带你100% 地了解 Redis 6.0 的客户端缓存
Posted 程序IT圈
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了带你100% 地了解 Redis 6.0 的客户端缓存相关的知识,希望对你有一定的参考价值。
,这是 Redis 历史上最大的一次版本更新,包括了客户端缓存 (Client side caching)、ACL、Threaded I/O 和 Redis Cluster Proxy 等诸多更新。
我们今天就依次聊一下客户端缓存的必要性、具体使用、原理分析和实现。
为什么需要客户端缓存?
我们都知道,使用 Redis 进行数据的缓存的主要目的是减少对 mysql 等数据库的访问,提供更快的访问速度,毕竟 《Redis in Action》中提到的, Redis 的性能大致是普通关系型数据库的 10 ~ 100 倍。
所以,如下图所示,Redis 用来存储热点数据,Redis 未命中,再去访问数据库,这样可以应付大多数情况下的性能要求。
但是,Redis 也有其性能上限,并且访问 Redis 必然有一定的网络 I/O 以及序列化反序列化损耗。所以,往往会引入进程缓存,将最热的数据存储在本地,进一步加快访问速度。
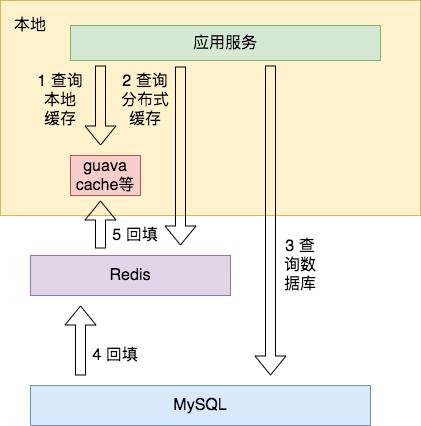
如上图所示(示意图,细节不必过度在意,下同),Guava Cache 等进程缓存作为一级缓存,Redis 作为二级缓存:
先去 Guava Cache 中查询数据,如果命中则直接返回。
Guava Cache 中未命中,则再去 Redis 中查询,如果命中则返回数据,并在 Guava Cache 中设置此数据。
Redis 也未命中的话,只有去 MySQL 中查询,然后依次将数据设置到 Redis 和 Guava Cache 中。
只使用 Redis 分布式缓存时,遇到数据更新时,应用程序更新完 MySQL 中的数据,可以直接将 Redis 中对应缓存失效掉,保持数据的一致性。
而进程内缓存的数据一致性比分布式的缓存面临更大的挑战。数据更新的时候,如何通知其他进程也更新自己的缓存呢?
如果按照分布式缓存的思路,我们可以设置极短的缓存失效时间,这样不必实现复杂的通知机制。
但是不同进程内的数据依然会面临不一致的问题,并且不同进程缓存失效时间不统一,同一个请求到了不同的进程,可能出现反复幻读的情况。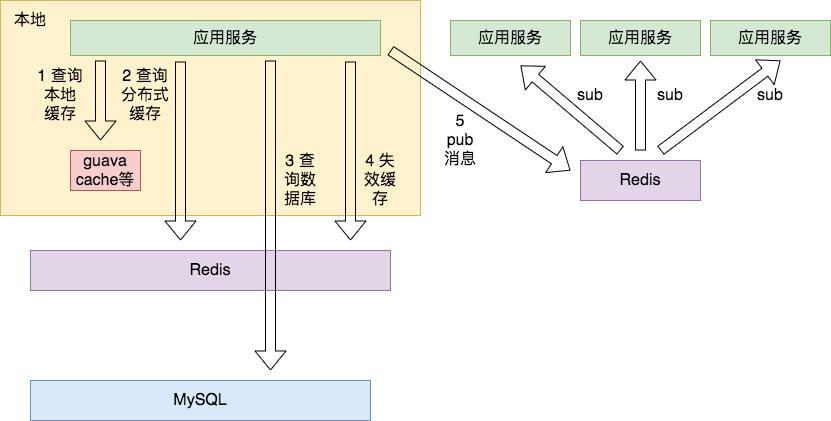
Ben 在 RedisConf18 给出了一个方案(视频和 PPT 链接在文末),通过 Redis 的 Pub/Sub,可以通知其他进程缓存对此缓存进行删除。如果 Redis 挂了或者订阅机制不靠谱,依靠超时设定,依然可以做兜底处理。
Antirez(Redis 的作者) 也正是听取 Ben 这个方案后,才决定在 Redis Server 支持客户端缓存的,因为在有服务端参与的情况下可以更好的处理上述这些问题。
功能介绍和演示
下面使用 Docker 安装 Redis 6.0.1,然后使用 telnet 来简单演示一下 Redis 6.0 的客户端缓存功能。所有相关的功能如下图所示,分别是使用RESP3 协议版本的普通模式和广播模式,以及使用 RESP2 协议版本的转发模式。我们先来看普通模式。
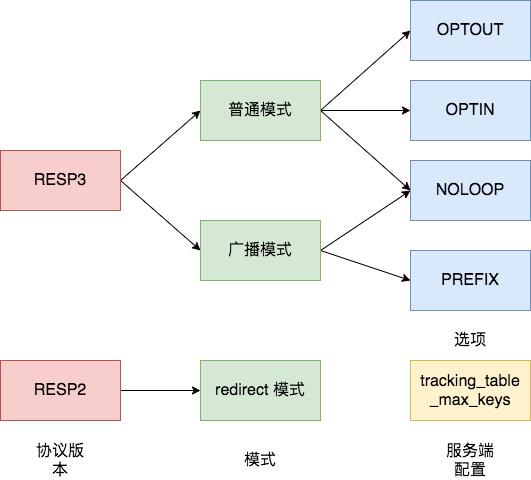
普通模式
先使用 redis-cli 设置缓存值 test=111,使用 telnet 连接上 Redis,然后发送 hello 3 开启 RESP3 协议。
[root@VM_0_3_centos ~]# telnet 127.0.0.1 6379
Trying 127.0.0.1...
Connected to 127.0.0.1.
Escape character is '^]'.
hello 3
