深度优先生成树和广度优先生成树(详解版)
Posted 编程大师
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深度优先生成树和广度优先生成树(详解版)相关的知识,希望对你有一定的参考价值。
前面已经给大家介绍了有关生成树和生成森林的有关知识,本节来解决对于给定的无向图,如何构建它们相对应的生成树或者生成森林。
其实在对无向图进行遍历的时候,遍历过程中所经历过的图中的顶点和边的组合,就是图的生成树或者生成森林。
图 1 无向图
例如,图 1 中的无向图是由 V1~V7 的顶点和编号分别为 a~i 的边组成。当使用深度优先搜索算法时,假设 V1 作为遍历的起始点,涉及到的顶点和边的遍历顺序为(不唯一):
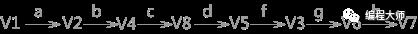
此种遍历顺序构建的生成树为:
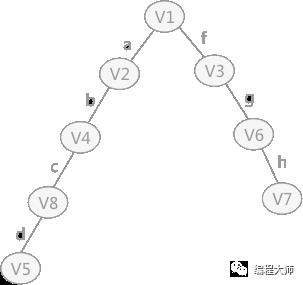
图 2 深度优先生成树
由深度优先搜索得到的树为深度优先生成树。同理,广度优先搜索生成的树为广度优先生成树,图 1 无向图以顶点 V1 为起始点进行广度优先搜索遍历得到的树,如图 3 所示:
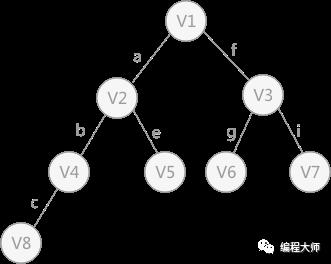
图 3 广度优先生成树
非连通图的生成森林
非连通图在进行遍历时,实则是对非连通图中每个连通分量分别进行遍历,在遍历过程经过的每个顶点和边,就构成了每个连通分量的生成树。
非连通图中,多个连通分量构成的多个生成树为非连通图的生成森林。
深度优先生成森林
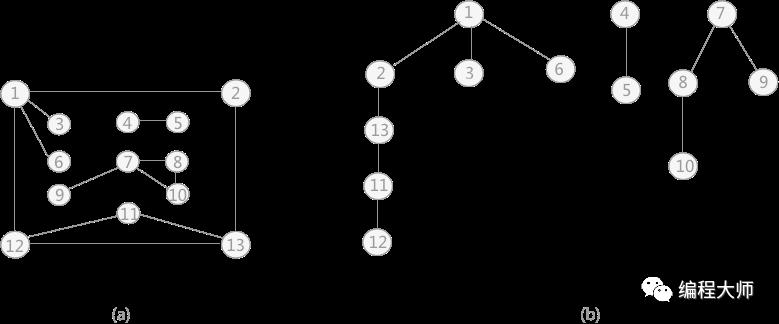
图 4 深度优先生成森林
例如,对图 4 中的非连通图 (a) 采用深度优先搜索算法遍历时,得到的深度优先生成森林(由 3 个深度优先生成树构成)如 (b) 所示(不唯一)。
非连通图在遍历生成森林时,可以采用孩子兄弟表示法将森林转化为一整棵二叉树进行存储。
具体实现的代码:
typedef enum{false,true}bool; //定义bool型常量bool visited[MAX_VERtEX_NUM]; //设置全局数组,记录标记顶点是否被访问过typedef struct {VRType adj; //对于无权图,用 1 或 0 表示是否相邻;对于带权图,直接为权值。}ArcCell,AdjMatrix[MAX_VERtEX_NUM][MAX_VERtEX_NUM];typedef struct {VertexType vexs[MAX_VERtEX_NUM]; //存储图中顶点数据AdjMatrix arcs; //二维数组,记录顶点之间的关系int vexnum,arcnum; //记录图的顶点数和弧(边)数}MGraph;//孩子兄弟表示法的链表结点结构typedef struct CSNode{VertexType data;struct CSNode * lchild;//孩子结点struct CSNode * nextsibling;//兄弟结点}*CSTree,CSNode;//根据顶点本身数据,判断出顶点在二维数组中的位置int LocateVex(MGraph G,VertexType v){int i=0;//遍历一维数组,找到变量vfor (; i<G.vexnum; i++) {if (G.vexs[i]==v) {break;}}//如果找不到,输出提示语句,返回-1if (i>G.vexnum) {printf("no such vertex. ");return -1;}return i;}//构造无向图void CreateDN(MGraph *G){scanf("%d,%d",&(G->vexnum),&(G->arcnum));getchar();for (int i=0; i<G->vexnum; i++) {scanf("%d",&(G->vexs[i]));}for (int i=0; i<G->vexnum; i++) {for (int j=0; j<G->vexnum; j++) {G->arcs[i][j].adj=0;}}for (int i=0; i<G->arcnum; i++) {int v1,v2;scanf("%d,%d",&v1,&v2);int n=LocateVex(*G, v1);int m=LocateVex(*G, v2);if (m==-1 ||n==-1) {printf("no this vertex ");return;}G->arcs[n][m].adj=1;G->arcs[m][n].adj=1;//无向图的二阶矩阵沿主对角线对称}}int FirstAdjVex(MGraph G,int v){//查找与数组下标为v的顶点之间有边的顶点,返回它在数组中的下标for(int i = 0; i<G.vexnum; i++){if( G.arcs[v][i].adj ){return i;}}return -1;}int NextAdjVex(MGraph G,int v,int w){//从前一个访问位置w的下一个位置开始,查找之间有边的顶点for(int i = w+1; i<G.vexnum; i++){if(G.arcs[v][i].adj){return i;}}return -1;}void DFSTree(MGraph G,int v,CSTree*T){//将正在访问的该顶点的标志位设为truevisited[v]=true;bool first=true;CSTree q=NULL;//依次遍历该顶点的所有邻接点for (int w=FirstAdjVex(G, v); w>=0; w=NextAdjVex(G, v, w)) {//如果该临界点标志位为false,说明还未访问if (!visited[w]) {//为该邻接点初始化为结点CSTree p=(CSTree)malloc(sizeof(CSNode));p->data=G.vexs[w];p->lchild=NULL;p->nextsibling=NULL;//该结点的第一个邻接点作为孩子结点,其它邻接点作为孩子结点的兄弟结点if (first) {(*T)->lchild=p;first=false;}//否则,为兄弟结点else{q->nextsibling=p;}q=p;//以当前访问的顶点为树根,继续访问其邻接点DFSTree(G, w, &q);}}}//深度优先搜索生成森林并转化为二叉树void DFSForest(MGraph G,CSTree *T){(*T)=NULL;//每个顶点的标记为初始化为falsefor (int v=0; v<G.vexnum; v++) {visited[v]=false;}CSTree q=NULL;//遍历每个顶点作为初始点,建立深度优先生成树for (int v=0; v<G.vexnum; v++) {//如果该顶点的标记位为false,证明未访问过if (!(visited[v])) {//新建一个结点,表示该顶点CSTree p=(CSTree)malloc(sizeof(CSNode));p->data=G.vexs[v];p->lchild=NULL;p->nextsibling=NULL;//如果树未空,则该顶点作为树的树根if (!(*T)) {(*T)=p;}//该顶点作为树根的兄弟结点else{q->nextsibling=p;}//每次都要把q指针指向新的结点,为下次添加结点做铺垫q=p;//以该结点为起始点,构建深度优先生成树DFSTree(G,v,&p);}}}//前序遍历二叉树void PreOrderTraverse(CSTree T){if (T) {printf("%d ",T->data);PreOrderTraverse(T->lchild);PreOrderTraverse(T->nextsibling);}return;}int main() {MGraph G;//建立一个图的变量CreateDN(&G);//初始化图CSTree T;DFSForest(G, &T);PreOrderTraverse(T);return 0;}
运行程序,拿图 4(a)中的非连通图为例,构建的深度优先生成森林,使用孩子兄弟表示法表示为:
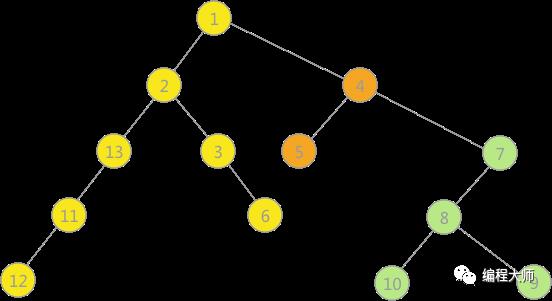
图5 孩子兄弟表示法表示深度优先生成森林
图中,3 种颜色的树各代表一棵深度优先生成树,使用孩子兄弟表示法表示,也就是将三棵树的树根相连,第一棵树的树根作为整棵树的树根。
运行结果
13,13
1
2
3
4
5
6
7
8
9
10
11
12
13
1,2
1,3
1,6
1,12
2,13
4,5
7,8
7,10
7,9
8,10
11,12
11,13
