系统架构聊聊开源消息中间件的架构和原理
Posted 码农有道
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了系统架构聊聊开源消息中间件的架构和原理相关的知识,希望对你有一定的参考价值。
说到消息中间件,身在互联网的童鞋们肯定下意识的就是高并发,高性能io调度等浮现在脑海,但是对应用来说,可能他的作用远不止性能这么简单,尤其是对与交易,金融打交道的业务平台来说。
ok,下面给大家介绍一下金融交易平台中,哪些场景是需要我们用到消息中间件的?为什么要使用?怎么设计中间件私有云让开发比较爽?(鉴于不同同学语言擅长不相同,这里只聊设计原理和机制方面的内容,本文会涉及市面上流行的开源产品,如activemq、rabbitmq、kafka、metaq等)
消息中间件的作用就是用来异步化并发能力的一个载体,不仅如此,它仍然需要在架构上保证很多能力,高可用,高并发,可扩展,可靠性,完整性,保证顺序等,光是这些都已经让各种设计者比较头疼了; 更有一些变态的需求,例如慢消费,不可重复等需要花的设计代价是相当高的,所以不要盲目的迷信开源大牛,对于很多机制,几乎都要重建;建立一个符合所有业务,好用,通用的私有云,没那么简单。
如果说一个支付系统每天要处理亿级业务单的话,那么消息中间件的处理能力至少得达到近百亿,因为很多系统都是依赖于中间件的集群能力,并且要保证不能出错,so,让我们从架构的一些层面上来一点点来分析中间件是怎么做到的?
高可用是一个永恒的话题,这个也是在金融界是否靠谱的一个衡量标准,要知道,金融界的架构师们会想方设法的让数据不会丢失,哪怕是一条数据,但是事实上,这个东西从理论上来讲,得靠人品。。。这个不是忽悠。
举一个例子来说,互联网数据架构中一份数据至少要存三份才叫高保证,但是事实上,谷歌的比利时数据中心在8.13日遭到雷劈后数据中心永久丢失0.000001%,不到0.05%的磁盘未能修复,这里要说的是,天时地利人和很重要,极限条件下没有什么不可能,一定会有架构漏洞,下面看一下mq高可用的一般做法:
下图是activemq的HA方案:
activemq的HA 通过master/slave的failover进行托管,其中主从切换可以通过多种方式进行切换:
1:通过一个nfs或其它共享磁盘设备进行一个共享锁,通过对共享文件锁的占有,来标记master的状态,当m挂掉以后,对应的slave会占有shared_lock而转换为master
