为什么说K-Means是基于距离的聚类算法?
Posted 中科院计算所培训中心
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了为什么说K-Means是基于距离的聚类算法?相关的知识,希望对你有一定的参考价值。
K-means算法是很典型的基于距离的聚类算法,采用距离作为相似性的评价指标,两个对象的距离越近,其相似度就越大。K-means算法认为簇是由距离靠近的对象组成的,因此把得到紧凑且独立的簇作为最终目标。
k-means聚类,需要用户设定一个聚类个数k作为输入数据。k个初始类聚类中心点的选取,对聚类结果具有较大的。为了用k-means达到高质量的聚类,需要估计k值。可根据需要的聚类个数,估计k值。
比如一百万篇文章,如果平均500篇分为一类,k值可以取2000(1百万/500)。
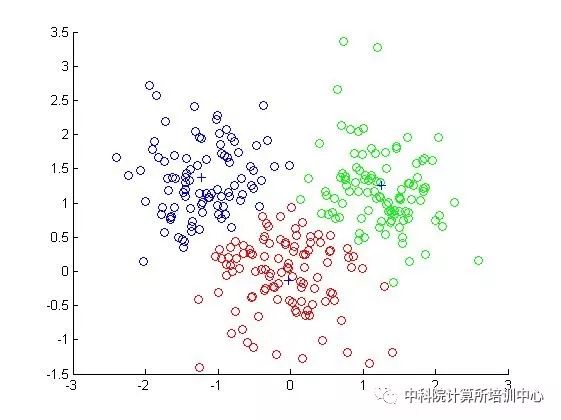
算法步骤
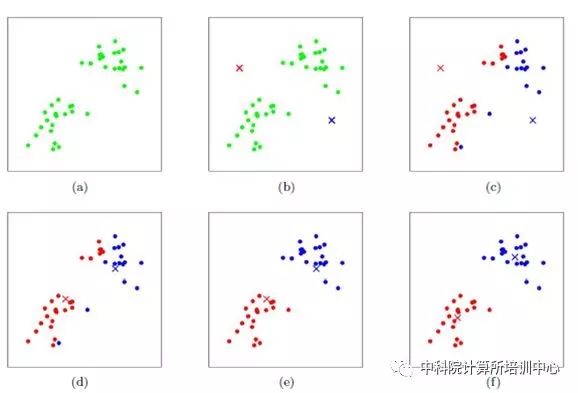
1)随机选取任意k个对象作为初始聚类中心,初始代表一个簇;
2)计算点到质心的距离,并把它归到最近的质心的类;
3)重新计算已经得到的各个类的质心;
4)迭代2~3步直至新的质心与原质心相等或小于指定阈值,算法结束。
EM的典型
这种两步算法是最大期望算法(EM)的典型例子,第一步是计算期望(E),利用对隐藏变量的现有估计值,计算其最大似然估计值;第二步是最大化(M),最大化在E 步上求得的最大似然值来计算参数的值。M 步上找到的参数估计值,被用于下一个E 步计算中,这个过程不断交替进行。
运行k-means聚类
K-mean聚类用到KMeansClusterer或KMeansDriver类,前一个是在内存(in-memory)里对节点聚类,后者采用MapReduce任务执行。
这两种方法可以:从盘上读取和写入数据,就像普通的Java程序。也可以通过分布式文件系统读写数据,在hadoop上执行聚类。先测试运行KMeansExample,使用一个随机点生成函数来创建一些点。这些点,生成向量格式的点,以正态分布出现,围绕着一个中心。可使用KMeansClusterer聚类方法,对这些点聚类。
k-means聚类输出的两类目录
clusters-*目录:在每一轮迭代末尾生成,clusters-0目录在第1轮迭代之后生成,clusters-1目录在第2轮迭代后生成,以此类推。包含了簇的信息:中心、标准差等。
clusteredPoints目录:包含了从簇ID到文档ID的最终映射。是根据最后一轮MapReduce操作的输出生成的。
中科院计算所培训中心
了解更多高品质课程
请登录官网:www.tcict.cn
微信客服:tcict1987
长按上图,识别图中二维码,关注官方微信!
以上是关于为什么说K-Means是基于距离的聚类算法?的主要内容,如果未能解决你的问题,请参考以下文章
聚类:层次聚类基于划分的聚类(k-means)基于密度的聚类基于模型的聚类