神经网络模型遇到瓶颈?这些Tricks让你相见恨晚!
Posted 计算机视觉life
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了神经网络模型遇到瓶颈?这些Tricks让你相见恨晚!相关的知识,希望对你有一定的参考价值。
快速获得最新干货
其实图像分类研究取得的大部分进展都可以归功于训练过程的改进,如数据增加和优化方法的改变。但是,大多数改进都没有比较详细的说明。因此作者在本文中测试实现了这些改进的方法,并通过消融实验来评估这些Tricks对最终模型精度的影响。作者通过将这些改进结合在一起,同时改进了各种CNN模型。在ImageNet上将ResNet-50的Top-1验证精度从75.3%提高到79.29%。同时还将证明了提高图像分类精度会在其他应用领域(如目标检测和语义分割)也可以带来更好的迁移学习性能。
1、Introduction
近年来ImageNet的榜单一直在被刷新,从2012年的AlexNet,再到VGG-Net、NiN、Inception、ResNet、DenseNet以及NASNet;Top-1精度也从62.5%(AlexNet)->82.7%(NASNet-A);但是这么大精度的提升也不完全是由模型的架构改变所带来的,其中 训练的过程也有会起到很大的作用,比如,损失函数的改进、数据的预处理方式的改变、以及优化方法的选择等;但是这也是很容易被忽略的部分,因此这篇文章在这里也会着重讨论这个问题。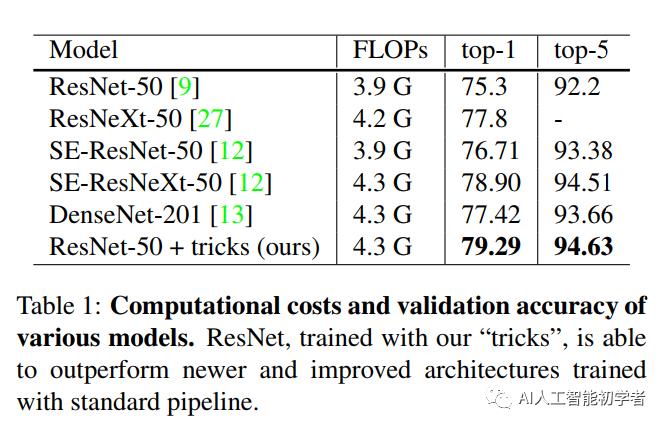
2、Efficient Training
近年来硬件发展迅速,特别是GPU。因此,许多与性能相关的权衡的最佳选择也会随之发生变化。例如,在训练中使用较低的数值精度和较大的Batch_Size更有效。
在本节中将在不牺牲模型精度的情况下实现低精度和大规模批量训练的各种技术。有些技术甚至可以提高准确性和训练速度。
2.1、Large-batch training
Mini-Batch SGD将多个样本分组到一个小批量中,以增加并行性,降低传输成本。然而,使用Large Batch-size可能会减慢训练进度。对于凸优化问题,收敛率随着批量大小的增加而降低。类似的经验结论已经被发表。
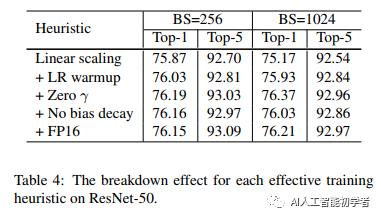
换句话说,在相同的epoch数量下,使用Large Batch-size的训练会与使用较小批次的训练相比,模型的验证精度降低。很多研究提出了启发式搜索的方法来解决这个问题。下面将研究4种启发式方法,可以在单台机器训练中扩大Batch-size的规模。
