学习教程深度神经网络模型训练中的 tricks(原理与代码汇总)
Posted 信息网络工程研究中心
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了学习教程深度神经网络模型训练中的 tricks(原理与代码汇总)相关的知识,希望对你有一定的参考价值。
阅读大概需要15分钟Follow小博主,每天更新前沿干货

导读
本文总结了多种图像分类任务中的重要技巧,对于目标检测和图像分割等任务,也起到了不错的作用。
Warmup
Linear scaling learning rate
Label-smoothing
Random image cropping and patching
Knowledge Distillation
Cutout
Random erasing
Cosine learning rate decay
Mixup training
AdaBoud
AutoAugment
其他经典的tricks
Warmup
from torch.optim.lr_scheduler import_LRScheduler
classGradualWarmupScheduler(_LRScheduler):
"""
Args:
optimizer (Optimizer): Wrapped optimizer.
multiplier: target learning rate = base lr * multiplier
total_epoch: target learning rate is reached at total_epoch, gradually
after_scheduler: after target_epoch, use this scheduler(eg. ReduceLROnPlateau)
"""
def __init__(self, optimizer, multiplier, total_epoch, after_scheduler=None):
self.multiplier = multiplier
if self.multiplier <= 1.:
raiseValueError('multiplier should be greater than 1.')
self.total_epoch = total_epoch
self.after_scheduler = after_scheduler
self.finished = False
super().__init__(optimizer)
def get_lr(self):
if self.last_epoch > self.total_epoch:
if self.after_scheduler:
ifnot self.finished:
self.after_scheduler.base_lrs = [base_lr * self.multiplier for base_lr in self.base_lrs]
self.finished = True
return self.after_scheduler.get_lr()
return[base_lr * self.multiplier for base_lr in self.base_lrs]
return[base_lr * ((self.multiplier - 1.) * self.last_epoch / self.total_epoch + 1.) for base_lr in self.base_lrs]
def step(self, epoch=None):
if self.finished and self.after_scheduler:
return self.after_scheduler.step(epoch)
else:
return super(GradualWarmupScheduler, self).step(epoch)
Linear scaling learning rate
Label-smoothing
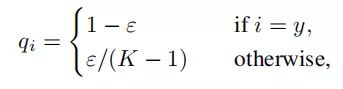
import torch
import torch.nn as nn
class LSR(nn.Module):
def __init__(self, e=0.1, reduction='mean'):
super().__init__()
self.log_softmax = nn.LogSoftmax(dim=1)
self.e = e
self.reduction = reduction
def _one_hot(self, labels, classes, value=1):
"""
Convert labels to one hot vectors
Args:
labels: torch tensor in format [label1, label2, label3, ...]
classes: int, number of classes
value: label value in one hot vector, default to 1
Returns:
return one hot format labels in shape [batchsize, classes]
"""
one_hot = torch.zeros(labels.size(0), classes)
#labels and value_added size must match
labels = labels.view(labels.size(0), -1)
value_added = torch.Tensor(labels.size(0), 1).fill_(value)
value_added = value_added.to(labels.device)
one_hot = one_hot.to(labels.device)
one_hot.scatter_add_(1, labels, value_added)
return one_hot
def _smooth_label(self, target, length, smooth_factor):
"""convert targets to one-hot format, and smooth
them.
