excel 如何在时间数据出现间断的数据行前面 插入空白行
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了excel 如何在时间数据出现间断的数据行前面 插入空白行相关的知识,希望对你有一定的参考价值。
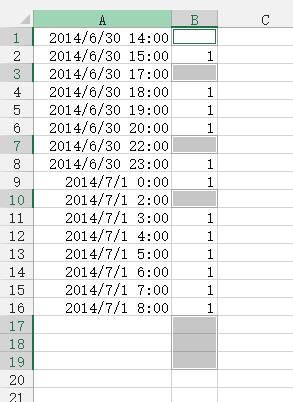
如下图:A列为时间数据,但数据不连续,间断点的出现没有规律。想在时间出现间断的数据行(如黄色标记)前面自动添加一行 或 多行 空白行,应该如何实现?
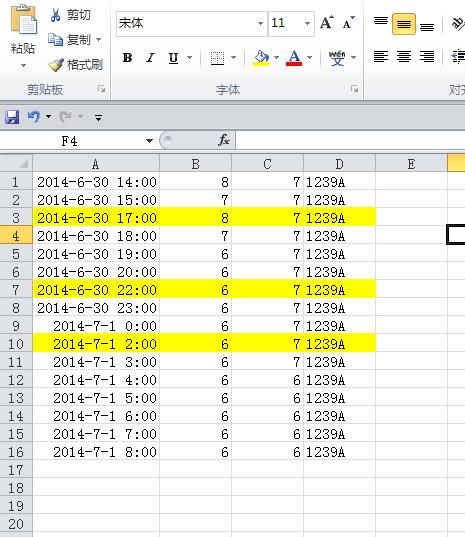
1.在E列选择一个“无间断点的时间序列”,简单方法之一,在E1中输入:2014/6/30 14:00 E2中输入:2014/6/30 15:00,然后选择E1:E2,向下拖拉复制到与A列最后一行相同的时间序列出现。
2. 在F列中引用A列数据,当A列数据不在E列中出现时,就填充为空值,F1公式:
=IF(ISERROR(MATCH(E1,$A$1:$A$16,0)),"",E1)
向下拖拉复制到与E列平齐。
3. 在G1中输入公式:
=IF($F1="","",INDEX($B$1:$D$16,MATCH($F1,$A$1:$A$16,0),COLUMN(A:A)))
向右拖拉复制到I1,再选择G1:I1,向下拖拉复制到与F列平齐。把B、C、D列数据引用到G、H、I列。如图:
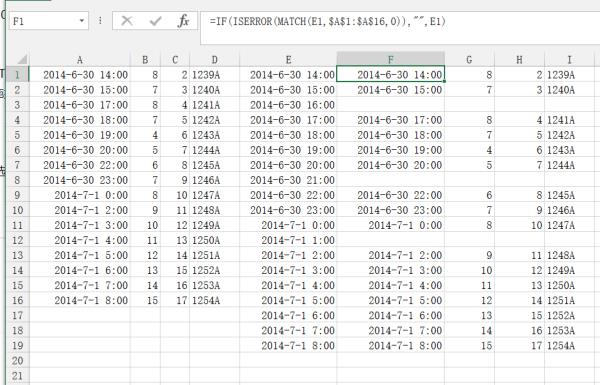
4. 如果需要把数据放到原数据A~D列,就选择F~I列数据——复制——选择A1单元格——右键——选择性粘贴——数值。
参考技术A 换个思路吧,先生成时间序列(可以用自动填充),然后根据时间序列vlookup查找匹配后面对应的值,就行了追问谢谢,能否麻烦再具体指点一下
参考技术B 插入一行可实现,插入多好需要VBA支持追问请问插入1行 如何实现
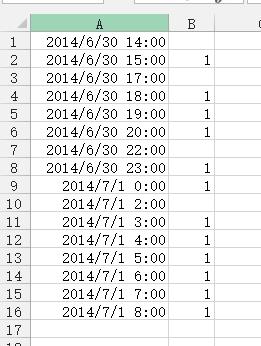
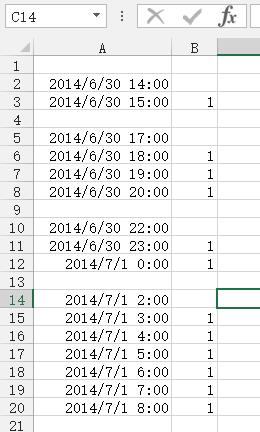
追答1、利用辅助列,在辅助列第二行输入以下公式:
=ROUND((A2-A1)*24,0)
填充公式到最后一行,结果如下图所示:

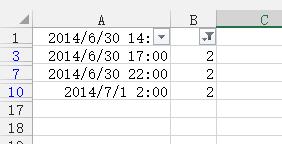
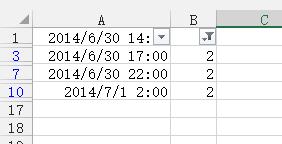
2、根据辅助列筛选,筛选不等于1的记录,结果如下图所示:
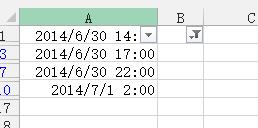
3、根据筛选结果删除这些不等于1的值,结果如下图所示:
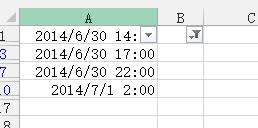
4、取消筛选,结果如下图所示:
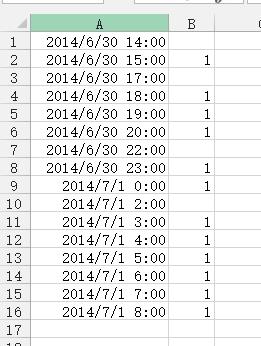
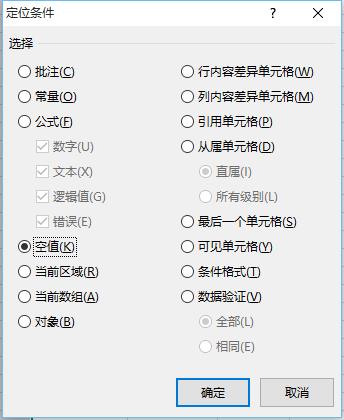
5、选择辅助列,按Ctrl+G,点击“定位条件”,按下图进行设置
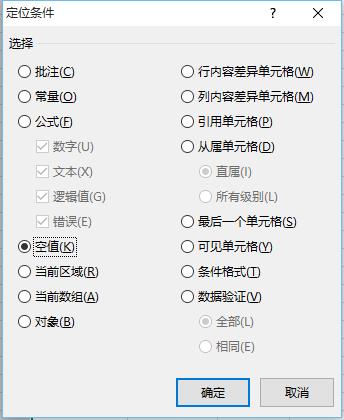
6、点击确定,结果如下图所示:
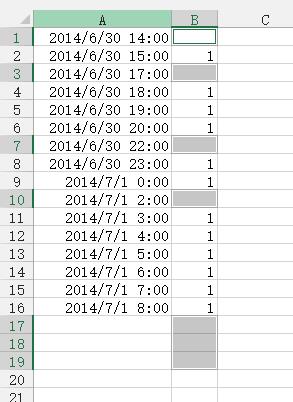
7、右击任意有底色的单元格,在右键菜单中选择插入,然后在弹出的对话框中选择整行,点击确定即可,效果如下图所示:
在n级列中逐行分类excel数据