2:通过zookeeper进行集群的管理,比较常见,这里不再介绍
下图是metaq的HA方案
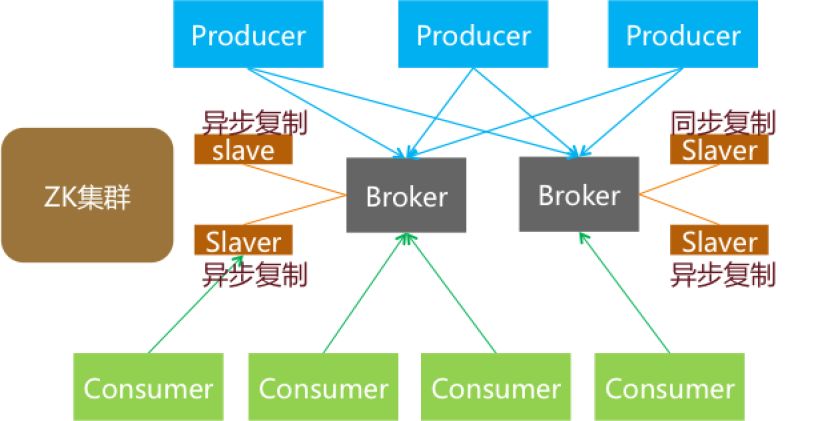
如上图,如出一辙,也是通过zk管理broker的主从结点。
当然这个只是其中的一个failover机制,只能保证消息在broker挂掉时转换到slave上,但是不能保证在这中间过程中的消息的丢失
当消息从broker流经时,很有可能因为宕机或是其它硬件故障而导致后,就有可能导致消息丢失掉,这个时候,就需要有相关的存储介质对消息的进行一个保障了
那么我们举kafka的存储机制作为一个参考,要知道消息中间件对存储的依赖不但要求速度快,并且要求IO的需求成本非常低,kafka自己设计了一套存储机制来满足上述的需求,这里简单介绍一下。
首先kafka中的topic在分布式部署下分做多个分区,分区的就相当于消息进行了一个负载,然后由多台机器进行路由,举个例子: 一个topic,debit_account_msg会切分为 debit_account_msg_0, debit_account_msg_1, debit_account_msg_2。。。等N个partition,每个partition会在本地生成一个目录比如/debit_account_msg/topic
里面的文件会分出很多segment,每个segment会定义一个大小,比如500mb一个segment,一个file分为index和log二个部分
00000000000000000.index
00000000000000000.log
00000000000065535.index
00000000000065535.log
其中数字代表msgId的值的索引起点,对应的数据结构如下图:
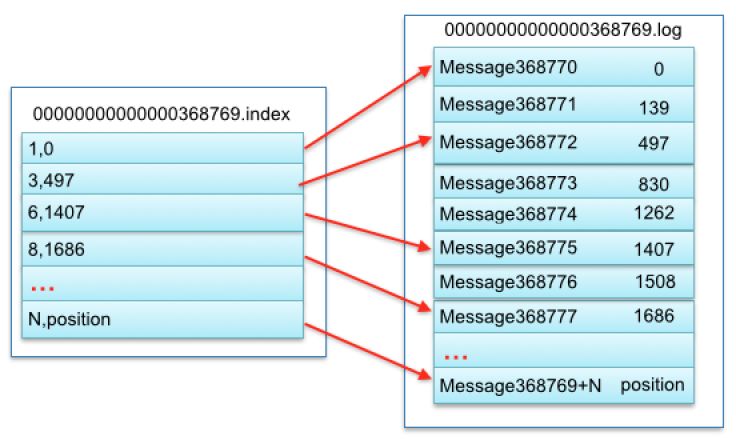
1,0代表msgId为1的消息,0代表在这个文件中的偏移量,读取到这个文件后再寻找到查询到对应的segment log文件读取对应的msg信息,对应的信息是一个固定格式消息体:
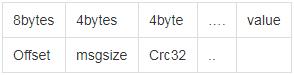
