设计数据密集型应用 第二章:数据模型与查询语言
Posted SuPhoebe
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了设计数据密集型应用 第二章:数据模型与查询语言相关的知识,希望对你有一定的参考价值。
第二章:数据模型与查询语言
语言的边界就是思想的边界。
—— 路德维奇·维特根斯坦,《逻辑哲学》(1922)
文章目录
数据模型可能是软件开发中最重要的部分了,因为它们的影响如此深远:不仅仅影响着软件的编写方式,而且影响着我们的 解决问题的思路。
多数应用使用层层叠加的数据模型构建。对于每层数据模型的关键问题是:它是如何用更低一层数据模型来表示的?例如:
- 作为一名应用开发人员,你观察现实世界(里面有人员,组织,货物,行为,资金流向,传感器等),并采用对象或数据结构,以及操控那些数据结构的API来进行建模。那些结构通常是特定于应用程序的。
- 当要存储那些数据结构时,你可以利用通用数据模型来表示它们,如JSON或XML文档,关系数据库中的表、或图模型。
- 数据库软件的工程师选定如何以内存、磁盘或网络上的字节来表示JSON/XML/关系/图数据。这类表示形式使数据有可能以各种方式来查询,搜索,操纵和处理。
- 在更低的层次上,硬件工程师已经想出了使用电流,光脉冲,磁场或者其他东西来表示字节的方法。
一个复杂的应用程序可能会有更多的中间层次,比如基于底层API的API,不过基本思想仍然是一样的:每个层都通过提供一个明确的数据模型来隐藏更低层次中的复杂性。这些抽象的设计允许不同的人群有效地协作(例如数据库厂商的工程师和使用数据库的应用程序开发人员)。
数据模型种类繁多,每个数据模型都自带如何正确使用他们的设想。有些用法很容易,有些则不支持如此;有些操作运行很快,有些则表现很差;有些数据转换非常自然,有些则很麻烦。
掌握一个数据模型需要花费很多精力(想想关系数据建模有多少本书)。即便只使用一个数据模型,不用操心其内部工作机制,构建软件也是非常困难的。然而,因为数据模型对上层软件的功能(能做什么,不能做什么)有着至深的影响,所以选择一个适合的数据模型是非常重要的。
在本章中,我们将研究一系列用于数据存储和查询的通用数据模型(前面列表中的第2点)。特别地,我们将比较关系模型,文档模型和少量基于图形的数据模型。我们还将查看各种查询语言并比较它们的用例。在第3章中,我们将讨论存储引擎是如何工作的。也就是说,这些数据模型实际上是如何实现的(列表中的第3点)。
关系模型与文档模型
现在最著名的数据模型可能是SQL。它基于Edgar Codd在1970年提出的关系模型【1】:数据被组织成关系(SQL中称作表),其中每个关系是元组(SQL中称作行)的无序集合。
关系模型曾是一个理论性的提议,当时很多人都怀疑是否能够有效实现它。然而到了20世纪80年代中期,关系数据库管理系统(RDBMSes)和SQL已成为大多数人们存储和查询某些常规结构的数据的首选工具。关系数据库已经持续称霸了大约25~30年——这对计算机史来说是极其漫长的时间。
关系数据库起源于商业数据处理,在20世纪60年代和70年代用大型计算机来执行。从今天的角度来看,那些用例显得很平常:典型的事务处理(将销售或银行交易,航空公司预订,库存管理信息记录在库)和批处理(客户发票,工资单,报告)。
当时的其他数据库迫使应用程序开发人员必须考虑数据库内部的数据表示形式。关系模型则致力于将上述实现细节隐藏在更简洁的接口之后。
