Sklearn参数详解—聚类算法
Posted 俊红的数据分析之路
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Sklearn参数详解—聚类算法相关的知识,希望对你有一定的参考价值。
总第115篇
前言
聚类是一种非监督学习,是将一份给定数据集划分成k类,这一份数据集可能是某公司的一批用户,也可能是某媒体网站的一系列文章,如果是某公司的一批用户,那么k-means做的就是根据用户的表现对用户的分类;如果媒体的文章,那么k-means做的就是根据文章的类型,把他分到不同的类别。
当一个公司用户发展到一定的量级以后,就没有办法以同样的精力去维护所有用户,这个时候就需要根据用户的种种表现对用户进行分类,然后根据用户类别的不同,采取不同的运营策略。而这里的分类方法就是聚类算法。我们这篇文章主要讲述一下常用的三种聚类方法:
K-means聚类
层次聚类
密度聚类
K-means聚类算法
K-means聚类算法是最简单、最基础的聚类算法,原理很简单,就是先指定k个点,然后计算每一个样本点分别到这k个点之间的距离,并将不同样本点划分到距离最近的那个点的集合,这样就把所有的样本分成k类了。比如下图就是将所有的样本分为3类。
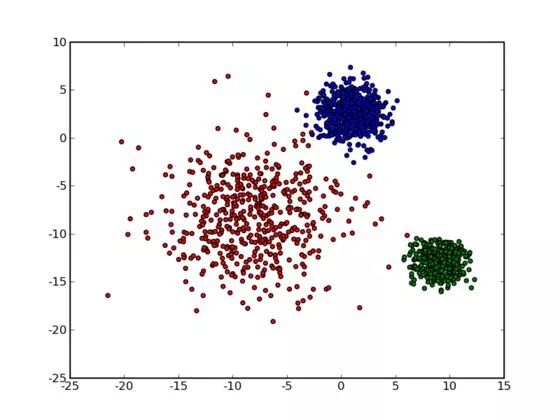
步骤:
随机选择K个点(质心)
通过计算每个点到这K个点之间的距离(这里的距离默认是欧式距离,一般也选择欧式距离,也可以是其他,比如DTW),并将样本点划分到距离最近的那个点。
计算划分后的点的平均值,并将均值作为新的质心,继续进行距离求解,然后重新进行划分,再次求均值,直到均值不发生变化时循环停止。
参数
class sklearn.cluster.KMeans
(n_clusters=8, init='k-means++', n_init=10, max_iter=300,
tol=0.0001, precompute_distances='auto', verbose=0,
random_state=None, copy_x=True, n_jobs=1, algorithm='auto')
n_clusters:质心数量,也就是分类数,默认是8个。
init:初始化质心的选取方式,主要有下面三种参数可选,‘k-means++’、‘random’ or an ndarray,默认是'k-means++'。因为初始质心是随机选取的,会造成局部最优解,所以需要更换几次随机质心,这个方法在sklearn中通过给init参数传入=“k-means++”即可。
K-means与K-means++区别:
原始K-means算法最开始随机选取数据集中K个点作为聚类中心,而K-means++按照如下的思想选取K个聚类中心:
假设已经选取了n个初始聚类中心(0<n<K),则在选取第n+1个聚类中心时:距离当前n个聚类中心越远的点会有更高的概率被选为第n+1个聚类中心,但在选取第一个聚类中心(n=1)时同样通过随机的方法,之所以这样做是因为聚类中心互相离得越远越好。
n_init:随机初始化的次数,kmeans质心迭代的次数。
max_iter:最大迭代次数,默认是300。
tol:误差容忍度最小值。
precompute_distances:是否需要提前计算距离,auto,True,False三个参数值可选。默认值是auto,如果选择auto,当样本数*质心数>12兆的时候,就不会提前进行计算,如果小于则会与提前计算。提前计算距离会让聚类速度很快,但是也会消耗很多内存。
copy_x:主要起作用于提前计算距离的情况,默认值是True,如果是True,则表示在源数据的副本上提前计算距离时,不会修改源数据。
algorithm:优化算法的选择,有auto、full和elkan三种选择。full就是一般意义上的K-Means算法,elkan是使用的elkan K-Means算法。默认的auto则会根据数据值是否是稀疏的(稀疏一般指是有大量缺失值),来决定如何选择full和elkan。如果数据是稠密的,就选择elkan K-means,否则就使用普通的Kmeans算法。

对象/属性
cluster_centers_:输出聚类的质心。
labels_:输出每个样本集对应的类别。
inertia_:所有样本点到其最近点距离之和。
层次聚类
层次聚类有两种方式,一种是从上至下(凝聚法),另一种是从下至上(分裂法),如下图所示。
从下至上(凝聚法)
从上至下就是把每一个样本分别当作一类,然后计算两两样本之间的距离,将距离较近的两个样本进行合并,再计算两两合并以后的簇之间的距离,将距离最近的两个簇进行合并,重复执行这个过程,直到达到最后指定的类别数或者达到了停止条件。
从上至下(分裂法)
从下至上就是刚开始把所有样本都当作同一类,然后计算两两样本之间的距离,将距离较远的两个样本分割成两类,然后再计算剩余样本集中每个样本到这两类中的距离,距离哪类比较近,则把样本划分到哪一类,循环执行这个过程,直到达到最后指定的类别数或者达到了停止条件。
