Hadoop2.0 NameNode HA和Federation简明理解
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hadoop2.0 NameNode HA和Federation简明理解相关的知识,希望对你有一定的参考价值。
参考技术A 为什么需要 NameNode HA 和 Federation ?1. 规避NameNode单点故障,secondary namenode只是定期做checkpoints,无法保证数据完整性,当nn失效时无法即时顶替;
2. 随集群规模扩大,NameNode内存出现瓶颈,Federation作用是“扩容”
1. 有 主备NameNode ,分别在active和standby模式。两者有 共享存储 、datanode同时向两个nn报告,保证数据一致性。
2. Zookeeper 集群(逻辑上与Hadoop集群独立)实现同步锁,监控nn
3. ZKFC 实现的FailoverController进程(必须在nn上,与ZK集群心跳通信,一般2000ms)
1. 多个nn共用一个集群内所有dn的资源,每个NN可以单独对外提供服务
2. 每个NN上有一个block pool,有单独的ID,每个DN会为所有block pool提供存储
3. DN按照block pool ID向对应的NN汇报块信息
4. 通过客户端挂载表将不同目录挂在不同NN上
好处:
1. 改动最小,前向兼容。NN无配置改动,只是横向扩容;客户端可以只连接一个NN,无需修改配置。
2. 分离了 namespace 和 块存储管理:DN资源得到充分利用,可以向多个NN提供服务
3. 客户端挂载表:通过路径自动对应NN,使Federation配置对应用透明
<未完待续>
还有配置项说明
hadoop之 Hadoop 2.x HA Federation
HDFS2.0之HA
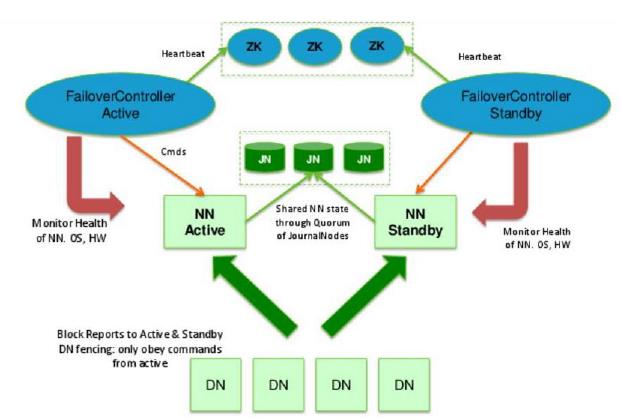
主备NameNode:
1、主NameNode对外提供服务,备NameNode同步主NameNode元数据,以待切换;
2、主NameNode的信息发生变化后,会将信息写到共享数据存储系统中让备NameNode合并到自己的内存中;
3、所有DataNode同时向两个NameNode发送心跳信息(块信息);
两种切换方式:
1、手动切换:通过命令实现主备之间的切换,可以用于HDFS升级等场合;
2、自动切换:基于Zookeeper实现;
Zookeeper Failover Controller:向Zookeeper注册NameNode并监控NameNode健康状态,当NM挂掉后,ZKFC为NameNode竞争锁,获得锁的NameNode变成active;
多种共享数据存储系统可供选择
1、NFS
2、多个Journal Node构成集群(推荐)
基本原理,数据同时写入所有的JN,多数写入成功,则认为写成功;
一般配置奇数个JN,JN越多,容错性越好;比如有3个JN,只要两个写成功,则数据写成功,最多允许一个JN挂掉;
3、Bookeeper
相对于hadoop1.x中多了备NameNode,JournalNode(存储共享数据),ZKFC&ZK(主备NN切换)
HDFS2.0之Federation
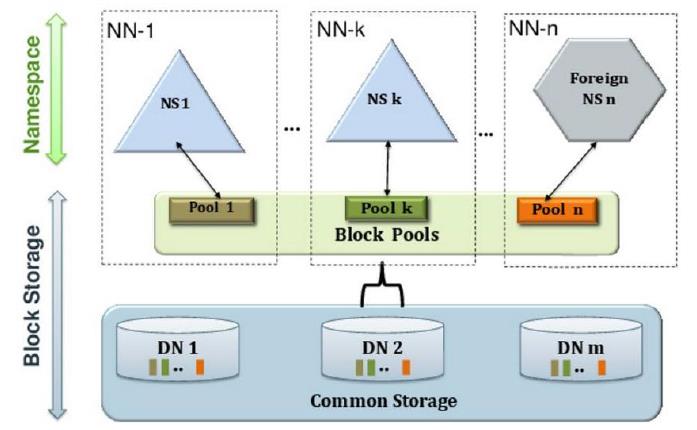
多个NN同时对外提供服务,每个NN分管一部分目录,多个NN共享底层DN存储;
此时每个NN都还是存在单点故障问题的,故还需要给Federation节点配置一个备用NN;
所有整个HADOOP2集群中可能存在的NN有:多个NN以及每个NN对应的备NN
带来的好处:单个NN内存和并发压力减小,NN彼此隔离,互不影响;
常见应用方法:
为不同业务创建不同NN,防止相互影响;(一个NN给开发用,一个NN测试用)
为不同需求创建不同NN,比如测试用的NN,生产用的NN;
HDFS2.0之其他实现机制(与1.0版本基本一致)
1、文件放置策略
文件被切成若干个block,存放在不同节点上;
切分过程对用户透明;
2、文件容错策略
基于副本的容错机制;
流水线复制;
3、副本放置策略
一个节点(1个rack)+ 两个节点(另1个rack)
4、......
以上是关于Hadoop2.0 NameNode HA和Federation简明理解的主要内容,如果未能解决你的问题,请参考以下文章