多年来,在数据存储和查询方面存在着许多相互竞争的方法。在20世纪70年代和80年代初,网络模型和分层模型曾是主要的选择,但关系模型随后占据了主导地位。对象数据库在20世纪80年代末和90年代初来了又去。XML数据库在二十一世纪初出现,但只有小众采用过。关系模型的每个竞争者都在其时代产生了大量的炒作,但从来没有持续【2】。
随着电脑越来越强大和互联,它们开始用于日益多样化的目的。关系数据库非常成功地被推广到业务数据处理的原始范围之外更为广泛的用例上。你今天在网上看到的大部分内容依旧是由关系数据库来提供支持,无论是在线发布,讨论,社交网络,电子商务,游戏,软件即服务生产力应用程序等等内容。
NoSQL的诞生
现在 - 2010年代,NoSQL开始了最新一轮尝试,试图推翻关系模型的统治地位。“NoSQL”这个名字让人遗憾,因为实际上它并没有涉及到任何特定的技术。最初它只是作为一个醒目的Twitter标签,用在2009年一个关于分布式,非关系数据库上的开源聚会上。无论如何,这个术语触动了某些神经,并迅速在网络创业社区内外传播开来。好些有趣的数据库系统现在都与*#NoSQL#*标签相关联,并且NoSQL被追溯性地重新解释为不仅是SQL(Not Only SQL) 【4】。
采用NoSQL数据库的背后有几个驱动因素,其中包括:
- 需要比关系数据库更好的可伸缩性,包括非常大的数据集或非常高的写入吞吐量
- 相比商业数据库产品,免费和开源软件更受偏爱。
- 关系模型不能很好地支持一些特殊的查询操作
- 受挫于关系模型的限制性,渴望一种更具多动态性与表现力的数据模型【5】
不同的应用程序有不同的需求,一个用例的最佳技术选择可能不同于另一个用例的最佳技术选择。因此,在可预见的未来,关系数据库似乎可能会继续与各种非关系数据库一起使用 - 这种想法有时也被称为混合持久化(polyglot persistence)。
对象关系不匹配
目前大多数应用程序开发都使用面向对象的编程语言来开发,这导致了对SQL数据模型的普遍批评:如果数据存储在关系表中,那么需要一个笨拙的转换层,处于应用程序代码中的对象和表,行,列的数据库模型之间。模型之间的不连贯有时被称为阻抗不匹配(impedance mismatch)1。
像ActiveRecord和Hibernate这样的 对象关系映射(ORM object-relational mapping) 框架可以减少这个转换层所需的样板代码的数量,但是它们不能完全隐藏这两个模型之间的差异。
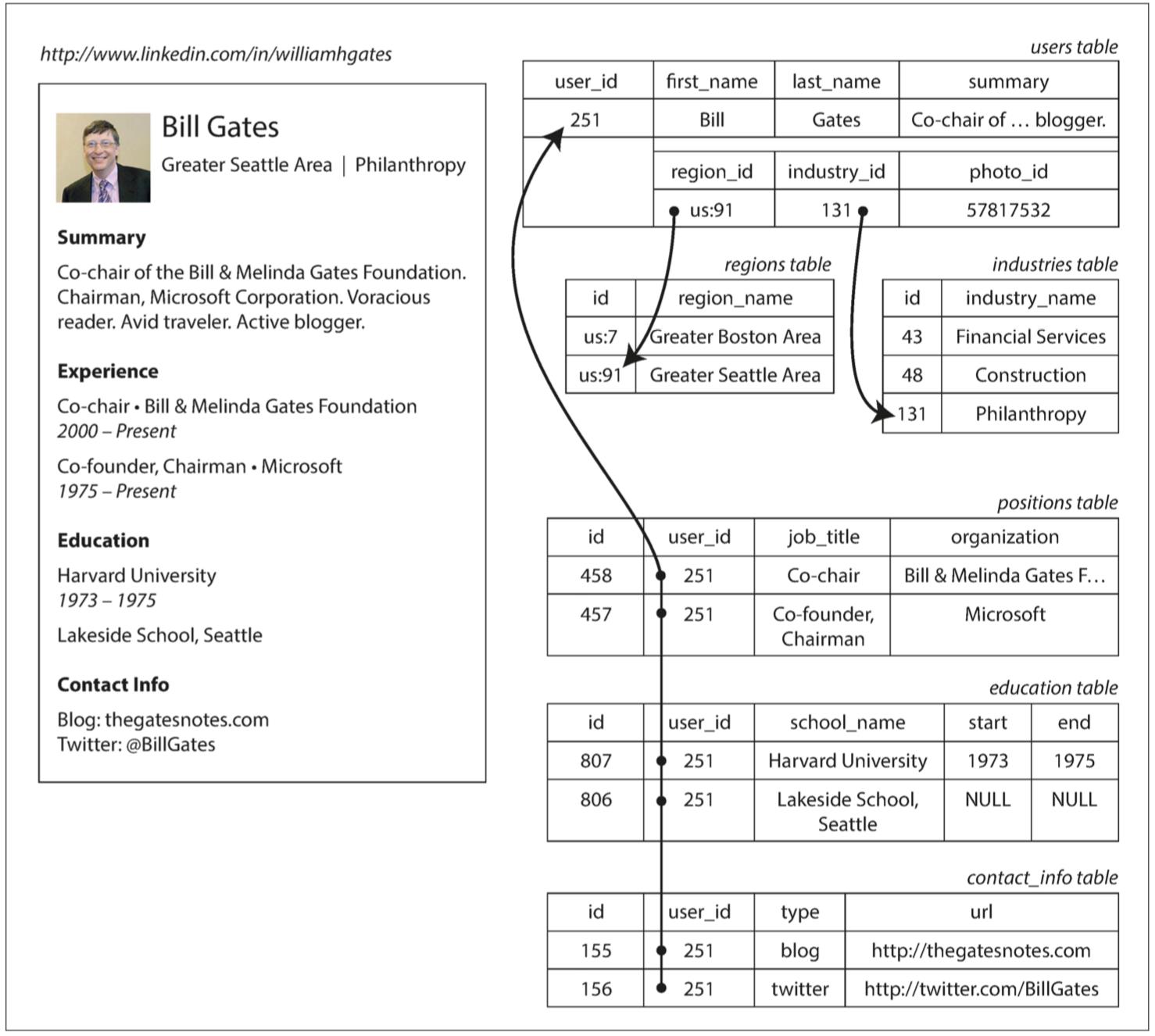
图2-1 使用关系型模式来表示领英简介
例如,图2-1展示了如何在关系模式中表示简历(一个LinkedIn简介)。整个简介可以通过一个唯一的标识符user_id来标识。像first_name和last_name这样的字段每个用户只出现一次,所以可以在User表上将其建模为列。但是,大多数人在职业生涯中拥有多于一份的工作,人们可能有不同样的教育阶段和任意数量的联系信息。从用户到这些项目之间存在一对多的关系,可以用多种方式来表示:
{kind=link}
- 传统SQL模型(SQL:1999之前)中,最常见的规范化表示形式是将职位,教育和联系信息放在单独的表中,对User表提供外键引用,如图2-1所示。
- 后续的SQL标准增加了对结构化数据类型和XML数据的支持;这允许将多值数据存储在单行内,并支持在这些文档内查询和索引。这些功能在Oracle,IBM DB2,MS SQL Server和PostgreSQL中都有不同程度的支持【6,7】。JSON数据类型也得到多个数据库的支持,包括IBM DB2,mysql和PostgreSQL 【8】。
