数据恢复:NIST的神经网络模型能在密集的图像中找出小型目标对象
Posted 计量测控
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据恢复:NIST的神经网络模型能在密集的图像中找出小型目标对象相关的知识,希望对你有一定的参考价值。
来源:NIST新闻
为了自动从科学论文中获取重要数据,美国国家标准与技术研究院(NIST)的计算机科学家们开发出一种方法,可以准确地检测图像数据中包含的密集、低质量绘图的小型几何体,比如三角形。NIST的模型采用神经网络方法来检测图案,在现代生活中还有许多可能的应用。
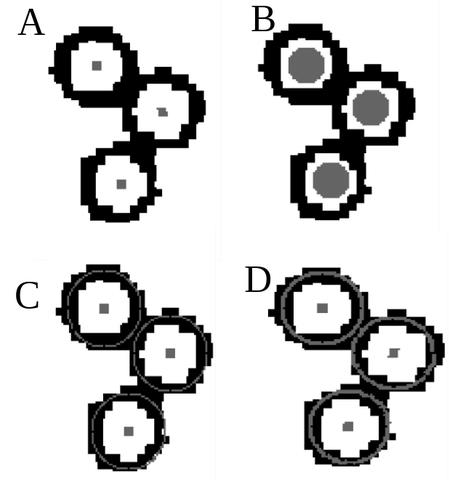
NIST的研究人员发现,使用特定的掩模(A和C)来标记数据,有助于训练神经网络模型在密集、低质量绘图中检测出小型几何体。研究项目的目的是恢复期刊文章中丢失的数据,但这种类型的目标检测也有其它应用,如图像分析、自动驾驶汽车、监控和机器检查。(图片来源:NIST)
NIST的神经网络模型在一组确定的测试图像中捕获到了97%的目标,并且目标中心的定位区域与手动选择位置只相差几个像素。
“这个研究项目的目的是恢复期刊文章中丢失的数据,”NIST的计算机科学家Adele Peskin解释道。“但是密集的小型目标检测的研究还有很多其它的应用。目标检测被广泛应用于图像分析、自动驾驶汽车、机器检查等领域,对于这些密集的小型目标对象,尤其难以定位和分离。”
研究人员所用的数据来自NIST热力学研究中心(TRC)的一个金属特性数据库,这里面的期刊文章最早可追溯到1900年左右。通常,这些文章里的结果仅以图形格式呈现,有时是手工绘制的,而且由于扫描或复印会更加不清楚。研究人员希望提取数据点的位置,以恢复最初的原始数据,以便进行进一步分析。在此之前,这些数据都是人工提取的。
这些图像展示了具有各种不同标记的数据点,主要是圆形、三角形和正方形,有填充的也有开放的,大小和清晰度都不同。这样的几何标记常被用来标记科学图表中的数据。在训练神经网络之前,人们用图形编辑软件将文字、数字和其它符号从图形子集中手动剔除,因为这些符号可能会被错误地视为数据点。
要想准确地检测和定位数据标记很困难,原因主要有:标记的清晰度和形状不一致;它们可能是开放的或填充的,而且有时是模糊的或扭曲的。例如,有些圆看起来非常圆,而另一些则没有足够的像素来完全定义它们的形状。此外,许多图像包含非常密集、重叠的圆形、正方形和三角形斑块。
研究人员试图创建一种网络模型,至少能像人工检测那样准确地识别出绘图点——图上实际位置的5个像素范围之内,图的每边大小为数千个像素。
正如在新发表的期刊论文中所描述的,NIST的研究人员采用了一种最初由德国研究人员开发用于分析生物医学图像的网络架构,称为U-Net。首先压缩图像的尺寸,减少空间信息,然后添加特征和上下文信息层,构建精确、高分辨率的结果。
为帮助训练网络分类标记形状和定位它们的中心,研究人员试验了四种用掩模标记训练数据的方法,每个几何体使用不同大小的中心标记和轮廓。
研究人员发现,在掩模上添加更多的信息,如更厚的轮廓,虽然提高了分类物体形状的准确性,但降低了在图中精确定位的准确性。最后,研究人员结合几种模型的优点,实现了最佳分类和最小定位误差。更改掩模被证明是提高网络性能的最佳方法,比其它方法(如在网络末端进行小的更改)更有效。
网络的最佳性能,即定位目标中心的准确率可达97%,仅适用于最初由非常清晰的圆、三角形和正方形表示出绘图点的图像子集。这种性能足以让NIST热力学研究中心(TRC)使用这个神经网络恢复来自更近期期刊论文中的数据。
尽管NIST的研究人员目前没有后续研究的计划,但神经网络模型“绝对”可以应用于其它图像分析问题,Peskin说。
如有科技文献外文检索、翻译等服务需求,欢迎来函来电!
联系人:李莉萍
微信:liliping304
【小编叨叨】号外号外!!计量测控推出全新版块——海外聚焦,我们定期翻译整理计量检测相关的海外科技动态、文献资料,方便读者进行参考交流!如有科技文献外文检索、翻译等服务需求,欢迎来函来电!
以上是关于数据恢复:NIST的神经网络模型能在密集的图像中找出小型目标对象的主要内容,如果未能解决你的问题,请参考以下文章
Keras 密集网络过拟合
设计数据密集型应用 第二章:数据模型与查询语言
你能在 TensorFlow 中组合两个神经网络吗?
基于5G密集网络模型的资源分配和负载均衡算法matlab仿真
Mnist手写数字识别 Tensorflow
用ViT替代卷积网络做密集预测,英特尔实验室提出DPT架构,在线Demo可用