中间件运维分析中的选型与实践
Posted apachekylin
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了中间件运维分析中的选型与实践相关的知识,希望对你有一定的参考价值。
在近期的 Kylin Data Summit 上,好买财富平台架构总监王晔倞在互联网专场上分享了好买财富在中间件运维分析平台的演进过程。好买财富为什么选择从广泛应用的 ELK 转向 Apache Kylin 呢?
△ 王晔倞
我们在监控上,通常会遇到哪些问题?
1. 问题一:裸用各种开源监控,无法精准定位
首先第一个问题,我们经常谈监控,监控其实是一种表象,底层其实都是通过一些数据的分析来判定到底哪里有问题,或者说你告诉我原因在哪,然后我去解决。同样的业务下,一般运维所产生的日志数据量比业务数据量要大,可能你产生一条业务数据,会产生同纬度的3-4倍的运维数据。现在来看一下,我们遇到了什么问题。
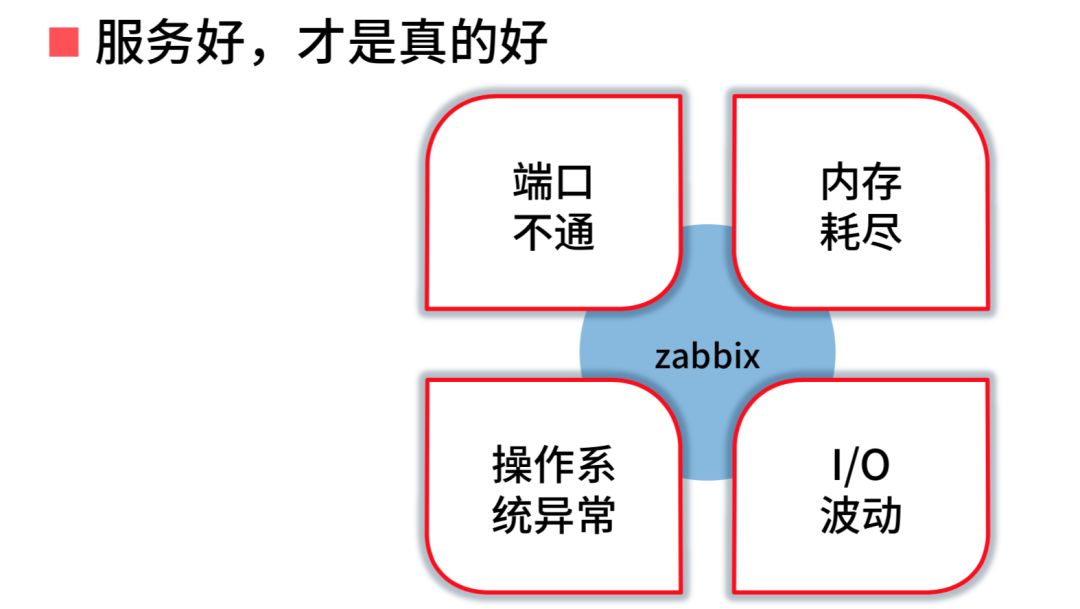
在运维场景下,大家都会用 zabbix 进行运维场景定位,主要做上图这四件事情。你会发现每家公司都用 zabbix,但是它起不到太多作用。它会帮你检测一些端口、内存、操作系统异常,大家平时在工作中因为这些异常导致你系统出现问题机率高吗?其实不高。
通常出现问题的时候,你的监控一切正常,但是服务出了问题。真的有哪一个端口不通,我可以很快解决,而且现在几乎所有高可用架构对于这些问题都有很好的解决方案。如果你的进程还在,端口还通,但是链路断掉,服务终止或者有损,怎么办?所以说你虽然用了一些开源工具,大家都是这么用的,但你会发现其实这样没有什么用。
2. 问题二:缺乏短链路监控与排障手段
我们来看一下我们一般的链路监控。现在很多做链路监控的工具,包括 pinpoint、skywalking,它虽然能告诉你哪个节点出了问题,但你还是要靠人去研究问题在哪里。你会发现我花了很大力气上这些东西,但是起不到太多作用,最后出现什么场景呢?

首先,前端业务报出问题了,前台说我来查一下,中台告诉你说日志都没打,我感觉没调过来,运维说好像没有问题,进程还在,端口也通,我这儿没有任何问题。然后,后台说你胡说什么,我这有反应,其实你传错了,接着DBA说你叫什么叫,你连数据库都没连上来。最后,运维说MQ堵塞了,不知道在叫啥。然后老板就会说叫你们处理了这么长时间,说了半天,你们问题解决没有?每个人都会觉得自己无辜,最终业务倒霉。
基于这样的场景,我们需要用什么样的方式解决呢?你需要通过一些分析解决。现在大家听到外面很多公司谈 AIOps 还有 DataOps,这些概念的核心就是大数据。你必须通过一些流水数据的各维度分析告诉我问题究竟在哪,如果你有了问题之后我怎么能够帮你自动,或者半自动解决,因为要的都是效率。你跟老板说这些东西有没有用呢?没有用,他会问你有没有短平快方式解决这个问题。那怎么办呢?有什么立竿见影的方法呢?
为什么选择 ELK?