1)Linear scaling learning rate
在Mini-Batch SGD中,由于样本是随机选取的,所以梯度下降也是一个随机的过程。增加批量大小不会改变随机梯度的期望,但会减小随机梯度的方差。换句话说,大的批量降低了梯度中的噪声,因此我们可以通过提高学习率来在梯度相反的方向上取得更大的进展。
Goyal等人提出对于ResNet-50训练,经验上可以根据批大小线性增加学习率。特别是,如果选择0.1作为批量大小256的初始学习率,那么当批量大小b变大时可以将初始学习率提高到:
在训练开始时,所有参数通常都是随机值,因此离最优解很远。使用过大的学习率可能导致数值不稳定。在Warmup中,在一开始使用一个比较小的学习率,然后当训练过程稳定时切换回初始设置的学习率base_lr。
Goyal等人提出了一种Gradual Warmup策略,将学习率从0线性地提高到初始学习率。换句话说,假设将使用前m批(例如5个数据epoch)进行Warmup,并且初始学习率为 ,那么在第 批时 将学习率设为i =m。
3)Zero
一个ResNet网络由多个残差块组成,而每个残差块又由多个卷积层组成。给定输入
,假设
是Last Layer的输出,那么这个残差块就输出
。注意,Block的最后一层可以是批处理标准化
层。
BN层首先标准化它的输入
,然后执行一个scale变换
。两个参数
都是可学习的,它们的元素分别被初始化为1s和0s。在零初始化启发式中,剩余块末端的所有BN层初始化了
。因此,所有的残差块只是返回它们的输入,模拟的网络层数较少,在初始阶段更容易训练。
4)No bias decay
权值衰减通常应用于所有可学习参数,包括权值和偏差。它等价于应用L2正则化到所有参数,使其值趋近于0。但如Jia等所指出,建议仅对权值进行正则化,避免过拟合。无偏差衰减启发式遵循这一建议,它只将权值衰减应用于卷积层和全连通层中的权值。其他参数,包括偏差和
和
以及BN层,都没有进行正则化。
LARS提供了分层自适应学习率,并且对大的Batch-size(超过16K)有效。本文中单机训练的情况下,批量大小不超过2K通常会导致良好的系统效率。
2.2、Low-precision training
神经网络通常是用32位浮点(FP32)精度训练的。也就是说,所有的数字都以FP32格式存储,输入和输出以及计算操作都是FP32类型参与的。然而,新的硬件可能已经增强了新的算术逻辑单元,用于较低精度的数据类型。
