一文读懂LiveData 的粘性事件
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了一文读懂LiveData 的粘性事件相关的知识,希望对你有一定的参考价值。
参考技术A 说的通俗一点,就是先发送数据,后订阅,也可以接收到数据。这其实本是livedata 的一个特性,但是却给我们的日常使用带来了非常的不便,而且不提供API来解除粘性事件,这种做法确实不是很友好。
接下来,就带大家来揭秘一下LiveData 粘性事件的原理。
前方大量源码来袭,如有不适者,可以直接跳总结。
首先我们从发送消息开始
这里有个 mVersion 要注意一下,后面会用到。然后就是通过 dispatchingValue 方法来分发消息了。
在这个方法里,主要是参数传的观察者是否为空,如果不为空,则向此观察者分发消息,如果为空,将会从观察者集合里面遍历观察者,进行分发。在这里,我们主要看 considerNotify 方法。
在我们前面提到 mVersion 用到了这里,和 mLastVersion 做了比较,这点我们在下个步骤进行说明。
这就是我们全部发送消息的过程了,很简单明了,但是还不足以窥全貌,接下来我们分析另外一个步骤,监听。
在这里,主要是对我们的 owner 和 observer 做了一层包装,然后让 lifecycle 进行了监听。然后我们就看看 包装了点什么
可以看到 LifecycleBoundObserver 继承了 ObserverWrapper ,实现了 LifecycleEventObserver 接口。
LifecycleEventObserver 接口 主要是当 lifecycle 状态改变的时候会感应到,并进行回调。
然后我们主要看看父类 ObserverWrapper :
是不是看到了一个熟悉的面孔,就是我们上个步骤 提到的 mLastVersion ,它是在这里定义的,并且默认是-1;这里会在后文进行贯穿起来,先了解它的源头。
接下来,我们先继续走流程,还是 LifecycleBoundObserver 类中,当状态改变的时候,会调用 onStateChanged 方法
当活跃状态改变的时候,会 调用 activeStateChanged :
当状态是活跃状态的时候,会调用 dispatchingValue 进行数据分发,我们上文用到的分发是遍历所有观察者进行数据分发,这次是只分发当前观察者。
接下来我们进行连贯一下:
首先发送数据 postValue ,次数会让进行 mVersion++ 操作,然后遍历观察者进行分发。
然后是进行监听操作,在进行监听的时候,会使用 LifecycleBoundObserver 对观察者进行包装一下,在这个操作里面, LifecycleBoundObserver 的父类 ObserverWrapper 定义了 mLastVersion 为-1 。在数据最后进行分发的时候, mLastVersion 是小于 mVersion 的,所以未拦截,然后进行了数据的分发。
然后就产生了粘性事件。
一文读懂kafka的幂等生产者
一文读懂kafka的幂等生产者
1 前言
大家好,我是明哥!
KAFKA 作为开源分布式事件流平台,在大数据和微服务领域都有着广泛的应用场景,是实时流处理场景下消息队列事实上的标准。用一句话概括,KAFKA 是实时数仓的基石,是事件驱动架构的灵魂。
但是一些技术小伙伴,尤其是一些很早就开始使用 KAFKA 的技术小伙伴们,对 KAFKA 的发展趋势和一些新特性,并不太熟悉,在使用过程中也踩了不少坑。
有鉴于此,我们接下来会有一个 KAFKA 系列文章,专门讲述 KAFKA 的这些新特性。
本文是该系列文章之一,讲述 KAFAK 的幂等生产者。
以下是正文。
2 从历史视角看 KAFKA 的发展
首先我们从历史视角,看下 KAFKA 的发展:
- KAFKA 在2013年12月推出了一个重要的版本 0.8.0,该版本相当重要,因为它通过 KAFKA-50 首次引进了多副本机制,为容错打下了坚实的基础;
- 然后在后续版本中逐步增添了很多新的功能特性:
- 如逐步摆脱对 zookeeper的依赖;
- 如支持 compact 清理策略;
- 如支持 kafka tired storage;
- 如生产者幂等性;
- 如对事务的支持;
- 如大的 kafka 生态的 kafka connect api, kafka stream api 以及 KSQL, 还有 kafka schema registry;
- 到目前为止(202109),KAFKA 最新的稳定版已经演进到了 2.8.0;
- KAFKA 已经从最开始仅仅作为一个高吞吐的消息中间件,发展到了如今实时流处理场景下消息队列事实上的标准,用一句话概括,KAFKA 是实时数仓的基石,是事件驱动架构的灵魂。
- 但是如今在市面上生产环境中,还不乏有使用早期版本如 0.8.0 版本的情况。