1. 决定因素
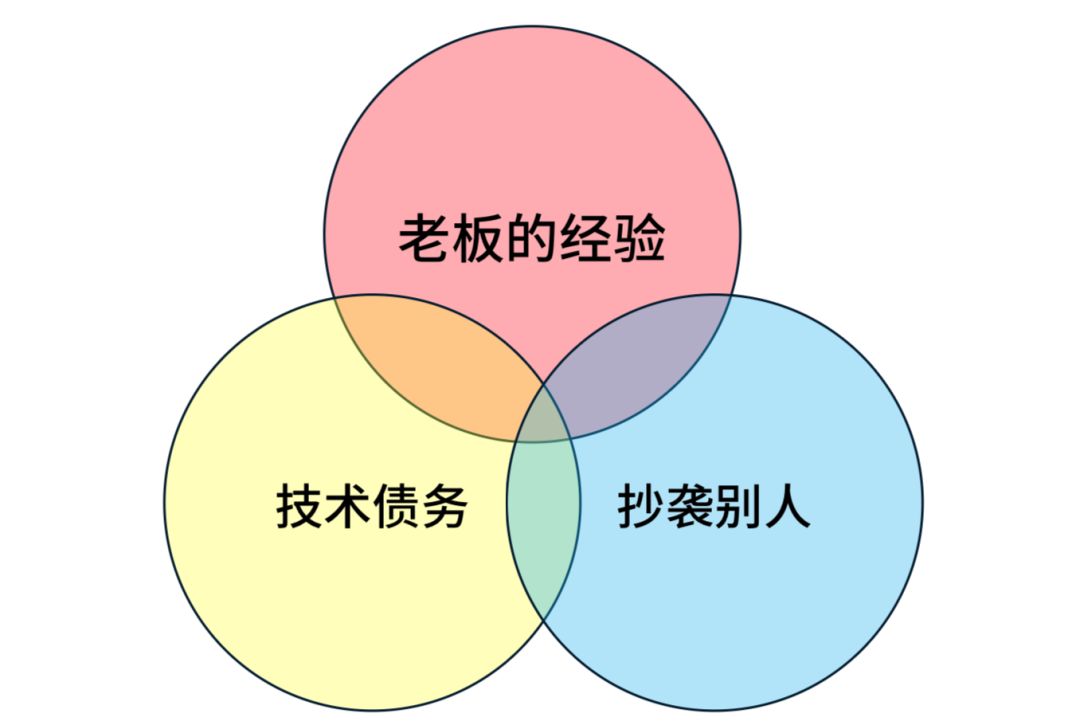
第一点是老板。技术老大说我以前用这个东西,所以我要用这个东西,你说什么都没有用,因为他是你领导。
第二点,因为历史上用了这个东西,所以我只能继续用下去。大家有没有算过,你用和不用 Hadoop,技术成本有什么区别?对很多公司来说,用 Hadoop 成本反而高了,但是很多人没有算过这笔帐。因为之前的人留下来一堆 Hadoop,配备的人才也是用 Hadoop。
第三点,因为滴滴用,所以我也用。为啥?因为滴滴这家公司特别牛逼。因为美团用,所以我用,阿里用,我也用。人家写的文章里一定写的是好的一面,不好的东西会到外面说吗?
所以我们选择了 ELK,整个行业在做运维数据分析场景监控,一般都用 ELK,所以我们也用。
2. 目的与目标

我们希望通过对各种日志收集分析找到故障原因,并且高效解决。目标第一点是设定一些报警阀值,这个跟 zabbix 不一样,它要求对服务的一些链路以及调用关系,以及种种分析之后的阀值进行判定,中间带逻辑的。目标的第二点,运维数据要有沉淀,大家知道运维的数据是需要沉淀的,因为你需要做同比类比分析,其实跟业务大数据一回事,你不能把这个数据扔掉。
3. ELK 时期架构
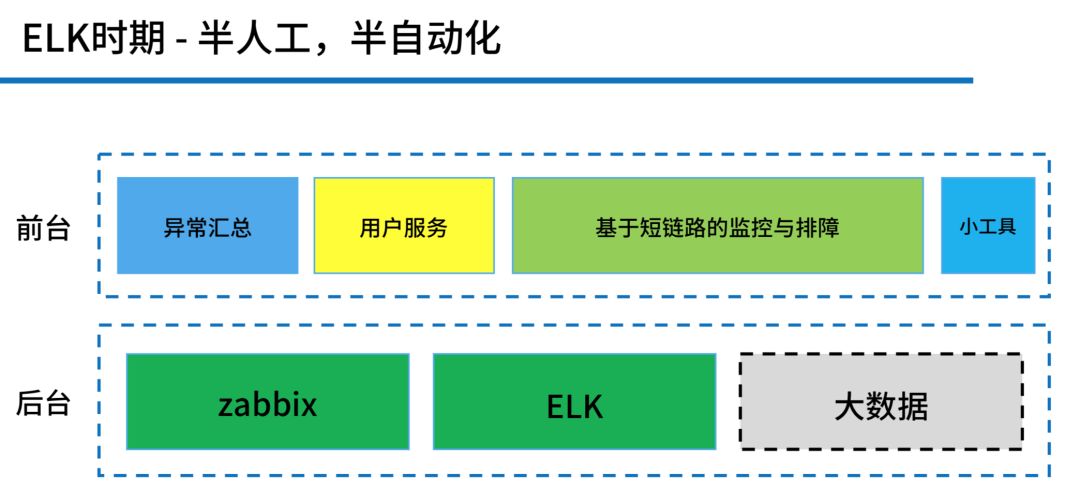