- 第三种选择是将职业,教育和联系信息编码为JSON或XML文档,将其存储在数据库的文本列中,并让应用程序解析其结构和内容。这种配置下,通常不能使用数据库来查询该编码列中的值。
对于一个像简历这样自包含文档的数据结构而言,JSON表示是非常合适的:参见例2-1。JSON比XML更简单。面向文档的数据库(如MongoDB 【9】,RethinkDB 【10】,CouchDB 【11】和Espresso【12】)支持这种数据模型。
例2-1. 用JSON文档表示一个LinkedIn简介
{
"user_id": 251,
"first_name": "Bill",
"last_name": "Gates",
"summary": "Co-chair of the Bill & Melinda Gates... Active blogger.",
"region_id": "us:91",
"industry_id": 131,
"photo_url": "/p/7/000/253/05b/308dd6e.jpg",
"positions": [
{
"job_title": "Co-chair",
"organization": "Bill & Melinda Gates Foundation"
},
{
"job_title": "Co-founder, Chairman",
"organization": "Microsoft"
}
],
"education": [
{
"school_name": "Harvard University",
"start": 1973,
"end": 1975
},
{
"school_name": "Lakeside School, Seattle",
"start": null,
"end": null
}
],
"contact_info": {
"blog": "http://thegatesnotes.com",
"twitter": "http://twitter.com/BillGates"
}
}
有一些开发人员认为JSON模型减少了应用程序代码和存储层之间的阻抗不匹配。不过,正如我们将在第4章中看到的那样,JSON作为数据编码格式也存在问题。缺乏一个模式往往被认为是一个优势;我们将在“文档模型中的模式灵活性”中讨论这个问题。
JSON表示比图2-1中的多表模式具有更好的局部性(locality)。如果在前面的关系型示例中获取简介,那需要执行多个查询(通过user_id查询每个表),或者在User表与其下属表之间混乱地执行多路连接。而在JSON表示中,所有相关信息都在同一个地方,一个查询就足够了。
从用户简介文件到用户职位,教育历史和联系信息,这种一对多关系隐含了数据中的一个树状结构,而JSON表示使得这个树状结构变得明确(见图2-2)。
{kind=link}
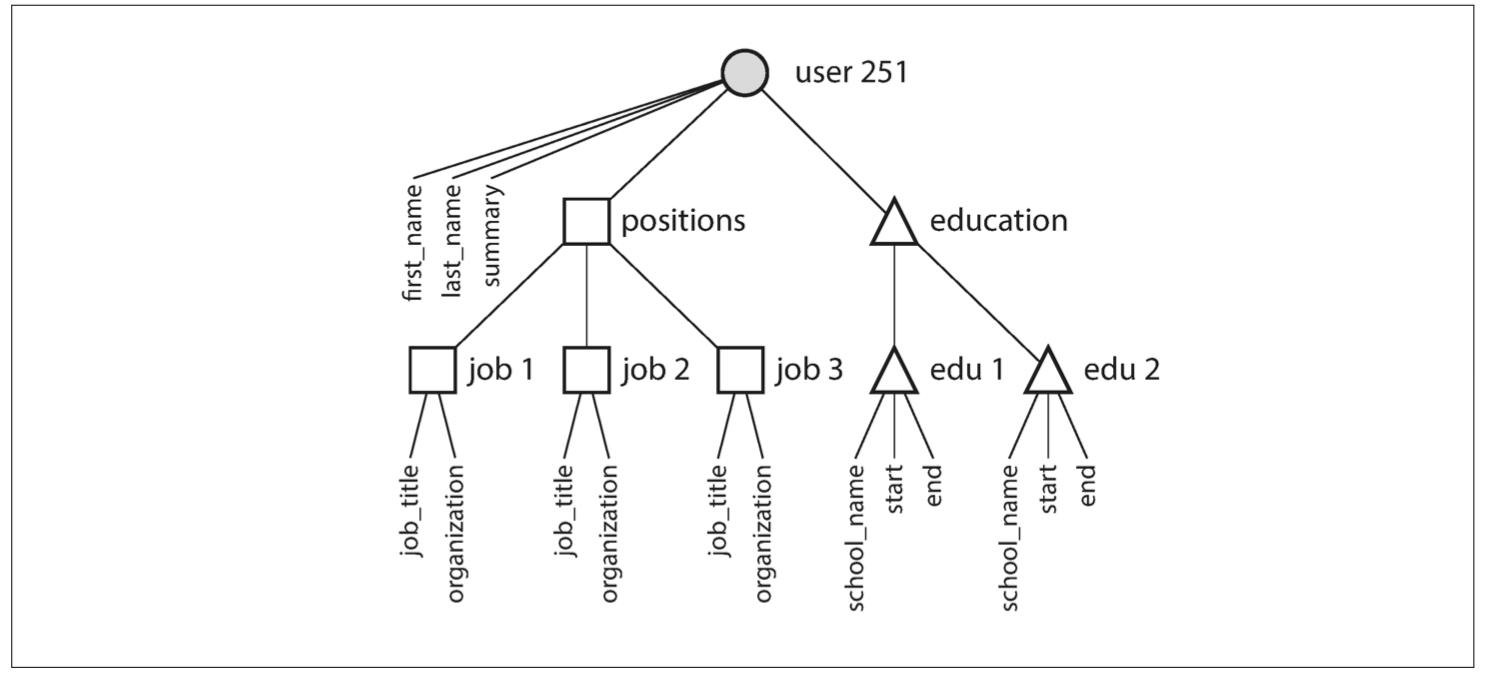
图2-2 一对多关系构建了一个树结构
译者注:这里的结论在实际工作中需要程序员的仔细考量;既可以选择用SQLDB和NoSQLDB结合的方式,也可以选择将JSON文件展开,并且存入SQLDB的每一列(如果JSON文件的栏目并不是很多的话)。灵活地利用各种数据库,应对各种不一样的场景是非常重要的。
多对一和多对多的关系
在上一节的例2-1中,region_id和industry_id是以ID,而不是纯字符串“Greater Seattle Area”和“Philanthropy”的形式给出的。为什么?