Args:
target: target in form with [label1, label2, label_batchsize]
length: length of one-hot format(number of classes)
smooth_factor: smooth factor for label smooth
Returns:
smoothed labels in one hot format
"""
one_hot = self._one_hot(target, length, value=1- smooth_factor)
one_hot += smooth_factor / length
return one_hot.to(target.device)
Random image cropping and patching
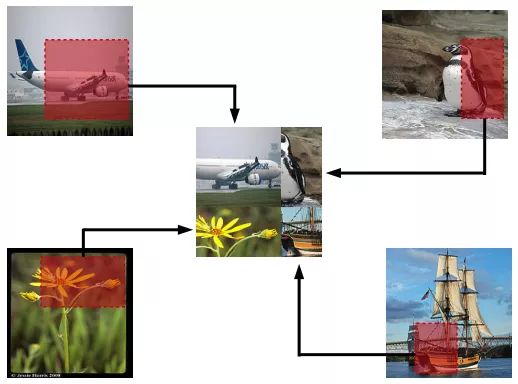
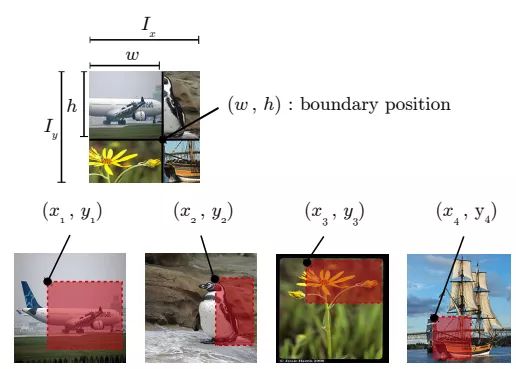
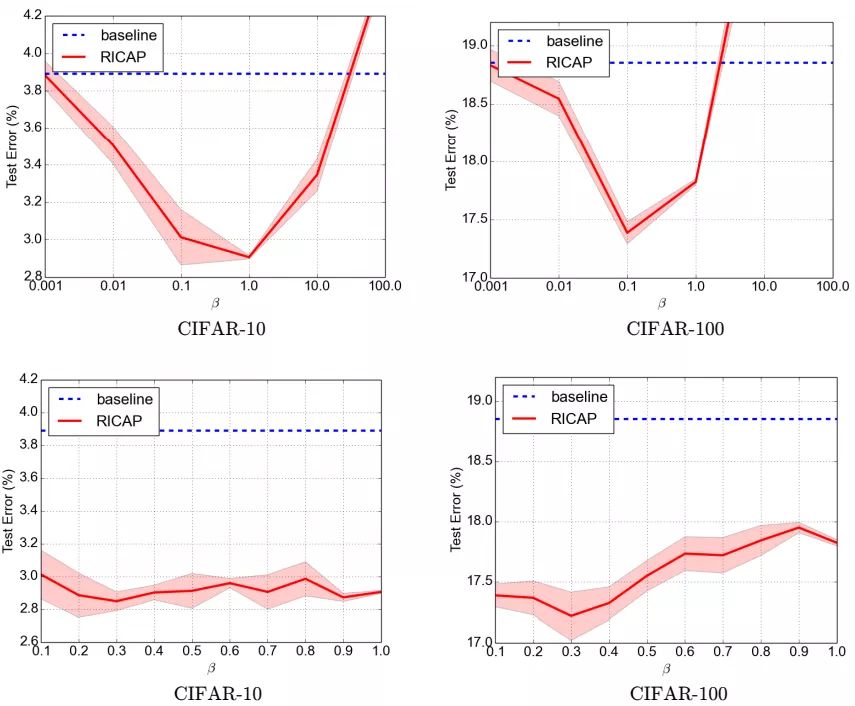
beta = 0.3# hyperparameter
for(images, targets) in train_loader:
# get the image size
I_x, I_y = images.size()[2:]
# draw a boundry position (w, h)
w = int(np.round(I_x * np.random.beta(beta, beta)))
h = int(np.round(I_y * np.random.beta(beta, beta)))
w_ = [w, I_x - w, w, I_x - w]
h_ = [h, h, I_y - h, I_y - h]
# select and crop four images
cropped_images = {}
c_ = {}
W_ = {}
for k in range(4):
index = torch.randperm(images.size(0))
x_k = np.random.randint(0, I_x - w_[k] + 1)
y_k = np.random.randint(0, I_y - h_[k] + 1)
cropped_images[k] = images[index][:, :, x_k:x_k + w_[k], y_k:y_k + h_[k]]
c_[k] = target[index].cuda()
W_[k] = w_[k] * h_[k] / (I_x * I_y)
# patch cropped images
patched_images = torch.cat(
(torch.cat((cropped_images[0], cropped_images[1]), 2),
torch.cat((cropped_images[2], cropped_images[3]), 2)),
3)
#patched_images = patched_images.cuda()
# get output
output = model(patched_images)
# calculate loss and accuracy
loss = sum([W_[k] * criterion(output, c_[k]) for k in range(4)])
acc = sum([W_[k] * accuracy(output, c_[k])[0] for k in range(4)])
Knowledge Distillation
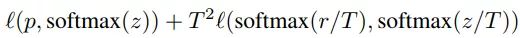
Cutout
import torch
import numpy as np
classCutout(object):
"""Randomly mask out one or more patches from an image.
Args:
n_holes (int): Number of patches to cut out of each image.
length (int): The length (in pixels) of each square patch.