例如,前面提到的Nvidia V100在FP32中提供了14个TFLOPS,而在FP16中提供了超过100个TFLOPS。如下表所示,在V100上从FP32切换到FP16后,整体训练速度提高了2到3倍。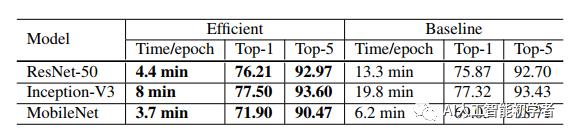 尽管有性能上的好处,降低的精度有一个更窄的范围,使结果更有可能超出范围,然后干扰训练的进展。Micikevicius等人提出在FP16中存储所有参数和激活,并使用FP16计算梯度。同时,FP32中所有的参数都有一个用于参数更新的副本。此外,损失值乘以一个比较小的标量scaler以更好地对齐精度范围到FP16也是一个实际的解决方案。
尽管有性能上的好处,降低的精度有一个更窄的范围,使结果更有可能超出范围,然后干扰训练的进展。Micikevicius等人提出在FP16中存储所有参数和激活,并使用FP16计算梯度。同时,FP32中所有的参数都有一个用于参数更新的副本。此外,损失值乘以一个比较小的标量scaler以更好地对齐精度范围到FP16也是一个实际的解决方案。
2.3、Experiment Results
3、Model Tweaks
模型调整是对网络架构的一个小调整,比如改变一个特定卷积层的stride。这样的调整通常不会改变计算复杂度,但可能会对模型精度产生不可忽略的影响。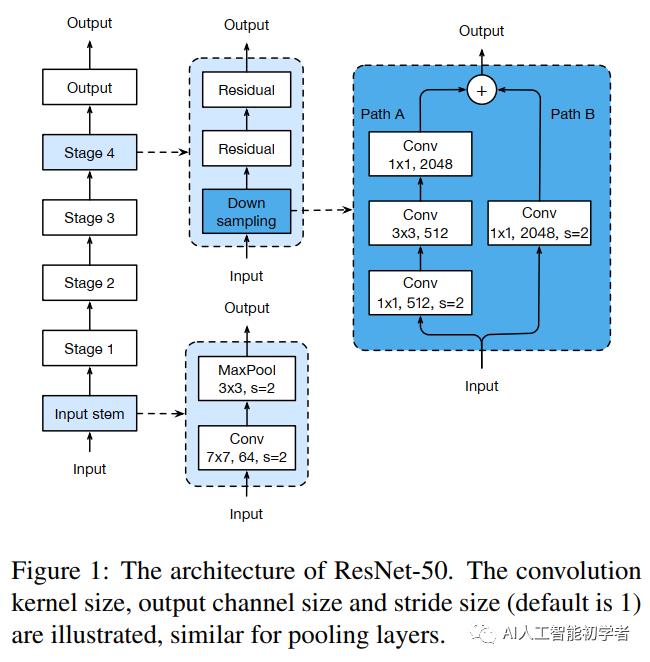
3.1、ResNet Tweaks
回顾了ResNet的两个比较流行的改进,分别称之为ResNet-B和ResNet-C。在此基础上,提出了一种新的模型调整方法ResNet-D。
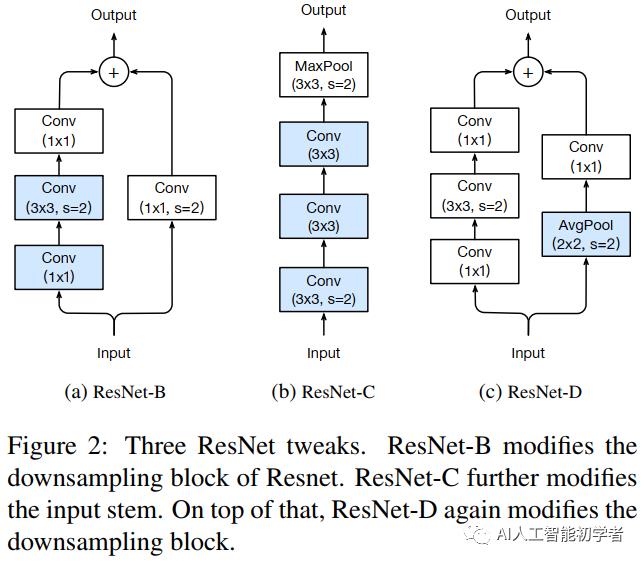 1)ResNet-B
1)ResNet-B
ResNet-B改变的下采样块。观察到路径A中的卷积忽略了输入feature map的四分之三,因为它使用的内核大小为1×1,Stride为2。ResNet-B切换路径A中前两个卷积的步长大小,如图a所示,因此不忽略任何信息。由于第2次卷积的kernel大小为3×3,路径a的输出形状保持不变。
2)ResNet-C
卷积的计算代价是卷积核的宽或高的二次项。一个7×7的卷积比3×3的卷积的计算量更大。因此使用3个3x3的卷积替换1个7x7的卷积,如图b所示,与第1和第2个卷积block的channel=32,stride=2,而最后卷积使用64个输出通道。
3)ResNet-D
受ResNet-B的启发,下采样块B路径上的1x1卷积也忽略了输入feature map的3/4,因此想对其进行修改,这样就不会忽略任何信息。通过实验发现,在卷积前增加一个平均为2x2的avg pooling层,将其stride改为1,在实践中效果很好,同时对计算成本的影响很小。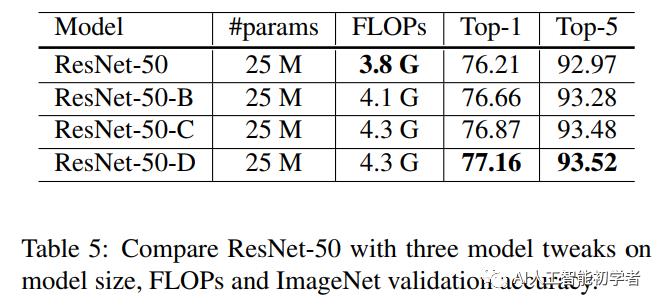