显然,这种机制单纯应用肯定是不能满足高并发IO的,首先二分查找segmentfile,然后再通过offset找到对应数据,再读取msgsize,再读取报体,至少是4次磁盘io,开销较大,但是在拉取时候是使用的顺序读取,基本上影响不大。
除了要上面所说的查询外。其实在写入磁盘之前都是在os上的pagecache上进行读写的,然后通过异步线程对硬盘进行定时的flush(LRU策略),但其实这个风险很大的,因为一旦os宕掉,会导致数据的丢失,尤其是在进行慢消费多积压很多数据的情况下,但是kafka他弟metaq对这块已经做了很多改造,对这些分区文件进行了replication机制(阿里内部使用),所以在这个层面上再怎么遭雷劈丢消息的机率就会比较小了,当然也不排除主机房光缆被人挖掉会有什么样的情况发生。
说了这么多,似乎看起来的比较完美和美好,但是实际上运维成本似乎很大。因为这些都是文件,一旦发生问题,需要人工去处理起来相当麻烦,而且是在一台一台机器上,需要比较大的运维成本去做一些运维规范以及api调用设施等。
所以,在这块我们可以通过改造,将数据存储在一些nosql上,比如mongoDB上,当然mysql也是可以,但是io能力和nosqldb完全不在一个水平线上,除非我们有强烈的事务处理机制,而在金融里的确对这块要求比较相当严谨。像在支付宝后面就使用了metaq,因为之前的中间件tbnotify在处理慢消费的情况下会很被动,而metaq在这块会有极大的优势,为什么,请听后面分解。
最开始大家使用mq很大部分工程师都用于解决性能和异步化的问题,其实对于同一个点来说,一个io调度其实并不是那么耗资源,废话少说让我们看下mq里的一些高并发点,首先在这里先介绍一下几个比较有名的中间件背景:
activemq当时就是专门的企业级解决方案,遵守jee里的jms规范,其实性能也还是不错的,但是拉到互联网里就是兔子抱西瓜,无能为力了
rabbitmq采用erlang语言编写,遵守AMQP协议规范,更具有跨平台性质,模式传递模式要更丰富,并且在分布式
rocketmq(metaq3.0现今最新版本, kafka也是metaq的前身,最开始是linkedIn开源出来的日志消息系统 ),metaq基本上把kafka的原理和机制用java写了一遍,经过多次改造,支持事务,发展速度很快,并且在阿里和国内有很比较好的社区去做这块的维护 。
性能比较,这里从网上找一些数据,仅供参考:
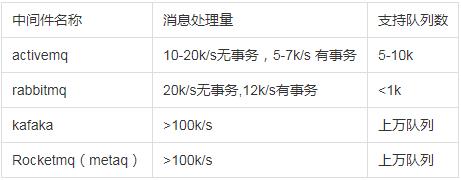
