Kafka网络模型设计研究
Posted 小张的科学日记
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Kafka网络模型设计研究相关的知识,希望对你有一定的参考价值。
之前做过一版网络库的常规设计,里面简单对照了redis、evio、kafka的网络(通信)设计,而这三个中尤以kafka的网络设计最为复杂,这里将对Kafka的网络通信部分做一次简单的review,在结尾处将展示一个我们自己实现的Java简版Kafka的运作,简版抛弃了一些脏活累活,期望在系列结束后能作为一个生产级别的MQ。
而在之前的某一篇中被提到有些脱离原理,所以这里开始对某些内容会更细di致ji一点,或者说,这篇更多是如果是我该如何考虑实现kafka这件事。
一、前言
Kafka的网络在各个版本中实现有较大的差异,在最早开源的0.7中network线程(参数num.network.threads指代的线程,主要负责网络io,读写缓存数据)和io线程(参数num.io.threads指代的线程,主要负责磁盘io,处理network线程解析出来的请求,生成response),这两个工作是共用线程池的,这就出现了一个老生常谈的问题,当epoll触发了很多读写事件后,由于其中一件事件处理很慢,拖累该epoll上所有事件。
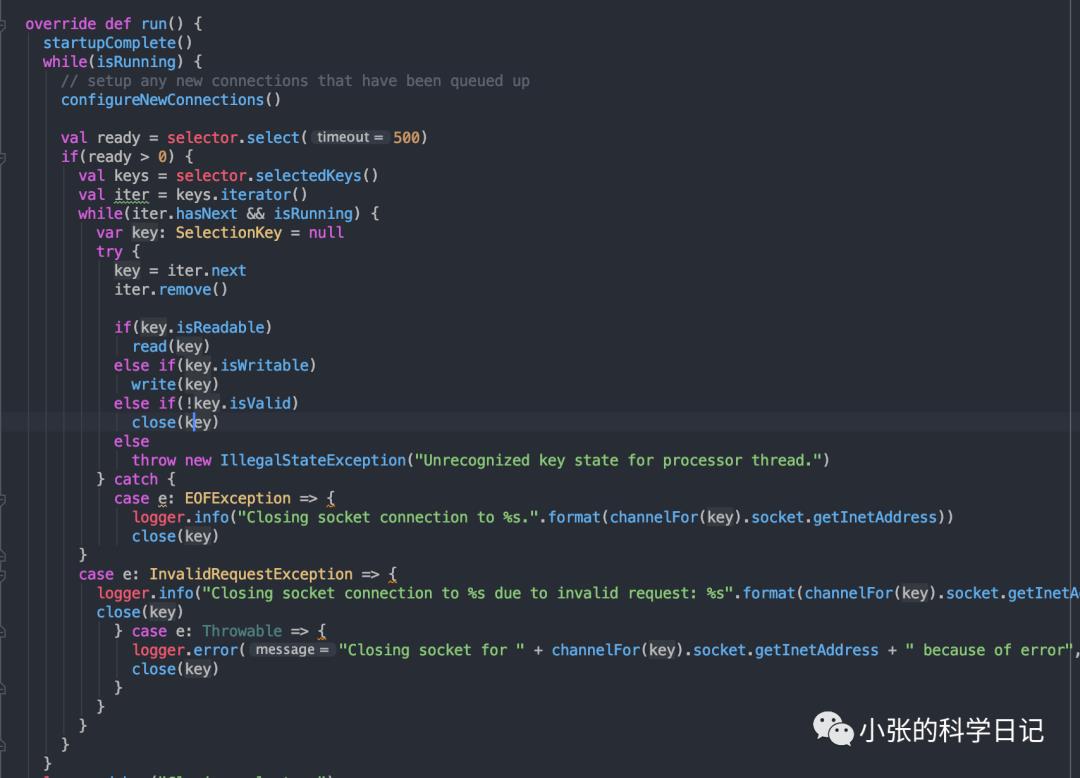
在Kafka 0.8后对这两处进行了分离,引入了一个RequestChannel组件,将网络io和磁盘io这两个职责进行了解耦,从此开始了后续版本一直沿用的1:n:m网络模型,那这个新组件和这个网络模型是如何工作的呢?