4、Training Refinements
4.1、Cosine Learning Rate Decay
Loshchilov等人提出了一种余弦退火策略。一种简化的方法是通过遵循余弦函数将学习率从初始值降低到0。假设批次总数为T(忽略预热阶段),那么在批次T时,学习率tm计算为:
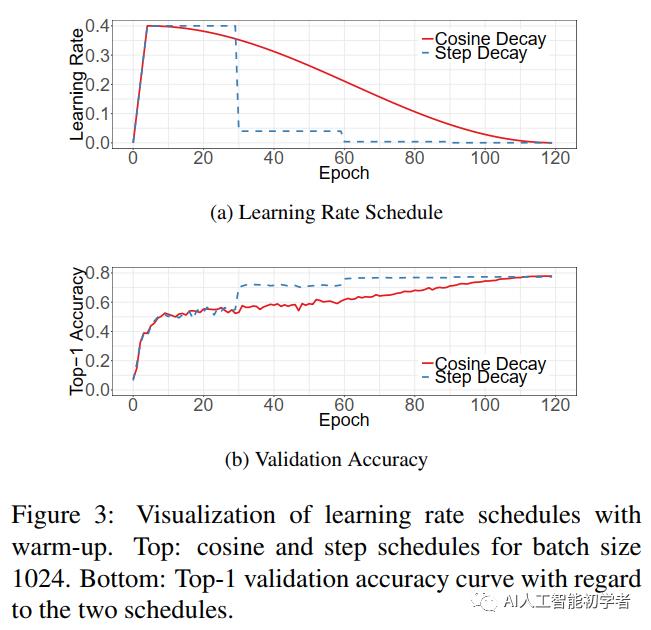
可以看出,余弦衰减在开始时缓慢地降低了学习速率,然后在中间几乎变成线性减少,在结束时再次减缓。与step衰减相比,余弦衰减从一开始就对学习进行衰减,但一直持续到步进衰减将学习率降低了10倍,从而潜在地提高了训练进度。
import torch
optim = torch.optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max, eta_min=0, last_epoch=-1)
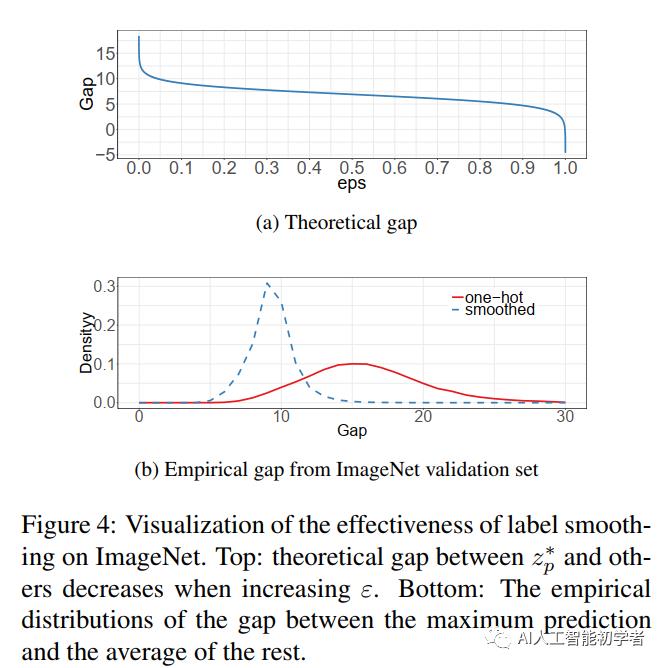
4.2、Label Smoothing
对于输出预测的标签不可能像真是的label一样真是,因此这里进行一定的平滑策略,具体的Label Smoothing平滑规则为:
# -*- coding: utf-8 -*-
"""
qi=1-smoothing(if i=y)
qi=smoothing / (self.size - 1) (otherwise)#所以默认可以fill这个数,只在i=y的地方执行1-smoothing
另外KLDivLoss和crossentroy的不同是前者有一个常数
predict = torch.FloatTensor([[0, 0.2, 0.7, 0.1, 0],
[0, 0.9, 0.2, 0.1, 0],
[1, 0.2, 0.7, 0.1, 0]])
对应的label为
tensor([[ 0.0250, 0.0250, 0.9000, 0.0250, 0.0250],
[ 0.9000, 0.0250, 0.0250, 0.0250, 0.0250],
[ 0.0250, 0.0250, 0.0250, 0.9000, 0.0250]])
区别于one-hot的
tensor([[ 0., 0., 1., 0., 0.],
[ 1., 0., 0., 0., 0.],
[ 0., 1., 0., 0., 0.]])