12,13
1 2 13 11 12 3 6 4 5 7 8 10 9
广度优先生成森林
非连通图采用广度优先搜索算法进行遍历时,经过的顶点以及边的集合为该图的广度优先生成森林。
拿图 4(a)中的非连通图为例,通过广度优先搜索得到的广度优先生成森林用孩子兄弟表示法为:
图6 广度优先生成森林(孩子兄弟表示法)
实现代码为:
typedef enum{false,true}bool; //定义bool型常量bool visited[MAX_VERtEX_NUM]; //设置全局数组,记录标记顶点是否被访问过typedef struct {VRType adj; //对于无权图,用 1 或 0 表示是否相邻;对于带权图,直接为权值。InfoType * info; //弧或边额外含有的信息指针}ArcCell,AdjMatrix[MAX_VERtEX_NUM][MAX_VERtEX_NUM];typedef struct {VertexType vexs[MAX_VERtEX_NUM]; //存储图中顶点数据AdjMatrix arcs; //二维数组,记录顶点之间的关系int vexnum,arcnum; //记录图的顶点数和弧(边)数}MGraph;typedef struct CSNode{VertexType data;struct CSNode * lchild;//孩子结点struct CSNode * nextsibling;//兄弟结点}*CSTree,CSNode;typedef struct Queue{CSTree data;//队列中存放的为树结点struct Queue * next;}Queue;//根据顶点本身数据,判断出顶点在二维数组中的位置int LocateVex(MGraph * G,VertexType v){int i=0;//遍历一维数组,找到变量vfor (; i<G->vexnum; i++) {if (G->vexs[i]==v) {break;}}//如果找不到,输出提示语句,返回-1if (i>G->vexnum) {printf("no such vertex. ");return -1;}return i;}//构造无向图void CreateDN(MGraph *G){scanf("%d,%d",&(G->vexnum),&(G->arcnum));for (int i=0; i<G->vexnum; i++) {scanf("%d",&(G->vexs[i]));}for (int i=0; i<G->vexnum; i++) {for (int j=0; j<G->vexnum; j++) {G->arcs[i][j].adj=0;G->arcs[i][j].info=NULL;}}for (int i=0; i<G->arcnum; i++) {int v1,v2;scanf("%d,%d",&v1,&v2);int n=LocateVex(G, v1);int m=LocateVex(G, v2);if (m==-1 ||n==-1) {printf("no this vertex ");return;}G->arcs[n][m].adj=1;G->arcs[m][n].adj=1;//无向图的二阶矩阵沿主对角线对称}}int FirstAdjVex(MGraph G,int v){//查找与数组下标为v的顶点之间有边的顶点,返回它在数组中的下标for(int i = 0; i<G.vexnum; i++){if( G.arcs[v][i].adj ){return i;}}return -1;}int NextAdjVex(MGraph G,int v,int w){//从前一个访问位置w的下一个位置开始,查找之间有边的顶点for(int i = w+1; i<G.vexnum; i++){if(G.arcs[v][i].adj){return i;}}return -1;}//初始化队列void InitQueue(Queue ** Q){(*Q)=(Queue*)malloc(sizeof(Queue));(*Q)->next=NULL;}//结点v进队列void EnQueue(Queue **Q,CSTree T){Queue * element=(Queue*)malloc(sizeof(Queue));element->data=T;element->next=NULL;Queue * temp=(*Q);while (temp->next!