【中文标题】在n级列中逐行分类excel数据【英文标题】:classifing excel data row by row in n level columns 【发布时间】:2021-12-25 17:24:39 【问题描述】:我在使用 excel 文件对某些列和行中的数据进行分类时遇到问题,我需要将合并单元格排列到下一列作为 1 行,并且下一列像这张图片一样放在它们旁边:
输入:
乳制品输出:
总结:
首先我们取Dairy行,然后我们到Dairy前面的第二列,得到Dairy前面的数据,然后我们到第二列,在Milk to Mr. 1前面我们得到Butter to Mrs. 1 和 Butter to Mrs. 2 等等...
之后,我们要将其导出到输出图片中的 excel 文件中。
我编写了一个代码,它获取第一列数据并找到它前面的所有数据,但我需要更改它以便像输出图片中那样逐行获取数据:
import pandas
import openpyxl
import xlwt
from xlwt import Workbook
df = pandas.read_excel('excel.xlsx')
result_first_level = []
for i, item in enumerate(df[df.columns[0]].values, 2):
if pandas.isna(item):
result_first_level[-1]['index'] = i
else:
result_first_level.append(dict(name=item, index=i, levels_name=[]))
for level in df.columns[1:]:
move_index = 0
for i, obj in enumerate(result_first_level):
if i == 0:
for item in df[level].values[0:obj['index'] - 1]:
if pandas.isna(item):
move_index += 1
continue
else:
obj['levels_name'].append(item)
move_index += 1
else:
for item in df[level].values[move_index:obj['index'] - 1]:
if pandas.isna(item):
move_index += 1
continue
else:
obj['levels_name'].append(item)
move_index += 1
# Workbook is created
wb = Workbook()
# add_sheet is used to create sheet.
sheet1 = wb.add_sheet('Sheet 1')
style = xlwt.easyxf('font: bold 1')
move_index = 0
for item in result_first_level:
for member in item['levels_name']:
sheet1.write(move_index, 0, item['name'], style)
sheet1.write(move_index, 1, member)
move_index += 1
wb.save('test.xls')
从here下载Input File excel
感谢您的帮助!