"""
def __init__(self, n_holes, length):
self.n_holes = n_holes
self.length = length
def __call__(self, img):
"""
Args:
img (Tensor): Tensor image of size (C, H, W).
Returns:
Tensor: Image with n_holes of dimension length x length cut out of it.
"""
h = img.size(1)
w = img.size(2)
mask = np.ones((h, w), np.float32)
for n in range(self.n_holes):
y = np.random.randint(h)
x = np.random.randint(w)
y1 = np.clip(y - self.length // 2, 0, h)
y2 = np.clip(y + self.length // 2, 0, h)
x1 = np.clip(x - self.length // 2, 0, w)
x2 = np.clip(x + self.length // 2, 0, w)
mask[y1: y2, x1: x2] = 0.
mask = torch.from_numpy(mask)
mask = mask.expand_as(img)
img = img * mask
return img

Random erasing


from __future__ import absolute_import
from torchvision.transforms import*
from PIL importImage
import random
import math
import numpy as np
import torch
classRandomErasing(object):
'''
probability: The probability that the operation will be performed.
sl: min erasing area
sh: max erasing area
r1: min aspect ratio
mean: erasing value
'''
def __init__(self, probability = 0.5, sl = 0.02, sh = 0.4, r1 = 0.3, mean=[0.4914, 0.4822, 0.4465]):
self.probability = probability
self.mean = mean
self.sl = sl
self.sh = sh
self.r1 = r1
def __call__(self, img):
if random.uniform(0, 1) > self.probability:
return img
for attempt in range(100):
area = img.size()[1] * img.size()[2]
target_area = random.uniform(self.sl, self.sh) * area
aspect_ratio = random.uniform(self.r1, 1/self.r1)
h = int(round(math.sqrt(target_area * aspect_ratio)))
w = int(round(math.sqrt(target_area / aspect_ratio)))
if w < img.size()[2] and h < img.size()[1]:
x1 = random.randint(0, img.size()[1] - h)
y1 = random.randint(0, img.size()[2] - w)
if img.size()[0] == 3:
img[0, x1:x1+h, y1:y1+w] = self.mean[0]
img[1, x1:x1+h, y1:y1+w] = self.mean[1]
img[2, x1:x1+h, y1:y1+w] = self.mean[2]
else:
img[0, x1:x1+h, y1:y1+w] = self.mean[0]
return img
return img
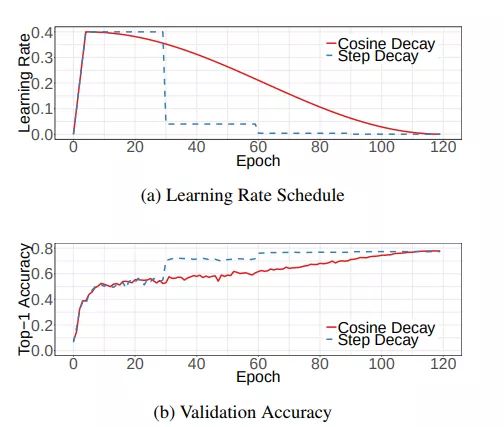
Cosine learning rate decay
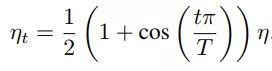
# Assuming optimizer uses lr = 0.05 for all groups
# lr = 0.05 if epoch < 30
# lr = 0.005 if 30 <= epoch < 60
# lr = 0.0005 if 60 <= epoch < 90
from torch.optim.lr_scheduler importStepLR
scheduler = StepLR(optimizer, step_size=30, gamma=0.1)
for epoch in range(100):
scheduler.step()
train(...)
validate(...)