// telnet 输出结果格式化标准化后如下,否则换行太多并且是 RESP3 格式,不需要了解格式。
> HELLO 3
1# "server" => "redis"
2# "version" => "6.0.1"
3# "proto" => (integer) 3
4# "id" => (integer) 10
5# "mode" => "standalone"
6# "role" => "master"
7# "modules" => (empty array)
这里需要注意,Redis 服务端只会 track 客户端在一个连接生命周期内的获取的只读命令的 key值。Redis 客户端默认不开启 track 模式,需要使用命令开启,然后必须要先获取一次 test 的值,这样 Redis 服务器才会记录它。
client tracking on
+OK
get test
$3
111
当键被修改,或者因为失效时间(expire time)和内存上限 maxmemory 策略被驱除时,Redis 服务端会通知这些客户端。我们这里简单地更新 test 的值,telnet 则会收到如下通知
>2 // RESP3 中的 PUSH 类型,标志为 > 符号
$10
invalidate
*1
$4
test
如果你再一次更新 test 值,这次 telnet 就不会再收到失效(invalidate)消息。除非 telnet 再进行一次 get 操作,重新 tracking 对应的键值。
也就是说 Redis 服务端记录的客户端 track 信息只生效一次,发送过失效消息后就会删除,只有下次客户端再次执行只读命令被 track,才会进行下一次消息通知 。
取消 tracking 的命令如下所示。
client tracking off
+OK
广播模式
Redis 还提供了一种广播模式(BCAST),它是另外一种客户端缓存的实现方式。这种方式下 Redis 服务端不再消耗过多内存存储信息,而是发送更多的失效消息给客户端。
这是服务端存储过多数据,消耗内存和客户端收到过多消息,消耗网络带宽之间的权衡(tradeoff)。
// 已经 hello 3 开启 RESP3 协议,不然无法收到失效消息,下同
client tracking on bcast
+OK
// 此时设置 key 为 a 的键值,收到如下消息。
>2
$10
invalidate
*1
$1
a
如果你不想所有的键值的失效消息都收到,则可以限制 key 的前缀,如下命令则表示只关注前缀为 test 的键值的消息。一般来说,业务的缓存 key 都是根据业务拥有统一的前缀,所以这一特性十分方便。
client tracking on bcast prefix test
与普通模式必须获取一次键的规则不同,广播模式下,只要键被修改或删除,符合规则的客户端都会收到失效消息,而且是可以多次获取的
与普通模式相比,虽然少存储了一些数据,但是由于需要对前缀规则进行匹配,会消耗一定的 CPU 资源,所以注意别使用过长的前缀。
转发模式
上述操作时客户端都需要先开启 RESP3,Redis 为了兼容 RESP2 协议提供了转发(Redirect)模式,不再使用 RESP3 原生支持 PUSH 消息,而是将消息通过 Pub/Sub 通知给另外一个客户端,具体流程如下图所示。
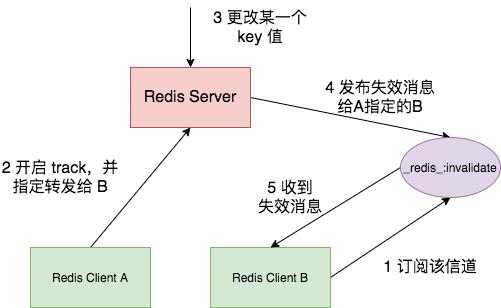
这里需要两个 telnet,其中一个 telnet 需要订阅 _redis_:invalidate 信道。然后另一个 telnet 开启 Redirect 模式,并制定将失效消息通过订阅信道发送给第一个 telnet。
# telent B
client id
:368
subscribe _redis_:invalidate
# telnet A,开启 track 并指定转发给 B
client tracking on bcast redirect 368