我们形成了上图这样的结构。“后台”右边有一个“大数据”,这个是灰色的,也就是在这个时间,我们提出了大数据解决方案,但是被否掉了。为啥?有句话听过没有,叫“用钱能解决的问题都不是问题”,关键是没钱,上大数据是有成本的。所以我们当时形成这样的结构,我们把 zabbix 和 ELK 放到后台,前端做了一些自定义开发,然后很快速地用一到两个月上了如下图的一个架构。
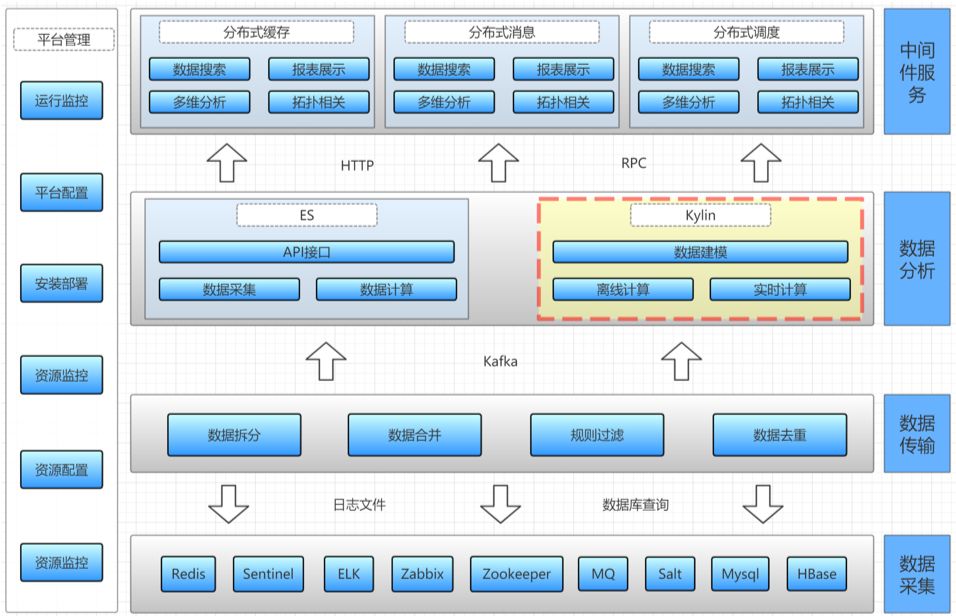
这大概是2017年、2018年的时候,这个时候我提出 Kylin,但是没有用,我提出了大数据解决方案,也没有用,而且也算了一笔账,发现确实好像没有必要去用。大家可以看到,我们通过了几层,下面的数据采集,我们有各种中间件的内容去收集,现在的互联网公司其实在这个地方做的都不是很好,就是因为用了太多开源技术,而且技术栈、中间件特点都不一样,所以在链路监控上其实做的非常欠缺,每家公司都这样。
4. ELK 时期成果
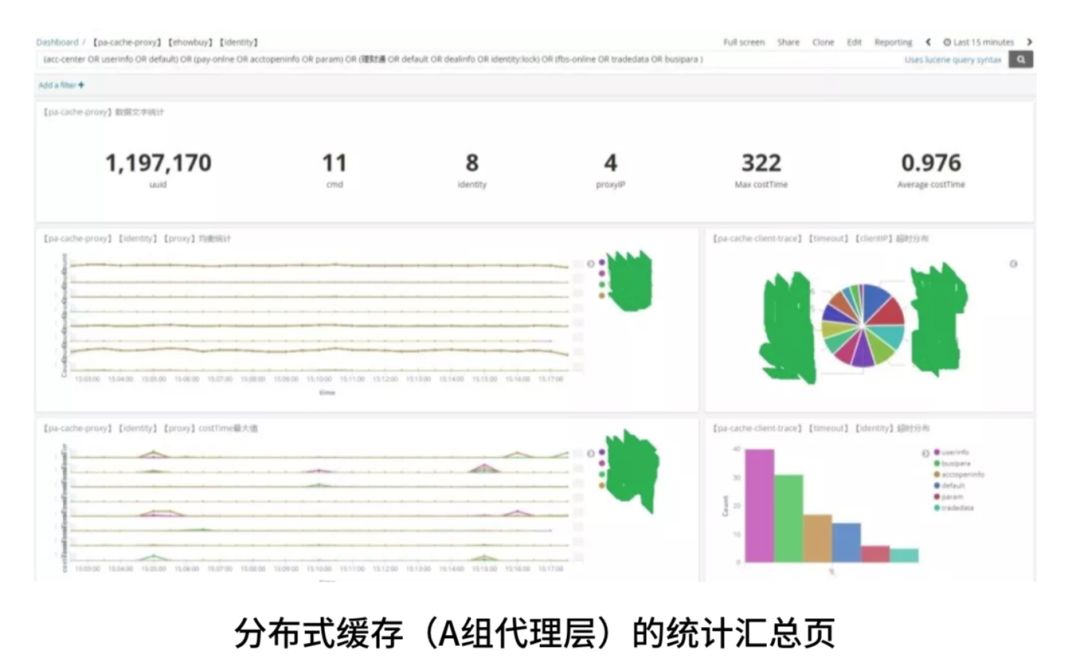
这个就是当时在 ELK 中间做的很多内容,这个是分布式缓存中的其中一个代理层切片的相关业务内容,我们可以很好地解决我们的问题,ELK 是一个非常不错的方案,我们也能做到想要的数据。
面临新需求
这个故事是不是说到这儿就结束了?你既然已经找到了方案,解决了问题,而且大家都在用,你为什么还用 Kylin 呢?
