机器学习之SKlearn(scikit-learn)的K-means聚类算法
Posted 启示AI科技
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习之SKlearn(scikit-learn)的K-means聚类算法相关的知识,希望对你有一定的参考价值。
在工程应用中,用python手写代码来从头实现一个算法的可能性非常低,这样不仅耗时耗力,还不一定能够写出构架清晰,稳定性强的模型。更多情况下,是分析采集到的数据,根据数据特征选择适合的算法,在工具包中调用算法,调整算法的参数,获取需要的信息,从而实现算法效率和效果之间的平衡。而sklearn,正是这样一个可以帮助我们高效实现算法应用的工具包。
Scikit learn 也简称 sklearn, 是机器学习领域当中最知名的 python 模块之一.
Sklearn 包含了很多种机器学习的方式:
· Classification 分类
· Regression 回归
· Clustering 非监督分类
· Dimensionality reduction 数据降维
· Model Selection 模型选择
· Preprocessing 数据预处理
我们总能够从这些方法中挑选出一个适合于自己问题的, 然后解决自己的问题.
sklearn有一个完整而丰富的官网,里面讲解了基于sklearn对所有算法的实现和简单应用。
Sklearn的安装直接在cmd命令行中输入:pip install scikit-learn
注意一点是需要自己的python版本要大于3.4
Sklearn常用算法模块
sklearn中常用的模块有分类、回归、聚类、降维、模型选择、预处理。
分类:识别某个对象属于哪个类别,常用的算法有:SVM(支持向量机)、nearest neighbors(最近邻)、random forest(随机森林),常见的应用有:垃圾邮件识别、图像识别。
分类
回归:预测与对象相关联的连续值属性,常见的算法有:SVR(支持向量机)、 ridge regression(岭回归)、Lasso,常见的应用有:药物反应,预测股价。
回归
聚类:将相似对象自动分组,常用的算法有:k-Means、 spectral clustering、mean-shift,常见的应用有:客户细分,分组实验结果。
聚类
降维:减少要考虑的随机变量的数量,常见的算法有:PCA(主成分分析)、feature selection(特征选择)、non-negative matrix factorization(非负矩阵分解),常见的应用有:可视化,提高效率。
模型选择:比较,验证,选择参数和模型,常用的模块有:grid search(网格搜索)、cross validation(交叉验证)、 metrics(度量)。它的目标是通过参数调整提高精度。
预处理:特征提取和归一化,常用的模块有:preprocessing,feature extraction,常见的应用有:把输入数据(如文本)转换为机器学习算法可用的数据。