# telent B 此时有键值被修改,收到 __redis__:invalidate 信道的消息
message
$20
__redis__:invalidate
*1
$1
a
你会发现,转发模式和文章开始提到的多级缓存中的更新机制很类似了,只不过那个方案中是业务系统修改完 key 后发送消息通知,而这里是 Redis 服务端代替业务系统发送消息通知。
OPTIN 和 OPTOUT 选项
使用 OPTIN 可以选择性的开启 tracking。只有你发送 client caching yes (Redis 文档中是 CACHING 命令,但是实验时发现无效)之后的下一条的只读命令的 key 才会 tracking,否则其他的只读命令的 key 不会被 tracking。
client tracking on optin
client caching yes
get a
get b
// 此时修改 a 和 b 的值,发现只收到 a 的失效消息
>2
$10
invalidate
*1
$1
a
而 OPTOUT 参数与之相反,你可以有选择的退出 tracking。发送 client caching off 之后的下一条只读命令的 key 不会被 tracking,其他只读命令都会被 tracking。
OPTIN 和 OPTOUT 是针对非 BCAST 模式,也就是只有发送了某个 key 的只读命令后,才会追踪相应的 key。而 BCAST 模式是无论你是否发送某个 key 的只读命令,只有 Redis 修改了 key,都会发送相应的 key 的失效消息(前缀匹配的)。
NOLOOP 选项
默认情况下,失效消息会发送给所有需要的 Redis 客户端,但是有些情况下触发失效消息也就是更新 key 的客户端不需要收到该消息。
设置 NOLOOP,可以避免这种情况,更新 Key 的客户端将不再收到消息,该选项在普通模式和广播模式下都适用。
最大 tracking 上限 trackingtablemax_keys
由上文可以知道,普通模式下需要存储大量的被 tracking 的 key 和客户端信息(具体存储的数据下文中会讲解),所以当 10k 客户端使用该模式处理百万个键时,会消耗大量的内存空间,所以 Redis 引入了 trackingtablemax_keys 配置,默认为无,不限制。
当有一个新的键被 tracking 时,如果当前 tracking 的 key 的数量大于 trackingtablemax_keys,则会随机删除之前 tracking 的 key,并且向对应的客户端发送失效消息。
原理和源码实现
普通模式原理
我们也先讲解普通模式的原理,Redis 服务端使用 TrackingTable 存储普通模式的客户端数据,它的数据类型是基数树(radix tree)。
基数树是针对稀疏的长整型数据查找的多叉搜索树,能快速且节省空间的完映射,一般用于解决 Hash冲突和 Hash表大小的设计问题,Linux 的内存管理就使用了它。
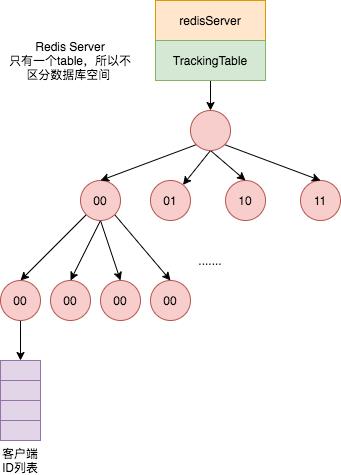
当开启 track 功能的客户端获取某一个键值时,Redis 会调用
enableTracking方法使用基数树记录下该 key 和 clientId 的映射关系。当某一个 key 被修改或删除时,Redis 会调用
trackingInvalidateKey方法根据 key 从 TrackingTable 中查找所有对应的客户端ID,然后调用sendTrackingMessage方法发送失效消息给这些客户端(会检查 CLIENT_TRACKING 相关标志位是否开启和是否开启了 NOLOOP)。发送完失效消息后,根据键的指针值将映射关系从 TrackingTable中删除。
客户端关闭 track 功能后,因为删除需要进行大量操作,所以 Redis 使用懒删除方式,只是将该客户端的 CLIENT_TRACKING 相关标志位删除掉。