如果用户界面用一个自由文本字段来输入区域和行业,那么将他们存储为纯文本字符串是合理的。另一方式是给出地理区域和行业的标准化的列表,并让用户从下拉列表或自动填充器中进行选择,其优势如下:
- 各个简介之间样式和拼写统一
- 避免歧义(例如,如果有几个同名的城市)
- 易于更新——名称只存储在一个地方,如果需要更改(例如,由于政治事件而改变城市名称),很容易进行全面更新。
- 本地化支持——当网站翻译成其他语言时,标准化的列表可以被本地化,使得地区和行业可以使用用户的语言来显示
- 更好的搜索——例如,搜索华盛顿州的慈善家就会匹配这份简介,因为地区列表可以编码记录西雅图在华盛顿这一事实(从“Greater Seattle Area”这个字符串中看不出来)
存储ID还是文本字符串,这是个 副本(duplication) 问题。当使用ID时,对人类有意义的信息(比如单词:Philanthropy)只存储在一处,所有引用它的地方使用ID(ID只在数据库中有意义)。当直接存储文本时,对人类有意义的信息会复制在每处使用记录中。
使用ID的好处是,ID对人类没有任何意义,因而永远不需要改变:ID可以保持不变,即使它标识的信息发生变化。任何对人类有意义的东西都可能需要在将来某个时候改变——如果这些信息被复制,所有的冗余副本都需要更新。这会导致写入开销,也存在不一致的风险(一些副本被更新了,还有些副本没有被更新)。去除此类重复是数据库 规范化(normalization) 的关键思想。2
数据库管理员和开发人员喜欢争论规范化和非规范化,让我们暂时保留判断吧。在本书的第三部分,我们将回到这个话题,探讨系统的方法用以处理缓存,非规范化和衍生数据。
不幸的是,对这些数据进行规范化需要多对一的关系(许多人生活在一个特定的地区,许多人在一个特定的行业工作),这与文档模型不太吻合。在关系数据库中,通过ID来引用其他表中的行是正常的,因为连接很容易。在文档数据库中,一对多树结构没有必要用连接,对连接的支持通常很弱3。
如果数据库本身不支持连接,则必须在应用程序代码中通过对数据库进行多个查询来模拟连接。(在这种情况中,地区和行业的列表可能很小,改动很少,应用程序可以简单地将其保存在内存中。不过,执行连接的工作从数据库被转移到应用程序代码上。
此外,即便应用程序的最初版本适合无连接的文档模型,随着功能添加到应用程序中,数据会变得更加互联。例如,考虑一下对简历例子进行的一些修改:
组织和学校作为实体
在前面的描述中,organization(用户工作的公司)和school_name(他们学习的地方)只是字符串。也许他们应该是对实体的引用呢?然后,每个组织,学校或大学都可以拥有自己的网页(标识,新闻提要等)。每个简历可以链接到它所提到的组织和学校,并且包括他们的图标和其他信息(参见图2-3,来自LinkedIn的一个例子)。
{kind=link}
推荐
假设你想添加一个新的功能:一个用户可以为另一个用户写一个推荐。在用户的简历上显示推荐,并附上推荐用户的姓名和照片。如果推荐人更新他们的照片,那他们写的任何建议都需要显示新的照片。因此,推荐应该拥有作者个人简介的引用。