【问题讨论】:
检查 'xlwings' 库,如果对您有用,将数据导入为 pandas 数据框,docs.xlwings.org/en/stable/datastructures.html @LorenzoBassetti 我一开始就得到了熊猫数据框,但我在将数据排列成 2 列时遇到了问题 可能对 A1-A12 重复“日记”......然后从 A13 到 A18 等重复“水果”等可能很有用,这样您就可以简单地阅读该行。您正在使用的合并单元格基本上只是 Excel 的“视觉”技巧,但是 A1 的值为 'Diary' ,而 A2...A12 的值为“null”。我建议不要使用合并单元格。 @LorenzoBassetti basedata 是合并的单元格,我对此无能为力,所以您可以添加答案并添加代码以便我更好地理解您吗? 请问您可以分享您的示例 excel 文件吗?使用networkx来解决这个问题。
【参考方案1】:
首先,填写您的数据以使用最后一个有效值填充空白单元格,然后使用pd.CategoricalDtype 创建有序集合以对product 列进行排序。最后,您只需成对地遍历列并重命名列以允许连接。最后一步是按product 值对行进行排序。
import pandas as pd
# Prepare your dataframe
df = pd.read_excel('input.xlsx').dropna(how='all')
df.update(df.iloc[:, :-1].ffill())
df = df.drop_duplicates()
# Get keys to sort data in the final output
cats = pd.CategoricalDtype(df.T.melt()['value'].dropna().unique(), ordered=True)
# Group pairwise values
data = []
for cols in zip(df.columns, df.columns[1:]):
col_mapping = dict(zip(cols, ['product', 'subproduct']))
data.append(df[list(cols)].rename(columns=col_mapping))
# Merge all data
out = pd.concat(data).drop_duplicates().dropna() \
.astype(cats).sort_values('product').reset_index(drop=True)
输出:
>>> cats
CategoricalDtype(categories=['Dairy', 'Milk to Mr.1', 'Butter to Mrs.1',
'Butter to Mrs.2', 'Cheese to Miss 2 ', 'Cheese to Mr.2',
'Milk to Miss.1', 'Milk to Mr.5', 'yoghurt to Mr.3',
'Milk to Mr.6', 'Fruits', 'Apples to Mr.6',
'Limes to Miss 5', 'Oranges to Mr.7', 'Plumbs to Miss 5',
'apple for mr 2', 'Foods & Drinks', 'Chips to Mr1',
'Jam to Mr 2.', 'Coca to Mr 5', 'Cookies to Mr1.',
'Coca to Mr 7', 'Coca to Mr 6', 'Juice to Miss 1',
'Jam to Mr 3.', 'Ice cream to Miss 3.', 'Honey to Mr 5',
'Cake to Mrs. 2', 'Honey to Miss 2',
'Chewing gum to Miss 7.'], ordered=True)
>>> out
product subproduct
0 Dairy Milk to Mr.1
1 Dairy Cheese to Mr.2
2 Milk to Mr.1 Butter to Mrs.1
3 Milk to Mr.1 Butter to Mrs.2
4 Butter to Mrs.2 Cheese to Miss 2
5 Cheese to Mr.2 Milk to Miss.1
6 Cheese to Mr.2 yoghurt to Mr.3
7 Milk to Miss.1 Milk to Mr.5
8 yoghurt to Mr.3 Milk to Mr.6
9 Fruits Apples to Mr.6
10 Fruits Oranges to Mr.7
11 Apples to Mr.6 Limes to Miss 5
12 Oranges to Mr.7 Plumbs to Miss 5
13 Plumbs to Miss 5 apple for mr 2
14 Foods & Drinks Chips to Mr1
15 Foods & Drinks Juice to Miss 1
16 Foods & Drinks Cake to Mrs. 2
17 Chips to Mr1 Jam to Mr 2.
18 Chips to Mr1 Cookies to Mr1.
19 Jam to Mr 2. Coca to Mr 5
20 Cookies to Mr1. Coca to Mr 6
21 Cookies to Mr1. Coca to Mr 7
22 Juice to Miss 1 Honey to Mr 5
23 Juice to Miss 1 Jam to Mr 3.
24 Jam to Mr 3. Ice cream to Miss 3.
25 Cake to Mrs. 2 Chewing gum to Miss 7.
26 Cake to Mrs. 2 Honey to Miss 2
【讨论】:
@MasOOd.KamYab,我希望这能解决你的问题,我的解释也足够清楚。 谢谢,但它在数据中间粉碎,如第 8 行不正确,我对 pandas 了解不多,所以如果你能修复这个错误,我会接受你的回答 我更新了我的答案,但我无法获得您的数据框的正确顺序。它看起来像 DFS(深度优先搜索)树,但不是因为您的第二行(Dairy, Cheese to Mr.2)不在正确的位置。以上是关于excel 如何在时间数据出现间断的数据行前面 插入空白行的主要内容,如果未能解决你的问题,请参考以下文章
mysql按照每天/每月等统计数据(连续不间断,当天/月没有数据为0)