聚类算法从理论到实践
Posted TalkingData数据学堂
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了聚类算法从理论到实践相关的知识,希望对你有一定的参考价值。
引言
本文是 TalkingData 数据产品经理何兴权老师在学习人大课程之后,将理论付诸实践,写的一篇聚类算法的实践心得。
一直强调学以致用,理论应用于实践。《邂逅统计学》是理论加实践,但实践主要是作业演练,还可以更落地。点击阅读原文,查看何兴权老师的人大统计学课程实践笔记。
那么什么更落地?工作更落地。如何切入?薛老师讲了聚类算法,而聚类算法在我们 TD 用的太多了,Lookalike、客缘、人本实验室等许多地方都有应用,也包括我之前做的智能招商项目,聚类商场,对商场进行定位。于是便有了此文——聚类算法从理论到实践。
1. 课程回顾
我们先回顾一下薛老师的课程,打好理论基础。薛老师结合实际案例“探讨北京供暖季空气质量的区域划分”讲解了聚类算法。
目标:根据供暖季的 PM2.5、AQI、CO、NO2、O3、SO2 均值进行区域划分。
方法:聚类分析,基于多个变量依某个标准,将数据分成若干小类,类内个体在多个变量取值上具有较高相似性,间的差异较大。
我们先了解以下基础知识:
1.1 距离
距离是划分小类的依据,定义某种距离,距离越近越应聚成一小类;距离越远越应分属于不同的小类。
常见的距离是几何概念,如二维或三维等几何空间的欧几里德距离,把每条数据(监测点)看成是 p 维(6 维)空间上的点,在点和点之间定义距离,注意消除量纲的影响。
距离的取值:(分点)
最短距离法(nearest neighbor):两类间的距离定义为两类中距离最近的两个个案之间的距离
最长距离法(furthest neighbor):两类间的距离定义为两类中距离最远的两个个案之间的距离
平均链锁法(within-groups linkage):两类之间的距离定义为两类个案之间距离的平均值。包括:组间平均链锁法(between-groups linkage):只考虑两类间个案的距离、组内平均链锁法(With-groups linkage):考虑所有个案间的距离(类内离散)。
1.2 层次性
聚类过程具有一定的层次性,某个类是另个类的子类,通常以合并(凝聚)方式聚类。步骤如下:(分类)
每个个体自成一类
将最近的个体聚成一小类
将最近的小类或个体再聚成一类
重复上述过程,即把所有个体和小类聚集成越来越大的类,直到所有个体为一大类为止
了解完基础知识后就开始实战,进行聚类,代码及所有可能的聚类解如下:
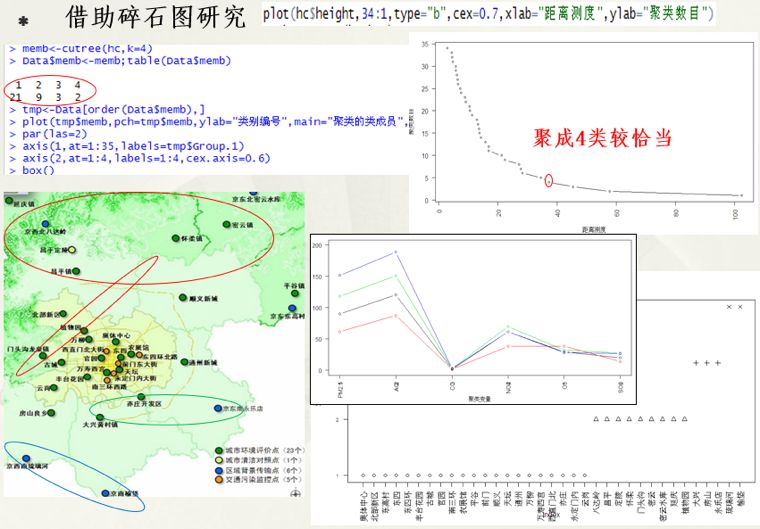
那么问题来了聚成多少小类比较合适?原则上是可合并类间距离小的小类。
这时我们需要借助碎石图研究,最终认为聚成 4 类比较恰当,如下:
2. 工作实战
回顾完课程,打好理论基础后,我们就结合工作进行实战,以我现在做的智能招商项目里的聚类商场,对商场进行定位为例。
2.1 项目背景
先介绍一下项目背景,咨询及业务部门反馈商业地产客户对大数据支持的智能招商方面有需求,主要是计算商场内不同品牌、品类之间的关联关系。初步调研后发现:2017 年新开业的商业项目累计突破 5000 家,品牌需求量达 10 万个以上,潜力巨大。
商业项目一方面频现业态配比不合理,定位老化等问题,另一方面又难以突破区域限制引进差异化品牌,这些问题使得商业项目的招商需求远大于品牌供给。