图2-3 公司名不仅是字符串,还是一个指向公司实体的链接(LinkedIn截图)
图2-4阐明了这些新功能需要如何使用多对多关系。每个虚线矩形内的数据可以分组成一个文档,但是对单位,学校和其他用户的引用需要表示成引用,并且在查询时需要连接。
{kind=link}
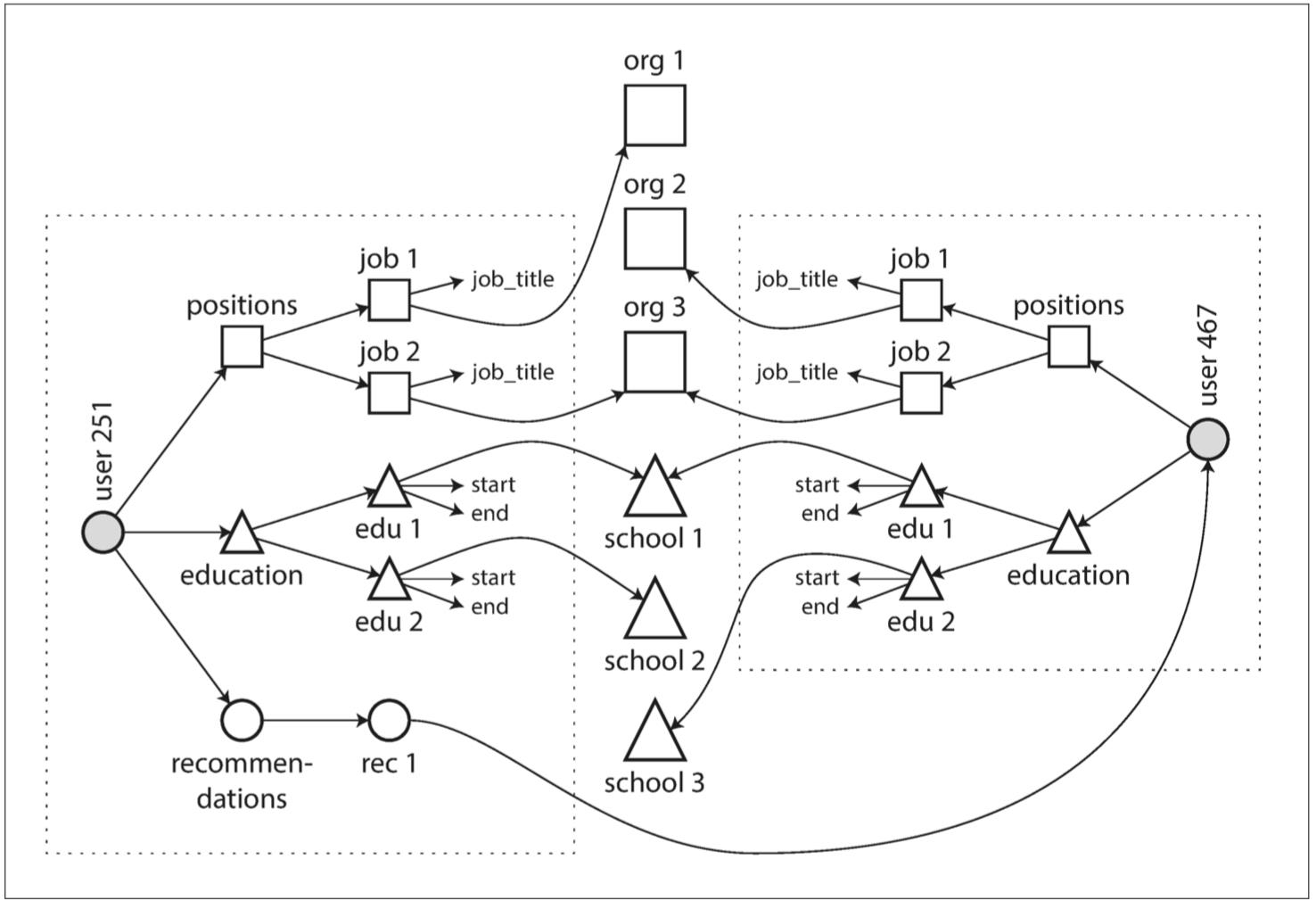
图2-4 使用多对多关系扩展简历
文档数据库是否在重蹈覆辙?
文档数据库(document database)和键值数据库(key-value database)的区别
相同点: 都是key-value结构
不同点: 在键值数据库中,我们只能通过key查找到整个value,数据库并不知道value里面存的内容到底是什么,而是通过应用程序将value里面的东西进行翻译解析;在文档数据库中,我们不仅可以通过key查找value,也可以通过document中对应的key找到具体内容,value对数据库来说是透明的。
在多对多的关系和连接已常规用在关系数据库时,文档数据库和NoSQL重启了辩论:如何最好地在数据库中表示多对多关系。那场辩论可比NoSQL古老得多,事实上,最早可以追溯到计算机化数据库系统。
20世纪70年代最受欢迎的业务数据处理数据库是IBM的信息管理系统(IMS),最初是为了阿波罗太空计划的库存管理而开发的,并于1968年有了首次商业发布【13】。目前它仍在使用和维护,运行在IBM大型机的OS/390上【14】。
IMS的设计中使用了一个相当简单的数据模型,称为层次模型(hierarchical model),它与文档数据库使用的JSON模型有一些惊人的相似之处【2】。它将所有数据表示为嵌套在记录中的记录树,这很像图2-2的JSON结构。
同文档数据库一样,IMS能良好处理一对多的关系,但是很难应对多对多的关系,并且不支持连接。开发人员必须决定是否复制(非规范化)数据或手动解决从一个记录到另一个记录的引用。这些二十世纪六七十年代的问题与现在开发人员遇到的文档数据库问题非常相似【15】。
那时人们提出了各种不同的解决方案来解决层次模型的局限性。其中最突出的两个是关系模型(relational model)(它变成了SQL,统治了世界)和网络模型(network model)(最初很受关注,但最终变得冷门)。这两个阵营之间的“大辩论”在70年代持续了很久时间【2】。
那两个模式解决的问题与当前的问题相关,因此值得简要回顾一下那场辩论。
网络模型
网络模型由一个称为数据系统语言会议(CODASYL)的委员会进行了标准化,并被数个不同的数据库商实现;它也被称为CODASYL模型【16】。
CODASYL模型是层次模型的推广。在层次模型的树结构中,每条记录只有一个父节点;在网络模式中,每条记录可能有多个父节点。例如,“Greater Seattle Area”地区可能是一条记录,每个居住在该地区的用户都可以与之相关联。这允许对多对一和多对多的关系进行建模。
网络模型中记录之间的链接不是外键,而更像编程语言中的指针(同时仍然存储在磁盘上)。访问记录的唯一方法是跟随从根记录起沿这些链路所形成的路径。这被称为访问路径(access path)。