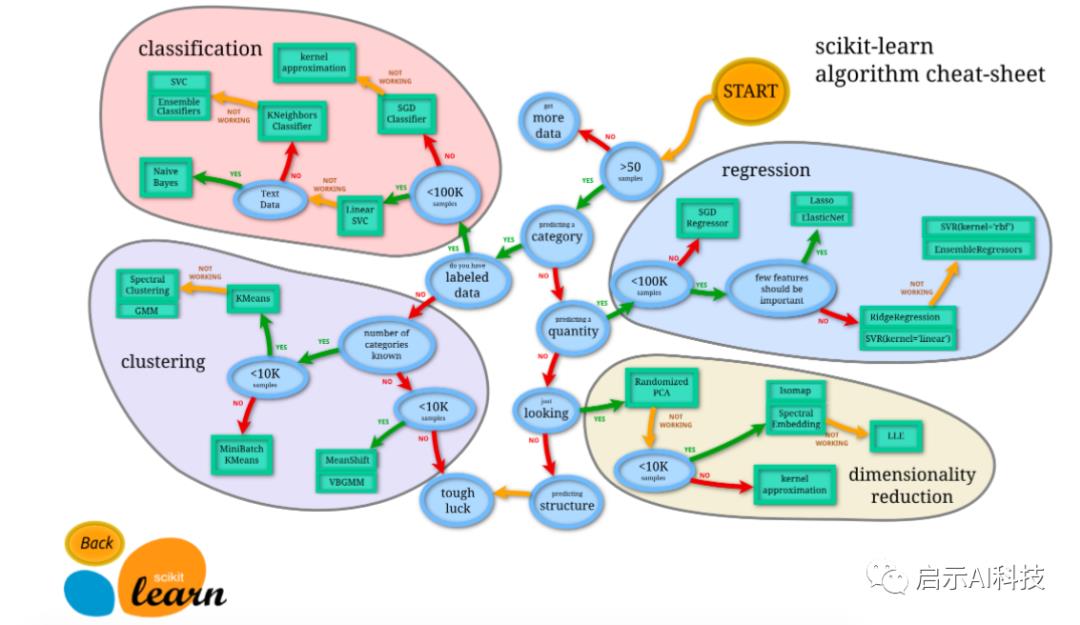
Sklearn算法模型选择
使用 Sklearn 时,先了解一下Sklearn都有什么模型方法,然后选择适当的方法,来达到你的目标。
Sklearn 官网提供了一个流程图, 蓝色圆圈内是判断条件,绿色方框内是可以选择的算法:
从 START 开始,首先看数据的样本是否 >50,小于则需要收集更多的数据。
由图中,可以看到算法有四类,分类,回归,聚类,降维。
其中 分类和回归是监督式学习,即每个数据对应一个 label。聚类 是非监督式学习,即没有 label。另外一类是 降维,当数据集有很多很多属性的时候,可以通过 降维 算法把属性归纳起来。
然后看问题属于哪一类问题,是分类还是回归,还是聚类,就选择相应的算法。当然还要考虑数据的大小,例如 100K 是一个阈值。
可以发现有些方法是既可以作为分类,也可以作为回归,例如 SGD。
Sklearn聚类算法
关于神经网络的分类与回归问题,小编前期的文章都分享了很多类似的文章,小伙伴们可以进入小编主页进行其他类似文章的阅读,今天我们就来看看Sklearn下面的聚类算法
聚类:将相似对象自动分组,常用的算法有:k-Means、 spectral clustering、mean-shift,常见的应用有:客户细分,分组实验结果
Sklearn官网也列举了不同的聚类算法的优缺点,可以参考如下
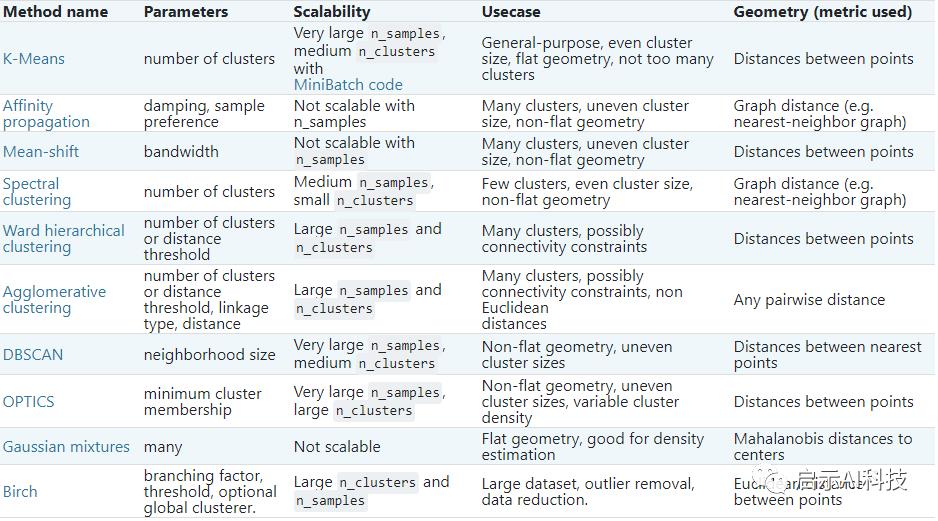
Sklearn聚类算法对比
Sklearn聚类算法官方列举了不同的算法,大家可以根据自己的数据特征,以及需要解决的问题,选择不同的算法,本期我们首先简单了解一下K-means算法
Sklearn聚类算法的K-means算法
K-means聚类算法
聚类算法的过程:
随机选择k个中心
遍历所有样本,把样本划分到距离最近的一个中心
划分之后就有K个簇,计算每个簇的平均值作为新的质心
重复步骤2,直到达到停止条件
停止:聚类中心不再发生变化;所有的距离最小;迭代次数达到设定值
在python中,聚类算法集成在sklearn.cluster中
from sklearn.cluster import KMeans
KMeans(n_clusters=8,init='k-means++',n_init=10,max_iter=300,tol=0.0001,
precompute_distances='auto',verbose=0,random_state=None,
copy_x=True,n_jobs=1,algorithm='auto')参数:
n_clusters:
整形,默认=8 【生成的聚类数,即产生的质心(centroids)数
init:有三个可选值:'k-means++', 'random',或者传递一个ndarray向量。
此参数指定初始化方法,默认值为 'k-means++'。
(1)'k-means++' 用一种特殊的方法选定初始质心从而能加速迭代过程的收敛
