机器学习常见的聚类算法(上篇)
Posted Python与算法社区
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习常见的聚类算法(上篇)相关的知识,希望对你有一定的参考价值。
1 前言
陈浩然,北大在读,个人网站:chrer.com,里面记录了机器学习、深度学习的系统学习笔记,欢迎大家访问,感谢分享!
之前已经讲过的各种方法——决策树、线性回归、神经网络…..都是属于监督学习的一部分,今天要讲的聚类算法,是属于无监督学习的典型代表。
我们已经知道,无监督学习是没有标记信息的,但是数据之间是具有内在规律的。无监督学习的目的就是找到这些数据之间的内在性质和规律。
聚类算法目的是将数据划分为几个互不相交且并集为原集的子集,每个子集可能对应于一个潜在的概念,例如:购买力强的顾客、尚待吸引的顾客。但是这些概念是算法不知道的,需要我们自己进行阐述。
2 距离计算
大量的聚类算法用到了距离计算——可以代表两个样本之间相似程度。一般而言,距离的度量有几个原则:
非负性:
同一性:
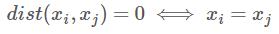
对称性:
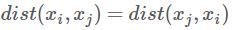
直递性:
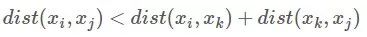
根据样本属性是否定义了序关系,可以将样本属性分为两类
有序属性——连续数值属性,离散有值属性等,如年龄18/19/20/21….
无序属性——例如性别,星座,血型等,他们之间无法进行比较
对于这两种不同的属性,可以定义不同的距离度量方法:
有序属性:闵科夫斯基距离——
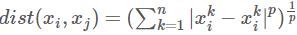 ,当p=1时,退化为曼哈顿距离,当p=2时,退化为欧几里得距离
,当p=1时,退化为曼哈顿距离,当p=2时,退化为欧几里得距离无序属性:因为无法直接计算,无序属性的距离度量较为复杂。令表示在属性u上取值为a的样本数,表示在第i个样本划分子集上属性u取值为a的样本数,之后定义属性u的两个取值a和b的VDM距离:
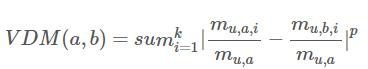
定义了以上两种属性距离之后,便可以将其结合起来计算两个样本的距离,若不同属性权重不同,也可以将每个属性乘以其权重。
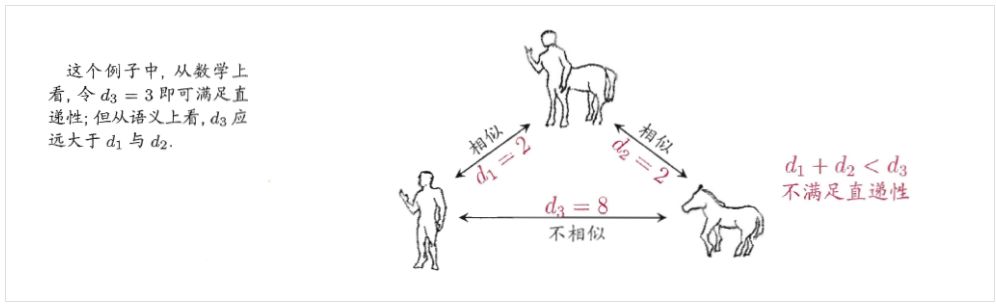
距离表示相似性度量,距离增大,相似性减少。当然,在日常生活中还可以遇到非度量距离——即不满足直递性的距离度量方式。例如,人与马不相似,但是人、马与“人马”都比较相似。
3 常见聚类算法
聚类算法多为循环或者迭代算法,因为聚类算法要解决的问题多是NP-难问题,大多通过类似贪心的算法逐步进行优化,故可能达不到全局最优解而陷入局部最优解。
下面假定要划分k个类,记为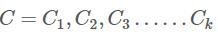 ,k的选择由现实要求而定,比如衣服型号划分,可以分为s,m,l三类,也可以划分为s,m,l,xl,xxl五类。
,k的选择由现实要求而定,比如衣服型号划分,可以分为s,m,l三类,也可以划分为s,m,l,xl,xxl五类。
3.1 k-均值算法
k-均值算法可以说是最经典的聚类算法,他的目标是最小化平方误差:
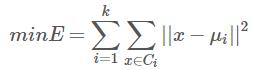
其中为第i类数据的平均值。k-均值算法思想如下:
初始化k个向量
根据样本数据距离最近的向量为依据将和一个向量最近的样本划为一类,如此划分子集
用从属于某一类的样本均值取代该向量
如上进行迭代,直到运行到某一个轮数,或者向量改变小于阈值
1# 输入:样本集D={x1,x2.....xm},聚类子集数目k
2def k_means(D,k):
3 while (True):
4 for j in range(1,k+1):
5 Cj = 空集
6 uj = 随机向量
7 for i in range(1,n+1):
8 for j in range(1,k+1):
9 # 求每个样本和每个向量之间的距离并找到最小距离
10 dij = dist(xi,uj)
11 min_di = min(dij for j in range(1,k+2))
12 # 假设min_di对应的最小距离类为p
13 Cp = Cp U xi
14 for j in range(1,k+1):
15 # 更新uj为该子集均值
16 uj = sum(Cj)/|cj|
17 if 所有的uj都没有发生更新:
18 break;
19 return {C1,C2......Ck}
运行图示如下,其中×表示当前的向量
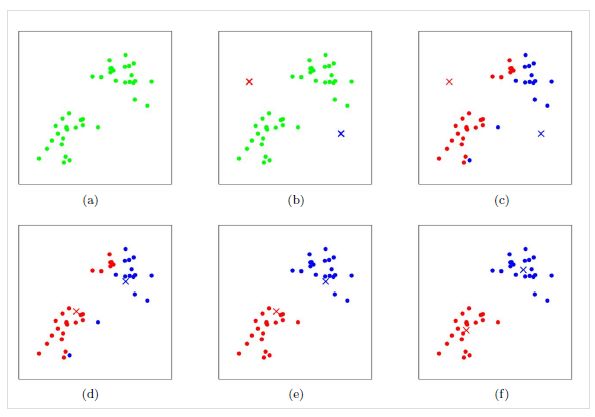
3.2 学习向量量化
学习向量量化是一个监督学习的算法,但他的思想和一般的无聚类算法比较相似:
向量量化的思路是,将高维输入空间分成若干不同的区域,对每个区域确定一个中心向量作为聚类的中心,与其处于同一区域的输入向量可用该中心向量来代表,从而形成了以各中心向量为聚类中心的点集。
也就是说,样本本身带有标记信息,已经划好了类别,算法的工作就是为每一组类别的变量找到一个代表向量。
算法思想如下:
随机初始化k个表示向量,并设定他们分别为第1…k类
随机选择一个样本,寻找离他最近的表示向量
更新该表示向量——如果表示向量所属类别和样本相同,就靠近该样本,否则远离该样本
重复2-4步骤,直到达到最大轮数位置
1# 输入样本 D={(x1,y1)......(xm,ym)},类别总数目k,训练轮数T
2def LVQ(D,k,T):
3 初始化k个表示向量p1,p2....pk
4 # 训练T轮
5 for t in range(1,T+1):
6 随机挑选一个样本(xr,yr)
7 寻找最近的表示向量ps
8 # 更新表示向量
9 refresh(ps)
10 return {p1,....pk}
其中更新表示向量的公式为:

上式中为学习率,在[0,1]之间,下图为图示:
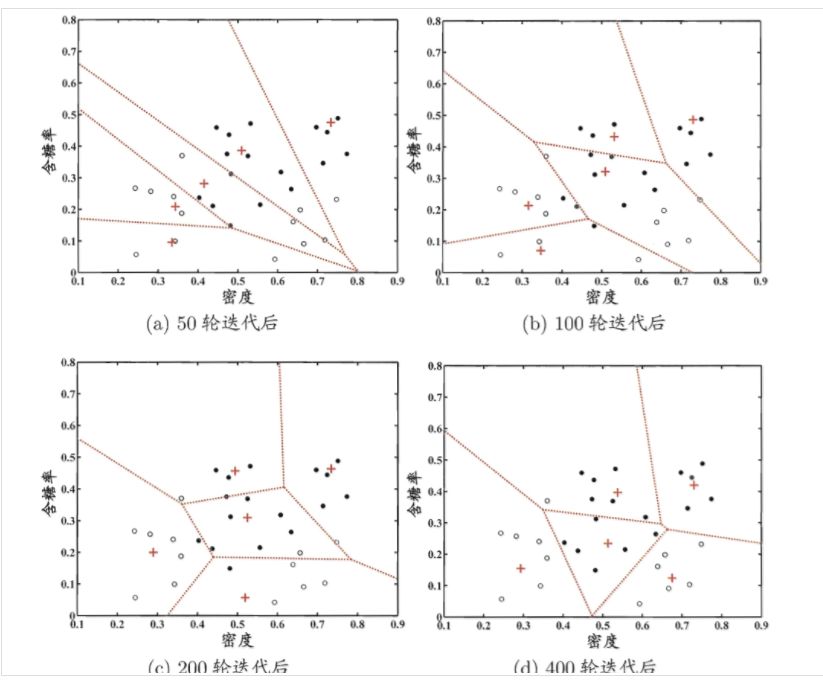
3.3 层次聚类
层次聚类的思想很有趣,它试图在不同的层次,一步一步的进行聚类。
算法的流程很简单:
将m个样本看做m个已经划分好的子集
找出距离最近的两个聚类子集,将它们合并
重复步骤2,直到剩余k个子集
那么唯一的问题就是如何计算两个的距离,一般有三种表示:
最小距离:将两个集合中距离最近的两个元素的距离当做集合的距离
最大距离:将两个集合中距离最远的两个元素的距离当做集合的距离
平均距离:
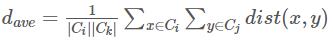
豪斯多夫距离,其定义如下
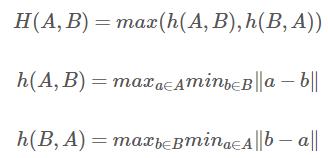
更多好文:
Python与机器学习算法频道
欢迎转发
以上是关于机器学习常见的聚类算法(上篇)的主要内容,如果未能解决你的问题,请参考以下文章