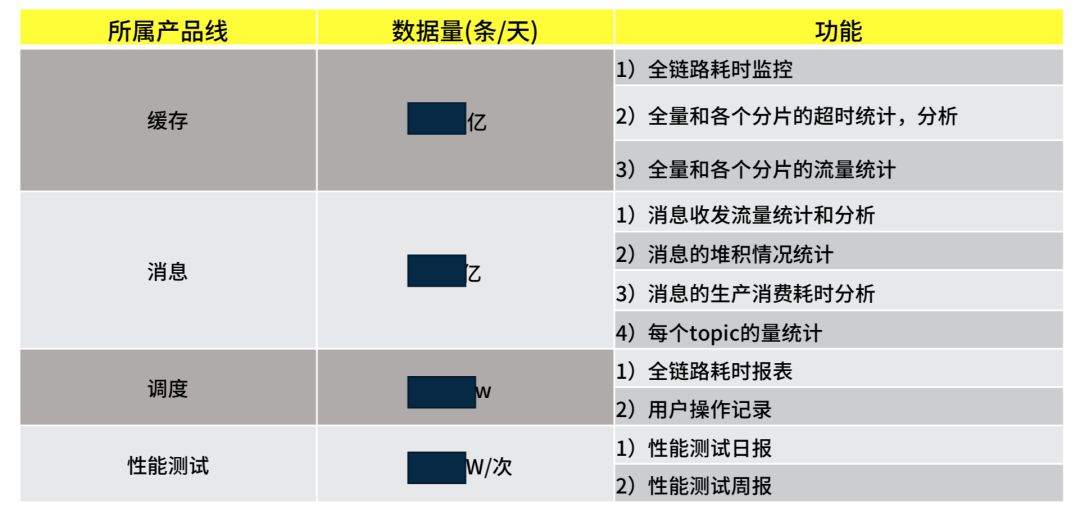
这是我们的一部分新需求。有同学说了这不是很简单吗,你刚才不是有方案了吗,你把 ELK 的节点铺多一点不就解决了吗?你会发现很多技术手段堆机器是一个最简单的方法,不要跟我说这个技术牛逼,你牛逼不过机器,加一堆机器问题都可以解决,为什么要用 Kylin 呢?
在技术选型之前,我们要思考些什么?
1. 现状
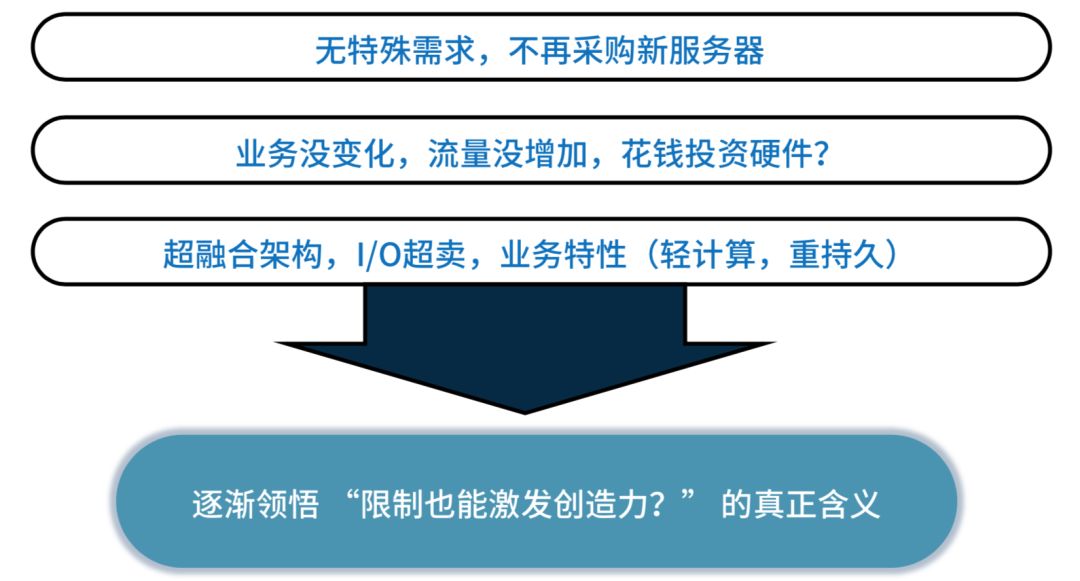
在这一两年中间金融行业遇到很多问题,红利逐渐在消失,公司流量在下降,然后公司就需要进行转型。在这个转型过程当中,公司对成本的控制是非常严的。也就是说,老板说我不会买一台机器,为什么?因为业务在变形,所以你要帮我减资源。所以第一,没有特殊需求,不能够再买服务器。
第二,业务没有变化,流量没有增加,你叫我投钱干什么?所以说很多的情况都是在于你的业务在快速发展,所以你需要技术突破,如果你业务没有进行发展,其实你是不需要突破的。
第三,这个特别重要,我不知道大家有没有看过你公司业务,你公司业务是以计算为核心,还是以你的 IO 为核心,也就是你的系统到底重 CPU 还是重 IO,大部分交易型公司基本上重 IO 轻计算,像交易要用到计算吗?计算量不会很大,我们业务也是一样,并且我们采用超融合架构,就是把所有硬件资源放在一个池子里面大家一起用,这样降低基础运维成本。
2. 目的
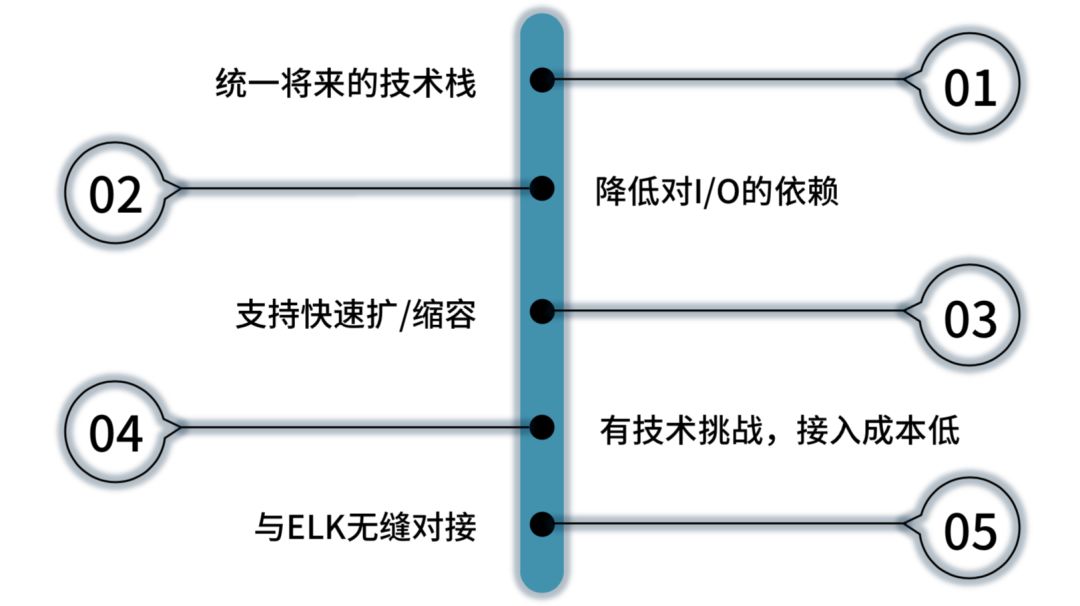
