AP聚类算法介绍
Posted 大数据和人工智能
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了AP聚类算法介绍相关的知识,希望对你有一定的参考价值。
Affinity Propagation (AP) 聚类是2007年在Science杂志上提出的一种新的聚类。它根据N个数据点之间的相似度进行聚类,这些相似度可以是对称的,即两个数据点互相之间的相似度一样(如欧氏距离);也可以是不对称的,即两个数据点互相之间的相似度不等。这些相似度组成N×N的相似度矩阵S(其中N为有N个数据点)。
在这里介绍几个文中常出现的名词:
exemplar:指的是聚类中心。
similarity:数据点i和点j的相似度记为S(i,j)。是指点j作为点i的聚类中心的相似度。
preference:数据点i的参考度称为P(i)或S(i,i)。是指点i作为聚类中心的参考度。一般取S相似度值的中值。
Responsibility:R(i,k)用来描述点k适合作为数据点i的聚类中心的程度。
Availability:A(i,k)用来描述点i选择点k作为其聚类中心的适合程度。
Damping factor:阻尼系数,主要是起收敛作用的。
算法优缺点:
[1] 与众多聚类算法不同,AP聚类不需要指定K(经典的K-Means)或者是其他描述聚类个数(SOM中的网络结构和规模)的参数。
[2] 一个聚类中最具代表性的点在AP算法中叫做Examplar,与其他算法中的聚类中心不同,examplar是原始数据中确切存在的一个数据点,而不是由多个数据点求平均而得到的聚类中心(K-Means)。
[3] 多次执行AP聚类算法,得到的结果是完全一样的,即不需要进行随机选取初值步骤。
[4] 算法复杂度较高,为O(N*N*logN),而K-Means只是O(N*K)的复杂度。因此当N比较大时(N>3000),AP聚类算法往往需要算很久。。
[*5] 若以误差平方和来衡量算法间的优劣,AP聚类比其他方法的误差平方和都要低。(无论k-center clustering重复多少次,都达不到AP那么低的误差平方和)
[*6] AP通过输入相似度矩阵来启动算法,因此允许数据呈非欧拉分布,也允许非常规的点-点度量方法。
算法描述:
假设
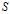 是一个刻画点之间相似度的矩阵,使得s(i,j)>s(i,k)当且仅当xi与Xj的相似性程度要大于其与Xk的相似性。
是一个刻画点之间相似度的矩阵,使得s(i,j)>s(i,k)当且仅当xi与Xj的相似性程度要大于其与Xk的相似性。
AP算法进行交替两个消息传递的步骤,以更新两个矩阵:
吸引信息(responsibility)矩阵R:r(i,k)描述了数据对象k适合作为数据对象i的聚类中心的程度,表示的是从i到k的消息;
归属信息(availability)矩阵A,a(i,k)描述了数据对象i选择数据对象k作为其据聚类中心的适合程度,表示从k到i的消息。
两个矩阵R ,A中的全部初始化为0. 可以看成Log-概率表。这个算法通过以下步骤迭代进行:
首先,吸引信息(responsibility)按照
然后,归属信息(availability)
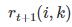 按照
按照
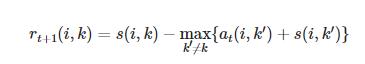
的迭代。
然后,归属信息(availability)
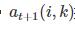 按照
按照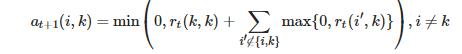
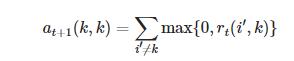
迭代。
对以上步骤进行迭代,如果这些决策经过若干次迭代之后保持不变或者算法执行超过设定的迭代次数,又或者一个小区域内的关于样本点的决策经过数次迭代后保持不变,则算法结束。
为了避免振荡,AP算法更新信息时引入了衰减系数
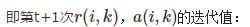
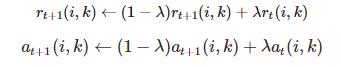
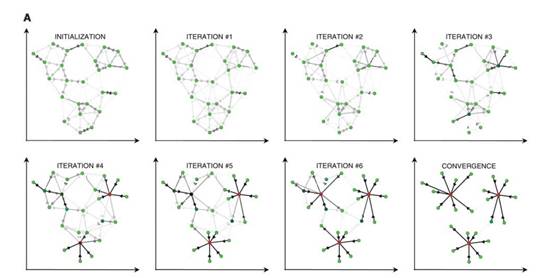
算法实现过程图

缺少数据资源,无以谈产业
缺少数据思维,无以言未来
以上是关于AP聚类算法介绍的主要内容,如果未能解决你的问题,请参考以下文章