值是111,hash(b.png)的值是112,hash(c.png)的值是113 ;并用服务器的ip值计算 服务器的hash值,并假设hash(服务器1IP)的值是30, hash(服务器2IP)的值是31, hash(服务器3IP)的值是32。
之后,为了在三张图片 和 三个服务器之间建立起一对一的映射关系,就可以用他们的值求%3 (其中3是服务器的个数),如下。
a.png — 111 %3 = 0 = 30%3 — 服务器1
b.png — 112 %3 = 1 = 31%3 — 服务器2
c.png — 113 %3 = 2 = 32%3 — 服务器3
(注意,0代表服务器1、1代表服务器2……后文会用到)
至此就得到了映射关系:
a.png = 服务器1
b.png = 服务器2
c.png = 服务器3
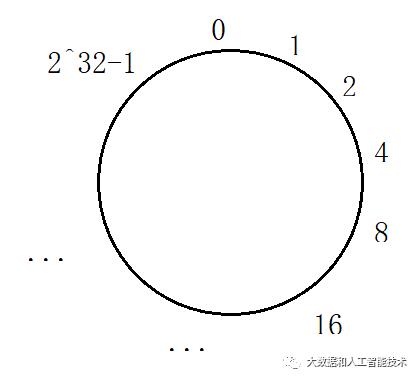
一致性hash的做法分为以下两步:
(1)计算服务器的hash值,即hash(服务器IP)
三个服务器映射后的情景,如下图。
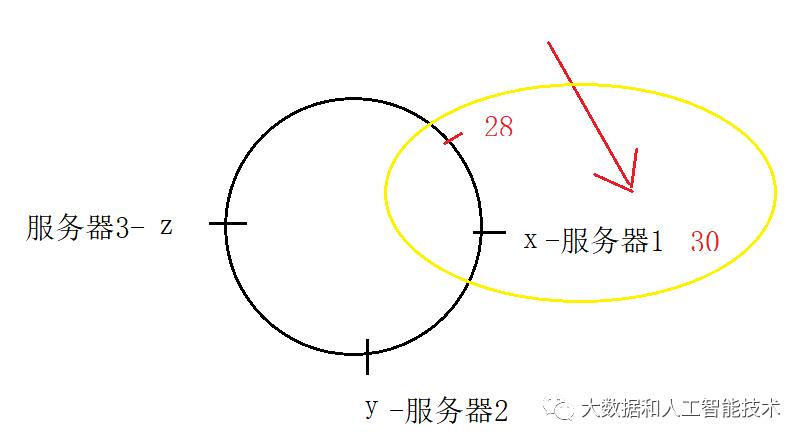
用了hash环之后,缓存的映射规则是:缓存数据的hash值,以顺时针的方向,映射到就近的服务器节点上。举个例子,假设x(服务器1)的值是30。如果现在要缓存的图片的hash值是28,(即 hash(图片)=28),那么在这个hash环上,28顺时针最近的点是30(即x点),因此就将这个图片缓存在x点表示的服务器1上,如下图。
同理,就可以将任何的数据缓存到服务器1、服务器2或者服务器3上了。
如果再增加一台服务器(服务器4),并假设服务器4对应在环上的Q点,如图。
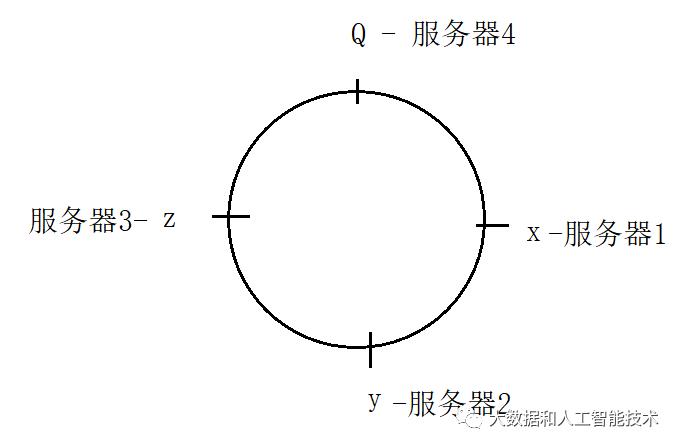
此时,原来的映射规则“大部分”都不会发生变化。例如,假设x是30,Q是25,那么原来的hash(图片)=28,根据“顺时针就近”的映射规则,仍然会映射到x点(即服务器1上),如图。
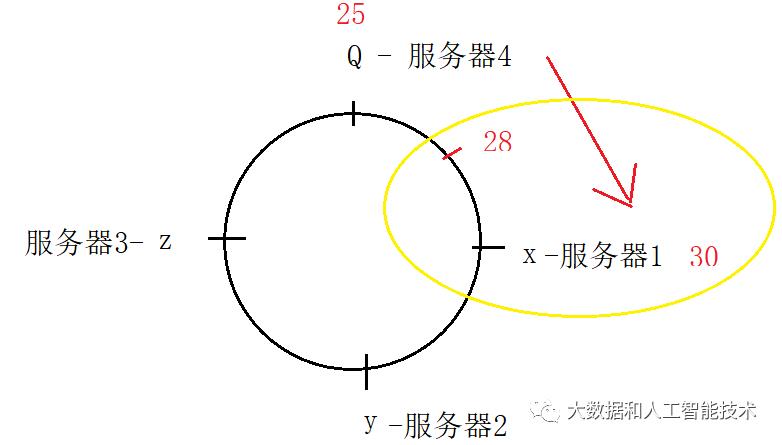
这样就解决了之前的问题:当服务器个数发生改变时,缓存仍然有效。例如,hash(图片)=28这个节点,在三个服务器和四个服务器的时候,都一定缓存在服务器1这个节点上。
以上就是一致性Hash的实现思路了。但还存在一个问题:hash倾斜。