第一,我希望现在做的技术选型能统一将来的技术栈,不能够这边写脚本,那边用某某技术,必须只能用一个技术,这样人可以统一,而且你写一些技术传承的文档也很方便,要不然不好统一。
第二,降低对 I/O 依赖,ELK 中的 E 其实就是 ES,ELK 最大核心其实是把全量数据存下来,每一次做索引,对 I/O 压力很大,如果你体量越大,对于 I/O 压力越大。大数据不一样,算完以后把流水丢掉了,我只要结果。但是 ELK 就是这样,但是它架构方便,搭建简单。
第三,我要支持快速扩/缩容。因为虽然业务的形态没有变化,但是业务量与分析量在增加。
第四,有技术挑战,接入成本低。如果你不去做技术突破,你的同学会感觉没有吸引力,你需要用一些新技术去挑战他们,让这个团队稳定,这也是要考虑的。
第五,你要能跟现有的 ELK 去进行对接,不能在这个地方投入更多的研发资源。
3. Elasticsearch vs Apache Kylin
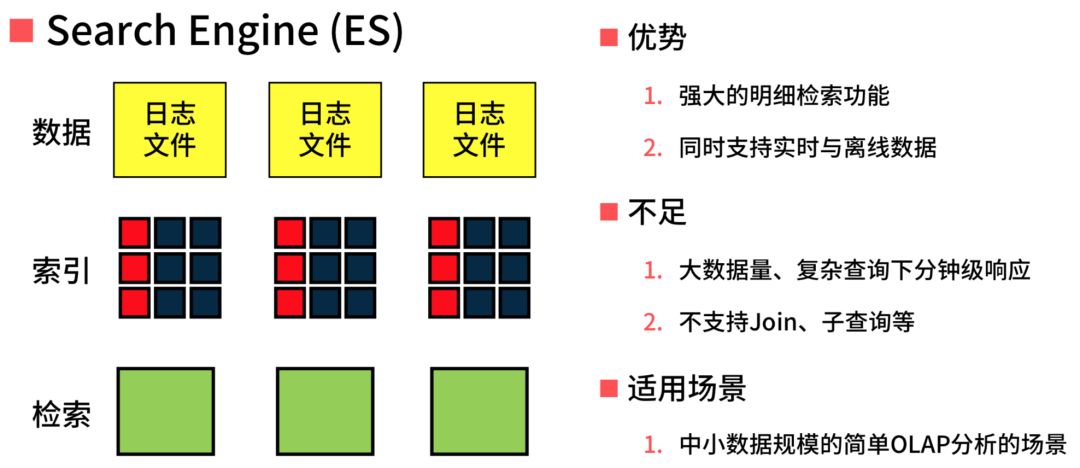
ES 检索功能非常强,另外同时支持实时跟离线数据,这个是为什么运维圈用 ELK 特别多的原因。不足的是它的数据量越大,它的速度越慢,而且对硬件需求越高,所以经常会听到 ELK 节点有几百个,上千上万个节点。ES 适用中小型规模简单的 OLAP 场景,OLAP 场景不限定于你的业务场景,你分析业务和分析运维场景一样,最后产出都是报表,在技术角度没有任何区别。