1:n:m中的1是一个Acceptor,我们谈它的职责是处理连接的建立,所以你们会看到很多不同的实现,我用epoll注册socket只对connet感兴趣,可以吧,我直接用socket然后accept,也可以吧,但他们职责是相同的,就是建立连接。
n是n个Selector,每个Selector都等同于一个epoll,当连接建立后,我是不能放在Acceptor中做读写缓冲,处理请求这种耗时的事情的,这会影响后续连接的建立,降低我的吞吐量,所以我们在1后面放n个epoll,对于1接受到的socketchannel(Java名词,非Java的请代之以fd,fd是文件描述符,linux系统调用epollctl的参数即为socket的fd),对于这些新建立的连接,我们使用round robin算法将他们分散注册到n个epoll上,并设置对这些fd的感兴趣事件是读,为什么是读呢?总不会有连接刚上来就要写吧,它(客户端)总得先来获取api版本啦、metadata啦这些吧。
还有一点扩展性的内容,和边沿触发和水平触发有关,但是大家应该都是用的水平触发,所以不是很有必要说明的,边沿触发是当缓冲区有了数据,或者数据消失,在这样一个跳变时刻触发对应的读写事件给epoll,水平触发则是当缓冲区存在数据或者不存在数据,这样的某个状态下触发对应的读写事件,理论上看起来是ET性能高一点,但ET会碰到数据读不完的问题,LT就简单一些,据我了解,只有Netty4实现了ET,别的网络库应该都是LT,并且在实测上ET也没有很明显的性能优势。
所以LT的情况下,上来只要注册读事件就可以了,不然缓冲区一直为空,就会一直触发写事件,而对应的用户空间的缓冲也为空,就很尴尬了。
m是m个Handler,当Selector响应对应的事件后,我们需要从缓冲区读取出完整的数据(这里有一次内核空间到用户空间的拷贝),按照我们定义的协议,解析成对应的request(举个例子,kafka就是前一个short做长度,然后apikey,apiversion,correlationId等等等等),然后将这个request放到RequestChannel中,RequestChannel中维护了一个Request的队列,它还定义了Request和Response的格式等一些通用的东西,负责规范化和解耦。m个handler就从RequestChannel的Request的队列中poll出请求做处理,处理完成后生成Reponse再放到RequestChannel的Response队列中,Selector则从Response中poll出新Response,将Response对应的fd注册好写事件,等待其触发后将Response序列化后写入缓冲区(一次用户空间到内核空间的拷贝),至此一个完整的请求就处理好了。
再后来到了0.10,发现Acceptor也不是直接注册到Selector了,而是交给Selector中newconnectors队列,再由Selector轮询newconnectors来处理新连接,Acceptor减少了注册到epoll的过程,可以更快的建立下一个连接了。同时也抽象出来KafkaChannel对象,前面也发现了我们省略了用户空间到缓冲区的数据的传输,而KafkaChannel就是一个用户空间的对象用来对应内核fd和其缓冲区数据,我们直接操作这个对象,至于KafkaChannel如何向缓冲区读取数据写入数据对我们是透明的(这块无非就是弄个byte[]写到缓冲区,或者读取byte[]然后解析一下,在多封装个加密)。
当然,从缓冲区读取数据到用户空间,就需要我们申请一块内存,我们当然可以new byte[],那么如果我们提前申请一块空间是不是就避免了这种频繁的new呢,在1.0后Kafka引入了memoryPool,又减少了内存分配的时间。
1.0做的不止如此,之前的几个版本,将所有同步进行的操作转成了异步,即不接收执行结果,而在下一次的轮询中检查,到了这个版本,增加了零拷贝优化,零的是用户空间和内核空间的拷贝。
至此,Kafka在网络上的高性能就基本完成了,我们总结一下,其中包含零拷贝、内存池、异步、epoll以及无处不在的中件缓存(newconnections、RequestChannel...)。
二、网络模型图示
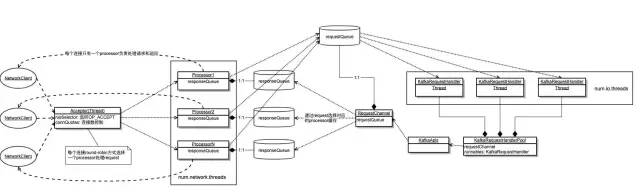
这种网络架构就不存在任何问题了吗?