参数
AgglomerativeClustering是用来实现凝聚法聚类模型的。
class sklearn.cluster.AgglomerativeClustering
(n_clusters=2, affinity='euclidean', memory=None,
connectivity=None, compute_full_tree='auto', linkage='ward',
pooling_func=<function mean at 0x174b938>)
n_clusters:目标类别数,默认是2。
affinity:样本点之间距离计算方式,可以是euclidean(欧式距离), l1、 l2、manhattan(曼哈顿距离)、cosine(余弦距离)、precomputed(可以预先设定好距离),如果参数linkage选择“ward”的时候只能使用euclidean。
linkage:链接标准,即样本点的合并标准,主要有ward、complete、average三个参数可选,默认是ward。每个簇(类)本身就是一个集合,我们在合并两个簇的时候其实是在合并两个集合,所以我们需要找到一种计算两个集合之间距离的方式,主要有这三种方式:ward、complete、average,分别表示使用两个集合方差、两个集合中点与点距离之间的平均值、两个集合中距离最小的两个点的距离。
对象/属性
labels_:每个样本点的类别。
n_leaves_:层次树中叶结点树。
密度聚类:
密度聚类与前面两种聚类方式不同,密度聚类无法事先指定类别个数,只能通过去指定每个点的邻域,以及邻域内包含样本点的最少个数。
先来看几个密度聚类里面用到的概念:
邻域:邻域是针对样本集中的每个点而言的,我们把距离某个样本点(可以把该点理解为圆心)距离在r(可理解为圆的半径)以内的点的集合称为该点的邻域。
核心对象:如果某个点的邻域内至少包含MinPts个样本,则该点就可以称为核心对象。
密度直达:如果点A位于点B的邻域中,且点B是核心对象,则称A和B是密度直达。
密度可达:对于点A和B,如果存在一个(或者若干个)点C,其中A到C是密度直达,C到B是密度直达,则A和B就称为密度可达。(你可以理解为C是一个跳板,你可以通过C从点A跳到B)
密度相连:若存在一个点C,使得C到A是密度直达,C到B是密度直达,则称A和B是密度相连的。
具体步骤
先建立几个集合,一个用来存储核心对象的集合Ω,初始值是空集;再初始化一个值k,用来存放簇的类别数,初始值为0;再新建一个集合Γ,用来存放未被使用的样本,初始值为全部样本集D。
遍历所有样本集中的每个样本点p,判断其是否满足核心对象的条件,如果满足,则把该点加入到核心对象集合Ω中;如果没有样本点满足核心对象条件,则结束遍历。
判断核心对象集合Ω是否为空,如果为空,则算法结束;如果不为空,则在集合Ω中随机选取一个样本点,将该点密度可达的所有样本点划分为一个簇,这个簇的样本集合称为Ck ,将簇的类别数k+1,未被使用样本Γ-Ck。
4.再在剩余的核心对象中重复步骤3,直到没有核心对象为止。
5.最后输出k个类别的样本集合{C1、C2、……、Ck}。
参数
class sklearn.cluster.DBSCAN
(eps=0.5, min_samples=5, metric='euclidean', metric_params=None,
algorithm='auto', leaf_size=30, p=None, n_jobs=1)
eps:即邻域中的r值,可以理解为圆的半径。
min_samples:要成为核心对象的必要条件,即邻域内的最小样本数,默认是5个。
metric:距离计算方式,和层次聚类中的affinity参数类似,同样也可以是precomputed。
metric_params:其他度量函数的参数。
algorithm:最近邻搜索算法参数,auto、ball_tree(球树)、kd_tree(kd树)、brute(暴力搜索),默认是auto。
leaf_size:最近邻搜索算法参数,当algorithm使用kd_tree或者ball_tree时,停止建子树的叶子节点数量的阈值。
p: 最近邻距离度量参数。只用于闵可夫斯基距离和带权重闵可夫斯基距离中p值的选择,p=1为曼哈顿距离,p=2为欧式距离。
对象/属性
core_sample_indices_:核心对象数。
labels_:每个样本点的对应的类别,对于噪声点将赋值为-1。
你还可以看:
参考文章:
http://www.cnblogs.com/pinard/p/6217852.html
以上是关于Sklearn参数详解—聚类算法的主要内容,如果未能解决你的问题,请参考以下文章
机器学习之SKlearn(scikit-learn)的K-means聚类算法