精选实践 | 爱奇艺实用数据库选型树:不同场景如何快速选择数据库?
Posted AI科技大本营
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了精选实践 | 爱奇艺实用数据库选型树:不同场景如何快速选择数据库?相关的知识,希望对你有一定的参考价值。
作者 | 郭磊涛 爱奇艺数据库和中间件负责人 TiDB User Group Ambassador
来源 | 授权转载自AskTUG
本文系 TUG 线下活动 “不同业务场景下的数据库技术选型思路” 分享实录。
我是爱奇艺的数据库和中间件负责人郭磊涛,今天主要向大家分享数据库选型方面的思路,供大家参考和学习。我们进行数据库选型的时候要考虑哪些问题?有哪些需求?待选用的数据库是否和需求对的上?是不是直接就可以拿来用?需不需要一些额外的开发?这些都会在今天的分享中提及。
谁选型?是负责采购的同学、 DBA 还是业务研发?
如
果选型的是采购的同学,他们更注重成本,包括存储方式、网络需求等。
-
首先是运维成本,包括监控告警是否完善、是否有备份恢复机制、升级和迁移的成本是否高、社区是否稳定、是否方便调优、排障是否简易等;
-
其次DBA会关注稳定性,包括是否支持数据多副本、服务高可用、多写多活等;
-
第三是性能,包括延迟、QPS 以及是否支持更高级的分级存储功能等;
-
第四是扩展性,如果业务的需求不确定,是否容易横向扩展和纵向扩容;最后是安全,需要符合审计要求,不容易出现 SQL 注入或拖库情况。
除了采购和 DBA之外,后台应用研发的同学同样会关注稳定性、性能、扩展性等问题,同时也非常关注数据库接口是否便于开发,是否便于修改数据库 schema 等问题。
-
-
TiDB;爱奇艺的 TiDB 实践会有另外的具体介绍;
-
-
Couchbase,这个在爱奇艺用的比较多,但国内互联网公司用的比较少,接下来的部分会详细说明;
-
其他,比如 MongoDB、图数据库、自研 KV 数据库 HiKV 等;
-
大数据分析相关系统,比如 Hive、Impala 等等。
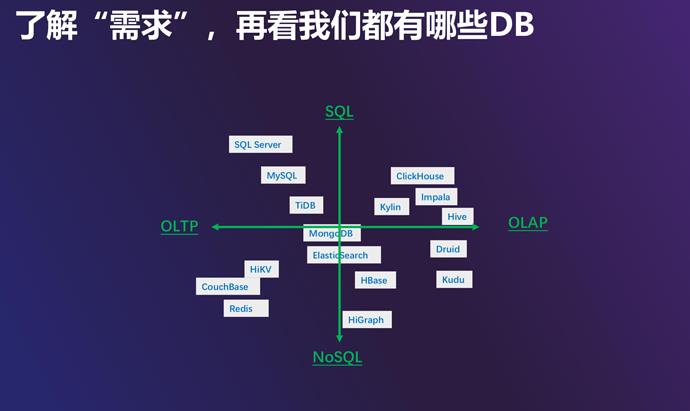
可以看到爱奇艺的数据库种类还是很多的,这会造成业务开发的同学可能不太清楚在他的业务场景下应该选用哪种数据库系统。那么,我们先对这些数据库按照接口(SQL,NoSQL)和面向的业务场景(OLTP, OLAP)这两位维度进行一个简单非严谨的分类。
左上角是面向 OLTP、支持 SQL 的这样一类系统,例如 MySQL,一般支持事务不同的隔离级别, QPS 要求比较高,延时比较低,主要用于交易信息和关键数据的存储,比如订单、VIP 信息等。
左下角是 NoSQL 数据库,是一类针对特殊场景做优化的系统,schema 一般比较简单,吞吐量较高、延迟较低,一般用作缓存或者 KV 数据库。
整个右侧都是 OLAP 的大数据分析系统,包括 Clickhouse、Impala等,一般支持SQL、不支持事务,扩展性比较好,可以通过加机器增加数据的存储量,响应延迟较长。
还有一类数据库是比较中立的,在数据量比较小的时候性能比较好,在数据量较大或复杂查询的时候性能也不差,一般通过不同的存储引擎和查询引擎来满足不同的业务需求,我们把它叫做 HTAP,TiDB 就是这样一种数据库。