广播模式原理
广播模式与普通模式类似,Redis 同样使用 PrefixTable 存储广播模式下的客户端数据,它存储前缀字符串指针和(需要通知的key和客户端ID)的映射关系。它和广播模式最大的区别就是真正发送失效消息的时机不同:
当客户端开启广播模式时,会在
PrefixTable的前缀对应的客户端列表中加入该客户端ID。当某一个 key 被修改或删除时,Redis 会调用
trackingInvalidateKey方法,trackingInvalidateKey方法中如果发现PrefixTable不为空,则调用trackingRememberKeyToBroadcast依次遍历所有前缀,如果key 符合前缀规则,则记录到PrefixTable对应的位置。在 Redis 的事件处理周期函数 beforeSleep 函数里会调用
trackingBroadcastInvalidationMessages函数来真正发送消息。
处理最大 tracking 上限
Redis 会在每次执行过命令后(processCommand方法)调用 trackingLimitUsedSlots 来判断是否需要进行清理:
判断 TrackingTable 中键的数量是否大于 trackingtablemax_keys;
在一定时间段内(不能太长,阻塞主流程),随机从 TrackingTable 中选出一个键删除,直到数量小于或者时间用完为止。
具体源码
关于源码,在 tracking.c 文件下,我们这里只看一下最为关键的 trackingInvalidateKey 函数和 sendTrackingMessage 函数,理解了这两个函数,广播模式和处理最大 tracking 上限等相关函数都与之类似。
void trackingInvalidateKey(client *c, robj *keyobj) {
if (TrackingTable == NULL) return;
sds sdskey = keyobj->ptr;
// 省略,如果广播模式的记录基数树不为空,则先处理广播模式
// 1 根据键的指针去 TrackingTable 查找
rax *ids = raxFind(TrackingTable,(unsigned char*)sdskey,sdslen(sdskey));
if (ids == raxNotFound) return;
// 2 使用迭代器遍历
raxIterator ri;raxStart(&ri,ids);raxSeek(&ri,"^",NULL,0);
while(raxNext(&ri)) {
// 3 根据 clientId 查找 client 实例
client *target = lookupClientByID(id);
// 4 如果未开启 track 或者是广播模式则跳过。
if (target == NULL ||
!(target->flags & CLIENT_TRACKING)||
target->flags & CLIENT_TRACKING_BCAST)
{ continue; }
// 5 如果开启了 NOLOOP 并且是导致key发生变化的client则跳过。
if (target->flags & CLIENT_TRACKING_NOLOOP &&
target == c)
{ continue; }
// 6 发送失效消息
sendTrackingMessage(target,sdskey,sdslen(sdskey),0);
}
// 7 减少数据统计,根据sdskey删除对应的记录
TrackingTableTotalItems -= raxSize(ids);
raxFree(ids);
raxRemove(TrackingTable,(unsigned char*)sdskey,sdslen(sdskey),NULL);
}