当然不是,其中最显眼的RequestChannel,这里集中了所有topic的请求,一旦有一个topic处理的很慢,将会在这里影响到所有的topic,我们之前有一次坏网络导致的问题,我猜测问题就是出在这里。
三、关于零拷贝技术
这种网络层面的优化无非就是上面几种:异步、零拷贝、内存池、批量处理,零拷贝其中比较有技术含量的。
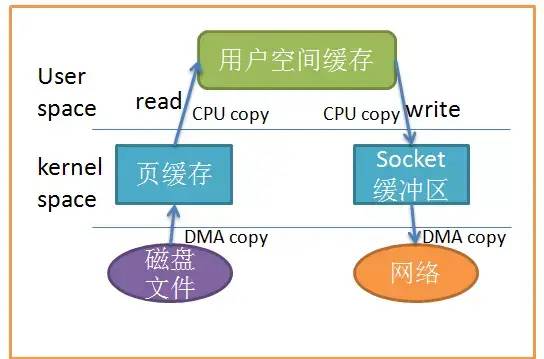
当我们做消费,首先从磁盘把数据拷贝到用户空间,然后从用户空间拷贝的网络,有DMA的情况下,仍然有两次拷贝,在Linux2.1后直接使用sendfile将源文件中偏移量xx的数据直接