前面我们提到了很多种的数据库,那么接下来就和大家介绍一下在爱奇艺我们是怎么使用这些数据库的。
MySQL 在爱奇艺的使用
首先是 MySQL。MySQL 基本使用方式是 master-slave + 半同步,支持每周全备+每日增量备份。我们做了一些基本功能的增强,首先是增强了数据恢复工具 Xtrabackup 的性能。之前遇到一个情况,我们有一个全量库是 300G 数据,增量库每天 70G 数据,总数据量 700G 左右。我们当时只需要恢复一个表的数据,但该工具不支持单表恢复,且整库恢复需要 5 个小时。针对这个情况我们具体排查了原因,发现在数据恢复的过程中需要进行多次写盘的 IO 操作并且有很多串行操作,所以我们做了一些优化,例如删减过程中的一些写盘操作,减少落盘并将数据处理并行化,优化后整库恢复耗时减少到 100 分钟,而且可以直接恢复单表数据。
第二是适配 DDL 和 DML 工具到内部系统,gh-ostt 和 oak-online-alter-table 在数据量大的时候会造成 master-slave 延时,所以我们在使用工具的时候也增加了延时上的考虑,实时探测Master-Slave 库之间延时的情况,如果延时较大会暂停工具的使用,恢复到正常水平再继续。
第二是 MySQL 高可用。Master-slave 加上半同步这种高可用方式不太完善,所以我们参照了 MHA 并进行了改动,采用 master + agent 的方式。Agent 在每一个物理机上部署,可以监控这个物理机上的所有实例的状态,周期性地向 master 发送心跳,Master 会实时监测各个Agent的状态。如果 MySQL故障,会启动 Binlog 补偿机制,并切换访问域名完成 failover。考虑到数据库跨机房跨地区部署的情况,MHA 的 master 我们也做了高可用设计,众多 master 会通过 raft 组成一个 raft group,类似 TiDB 的 PD 模块。目前 MySQL failover 策略支持三种方式:同机房、同地域跨机房以及跨地域。
第三是提高MySQL扩展能力,以提供更大容量的数据存储。扩展方式有 SDK,例如开源的 ShardingSphere,在爱奇艺的使用也比较广泛。另外就是 Proxy,开源的就更多了。但是 SDK 和 Proxy 使用的问题是支持的 SQL 语句简单,扩容难度大,依赖较多且运维复杂,所以部分业务已经迁移至 TiDB。
第四是审计。我们在 MySQL 上做了一个插件获取全量 SQL 操作,后端打到 Kafka,下游再接入包括 Clickhouse 等目标端进行 SQL 统计分析。除此之外还有安全策略,包括主动探索是否有 SQL 注入及是否存在拖库情况等,并触发对应的告警。MySQL 审计插件最大的问题是如何降低对 MySQL 性能的影响,对此我们进行了一些测试,发现使用 General Log 对性能损耗较大,有 10%~20% 的降低。于是我们通过接口来获取 MySQL 插件里的监控项,再把监控项放到 buffer 里边,用两级的 RingBuffer 来保证数据的写入不会有锁资源竞争。在这个插件里再启动一个线程,从 RingBuffer 里读取数据并把数据打包写到 FIFO 管道里。我们在每台 MySQL 的物理机里再启动一个 Agent,从管道里阻塞地读取数据发至 Kafka。优化后我们再次进行压测,在每台机器上有 15 万的更新、删除或插入操作下不会丢失数据,性能损耗一般情况下小于 2%。目前已经在公司内部的集群上线了一年时间,运行比较稳定,上线和下线对业务没有影响。