说实话来讲,这些数据级别来讲,相差没有太离谱,但是我们可以通过分析一些共性来讲,这些主要性能差别在哪里?
rocketmq是metaq的后继者,除了在一些新特性和机制方面有改进外,性能方面的原理都差不多,下面说下这些高性能的一些亮点:
rocketmq的消费主要采用pull机制,所以对于broker来讲,很多消费的特性都不需要在broker上实现,只需要通过consumer来拉取相关的数据即可,而像activemq,rabbitmq都是采取比较老的方式让broker去dispatch消息,当然些也是jms或amqp的一些标准投递方式
文件存储是顺序存储的,所以来拉消息的时候只需要通过调用segment的数据就可以了,并且consumer在做消费的时候是最大程度的去消费信息,不太可能产生积压,而且可以通过设置io调度算法,像noop模式,可以提高一些顺序读取的性能 。
通过pagecache去命中在os缓存中的数据达到一个热消费
metaq的批量磁盘IO以及网络IO,尽量让数据在一次io中运转,消息起来都是批量的,这样对io的调度不太需要消耗太多资源
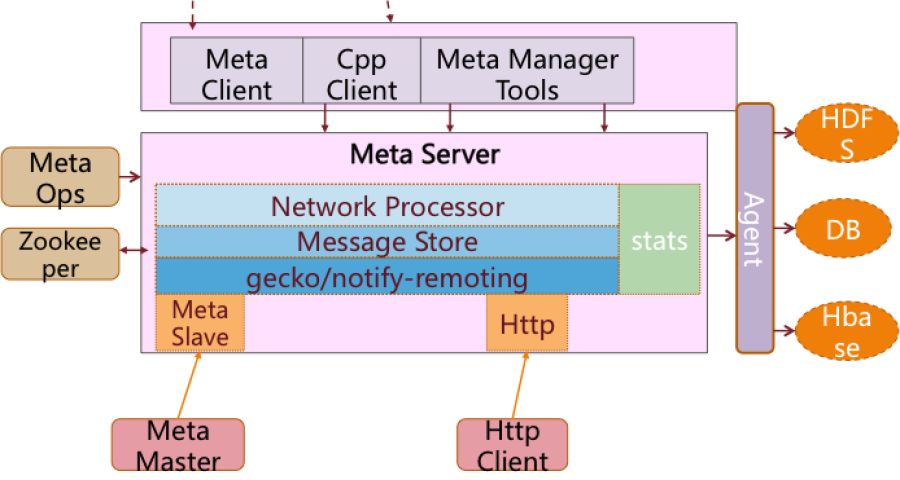
NIO传输,如下图,这个是最初metaq的一个架构,最初metaq使用的是taobao内部的gecko和notify-remoting集成的一些高性能的NIO框架去分发消息
消费队列的轻量化,要知道我们的消息能力是通过队列来获取的
看下面的图:
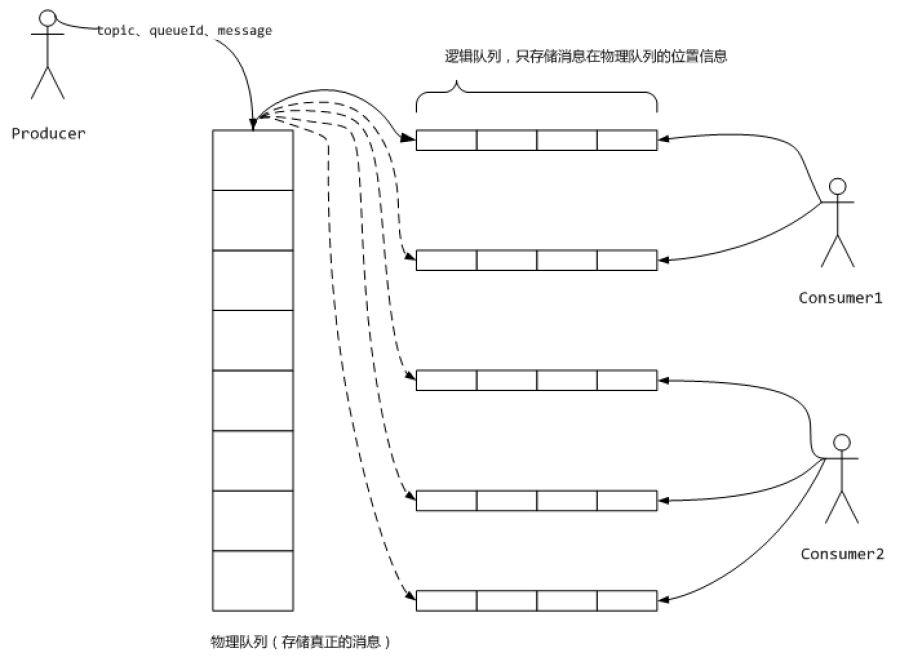
metaq在消费的物理队列上添加了逻辑队列,队列对应的磁盘数据是串行化的,队列的添加不会添加磁盘的iowait负担,写入可以顺序,但是在读取的时候仍然需要去用随机读,首先是逻辑队列 ,然后再读取磁盘,所以pagecache很重要,尽量让内存大一些,这块分配就会充分得到利用。
其实做到上面这些已经基本上能保证我们的性能在一个比较高的水平; 但是有时候性能并不是最重要的,最重要的是要和其它的架构特性做一个最佳的平衡,毕竟还有其它的机制要满足。因为在业界基本上最难搞定的三个问题:高并发,高可用,一致性是互相冲突的。
这是一个老生常谈的问题,对于一般系统或是中间件,可以较好的扩展,但是在消息中间件这块,一直是一个麻烦事,为什么?