最简单的情况下,访问路径类似遍历链表:从列表头开始,每次查看一条记录,直到找到所需的记录。但在多对多关系的情况中,数条不同的路径可以到达相同的记录,网络模型的程序员必须跟踪这些不同的访问路径。
CODASYL中的查询是通过利用遍历记录列和跟随访问路径表在数据库中移动游标来执行的。如果记录有多个父结点(即多个来自其他记录的传入指针),则应用程序代码必须跟踪所有的各种关系。甚至CODASYL委员会成员也承认,这就像在n维数据空间中进行导航【17】。
尽管手动选择访问路径够能最有效地利用20世纪70年代非常有限的硬件功能(如磁带驱动器,其搜索速度非常慢),但这使得查询和更新数据库的代码变得复杂不灵活。无论是分层还是网络模型,如果你没有所需数据的路径,就会陷入困境。你可以改变访问路径,但是必须浏览大量手写数据库查询代码,并重写来处理新的访问路径。更改应用程序的数据模型是很难的。
关系模型
相比之下,关系模型做的就是将所有的数据放在光天化日之下:一个 关系(表) 只是一个 元组(行) 的集合,仅此而已。如果你想读取数据,它没有迷宫似的嵌套结构,也没有复杂的访问路径。你可以选中符合任意条件的行,读取表中的任何或所有行。你可以通过指定某些列作为匹配关键字来读取特定行。你可以在任何表中插入一个新的行,而不必担心与其他表的外键关系4。
在关系数据库中,查询优化器自动决定查询的哪些部分以哪个顺序执行,以及使用哪些索引。这些选择实际上是“访问路径”,但最大的区别在于它们是由查询优化器自动生成的,而不是由程序员生成,所以我们很少需要考虑它们。
如果想按新的方式查询数据,你可以声明一个新的索引,查询会自动使用最合适的那些索引。无需更改查询来利用新的索引。(请参阅“用于数据的查询语言”。)关系模型因此使添加应用程序新功能变得更加容易。
关系数据库的查询优化器是复杂的,已耗费了多年的研究和开发精力【18】。关系模型的一个关键洞察是:只需构建一次查询优化器,随后使用该数据库的所有应用程序都可以从中受益。如果你没有查询优化器的话,那么为特定查询手动编写访问路径比编写通用优化器更容易——不过从长期看通用解决方案更好。
与文档数据库相比
在一个方面,文档数据库反而有着层次模型的部分特点:在其父记录中存储嵌套记录(图2-1中的一对多关系,如positions,education和contact_info),而不是在单独的表中。
但是,在表示多对一和多对多的关系时,关系数据库和文档数据库并没有根本的不同:在这两种情况下,相关项目都被一个唯一的标识符引用,这个标识符在关系模型中被称为外键,在文档模型中称为文档引用【9】。该标识符在读取时通过连接或后续查询来解析。迄今为止,文档数据库没有走CODASYL的老路。
关系型数据库与文档数据库在今日的对比
将关系数据库与文档数据库进行比较时,可以考虑许多方面的差异,包括它们的容错属性(参阅第5章)和处理并发性(参阅第7章)。本章将只关注数据模型中的差异。
支持文档数据模型的主要论据是架构灵活性,因局部性而拥有更好的性能,以及对于某些应用程序而言更接近于应用程序使用的数据结构。关系模型通过为连接提供更好的支持以及支持多对一和多对多的关系来反击。
哪种数据模型更有助于简化应用代码?