在商场井喷式爆发的背景下,品牌方选择在哪里开店,便是其首要问题。在品牌选址过程中,商圈分析、周边环境、交通状况、人口密度、区位购买力、业态布局、客群挖掘、品牌画像等服务都是痛点。
因此,连接品牌方与项目方成为行业新诉求。为品牌方带来拓展计划、加盟代理、品牌推荐、品牌秀场等多种支持,为项目方提供商铺招商、业态招商、项目推荐等服务都是我们招商探索的方向。
做招商的第一步就是了解商场,做一个商场画像,了解商场的特点及定位,然后才能进行引进差异化或者互补品牌等一系列的工作。
综合我们的数据和业务需求,我们选取了商场的规模(拥有的品牌数)和商场品牌业态占比(服饰鞋帽、家居厨具、丽人、箱包)等因素进行聚类。
2.2 算法选择
算法上,我们选用了 Python sklearn.cluster 的 KMeans 算法进行聚类。理论与现实总有距离,仅有薛老师的基础讲解还不够,我们需要进一步了解 Python 中 KMeans 算法的相关使用,尤其是参数这一块。
参考文档:
http://scikit-learn.org/stable/modules/generated/sklearn.cluster.KMeans.html#examples-using-sklearn-cluster-kmeans
贴心地附上汉化后的文档:
http://blog.csdn.net/xiaoyi_zhang/article/details/52269242
有些同学可能会懵,这么多参数,怎么玩。参数多,但很多都用不上,视你的需求而定,在这里,我说一下我使用的几个参数:
1. n_clusters
整形,缺省值=8,生成的聚类数,即产生的质心(centroids)数
即最后商场可以分为几类,一般会由咨询结合业务场景给一个大概的范围,我们在算法中进行调试,不断迭代,直至有一个理想的结果。
2. n_init 和 max_iter
n_init:整形,缺省值=10,用不同的质心初始化值运行算法的次数,最终解是在 inertia 意义下选出的最优结果。
max_iter:整形,缺省值=300,执行一次 k-means 算法所进行的最大迭代数。
这个我们视源数据大小和算法生成的结果来调,因为源数据不大,我们希望有一个较好的结果,因此参数调的较大,我们把 max_iter 调成了 5000,取得了一个不错的结果。
3. n_jobs
整形数,指定计算所用的进程数。内部原理是同时进行 n_init 指定次数的计算。
若值为 -1,则用所有的 CPU 进行运算。若值为 1,则不进行并行运算,这样方便调试。若值小于-1,则用到的 CPU 数为(n_cpus + 1 + n_jobs)。因此如果 n_jobs 值为-2,则用到的 CPU 数为总 CPU 数减 1。我们用的-1,即所有的 CPU 进行运算。
2.3 结果输出
完成算法的计算后,就需要对结果进行输出了。
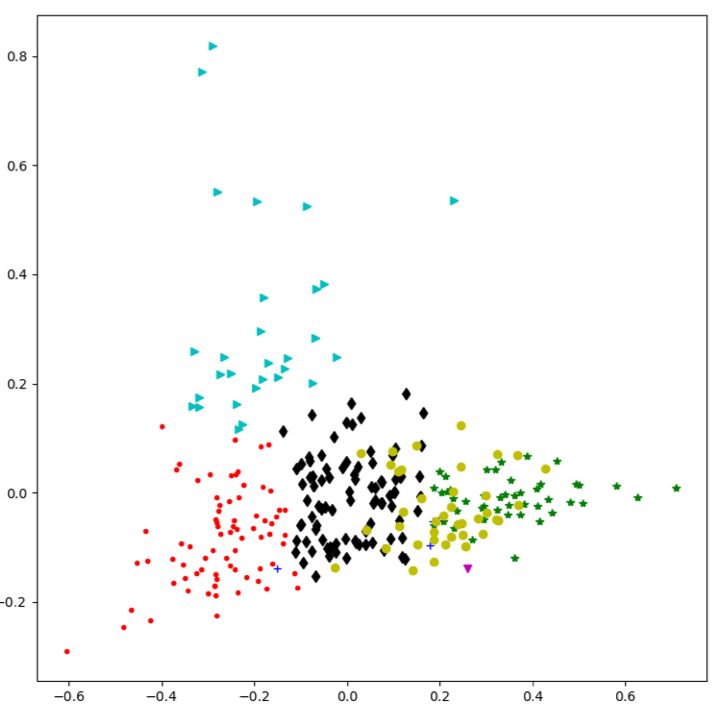
我们输出了聚类结果,部分数据如下表:

第一列 label 即代表聚类后的分类,同一个 label 代表在同一类。
聚类结果有了,但我们无法很直观地看出每一类的特点,因此,我们求了每一类中心点的规模和业态,部分数据如下表:
期间和后续还遇到了一些问题,在此就不一一展开,欢迎感兴趣的同学一起探讨。
学习算法为的就是应用于实际业务,不然就是屠龙之术。想要解决实际业务问题,常常需要算法来做支撑。两者相辅相成,学以致用,理论应用于实践。路漫漫其修远兮,吾将上下而求索。
题图来自:MDPI
以上是关于聚类算法从理论到实践的主要内容,如果未能解决你的问题,请参考以下文章