第五是分级存储。MySQL 里会存一些过程性的数据,即只需要读写最近一段时间存入的数据,过段时间这些数据就不需要了,需要进行定时清理。分级存储就是在 MySQL 之上又用了其他存储方式,例如 TiDB 或其他 TokuDB,两者之间可以进行数据自动搬迁和自动归档,同时前端通过 SDK + Proxy 来做统一的访问入口。这样一来,业务的开发同学只需要将数据存入 MySQL 里,读取时可能从后端接入的任意数据库读出。这种方式目前只是过渡使用,之后会根据 TiDB 的特性进行逐步迁移。
Redis 在爱奇艺的使用
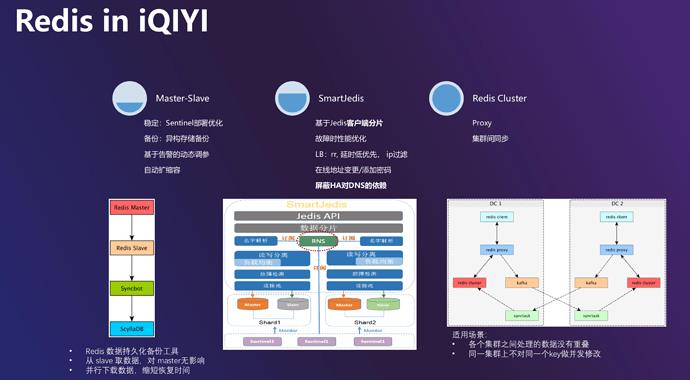
接下来是 Redis。Redis 也是使用 master - slave 这种方式,由于网络的复杂性我们对 Sentinel 的部署进行了一些特殊配置,在多机房的情况下每个机房配置一定数量 Sentinel 来避免脑裂。
备份恢复方面介绍一个我们的特殊场景,虽然 Redis 是一个缓存,但我们发现不少的业务同学会把它当做一个 KVDB 来使用,在某些情况下会造成数据的丢失。所以我们做了一个 Redis 实时备份功能,启动一个进程伪装成 Redis 的 Slave 实时获取数据,再放到后端的 KV 存储里,例如 ScyllaDB,如果要恢复就可以从 ScyllaDB 里把数据拉出来。我们在用 Redis 时最大的痛点就是它对网络的延迟或抖动非常敏感。如有抖动造成 Redis Master 超时,会由 Sentinel 重新选出一个新的节点成为 Master,再把该节点上的数据同步到所有 Slave 上,此过程中数据会放在 Master 节点的 Buffer 里,如果写入的 QPS 很高会造成 Buffer 满溢。如果 Buffer 满后 RDB 文件还没有拷贝过去,重建过程就会失败。
基于这种情况,我们对 Redis 告警做了自动化优化,如有大量 master - slave 重建失败,我们会动态调整一些参数,例如把 Buffer 临时调大等, 此外我们还做了 Redis 集群的自动扩缩容功能。
我们在做 Redis 开发时如果是 Java 语言都会用到 Jedis。用 Jedis 访问客户端分片的 Redis 集群,如果某个分片发生了故障或者 failover,Jedis 就会对所有后端的分片重建连接。如果某一分片发生问题,整个 Redis 的访问性能和 QPS 会大幅降低。针对这个情况我们优化了 Jedis,如果某个分片发生故障,就只针对这个分片进行重建。