如果应用程序中的数据具有类似文档的结构(即,一对多关系树,通常一次性加载整个树),那么使用文档模型可能是一个好主意。将类似文档的结构分解成多个表(如图2-1中的positions,education和contact_info)的关系技术可能导致繁琐的模式和不必要的复杂的应用程序代码。
文档模型有一定的局限性:例如,不能直接引用文档中的嵌套的项目,而是需要说“用户251的位置列表中的第二项”(很像分层模型中的访问路径)。但是,只要文件嵌套不太深,这通常不是问题。
文档数据库对连接的糟糕支持可能是个问题,也可能不是问题,这取决于应用程序。例如,如果某分析型应用程序使用一个文档数据库来记录何时何地发生了何事,那么多对多关系可能永远也用不上。【19】。
但如果你的应用程序确实会用到多对多关系,那么文档模型就没有那么诱人了。尽管可以通过反规范化来消除对连接的需求,但这需要应用程序代码来做额外的工作以确保数据一致性。尽管应用程序代码可以通过向数据库发出多个请求的方式来模拟连接,但这也将复杂性转移到应用程序中,而且通常也会比由数据库内的专用代码更慢。在这种情况下,使用文档模型可能会导致更复杂的应用代码与更差的性能【15】。
我们没有办法说哪种数据模型更有助于简化应用代码,因为它取决于数据项之间的关系种类。对高度关联的数据而言,文档模型是极其糟糕的,关系模型是可以接受的,而选用图形模型(参见“图数据模型”)是最自然的。
文档模型中的架构灵活性
大多数文档数据库以及关系数据库中的JSON支持都不会强制文档中的数据采用何种模式。关系数据库的XML支持通常带有可选的模式验证。没有模式意味着可以将任意的键和值添加到文档中,并且当读取时,客户端对无法保证文档可能包含的字段。
文档数据库有时称为无模式(schemaless),但这具有误导性,因为读取数据的代码通常假定某种结构——即存在隐式模式,但不由数据库强制执行【20】。一个更精确的术语是读时模式(schema-on-read)(数据的结构是隐含的,只有在数据被读取时才被解释),相应的是写时模式(schema-on-write)(传统的关系数据库方法中,模式明确,且数据库确保所有的数据都符合其模式)【21】。
译者注:在生产实践中,我从未见到过真正的无模式。因为无论如何,程序员都需要清楚读取某个数据库的某个域(field)能够得到自己需要的数据。所谓的读时模式,只是在写的时候更加自由,可扩展性更高,比如,你可以在JSON文件中添加任意的field,并且不用修改schema就可以存入NoSQLDB中。但是在读取数据库的时候,程序员需要知道自己在干什么。
读时模式类似于编程语言中的动态(运行时)类型检查,而写时模式类似于静态(编译时)类型检查。就像静态和动态类型检查的相对优点具有很大的争议性一样【22】,数据库中模式的强制性是一个具有争议的话题,一般来说没有正确或错误的答案。
在应用程序想要改变其数据格式的情况下,这些方法之间的区别尤其明显。例如,假设你把每个用户的全名存储在一个字段中,而现在想分别存储名字和姓氏【23】。在文档数据库中,只需开始写入具有新字段的新文档,并在应用程序中使用代码来处理读取旧文档的情况。例如:
if (user && user.name && !user.first_name) {
// Documents written before Dec 8, 2013 don't have first_name
user.first_name = user.name.split(" ")[0];
}
另一方面,在“静态类型”数据库模式中,通常会执行以下 迁移(migration) 操作:
ALTER TABLE users ADD COLUMN first_name text;
UPDATE users SET first_name = split_part(name, ' ', 1); -- PostgreSQL
UPDATE users SET first_name = substring_index(name, ' ', 1); -- MySQL
改变数据库模式(schema)的速度很慢,甚至要求数据库停运。它的这种坏名声并不是完全如此的:大多数关系数据库系统可在几毫秒内执行ALTER TABLE语句。MySQL是一个值得注意的例外,它执行ALTER TABLE时会复制整个表,这可能意味着在更改一个大型表时会花费几分钟甚至几个小时的停机时间,尽管存在各种工具来解决这个限制【24,25,26】。
大型表上运行UPDATE语句在任何数据库上都可能会很慢,因为每一行都需要重写。要是不可接受的话,应用程序可以将first_name设置为默认值NULL,并在读取时再填充,就像使用文档数据库一样。
当由于某种原因(例如,数据是异构的)集合中的项目并不都具有相同的结构时,读时模式更具优势。例如,如果:
- 存在许多不同类型的对象,将每种类型的对象放在自己的表中是不现实的。
- 数据的结构由外部系统决定。你无法控制外部系统且它随时可能变化。
在上述情况下,使用模式的坏处远大于它的帮助,无模式的存储可能是一个更加自然的数据模型。但是,要是所有记录都具有相同的结构,那么模式是记录并强制这种结构的有效机制。第四章将更详细地讨论模式和模式演化。
查询的数据局部性
文档通常以单个连续字符串形式进行存储,编码为JSON,XML或其二进制变体(如MongoDB的BSON)。如果应用程序经常需要访问整个文档(例如,将其渲染至网页),那么存储局部性会带来性能优势。如果将数据分割到多个表中(如图2-1所示),则需要进行多次索引查找才能将其全部检索出来,这可能需要更多的磁盘查找并花费更多的时间。
局部性仅仅适用于同时需要一份文档绝大部分内容的情况。数据库通常需要加载整个文档,即使只访问其中的一小部分,这对于大型文档来说是很浪费的。更新文档时,通常需要整个重写。只有不改变文档大小的修改才可以容易地原地执行。因此,通常建议保持相对小的文档,并避免增加文档大小的写入【9】。这些性能限制大大减少了文档数据库的实用场景。
值得指出的是,为了局部性而分组集合相关数据的想法并不局限于文档模型。例如,Google的Spanner数据库在关系数据模型中提供了同样的局部性属性,允许模式声明一个表的行应该交错(嵌套)在父表内【27】。Oracle类似地允许使用一个称为 多表索引集群表(multi-table index cluster tables) 的类似特性【28】。Bigtable数据模型(用于Cassandra和HBase)中的 列族(column-family) 概念与管理局部性的目的类似【29】。
在第3章将还会看到更多关于局部性的内容。
文档和关系数据库的融合
自2000年代中期以来,大多数关系数据库系统(MySQL除外)都已支持XML。这包括对XML文档进行本地修改的功能,以及在XML文档中进行索引和查询的功能。这允许应用程序使用那种与文档数据库应当使用的非常类似的数据模型。
从9.3版本开始的PostgreSQL 【8】,从5.7版本开始的MySQL以及从版本10.5开始的IBM DB2 [30]也对JSON文档提供了类似的支持级别。鉴于用在Web APIs的JSON流行趋势,其他关系数据库很可能会跟随他们的脚步并添加JSON支持。
在文档数据库中,RethinkDB在其查询语言中支持类似关系的连接,一些MongoDB驱动程序可以自动解析数据库引用(有效地执行客户端连接,尽管这可能比在数据库中执行的连接慢,需要额外的网络往返,并且优化更少)。
随着时间的推移,关系数据库和文档数据库似乎变得越来越相似,这是一件好事:数据模型相互补充5,如果一个数据库能够处理类似文档的数据,并能够对其执行关系查询,那么应用程序就可以使用最符合其需求的功能组合。
关系模型和文档模型的混合是未来数据库一条很好的路线。
数据查询语言
当引入关系模型时,关系模型包含了一种查询数据的新方法:SQL是一种 声明式 查询语言,而IMS和CODASYL使用 命令式 代码来查询数据库。那是什么意思?