"""
import torch
import torch.nn as nn
from torch.autograd import Variable
import matplotlib.pyplot as plt
import numpy as np
class LabelSmoothing(nn.Module):
"Implement label smoothing. size表示类别总数 "
def __init__(self, size, smoothing=0.0):
super(LabelSmoothing, self).__init__()
self.criterion = nn.KLDivLoss(size_average=False)
#self.padding_idx = padding_idx
self.confidence = 1.0 - smoothing#if i=y的公式
self.smoothing = smoothing
self.size = size
self.true_dist = None
def forward(self, x, target):
"""
x表示输入 (N,M)N个样本,M表示总类数,每一个类的概率log P
target表示label(M,)
"""
assert x.size(1) == self.size
true_dist = x.data.clone()#先深复制过来
#print true_dist
true_dist.fill_(self.smoothing / (self.size - 1))#otherwise的公式
#print true_dist
#变成one-hot编码,1表示按列填充,
#target.data.unsqueeze(1)表示索引,confidence表示填充的数字
true_dist.scatter_(1, target.data.unsqueeze(1), self.confidence)
self.true_dist = true_dist
return self.criterion(x, Variable(true_dist, requires_grad=False))
if __name__=="__main__":
# Example of label smoothing.
crit = LabelSmoothing(size=5,smoothing= 0.1)
#predict.shape 3 5
predict = torch.FloatTensor([[0, 0.2, 0.7, 0.1, 0],
[0, 0.9, 0.2, 0.1, 0],
[1, 0.2, 0.7, 0.1, 0]])
v = crit(Variable(predict.log()),
Variable(torch.LongTensor([2, 1, 0])))
# Show the target distributions expected by the system.
plt.imshow(crit.true_dist)
4.3、Knowledge Distillation
在训练过程中增加了一个蒸馏损失,以惩罚Teacher模型和Student模型的softmax输出之间的差异。给定一个输入,设p为真概率分布,z和r分别为学生模型和教师模型最后全连通层的输出。损失改进为:
4.4、Mixup Training
在Mixup中,每次我们随机抽取两个例子 和 。然后对这2个sample进行加权线性插值,得到一个新的sample:
其中
import numpy as np
import torch
def mixup_data(x, y, alpha=1.0, use_cuda=True):
if alpha > 0.:
lam = np.random.beta(alpha, alpha)
else:
lam = 1.
batch_size = x.size()[0]
if use_cuda:
index = torch.randperm(batch_size).cuda()
else:
index = torch.randperm(batch_size)
mixed_x = lam * x + (1 - lam) * x[index,:] # 自己和打乱的自己进行叠加
y_a, y_b = y, y[index]
return mixed_x, y_a, y_b, lam
def mixup_criterion(y_a, y_b, lam):
return lambda criterion, pred: lam * criterion(pred, y_a) + (1 - lam) * criterion(pred, y_b)
4.5、Experiment Results
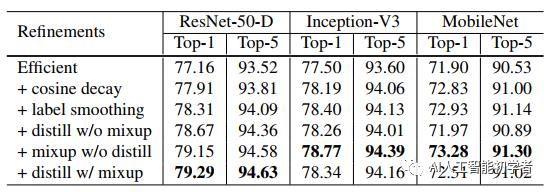
5、Transfer Learning
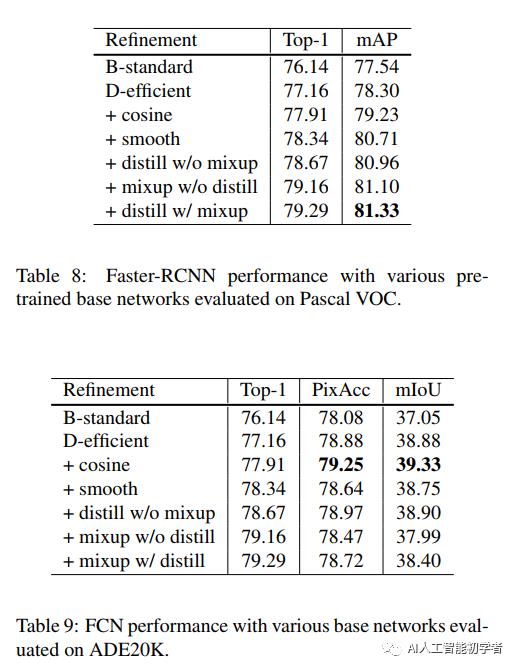
更多详细内容可以参考论文原文。
References
[1] Bag of Tricks for Image Classification with Convolutional Neural Networks
[2] https://github.com/rwightman/pytorch-image-models
交流群
投稿、合作也欢迎联系:simiter@126.com
扫描关注视频号,看最新技术落地及开源方案视频秀 ↓
以上是关于神经网络模型遇到瓶颈?这些Tricks让你相见恨晚!的主要内容,如果未能解决你的问题,请参考以下文章
tricks深度神经网络模型训练中的 tricks(原理与代码汇总)