在业务访问 Redis 时我们会对 Master 绑定一个读写域名,多个从库绑定读域名。但如果我们进行 Master failover,会将读写域名从某旧 Master 解绑,再绑定到新 Master 节点上。DNS 本身有一个超时时间,所以数据库做完 failover 后业务程序里没有立刻获取到新的 Master 节点的 IP的话,有可能还会连到原来的机器上,造成访问失败。我们的解决方法是把 DNS 的 TTL 缩短,但对 DNS 服务又会造成很大的压力,所以我们在 SDK 上提供 Redis 的名字服务 RNS,RNS 从 Sentinel 里获取集群的拓扑和拓扑的变化情况,如果集群 failover,Sentinel 会接到通知,客户端就可以通过 RNS 来获取新的 Master 节点的 IP 地址。我们去掉域名,通过 IP 地址来访问整个集群,屏蔽了 DNS 的超时,缩短了故障的恢复时间。SDK 上还做了一些功能,例如 Load Balance 以及故障检测,比如某个节点延时较高的话会被临时熔断等。
客户端分片的方式会造成 Redis 的扩容非常痛苦,如果客户端已经进行了一定量的分片,之后再增加就会非常艰难。Redis 在 3.0 版本后会提供 Redis Cluster,因为功能受限在爱奇艺应用的不是很多,例如不支持显示跨 DC 部署和访问,读写只在主库上等。我们某些业务场景下会使用 Redis 集群,例如数据库访问只发生在本 DC,我们会在 DC 内部进行 Cluster 部署。但有些业务在使用的过程中还是想做 failover,如果集群故障可以切换到其他集群。根据这种情况我们做了一个 Proxy,读写都通过它来进行。写入数据时 Proxy 会做一个旁路,把新增的数据写在 Kafka 里,后台启用同步程序再把 Kafka 里的数据同步到其他集群,但存在一些限制,比如我们没有做冲突检测,所以集群间数据需要业务的同学做单元化。线上环境的Redis Cluster 集群间场景跨 DC 同步 需要 50 毫秒左右的时间。
Couchbase 在爱奇艺的使用
Redis 虽然提供 Cluster 这种部署方式,但存在一些问题。所以数据量较大的时候(经验是 160G),就不推荐 Redis 了,而是采用另一种存储方式 Couchbase。
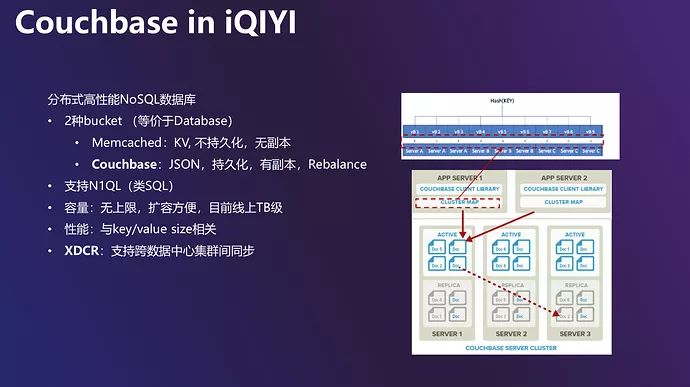
Couchbase 在国内互联网公司用的比较少,一开始我们是把他当做一个 Memcached 来使用的,即纯粹的缓存系统。但其实它性能还是比较强大的,是一个分布式高性能的 KV 系统,支持多种存储引擎 (bucket)。第一种是 Memcached bucket,使用方式和 Memcached 一样为 KV 存储,不支持数据持久化也没有数据副本,如果节点故障会丢失数据;第二种是 Couchbase bucket,支持数据持久化,使用 Json 写入,有副本,我们一般会在线上配置两个副本,如果新加节点会对数据进行 rebalance,爱奇艺使用的一般是 Couchbase bucket 这种配置。Couchbase 数据的分布如右图,数据写入时在客户端上会先进行一次哈希运算,运算完后会定位 Key 在哪一个 vBucket (相当于数据库里的某个分片)。之后客户端会根据 Cluster Map 发送信息至对应的服务端,客户端的 Cluster Map 保存的是 vBucket 和服务器的映射关系,在服务端数据迁移的过程中客户端的 Cluster Map 映射关系会动态更新,因此客户端对于 服务端的 failover 操作不需要做特殊处理,但可能在 rebalance 过程中会有短暂的超时,导致的告警对业务影响不大。
