排序2-冒泡排序
Posted 嵌入式Max
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了排序2-冒泡排序相关的知识,希望对你有一定的参考价值。
本篇文章介绍冒泡排序及其优化方式与改进算法,从最简单的冒泡排序开始,不断地升级算法处理方式,介绍包括「鸡尾酒排序」、「梳排序」相关的实现与原理。
经典冒泡排序
其基本原理在之前的文章里面已经说过,就是利用相邻待排序数组的数组元素大小比较并交换达到整个序列的排序目的。基本的过程如下图所示:
图中红色的双向箭头就是指的比较与交换,图中的箭头指向的对象只是每一个元素的位置,并不是元素本身,它代表着「比较、交换」的前后的顺序,忽略图中箭头指向的具体元素值。通常情况下,最原始版本的冒泡排序是需要进行 N-1 次整个数组的遍历,每次都对整个数组区间范围的元素进行比较与交换,这个是最符合直觉的排序算法了,但是显然,它显得不那么的高效。
但是,作为开拓者,我还是需要把这个最原始的代码实现出来并且亲自测一测的,终于,本篇文章开始,可能就真的需要常常狂贴代码了,因为有些时候算法的优化或者理解,代码还是不可少的。首先就贴一波我写的经典冒泡排序的代码:
int classic_bubble_sort(int *sort_butt, int size, bool ascend)
{
int i = 0, idx = 0;
int end_idx = size-1;
int swap_tmp = 0;
for (i = 0; i < size-1; i++) {
for (idx = 0; idx < end_idx; idx++) {
if (sort_butt[idx] > sort_butt[idx+1]) {
swap_tmp = sort_butt[idx];
sort_butt[idx] = sort_butt[idx+1];
sort_butt[idx+1] = swap_tmp;
}
}
}
nb_logd("[%s] ", __FUNCTION__);
return 0;
}首先来分析下无聊的时间、空间复杂度啥的,最末尾那个函数形参先忽略掉,暂时没用,用不到它。简要分析下它的复杂度,首先它有内外两层循环,每级循环是 N-1 次,合起来就是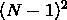 ,忽略掉低阶、常熟、系数等就是 O(N^2)。每一次循环里面都会有一个判断,判断如果成立的话会有对应的三次赋值。
,忽略掉低阶、常熟、系数等就是 O(N^2)。每一次循环里面都会有一个判断,判断如果成立的话会有对应的三次赋值。
所以比较详细的函数执行过程就是,(N-1)^2 次大小判断加上 (K-1)^2 次值交换。空间复杂度是 O(1),因为没有用到多余的数组,除了 swap_tmp 等几个临时变量。那么问题来了,这玩意儿该怎么去优化呢?这里还是列下最常用的几个点:
利用标志位(类似哨兵)来标识某一次循环是否有交换操作,如果没有则就此结束排序,因为此时数组就已经是有序的了。
内层循环每次循环之后就减去1个循环长度,因为每次循环过后就把最大(最小)的那个数放在了数组末尾,下次就无需再次全部遍历了。
基于上面的准则,下面来一个经典冒泡排序的优化代码:
int fast_bubble_sort(int *sort_butt, int size, bool ascend)
{
int i = 0, idx = 0;
int end_idx = size-1;
int swap_tmp = 0;
bool swap_flag = 0;
for (i = 0; i < size-1; i++) {
for (idx = 0; idx < end_idx; idx++) {
if (sort_butt[idx] > sort_butt[idx+1]) {
swap_tmp = sort_butt[idx];
sort_butt[idx] = sort_butt[idx+1];
sort_butt[idx+1] = swap_tmp;
swap_flag = 1;
}
}
if (!swap_flag)
goto end;
swap_flag = 0;
end_idx--;
}
end:
nb_logd("[%s] ", __FUNCTION__);
return 0;
}那么,它为什么快呢?先看下它的循环次数,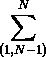 ,合计就是
,合计就是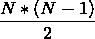 ,但是它比上一个代码里面多了个判断、赋值、减减操作。还多了若干个