发到某socket,不用过用户空间,对上层Java来说就是filechannel.transferTo。
其实epoll、sendfile、reuseport、reuseaddr、io_uri,好像越来越多的事情交给内核去做了。
四、结尾
我们自己按照思路实现一下Java简版Kafka,并且完成一个简单的元数据获取测试,模拟0.7版本的1:n网络模型,为了省事n=1,模拟0.8的元数据协议。
Acceptor如下
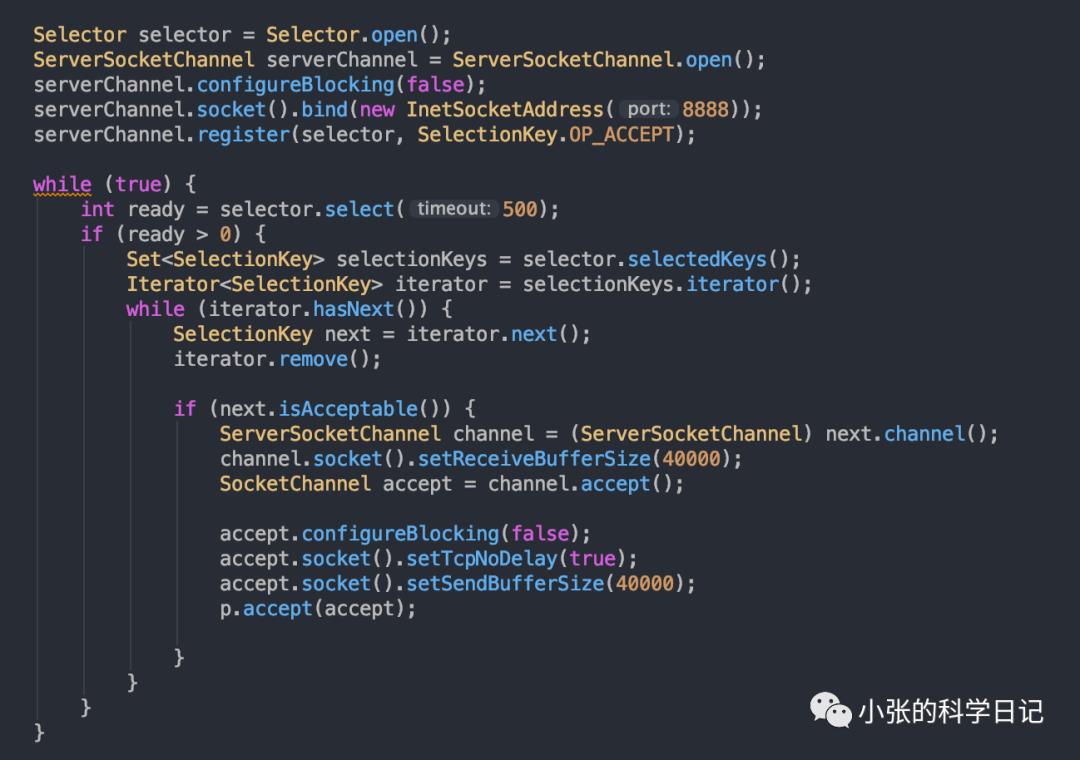
Selector
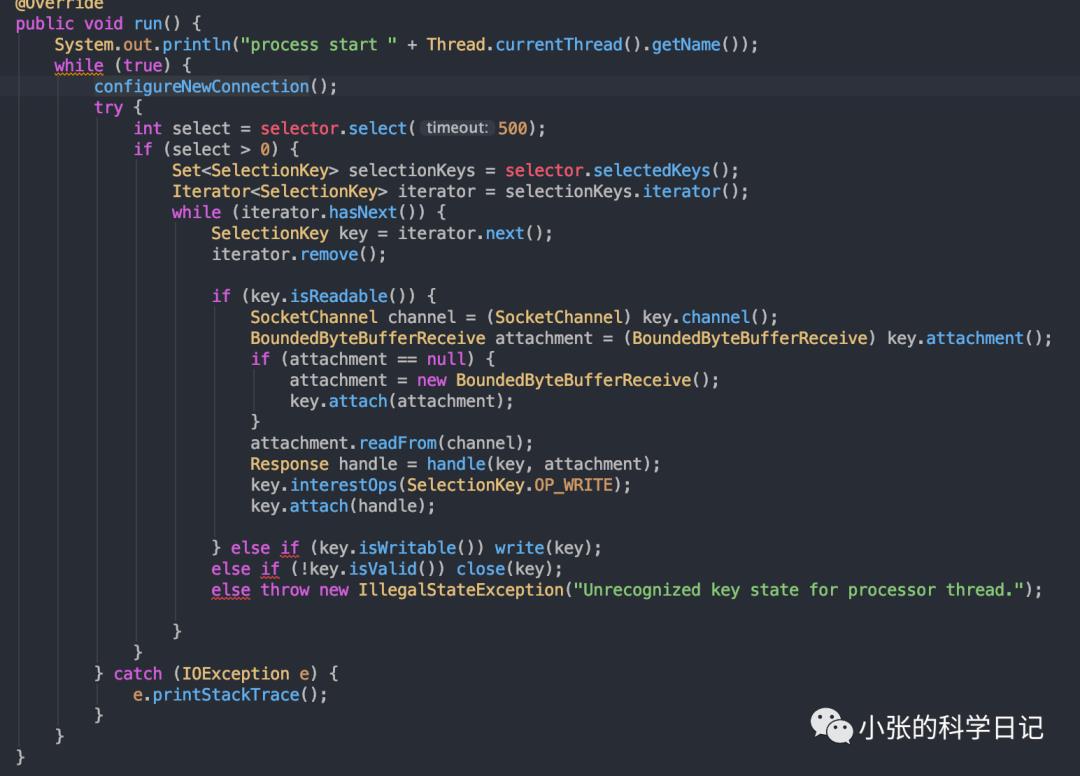