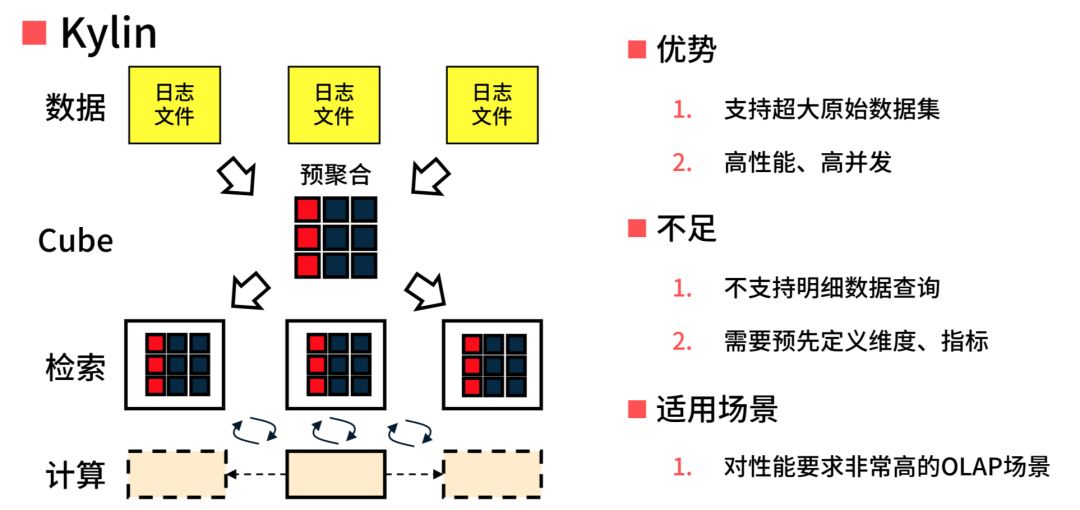
Kylin 的优势是提供亚秒级查询速度,这个优势对于我们现在的场景没用,我现在就是希望能够降低 I/O 依赖,能不能够把空间省下来,然后把我们的现在的资源倾向从 I/O 倾向到 CPU 上去,因为我 CPU 很空。所以 ES 跟 Kylin 以及大数据之间的区别,这是非常清晰的。
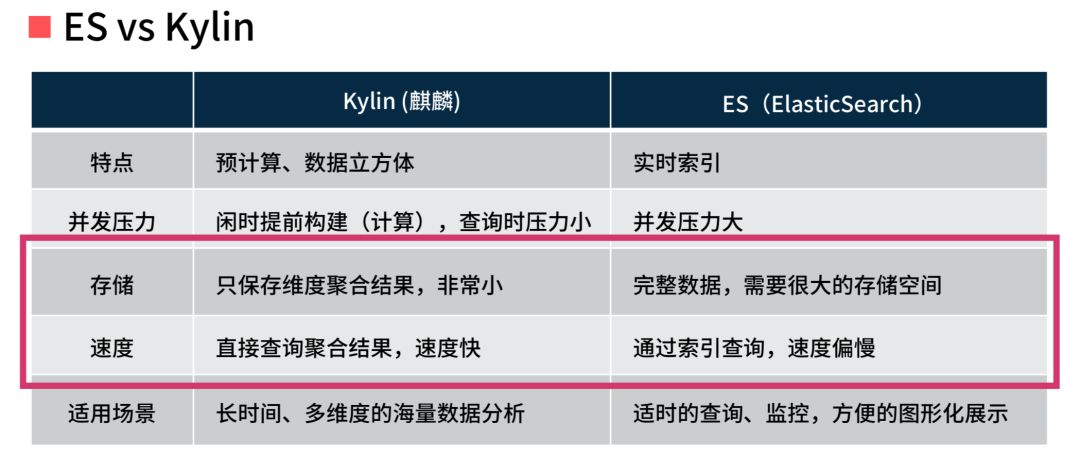
大家来看一下上图的表,红框的是我们看重的地方,像 ES 需要很大存储空间,但是在 Kylin 和大数据上是只保存维度聚合的结果数据,对I/O的依赖很小。那有同学说了,你干嘛不直接用 Hadoop,干嘛要套 Kylin 在 Hadoop 上?Kylin 其实提供了很多在用户场景中的接口,包括对接 BI 工具 Superset,提供给我们很多之前在 Hadoop 上根本用不到的东西。
在这个事情上,我就投了一个工程师,这个工程师是做分布式的,从来没有接触过 Hadoop,我花了四个月就做完了。当然,我现在还在浅水区,没有在深水区,但是它确实解决了我们的问题,大家可以看一下演讲最后的数据对比。
4. 运维 vs 业务
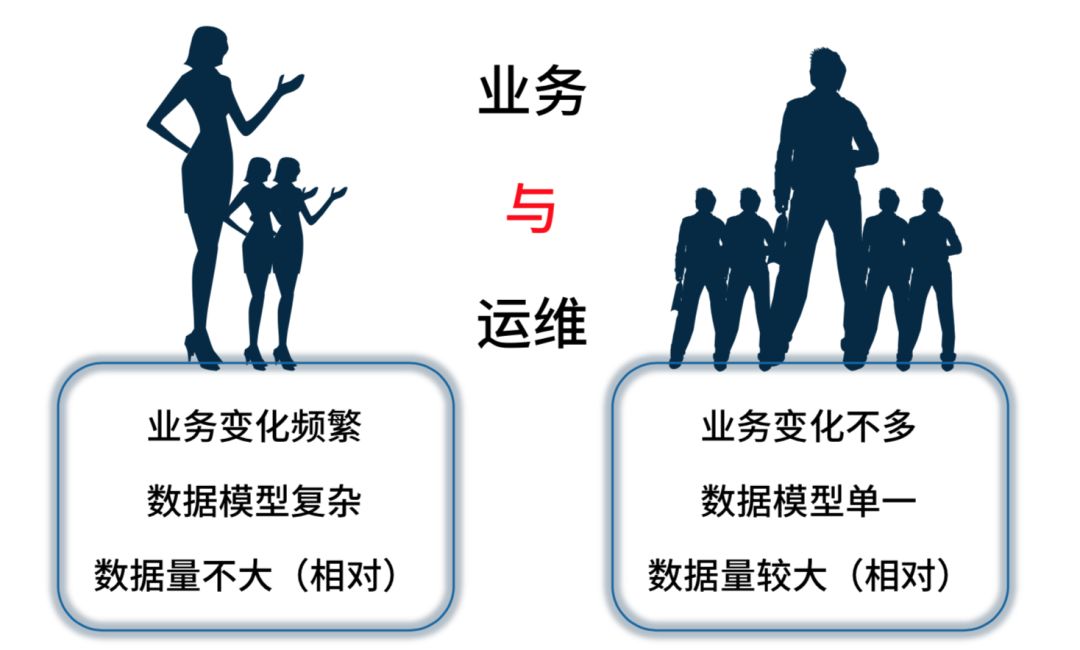
从我的角度来看,上图是我们业务和运维现在的区别,左侧是业务,右边是运维。左边业务变化很频繁,报表很频繁地变,数据模型相对比较复杂。但是对于运维来说业务变化不多,要的一些报表固化,但是数据量会变,模型不会变,数据模型变化单一,相对来说数据量会比较大。