Couchbase 在爱奇艺应用比较早,2012 年还没有 Redis Cluster 的时候就开始使用了。集群管理使用 erlang 语言开发,最大功能是进行集群间的复制,提供多种复制方式:单向、双向、星型、环式、链式等。爱奇艺从最初的 1.8 版本使用到如今的 5.0 版本,正在调研 6.0。中间也遇到了很多坑,例如 NTP 时间配置出错会导致崩溃,如果每个集群对外 XDCR 并发过高导致不稳定,同步方向变更会导致数据丢失等等,我们通过运维和一些外部工具来进行规避。
Couchbase 的集群是独立集群,集群间的数据同步通过 XDCR,我们一般配置为双向同步。对于业务来说,如果 Cluster 1 写入, Cluster 2 不写入,正常情况下客户端会写 Cluster 1。如果 Cluster 1 有故障,我们提供了一个 Java SDK,可以在配置中心把写入更改到 Cluster 2,把原来到 Cluster 1 的连接逐步断掉再与Cluster 2 新建连接。这种集群 failover 的过程对于客户端来说是相对透明和无感的。
爱奇艺自研数据库 HiKV 的使用
Couchbase 虽然性能非常高,并且数据的存储可以超过内存。但是,如果数据量超过内存 75% 这个阈值,性能就会下降地特别快。在爱奇艺,我们会把数据量控制在可用内存的范围之内,当做内存数据库使用。但是它的成本非常高,所以我们后面又开发了一个新的数据库—— HiKV。
开发 HiKV 的目的是为了把一些对性能要求没那么高的 Couchbase 应用迁移到 HiKV 上。HiKV 基于开源系统 ScyllaDB,主要使用了其分布式数据库的管理功能,增加了单机存储引擎 HiKV。ScyllaDB 比较吸引人的是它宣称性能高于 Cassandra 十倍,又完全兼容 Cassandra 接口,设计基本一致,可以视为 C++ 版 Cassandra 系统。ScyllaDB 性能的提升主要是使用了一些新的技术框架,例如 C++ 异步框架 seastar,主要原理是在j每台物理机的核上会 attach 一个应用线程,每个核上有自己独立的内存、网络、IO 资源,核与核之间没有数据共享但可以通信,其最大的好处是内存访问无锁,没有冲突过程。当一个数据读或写到达 ScyllaDB 的 server 时,会按照哈希算法来判断请求的 Key 是否是该线程需要处理的,如果是则本线程处理,否则会转发到对应线程上去。除此之外,它还支持多副本、多数据中心、多写多活,功能比较强大。
在爱奇艺,我们基于 SSD 做了一个 KV 存储引擎。Key 放在内存里,Value 放在盘上的文件里,我们在读和写文件时,只需要在内存索引里定位,再进行一次盘的 IO 开销就可以把数据读出来,相比 ScyllaDB 原本基于 LSM Tree 的存储引擎方式对 IO 的开销较少。索引数据全部放在内存中,如果索引长度较长会限制单机可存储的数据量,于是我们通过开发定长的内存分布器,对于比较长的 Key 做摘要缩短长度至 20 字节,采用红黑树索引,限制每条记录在内存里的索引长度至为 64 字节。内存数据要定期做 checkpoint,客户端要做限流、熔断等。