许多常用的编程语言是命令式的。例如,给定一个动物物种的列表,返回列表中的鲨鱼可以这样写:
function getSharks() {
var sharks = [];
for (var i = 0; i < animals.length; i++) {
if (animals[i].family === "Sharks") {
sharks.push(animals[i]);
}
}
return sharks;
}
在关系代数中:
s
h
a
r
k
s
=
σ
f
a
m
i
l
y
=
"
s
h
a
r
k
s
"
(
a
n
i
m
a
l
s
)
sharks = σ_{family = "sharks"}(animals)
sharks=σfamily="sharks"(animals)
σ(希腊字母西格玛)是选择操作符,只返回符合条件的动物,family="shark"。
定义SQL时,它紧密地遵循关系代数的结构:
SELECT * FROM animals WHERE family ='Sharks';
命令式语言告诉计算机以特定顺序执行某些操作。可以想象一下,逐行地遍历代码,评估条件,更新变量,并决定是否再循环一遍。
在声明式查询语言(如SQL或关系代数)中,你只需指定所需数据的模式 - 结果必须符合哪些条件,以及如何将数据转换(例如,排序,分组和集合) - 但不是如何实现这一目标。数据库系统的查询优化器决定使用哪些索引和哪些连接方法,以及以何种顺序执行查询的各个部分。
声明式查询语言是迷人的,因为它通常比命令式API更加简洁和容易。但更重要的是,它还隐藏了数据库引擎的实现细节,这使得数据库系统可以在无需对查询做任何更改的情况下进行性能提升。
例如,在本节开头所示的命令代码中,动物列表以特定顺序出现。如果数据库想要在后台回收未使用的磁盘空间,则可能需要移动记录,这会改变动物出现的顺序。数据库能否安全地执行,而不会中断查询?
SQL示例不确保任何特定的顺序,因此不在意顺序是否改变。但是如果查询用命令式的代码来写的话,那么数据库就永远不可能确定代码是否依赖于排序。SQL相当有限的功能性为数据库提供了更多自动优化的空间。
最后,声明式语言往往适合并行执行。现在,CPU的速度通过核心(core)的增加变得更快,而不是以比以前更高的时钟速度运行【31】。命令代码很难在多个核心和多个机器之间并行化,因为它指定了指令必须以特定顺序执行。声明式语言更具有并行执行的潜力,因为它们仅指定结果的模式,而不指定用于确定结果的算法。在适当情况下,数据库可以自由使用查询语言的并行实现【32】。
Web上的声明式查询
声明式查询语言的优势不仅限于数据库。为了说明这一点,让我们在一个完全不同的环境中比较声明式和命令式方法:一个Web浏览器。
假设你有一个关于海洋动物的网站。用户当前正在查看鲨鱼页面,因此你将当前所选的导航项目“鲨鱼”标记为当前选中项目。
<ul>
<li class="selected">
<p>Sharks</p>
<ul>
<li>Great White Shark</li>
<li>Tiger Shark</li>
<li>Hammerhead Shark</li>
</ul>
</li>
<li><p>Whales</p>
<ul>
<li>Blue Whale</li>
<li>Humpback Whale</li>
<li>Fin Whale</li>
</ul>
</li>
</ul>
现在想让当前所选页面的标题具有一个蓝色的背景,以便在视觉上突出显示。使用CSS实现起来非常简单:
li.selected > p {
background-color: blue;
}
这里的CSS选择器li.selected> p声明了我们想要应用蓝色样式的元素的模式:即其直接父元素是具有selectedCSS类的<li>元素的所有<p>元素。示例中的元素<p> Sharks </p>匹配此模式,但<p> Whales </p>不匹配,因为其<li>父元素缺少class =“selected”。
如果使用XSL而不是CSS,你可以做类似的事情:
<xsl:template match="li[@class='selected']/p">
<fo:block background-color="blue">
<xsl:apply-templates/>
</fo:block>
</xsl:template>
这里的XPath表达式li[@class='selected']/p相当于上例中的CSS选择器li.selected> p。CSS和XSL的共同之处在于,它们都是用于指定文档样式的声明式语言。
想象一下,必须使用命令式方法的情况会是如何。在javascript中,使用 文档对象模型(DOM) API,其结果可能如下所示:
var liElements = document.getElementsByTagName("li");
for (var i = 0; i < liElements.length; i++) {
if (liElements[i].className === "selected") {
var children = liElements[i].childNodes;
for (var j = 0; j < children.length; j++) {
var child = children[j];
if (child.nodeType === Node.ELEMENT_NODE && child.tagName === "P") {
child.setAttribute("style", "background-color: blue");
}
}以上是关于设计数据密集型应用 第二章:数据模型与查询语言的主要内容,如果未能解决你的问题,请参考以下文章