=NULL) {temp=temp->next;}temp->next=element;}//队头元素出队列void DeQueue(Queue **Q,CSTree *u){(*u)=(*Q)->next->data;(*Q)->next=(*Q)->next->next;}//判断队列是否为空bool QueueEmpty(Queue *Q){if (Q->next==NULL) {return true;}return false;}void BFSTree(MGraph G,int v,CSTree*T){CSTree q=NULL;Queue * Q;InitQueue(&Q);//根结点入队EnQueue(&Q, (*T));//当队列为空时,证明遍历完成while (!QueueEmpty(Q)) {bool first=true;//队列首个结点出队DeQueue(&Q,&q);//判断结点中的数据在数组中的具体位置int v=LocateVex(&G,q->data);//已经访问过的更改其标志位visited[v]=true;//遍历以出队结点为起始点的所有邻接点for (int w=FirstAdjVex(G,v); w>=0; w=NextAdjVex(G,v, w)) {//标志位为false,证明未遍历过if (!visited[w]) {//新建一个结点 p,存放当前遍历的顶点CSTree p=(CSTree)malloc(sizeof(CSNode));p->data=G.vexs[w];p->lchild=NULL;p->nextsibling=NULL;//当前结点入队EnQueue(&Q, p);//更改标志位visited[w]=true;//如果是出队顶点的第一个邻接点,设置p结点为其左孩子if (first) {q->lchild=p;first=false;}//否则设置其为兄弟结点else{q->nextsibling=p;}q=p;}}}}//广度优先搜索生成森林并转化为二叉树void BFSForest(MGraph G,CSTree *T){(*T)=NULL;//每个顶点的标记为初始化为falsefor (int v=0; v<G.vexnum; v++) {visited[v]=false;}CSTree q=NULL;//遍历图中所有的顶点for (int v=0; v<G.vexnum; v++) {//如果该顶点的标记位为false,证明未访问过if (!(visited[v])) {//新建一个结点,表示该顶点CSTree p=(CSTree)malloc(sizeof(CSNode));p->data=G.vexs[v];p->lchild=NULL;p->nextsibling=NULL;//如果树未空,则该顶点作为树的树根if (!(*T)) {(*T)=p;}//该顶点作为树根的兄弟结点else{q->nextsibling=p;}//每次都要把q指针指向新的结点,为下次添加结点做铺垫q=p;//以该结点为起始点,构建广度优先生成树BFSTree(G,v,&p);}}}//前序遍历二叉树void PreOrderTraverse(CSTree T){if (T) {printf("%d ",T->data);PreOrderTraverse(T->lchild);PreOrderTraverse(T->nextsibling);}return;}int main() {MGraph G;//建立一个图的变量CreateDN(&G);//初始化图CSTree T;BFSForest(G, &T);PreOrderTraverse(T);return 0;}运行结果为:
13,13
1
2
3
4
5
6
7
8
9
10
11
12
13
1,2
1,3
1,6
1,12
2,13
4,5
7,8
7,10
7,9
8,10
11,12
11,13
12,13
1 2 13 3 6 12 11 4 5 7 8 9 10
以上是关于深度优先生成树和广度优先生成树(详解版)的主要内容,如果未能解决你的问题,请参考以下文章
关于数据结构的深度优先遍历和广度优先遍历以及最小生成树 第四大题的第一题
邻接矩阵c源码(构造邻接矩阵,深度优先遍历,广度优先遍历,最小生成树prim,kruskal算法)