Handler
这里本来要实现2.4的协议,太麻烦了,所以只实现了0.8的apikey=3
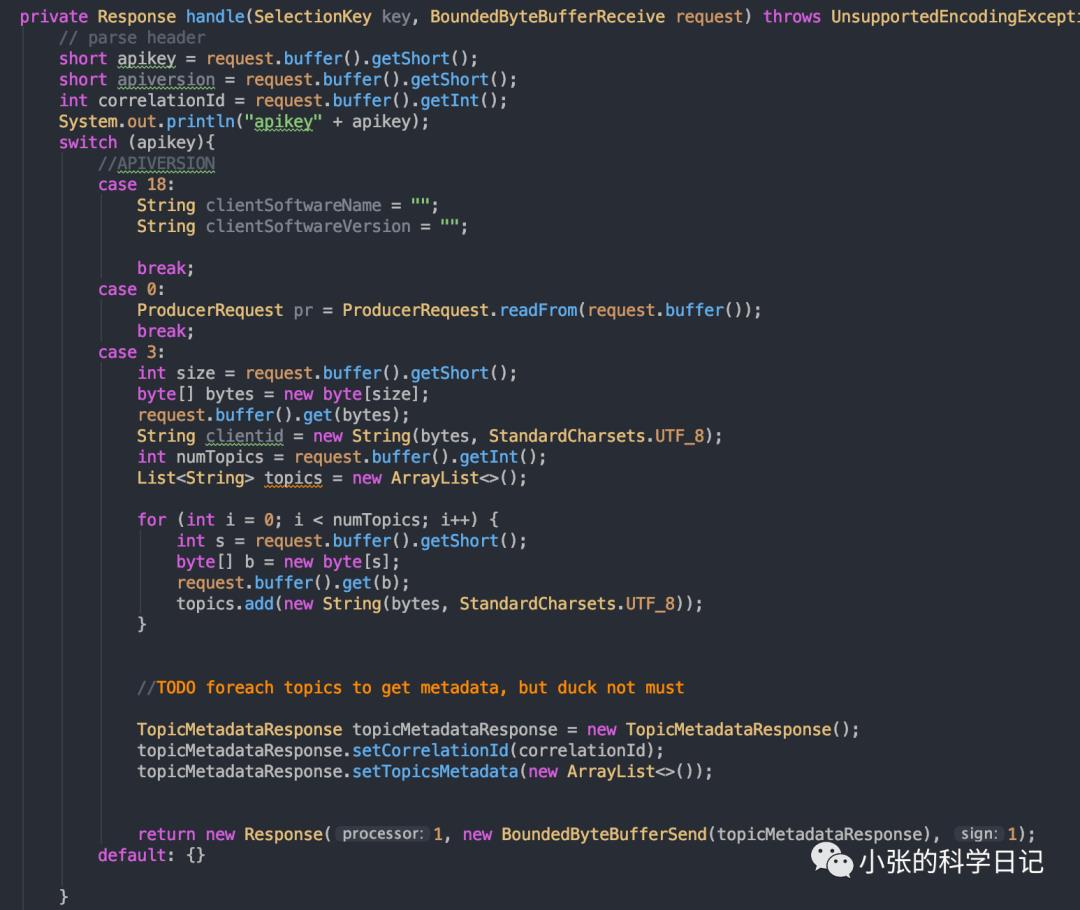
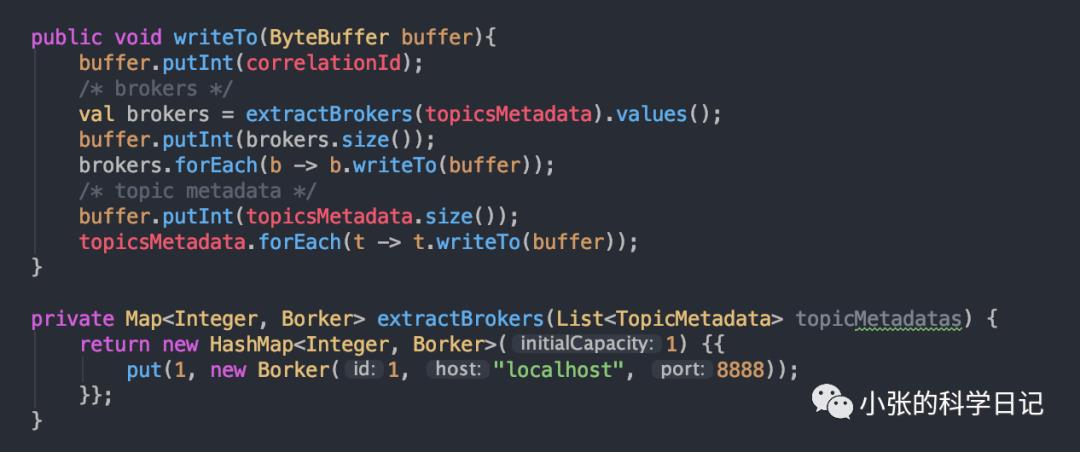
响应还用的假数据,毕竟没整合zk,假数据如下:
启动简版只支持元数据和生产协议的kafka:
启动生产者,看到我们造的假数据[1, localhost, 8888]:
测试通过,毕竟时间有限,后续将按照我们的分析,将网络模型和协议完善。
以上是关于Kafka网络模型设计研究的主要内容,如果未能解决你的问题,请参考以下文章