最终成果
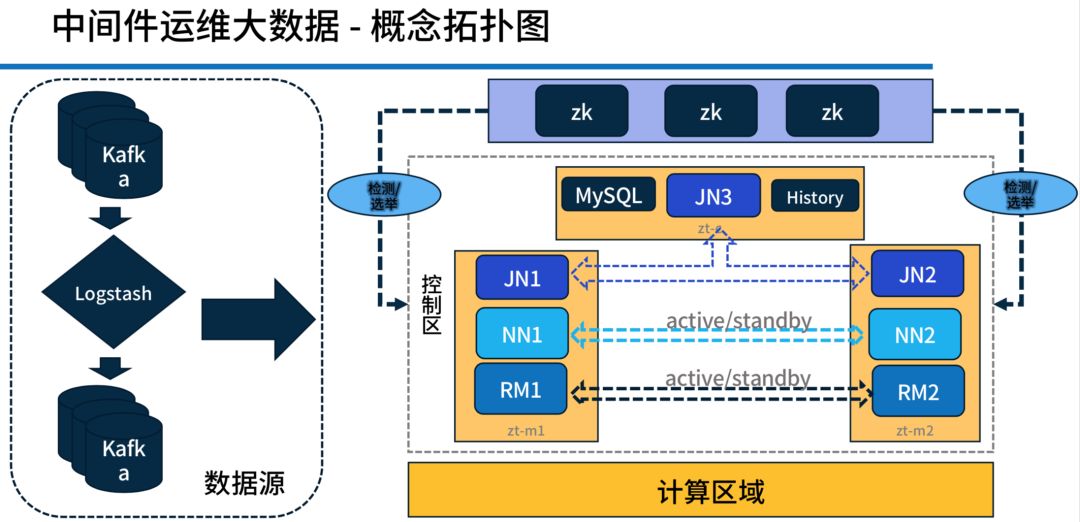
上图为架构图。右侧基本上是整个大数据的架构,大家主要看一下左边,现在的 Kylin 其实能很好地跟 ELK 中的 L(Logstash) 进行连接,直接跟 Kafka 连接就可以进行使用了,对我们来说这块成本非常低。
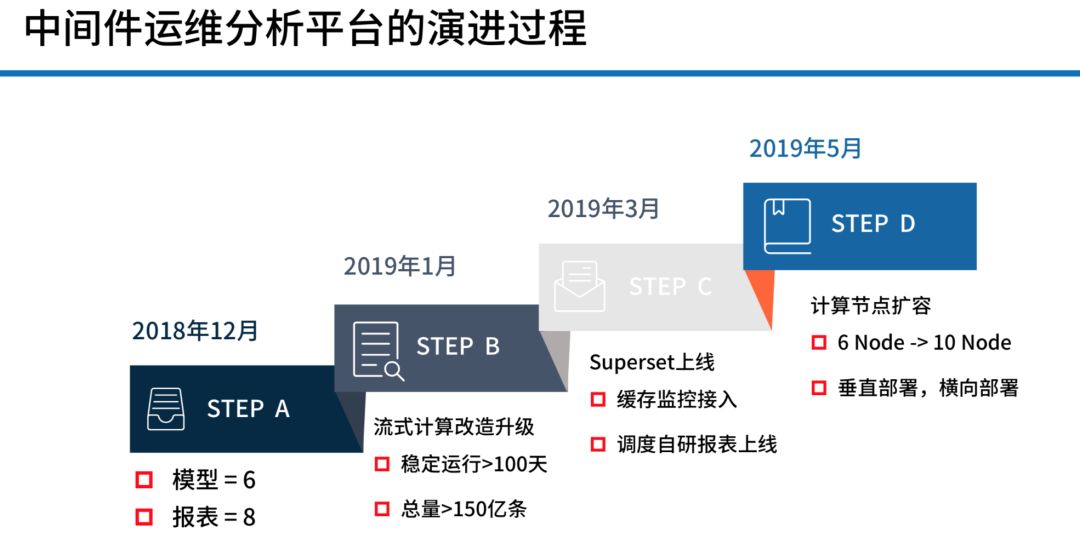
我们是从18年12月份开始做这个平台,然后花了一个月时间,开始使用流式计算,总数据量大概在150亿条这样的规模,刚才我所说的那个同学并不是全职做这套大数据的,你可以认为他是半全职方式做的。两个月以后,我们的 Superset 上线,接入了监控和自研报表。然后又过了两个月,我们计算节点从 6 Node 到 10 Node,从原先的单机复用变成了26台左右的物理机。我们做了监控调度线程、执行、资源、耗时的一些报表,数据全部都是来自于 Kylin 的。
做任何事情,一定要通过数据告诉老板你做这个东西是有收益的,就是你要么省钱,要么赚钱。IT 作为成本中心,你一定要告诉老板你如何省钱,他才会对你加大投入。
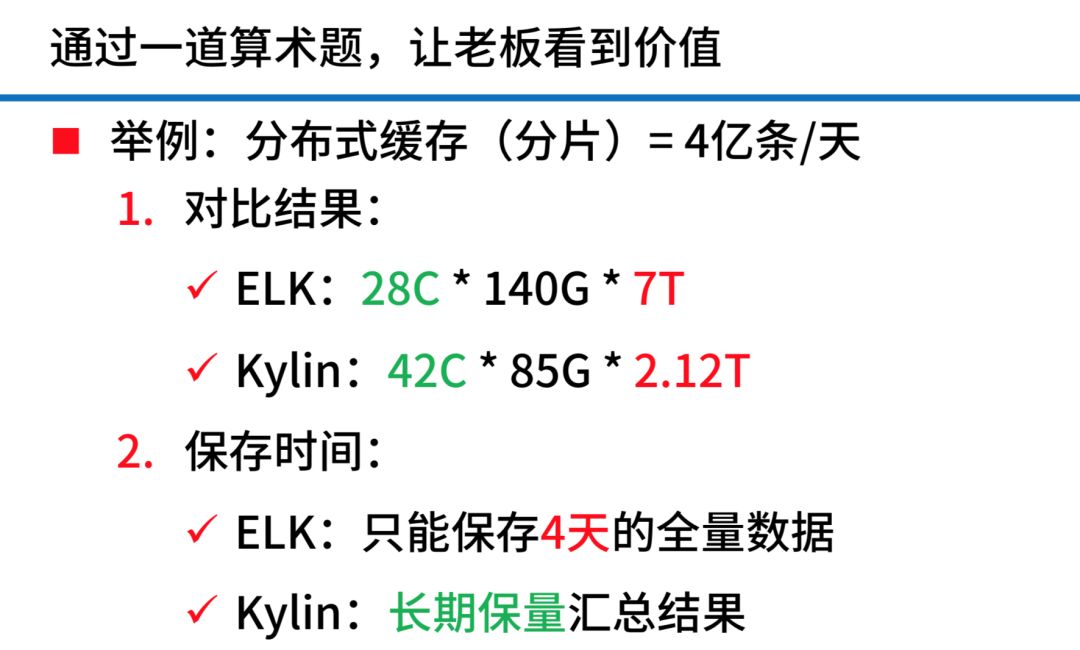