先说下activemq的扩展起来的局限性,因为activemq的扩展需要业务性质,作为broker首先要知道来源和目的地,但是这些消息如果都是分布式传输的话,就会变的复杂,下面看一下activemq的负载是怎么玩转的
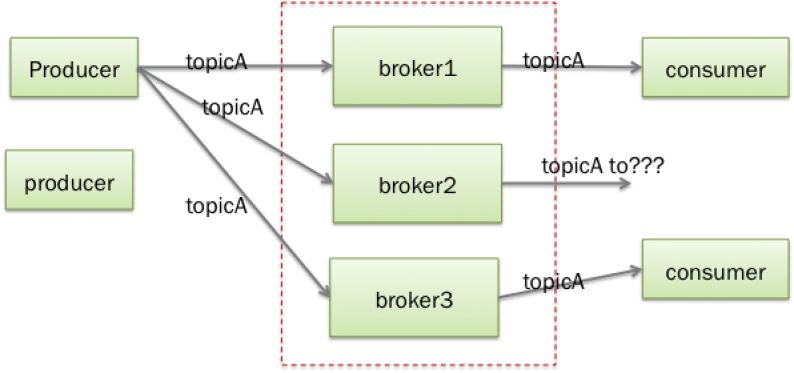
我们假设producer去发topicA的消息,如果正常情况下所有的consumer都连到每一个broker上的,辣么假如broker上有producer上的消息过来,是可以transfer到对应的consumer上的。
但是如果像图中 broker2中如果没有对应的消息者连接到上面,这种情况下怎么办呢?因为假设同一个topic的应用系统(producer)和依赖系统 (consumer)节点很多,那又该如何扩容呢?activemq是可以做上图中正常部分,但是需要改变producer,broker,consumer的对应的配置,相当麻烦。
当然activemq也可以通过multicast的方式来做动态的查找(也有人提到用lvs或f5做负载,但是对于consumer一样存在较大的问题,而且这种负载配置对于topic的分发,没实质性作用),但是,仍然会有我说的这个问题,如果topic太大,每个broker都需要连接所有的producer或是consumer, 不然就会出现我说的情况,扩容这方面activemq是相当的麻烦
下面来说一下metaq是如何做这块事情的,看图说话
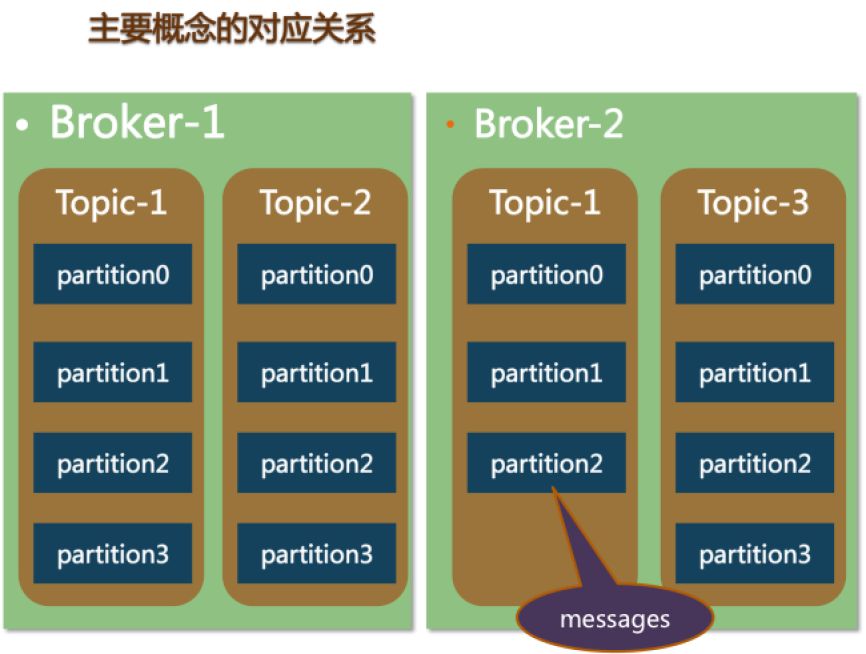
metaq上是以topic为分区的,在这个层面来讲,我们只要配置topic的分区有多少个就好了,这样切片起来就是有个"业务"概念作为路由规则;一般一个broker机器上配置有多个topic,每个topic在一个机器上一般是只有一个分区,假如机器不够了,也是可以支持多个分区的,一般来说,我们可以通过业务id来取模自定义分区,通过获取发区参数即可。
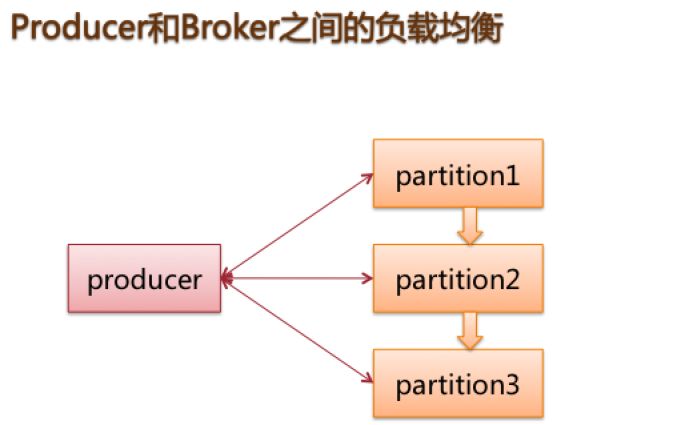