Mixup training
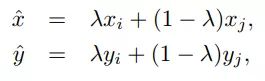
for(images, labels) in train_loader:
l = np.random.beta(mixup_alpha, mixup_alpha)
index = torch.randperm(images.size(0))
images_a, images_b = images, images[index]
labels_a, labels_b = labels, labels[index]
mixed_images = l * images_a + (1- l) * images_b
outputs = model(mixed_images)
loss = l * criterion(outputs, labels_a) + (1- l) * criterion(outputs, labels_b)
acc = l * accuracy(outputs, labels_a)[0] + (1- l) * accuracy(outputs, labels_b)[0]
AdaBound
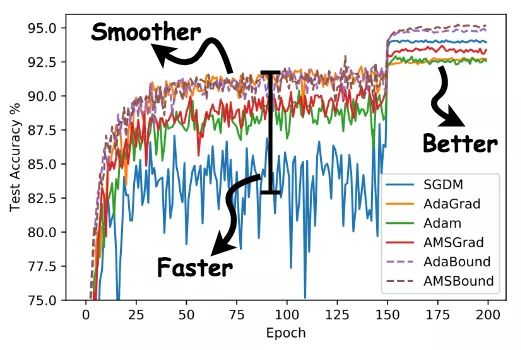
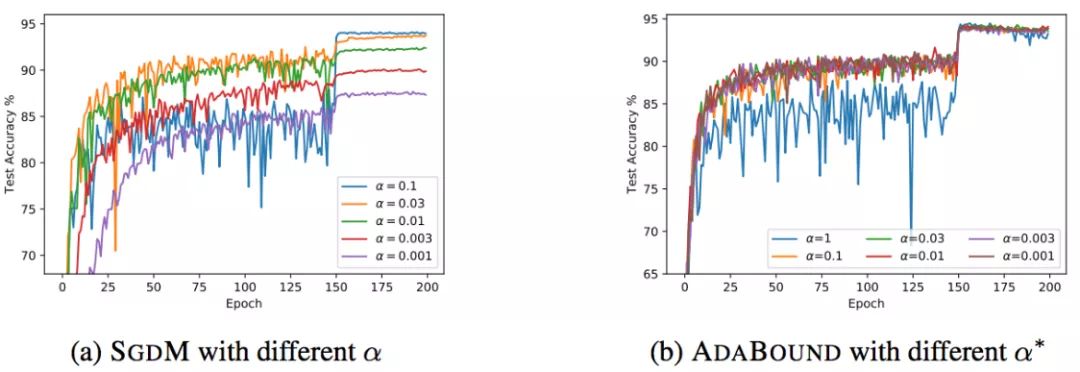
pip install adabound
optimizer = adabound.AdaBound(model.parameters(), lr=1e-3, final_lr=0.1)
AutoAugment
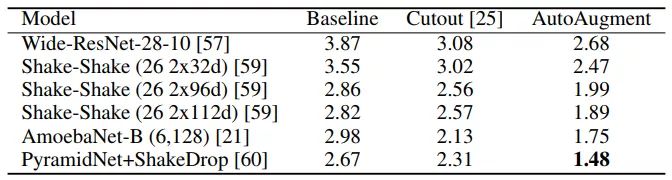
其他经典的tricks
常用的正则化方法为
Dropout
L1/L2正则
Batch Normalization
Early stopping
Random cropping
Mirroring
Rotation
Color shifting
PCA color augmentation
...
其他
Xavier init[12]
...
参考资料
[1] Deep Residual Learning for Image
Recognition(https://arxiv.org/pdf/1512.03385.pdf
[2] http://cs231n.github.io/neural-networks-2/
[3] Accurate, Large Minibatch SGD:
Training ImageNet in 1 Hour
https://arxiv.org/pdf/1706.02677v2.pdf
[4] Rethinking the Inception Architecture for Computer Vision
https://arxiv.org/pdf/1512.00567v3.pdf
[5]Bag of Tricks for Image Classification with Convolutional Neural Networks
https://arxiv.org/pdf/1812.01187.pdf
[6] Adaptive Gradient Methods with Dynamic Bound of Learning Rate
https://www.luolc.com/publications/adabound/
[7] Random erasing
https://arxiv.org/pdf/1708.04896v2.pdf
[8] RICAP https://arxiv.org/pdf/1811.09030.pdf
[9] Distilling the Knowledge in a Neural Network
https://arxiv.org/pdf/1503.02531.pdf
[10] Improved Regularization of Convolutional Neural Networks with Cutout
https://arxiv.org/pdf/1708.04552.pdf
[11] Mixup: BEYOND EMPIRICAL RISK MINIMIZATION
https://arxiv.org/pdf/1710.09412.pdf
[12] AutoAugment: Learning Augmentation Policies from Data
https://arxiv.org/pdf/1805.09501.pdf
[13] Understanding the difficulty of training deep feedforward neural networks
http://proceedings.mlr.press/v9/glorot10a/glorot10a.pdf


免责申明:本站所有内容均来自网络,我们对文中观点保持中立,对所包含内容的准确性,可靠性或者完整性不提供任何明示或暗示的保证,请仅作参考。若有侵权,请联系删除。
以上是关于学习教程深度神经网络模型训练中的 tricks(原理与代码汇总)的主要内容,如果未能解决你的问题,请参考以下文章