我们分布式缓存中间的部分的分片,其中有一个分片每天产生4亿条日志量,我们的对比如上图。其实就是技术栈不一样,两个技术栈,一个是重 I/O 的,一个重计算,当时在这样的场景中你选择了一个合适技术去使用,并且也做出一些成绩获得一定收益就可以了。保存的时间,如果用 ELK,我们当时公司存储量在不添加任何硬件前提下,只能保存四天的全量数据,如果用 Kylin,因为流水数据都删掉了,我可以长期保存汇总的结果,我想查多久就可以查多久。
以上整个过程证明了是因为我们的业务场景和历史运转周期到了这个时间点,触发了我需要做这件事情。我们现在这个系统运行到现在一年半时间,运行得非常好,也没有增加物理机,而且我们现在的监控和运维每天看前一天的整个运维的分布式中间件运行情况是否良好,全部靠 Kylin 提供的数据给我看的。我们也发现过很多隐患,然后解决了。
演进为啥总那么坎坷,能快一些吗?
之前有人说每次听某某公司演进都很卡壳,你能不能简单一些?可以,你跟你老板说猛砸几个亿,又快又牛逼,什么事都可以解决,关键点在于你什么时候在什么合适的场景,用什么样合适的技术,并且招到所谓合适的人,不要去提大而空的东西,实际用数据和数学的公式告诉你的老板,这个东西非常合适,他才会相信你。
当然,如果你现在公司还处于快速发展中,你不用说这个东西,因为你的业务在逼着你必须用一些东西做;如果你的公司已经进入平稳期,或者缓慢转型期、下降期的时候,你必须采用这样的模式告诉出钱的人,什么东西才最合适。
往期案例与实践
点“阅读原文”下载分享PPT
以上是关于中间件运维分析中的选型与实践的主要内容,如果未能解决你的问题,请参考以下文章
消息中间件选型分析——从Kafka与RabbitMQ的对比来看全局