metaq的消费者也是通过group(这个分组一般根据partition的能力来配置)负载的方式去partition去拉消息,假如有多的消费者,不需要参与消费。一般线上都是这种情况,因为毕竟应用服务器要远大于消息服务器。
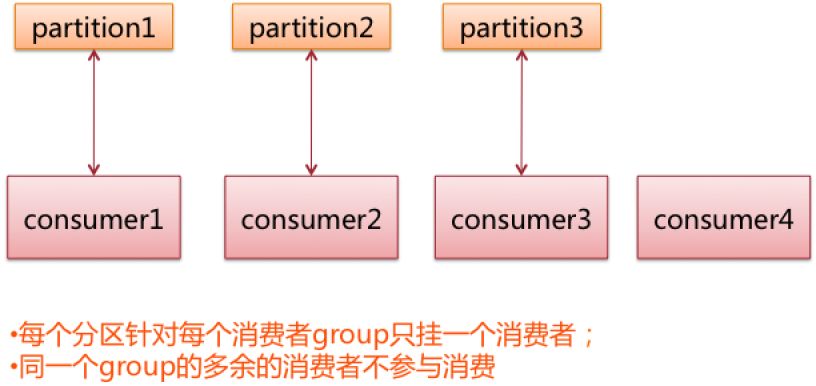
另外一种情况,当分区过多时,如下图
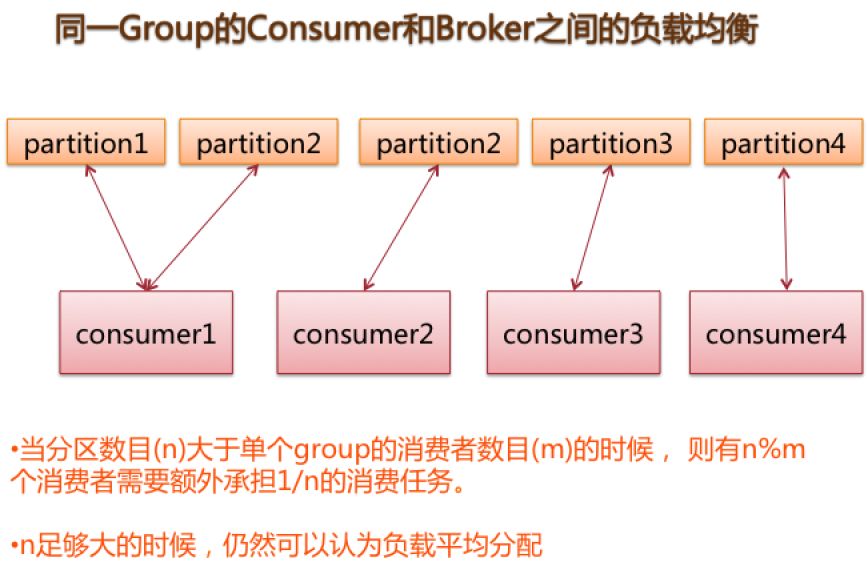
这样的负载在多依赖的核心消息时,对于服务器broker的要求还是比较高的,毕竟依赖的量较大,另外对于消息具有广播特点的话,可能会更大,所以对于broker而言,需要高io的硬盘以及大内存做pagecache,真正需要的运算并不需要太大
可靠性是消息中间件的重要特性,看下mq是怎么流转这些消息的,拿activemq来先来做下参考,它是基于push&push机制。
如何保证每次的消息发送都被消费到?Activemq的生产者发送消息后都需要收到一条broker的ack才会确认消收到,同样对于broker到consumer也是同样的保障。
Metaq的机制也是同样的,但是broker到consumer是通过pull的方式,所以它的到达保障要看consumer的能力如何,但是一般情况下,应用服务器集群不太可能出现雪崩效应。
如何保证消息的幂等性?目前来说基本上activemq,metaq都不能保证消息的幂等性,这就需要一些业务来保证了。因为一旦broker超时,就会重试,重试的话都会产生新的消息,有可能broker已经落地消息了,所以这种情况下没法保证同一笔业务流水产生二条消息出来
消息的可靠性如何保证?这点上activemq和metaq基本上机制一样:
生产者保证:生产数据后到broker后必须要持久化才能返回ACK给来源
broker保证:metaq服务器接收到消息后,通过定时刷新到硬盘上,然后这些数据都是通过同步/异步复制到slave上,来保证宕机后也不会影响消费