HiKV 目前在爱奇艺应用范围比较大,截至目前已经替换了 30% 的 Couchbase,有效地降低了存储成本。
爱奇艺的数据库运维管理
爱奇艺数据库种类较多,如何高效地运维和管理这些数据库也是经历了不同的阶段。
最初我们通过 DBA 写脚本的方式管理,如果脚本出问题就找 DBA,导致了 DBA 特别忙碌。
第二个阶段我们考虑让大家自己去查问题的答案,于是在内部构建了一个私有云,通过 Web 的方式展示数据库运行状态,让业务的同学可以自己去申请集群,一些简单地操作也可以通过自服务平台实现,解放了 DBA。一些需要人工处理的大型运维操作经常会造成一些人为故障,敲错参数造成数据丢失等。
于是在第三个阶段我们把运维操作 Web 化,通过网页点击可以进行 90% 的操作。
第四个阶段让经验丰富的 DBA 把自身经验变成一些工具,比如有业务同学说 MySQL master-slave 延时了,DBA 会通过一系列操作排查问题。现在我们把这些操作串起来形成一套工具,出问题时业务的同学可以自己通过网页上的一键诊断工具去排查,自助进行处理。除此之外我们还会定期做预警检查,对业务集群里潜在的问题进行预警报告;开发智能客服,回答问题;通过监控的数据对实例打标签,进行削峰填谷地智能调度,提高资源利用率。
实用数据库选型树:快速进行数据库选型
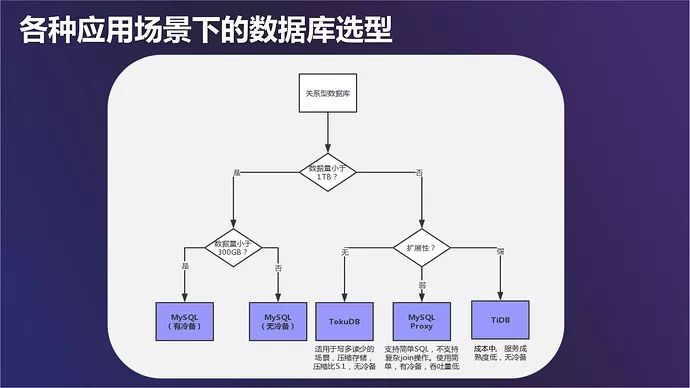
最后来说一些具体数据库选型建议。这是 DBA 和业务一起,通过经验得出来的一些结论。对于关系型数据库的选型来说,可以从数据量和扩展性两个维度考虑,再根据数据库有没有冷备、要不要使用 Toku 存储引擎,要不要使用 Proxy 等等进行抉择。
NoSQL 也是什么情况下使用 master-slave,什么情况下使用客户端分片、集群、Couchbase、HiKV 等,我们内部自服务平台上都有这个选型树信息。
一些思考
我们在选形时先思考需求,判断需求是否真实。你可以从数据量、QPS、延时等方面考虑需求,但这些都是真实需求吗?是否可以通过其他方式把这个需求消耗掉,例如在数据量大的情况下可以先做数据编码或者压缩,数据量可能就降下来了。不要把所有需求都推到数据库层面,它其实是一个兜底的系统。
第二个思考的点是对于某个数据库系统或是某个技术选型我们应该考虑什么?是因为热门吗?还是因为技术上比较先进?但是不是能真正地解决你的问题?如果你数据量不是很大的话就不需要选择可以存储大数据量的系统。
第三是放弃,当你放弃一个系统时真的是因为不好用吗?还是没有用好?放弃一个东西很难,但在放弃时最好有一个充分的理由,包括实测的结果。
第四是自研,在需要自己开发数据库时可以参考和使用一些成熟的产品,但不要盲目自研。
大家在数据库选型中会考虑哪些因素呢?欢迎评论留言告诉大家你的想法~
(*本文为AI科技大本营投稿文章,转载请微信联系 1092722531)
以上是关于精选实践 | 爱奇艺实用数据库选型树:不同场景如何快速选择数据库?的主要内容,如果未能解决你的问题,请参考以下文章
深度学习核心技术精讲100篇(五十)-爱奇艺逗芽表情搜索分析与实践
HBase 在爱奇艺的应用实践
Flink 在爱奇艺广告业务的实践
Flink 在爱奇艺广告业务的实践
爱奇艺数据中台的数据治理实践
长连接网关技术专题:爱奇艺WebSocket实时推送网关技术实践