3 什么是幂等生产者?
我们知道,当 kafka producer 向 broker 中的 topic发送数据时,可能会因为网络抖动等各种原因,造成 producer 收不到 broker 的 ack 确认信息。此时 producer 有两种选择:
- producer 可以选择忽略没有收到 ack 确认消息,不做任何进一步处理:此时有可能会丢失消息。(之所以说有可能,是因为消息有可能没有写到 broker 的topic 中,但也有可能已经正确地写到了 broker 的 topic 中,只是回调的 ack 消息因网络抖动 producer 没有收到;)
- producer 也可以选择多次尝试重发消息,直到收到ack 确认消息或重试最大次数到达: 此时有可能会造成消息的重复写,即 broker 端的 topic 中,重复地存储了重试发送的这些消息;
- producer 重发没有收到 ack 确认的消息, 也可能会造成 broker 端 topic 的 partition 中 消息的顺序混乱,即因失败重发的消息在部分没有失败不需要重发的消息之后。
- 因 producer 重发没有收到 ack 确认的消息造成数据重复的问题,可以参见如下示意图,图中 message 7/8/9/10 即为重复的消息。
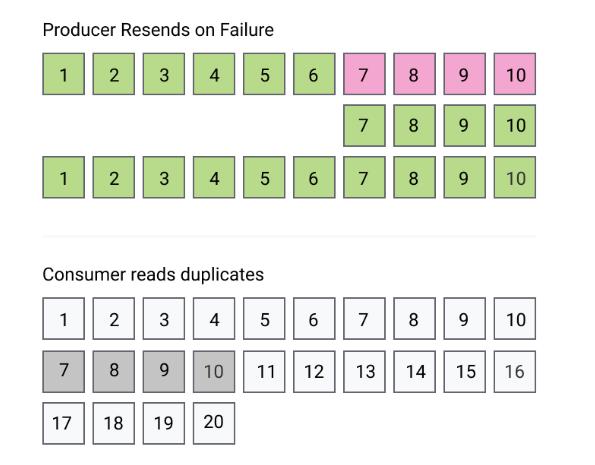
KAFKA 的幂等生产者即 idempotent producer,就是解决上述问题的:它可以确保消息被正确地投递到 broker端,不会丢失没有重复,而且是以正确的顺序存储在 topic 的各个 partition 中。
4 如何启用幂等生产者?
- 启用幂等生产者,不涉及任何代码层面的改动,只涉及以下配置项的更改:
- enable.idempotence=true;//幂等生产者功能开关
- message.send.max.retries=xx //发送失败重试次数,可以配置很大比如10000000,甚至Integer.MAX_VALUE;
- max.in.flight.requests.per.connection=xx //xx <= 5, 代表每个连接中在途请求次数,有的博文说该参数必须配置为=1,其实不然,只需要<=5即可(
max.in.flightmust be set <= 5 whenenable.idempotenceis true"); - Acks=All //ACK 确认参数,可选 0/1/-1/ALL,-1 与 ALL 等价。在开启幂等生产者功能时,该参数必须配置为ALL/-1,即所有 ISR 都要确认收到了消息,才认为消息投递成功(
acksmust be set toallwhenenable.idempotenceis true"); - 在开启幂等生产者即 enable.idempotence=true 的情况下,也可以不配置参数 max.in.flight.requests.per.connection 和参数 Acks,此时这两个参数会被自动配置;
5 幂等生产者的原理是什么?
首先需要说明下,在启用幂等生产者的情况下,消息失败时的重新发送,是由 kafka client 自动实现的,对我们来讲是透明的,我们不需要在代码中重试发送。(事实上,在代码中重试消息发送,反而会引起消息重复).
其内部工作原理如下:
- 在 producer 端,每个 producer 都被 broker 自动分配了一个 Producer Id (PID), producer 向 broker 发送的每条消息,在内部都附带着该 pid 和一个递增的 sequence number;
- 在 broker 端,broker 为每个 topic 的每个 partition 都维护了一个当前写成功的消息的最大 PID-Sequence Number 元组;
- 当 broker 收到一个比当前最大 PID-Sequence Number 元组小的 sequence number 消息时,就会丢弃该消息,以避免造成数据重复存储;
- 当 broker 失败重新选举新的 leader 时, 以上去重机制仍然有效:因为 broker 的 topic 中存储的消息体中附带了 PID-sequence number 信息,且 leader 的所有消息都会被复制到 followers 中。当某个原来的 follower 被选举为新的 leader 时,它内部的消息中已经存储了PID-sequence number 信息,也就可以执行消息去重了。
- 幂等生产者,在 broker 端去重的工作原理,如下图所示:

6 幂等生产者与事务有何关系?
幂等生产者是 kafka 事务的必要不充分条件,即:
- 开启幂等生长者,不一定需要开启事务;
- 开始 kafka 事务,必须要开启幂等生产者;
- 事实上,开启 kafka事务时,kafka 会自动开启幂等生产者。
- 关于 kafka 事务的详细介绍,敬请关注下一篇博文。
!关注不迷路~ 各种福利、资源定期分享!欢迎小伙伴们扫码添加明哥微信,后台加群交流学习。

以上是关于一文读懂LiveData 的粘性事件的主要内容,如果未能解决你的问题,请参考以下文章