源码如上所示,trackingInvalidateKey 方法主要做了 7 件事情:
根据键的指针去 TrackingTable 查找客户端ID列表;
使用迭代器遍历列表;
根据 clientId 查找 client 实例;
如果 client 实例未开启 track 或者是广播模式则跳过;
如果 client 实例开启了 NOLOOP 并且是导致key发生变化的client则跳过;
调用 sendTrackingMessage 方法发送失效消息;
减少数据统计,根据sdskey删除对应的记录
下面来看真正发送消息的 sendTrackingMessage 函数,它主要做了6件事:
如果 clienttrackingredirection 不为空,则开启了转发模式;
找到转发的客户端实例;
如果转发客户端关闭了,则必须通知原客户端;
如果是客户端使用 RESP3 则发 PUSH 消息;
如果是转发模式,往 TrackingChannelName 也就是
_redis_:invalidate信道中发送失效消息的头部信息;发送键等信息。
void sendTrackingMessage(client *c, char *keyname, size_t keylen, int proto) {
int using_redirection = 0;
// 1 如果 client_tracking_redirection 不为空,则开启了转发模式
if (c->client_tracking_redirection) {
// 2 找到转发的客户端实例
client *redir = lookupClientByID(c->client_tracking_redirection);
if (!redir) {
// 3 如果转发客户端关闭了,则必须通知原客户端
....
return;
}
c = redir;
using_redirection = 1;
}
if (c->resp > 2) {
// 4 如果是 RESP3 则发PUSH
addReplyPushLen(c,2);
addReplyBulkCBuffer(c,"invalidate",10);
} else if (using_redirection && c->flags & CLIENT_PUBSUB) {
// 5 转发模式,往 TrackingChannelName 信道中发送消息
addReplyPubsubMessage(c,TrackingChannelName,NULL);
} else {
return;
}
// 6 发送键等信息,和上边4,5操作连在一起的。
addReplyProto(c,keyname,keylen);
}
后记
相信看到这里的小伙伴们都已经有点疲惫了吧,但是还请大家多多点赞多多评论。后续还会学习其他 Redis 6.0.0 的其他亮点功能,请大家继续关注。
参考
https://redis.io/topics/client-side-caching
https://tech.meituan.com/2017/03/17/cache-about.html
https://cloud.tencent.com/developer/article/1005399
https://juejin.im/post/5b849878e51d4538c77a974a
https://www.kawabangga.com/posts/3590
ppt https://www.slideshare.net/RedisLabs/redisconf18-techniques-for-synchronizing-inmemory-caches-with-redis
视频 https://www.bilibili.com/video/BV1qe411p7v9/
以上是关于带你100% 地了解 Redis 6.0 的客户端缓存的主要内容,如果未能解决你的问题,请参考以下文章