,但是它比上一个代码里面多了个判断、赋值、减减操作。还多了若干个 swap_flag = 1 的操作。那么,它为什么就这么快呢,因为它虽然内部的操作多了点,但是架不住循环少了,少了几乎一半那种,并且这是在最坏的情况下,实际上运气好的话排到某个循环的时候就会满足 swap_flag = 0 了,那个时候就可以直接退出了。
那么,它究竟快多少呢?我在文章末尾的时候把所有的优化措施与改进算法与经典算法的耗时分别列出来看看。
鸡尾酒排序
那么,上面的优化已经很给力了,但是能不能更快啊?!这个时候就需要鸡尾酒排序出场了,它的基本思路是把上面的内层循环改为两个,一次从前到后(跟上面的一样)找最大值,一次从后往前找最小值,听起来是不是感觉循环更多了哈,代码如下:
int shaker_bubble_sort(int *sort_butt, int size, bool ascend)
{
int i = 0, idx = 0;
int end_idx = size-1, start_idx = 0;
int swap_tmp = 0;
bool swap_flag = 0;
while (start_idx < end_idx) {
for (idx = start_idx; idx < end_idx; idx++) {
if (sort_butt[idx] > sort_butt[idx+1]) {
swap_tmp = sort_butt[idx];
sort_butt[idx] = sort_butt[idx+1];
sort_butt[idx+1] = swap_tmp;
swap_flag = 1;
}
}
if (!swap_flag)
goto end;
swap_flag = 0;
end_idx--;
for (idx = end_idx; idx > start_idx; idx--) {
if (sort_butt[idx] < sort_butt[idx-1]) {
swap_tmp = sort_butt[idx];
sort_butt[idx] = sort_butt[idx-1];
sort_butt[idx-1] = swap_tmp;
swap_flag = 1;
}
}
if (!swap_flag)
goto end;
swap_flag = 0;
start_idx++;
}
end:
nb_logd("[%s] ", __FUNCTION__);
return 0;
}
我对上面的代码加了一个粗略的调试手段,就是在每一个满足排序成功退出时候的 swap_flag 标记位之后加上一个打印,看下经过优化的排序与鸡尾酒排序两者之间经历的循环次数,目前在我的机器上面使用随机数进行了多组测试,只列出数组长度是 5000 的情况:
| 排序算法 | 数组长度 | 外层循环次数 |
|---|---|---|
| 经典冒泡 | 5000 | 5000 |
| 优化冒泡 | 5000 | 4912 |
| 经典冒泡 | 5000 | 1242 |
可以看到虽然鸡尾酒排序的内层循环看起来多了一层,但是即使是把循环的次数加倍也没有优化过后的冒泡排序循环次数多,所以这就造成鸡尾酒排序的时间消耗最终还是比其它的冒牌排序更快。那么,问题是:为什么它的总的循环次数就这么少呢?表面一点的解释是因为它每次内部循环的时候都会搬移一个最大的值到未排序区间的末尾,搬移一个最小的值到未排序区间的开头。
那么,按照常规的理解,虽然你这样搬会一次搬运两个极值,但是你这个循环多了一次啊,这么一算,好像理论上来讲并没有减少多少循环次数啊。我们看那个鸡尾酒排序的内层循环的代码,它的循环次数也是由 N-1 往下递减,比如第一次外层循环,内层循环的第一个找最大值循环是 N-1 次,第二个找最小值循环是 N-2 次,往后依次递减,如果不考虑数据的有序度的话,鸡尾酒排序与优化的冒泡排序的理论循环次数是相等的,怎么也不会比它快啊。
问题就在于数据的有序度上面,在鸡尾酒排序状态下,保持理论的最大循环次数怎么都不会超过优化过后的冒泡排序,同时鸡尾酒排序加快了整体数组数据的有序性进度(因为它每次找两个极值嘛),它会让小的数尽快地转移到数组的开头,而优化的经典冒泡排序小的数每次都是被动的慢慢往数组的开头移动。这就造成从概率上来讲,大概率你每次搬运两个极值的情况下会比每次单方向搬运一个极值的情况下更快的让整个数组变得有序,从而提前退出整个循环。
我这个没有非常确切的数学模型来描述它,我也不尝试去证明这个玩意儿了,感觉至少现在对我来说,费老鼻子劲去从数学上建模并证明它是付出与收获不成正比的。我只能按照自己的理解方式从一个大概的方向上去描述它。
梳排序
鸡尾酒排序看起来已经很快了哈,那么,能不能更快呢(快无止境啊)?!答案是,果然还能更快,看看,就个冒泡排序都能玩出花来,先看下它的排序操作图:
梳排序的原理是比较骚气的,它重在走位风骚,它每次不是只迈一步,而是一次迈出好几步的距离,但是它不会扯着蛋,这怎么比,这完全比不了嘛!先上个代码:
int gap_bubble_sort(int *sort_butt, int size, bool ascend)
{
int i = 0, idx = 0;
int end_idx = 0;
int swap_tmp = 0;
int gap = size;
bool swap_flag = 1;
while(swap_flag || gap != 1) {
swap_flag = 0;
gap /= 1.3;
gap = (gap < 1) ? 1 : gap;
end_idx = size-gap;
for (idx = 0; idx < end_idx; idx++) {
if (sort_butt[idx] > sort_butt[idx+gap]) {
swap_tmp = sort_butt[idx];
sort_butt[idx] = sort_butt[idx+gap];
sort_butt[idx+gap] = swap_tmp;
swap_flag = 1;
}
}
}
end:
nb_logd("[%s] ", __FUNCTION__);
return 0;
}可以看到,它的步长是按照 gap = gap/1.3 来依次递减的,那么先不管它为什么快啊,咱就先说下为什么是 1.3,它不是 1.5,也不是 2,它怎么就整出来个 1.3。根据维基百科来讲呢,这个值是试出来的,没错,它就是试出来的,据说是尝试了 2000 个以上的数,最终优中选优得到的这个数,感觉跟卡马克的求平方根倒数那个静态魔数有的一拼,后面在快速排序里面还能够看到类似这种不知道哪里蹦出来的数,但它就是很神奇的加速了整个的排序过程。
为了验证下梳排序的性能,我也加了些打印调试,在 5000 个数的时候:
| Gap比例 | 数组长度 | 外层循环次数 |
|---|---|---|
| 1.3 | 5000 | 33 |
| 1.5 | 5000 | 531 |
| 1.2 | 5000 | 41 |
这么一比,事情就是这么的神奇,更多的数我没有试过哦,我就试了这三个,我不想试好几千个,总之甭管为什么了,1.3 就是最屌的,那就先用着呗。还有没有发现一个问题,梳排序的交换次数也太少了,比起上面的鸡尾酒啥的少了好几十倍那种,这个性能也是有点恐怖的,这个快的让我一度怀疑程序是不是写错了,后来加了一个验证程序在后面,发现好像它就是这么快,这么不讲道理。
那么,它又是为什么这么快的呢,首先要明确一个点,那就是判断比交换省的时间更多,梳排序以更长的跨度来比较交换,它会使得原有的数组更快的趋于有序,为什么呢?因为它的跨度大,如果数组当中比较大的数恰好在这个大跨度比较的某个节点,那么这个数只需要比之前少的多的交换即可到达数组的终点。
又是从概率上来讲,大跨度加速了交换的效率,把大的数据尽可能的一次性直接从接近头部搬到接近尾部,同样的,在交换过程中小的数据也能够尽可能一次性的从尾部搬到接近头部,开始的跨度大,循环需要的时间短,并且前期的积累给整个数组带来了更有序的特点,每次更大的跨度排序完毕,这个数组就变得更加有序了一点,往后需要额交换就越少,判断比交换耗费的时间更短,这就是它为什么这么快。
对比
| 算法 | 数组长度 | 外层循环次数 | 时间消耗 | 平均时间复杂度(稍微精确了点儿) |
|---|---|---|---|---|
| 经典冒泡 | 5000 | 5000 | 103.41ms |
|
| 优化冒泡 | 5000 | 4912 | 61.044ms |
|
| 鸡尾酒 | 5000 | 1242 | 59.114ms |
|
| 梳排序 | 5000 | 33 | 0.846ms |
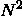
k 的值为 1.3。可以想到,梳排序是不稳定的排序算法,因为 Gap 大于 1,可能会把中间的值给隔过去了。对于代码本身还是可以可以有进一步优化空间的,比如 if 比 x>y?x:y 这样的更快,循环的时候不要每次都计算 size-1,提前算好一次就行这类的优化,不过这不是重点,不再赘述了。
End
那么,还能不能更快呢?!对于冒泡排序来说,我暂时无能为力了。冒泡排序就这么搞完啦,下一波就是选择排序和插入排序了,这两个可以放到一起说下。完整的代码放到:Github 这里
现在还没上传,稍后整理下上传。微信客户端直接阅读原文就可以看到啦。
以上是关于排序2-冒泡排序的主要内容,如果未能解决你的问题,请参考以下文章