activemq也是通过数据库或是文件存储在本地,做本地的恢复
消费者保证:消息的消费者是一条接着一条地消费消息,只有在成功消费一条消息后才会接着消费下一条。如果在消费某条消息失败(如异常),则会尝试重试消费这条消息(默认最大5次),超过最大次数后仍然无法消费,则将消息存储在消费者的本地磁盘,由后台线程继续做重试。而主线程继续往后走,消费后续的消息。因此,只有在MessageListener确认成功消费一条消息后,meta的消费者才会继续消费另一条消息。由此来保证消息的可靠消费。
mq的一致性我们讨论二个场景:
1:保证消息不会被多次发送/消费
2:保证事务
刚才上面介绍的一些mq都是不能保证一致性的,为什么不去保证?代价比较大,只能说,这些都是可以通过改造源码来进行保证的,而且方案比较相对来说不是太复杂,但是额外的开销比较大,比如通过额外的缓存集群来保证某段时间的不重复性,相信后面应该会有一些mq带上这个功能。
Activemq支持二种事务,一个是JMS transaction,一个是XA分布式事务,如果带上事务的话,在交互时会生成一个transactionId去到broker,broker实现一些TM去分配事务处理,metaq也支持本地事务和XA,遵守JTA标准这里activemq和metaq的事务保证都是通过redo日志方式来完成的,基本上一致。
这里的分布式事务只在broker阶段后保证,在broker提交之前会把prepare的消息存储在本地文件中,到commit阶段才将消息写入队列,最后通过TM实现二阶段提交。
像公司内部也有一些性能很不错的消息中间件,希望后面也能做到开源给到更多的人去使用。针对现在流行的一些消息中间件我们可以针对不同的应用,不同的成本,不同的开发定制不同的架构,当然,这些架构一定是需要我们经过多方面考量。
推荐阅读:
专注服务器后台技术栈知识总结分享
欢迎关注交流共同进步
码农有道,为您提供通俗易懂的技术文章,让技术变的更简单!
以上是关于系统架构聊聊开源消息中间件的架构和原理的主要内容,如果未能解决你的问题,请参考以下文章