(2)'random' 随机从训练数据中选取初始质心。
(3)如果传递的是一个ndarray,则应该形如 (n_clusters, n_features) 并给出初始质心n_init:整形,默认=10用不同的质心初始化值运行算法的次数,最终解是在inertia意义下选出的最优结果
max_iter:整形,默认=300执行一次k-means算法所进行的最大迭代数
tol:float形,默认值= 1e-4 与inertia结合来确定收敛条件
precompute_distances:三个可选值,'auto',True 或者 False。预计算距离,计算速度更快但占用更多内存。
(1)'auto':如果 样本数乘以聚类数大于 12million 的话则不预计算距离
(2)True:总是预先计算距离
(3)False:永远不预先计算距离
自版本0.23起已弃用:'precompute_distances'在版本0.22中已弃用,并将在0.25中删除。没有作用
verbose:int 默认为0,Verbosity mode
random_state:整形或 numpy.RandomState 类型,可选用于初始化质心的生成器(generator)如果值为一个整数,则确定一个seed。此参数默认值为numpy的随机数生成器copy_x:布尔型,默认值=True
当我们precomputing distances时,将数据中心化会得到更准确的结果如果把此参数值设为True,则原始数据不会被改变
如果是False,则会直接在原始数据上做修改并在函数返回值时将其还原
但是在计算过程中由于有对数据均值的加减运算,所以数据返回后,原始数据和计算前可能会有细小差别n_jobs:整形数。 指定计算所用的进程数。内部原理是同时进行n_init指定次数的计算。(1)若值为 -1,则用所有的CPU进行运算
(2)若值为1,则不进行并行运算,这样的话方便调试
(3)若值小于-1,则用到的CPU数为(n_cpus + 1 + n_jobs)
如果 n_jobs值为-2,则用到的CPU数为总CPU数减1
从0.23版n_jobs开始不推荐使用:从0.23版开始不推荐使用,并将在0.25版中删除。
algorithm:三种可选“auto”, “full”, “elkan”, default=”auto”
使用K均值算法。经典的EM风格算法是“full”的 通过使用三角形不等式,“ elkan”算法对于定义良好的聚类的数据更有效 但是,由于分配了额外的形状数组(n_samples,n_clusters),因此需要更多的内存。目前,“ auto”(保持向后兼容性)选择“ elkan”在版本0.18中更改:添加了Elkan算法以上算法中的参数虽然很多,但是绝大多数我们直接采用默认参数即可,这样在我们实际使用过程中,传递我们需要的几个参数便可。下期文章,就k-means算法我们使用几个案例来具体学习一下其算法的实际应用
聚类算法
以上是关于机器学习之SKlearn(scikit-learn)的K-means聚类算法的主要内容,如果未能解决你的问题,请参考以下文章