假设x、y、z三个点的数字非常接近,那么这三个点将落在hash环上相近的位置,如图。
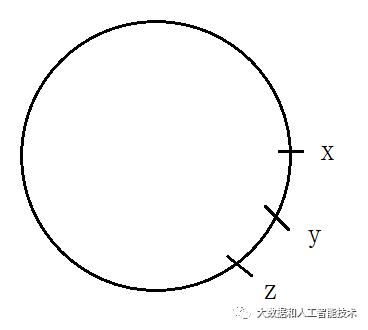
此时,根据“顺时针就近原则”,大部分的缓存将会映射到x点上,如图。
如果这样,那么x节点(即服务器1)将缓存大部分数据,而其他的y、z节点(即服务器2、服务器3)仅缓存非常少量的数据。这种在hash环上,各个节点缓存数据不均等的问题,就称为“hash倾斜”。
一种解决hash倾斜的做法就是:使用虚拟节点。即在环上生成多个 虚拟节点,后续 请求先找虚拟节点,然后再通过虚拟节点找到对应的真实节点。
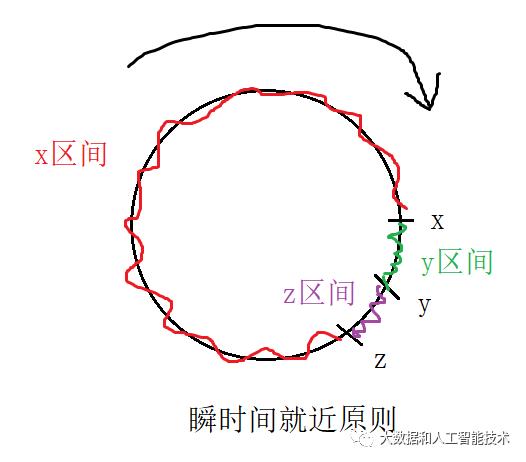
如下图,在hash环上均匀的设置虚拟节点x1、x2、x3....,y1、y2、y3...,z1、z2、z3...
虚拟节点和真实节点的映射关系是:
真实节点x ,对应于 x1、x2、x3 ...
真实节点y ,对应于 y1、y2、y3 ...
真实节点z ,对应于 z1、z2、z3 ...
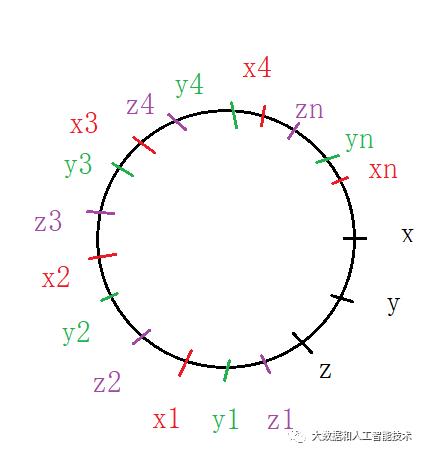
这样就可以均匀的将环分割成x区域、y区域、z区域三部分,也就是说:任何一个点,散落在x区域、y区域和z区域的概率是均等的。
之后,假设某一个缓存的数据落在了图中的M点。
那么根据 “顺时针就近原则”,该数据应该缓存在y3点。然后根据虚拟节点和真实节点的映射关系,可知y3会映射到y点上,所以选择y节点(即服务器2)缓存此数据。
简言之:hash(数据) -> 虚拟节点 ->真实节点
以上内容,如果还不明白,可以看以下的视频教程(从第50分钟20秒开始看)
- 完 -
推荐阅读
▲
在“大数据和人工智能技术”聊天对话框回复以下关键词,可获得相关信息哟
回复【资料】获取JAVA全栈视频的配套资料
回复【最新课程】获取一门尚未公开的高级课程(不定期更换)
回复【提问】获取免费答疑方式
回复【课程】获取JAVA全栈视频教程 + 配套资料
回复【软件】获取常用的开发软件(逐步完善)
回复【亿级源码】获取本号作者出版的《亿级流量Java高并发与网络编程实战》一书配套源码
回复【javase】获取JAVA基础视频教程
更多课程,逐步开放...
以上是关于什么是一致性hash算法的主要内容,如果未能解决你的问题,请参考以下文章