图像识别技术综述
Posted 数智联盟
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了图像识别技术综述相关的知识,希望对你有一定的参考价值。
点击标题下【数智联盟】可快速关注
无论怎样,我们不得不承认,在我们所处的当今时代,技术发展对现代生活有着决定性的影响。
但令人喜忧参半的是,科技变化如此之快,我们几乎无法跟上它的脚步,更不用说预测未来了。 其中发展最快速,影响力最大和最吸引人的技术进步之一就是图像识别。
什么是图像识别?
图像识别是计算机视觉的机制之一,而计算机视觉是人工智能的一个分支。
正如我们在AI、机器学习与深度学习的区别一文中提到的那样,人工智能(也称AI)是一种能够模仿人类特征并胜任通常需要人类智能才能完成的任务的计算机系统。
为了让AI更有说服力,我们需要所谓的“计算机视觉”。根据Venture Beat的说法,计算机视觉是“计算机获取,处理和分析主要来自视觉提示或热传感器,超声波等类似来源的数据。
简而言之,计算机视觉使得机器能够“看”事物——甚至包括人类无法看到的事物。例如,位于匹兹堡(美国)的卡内基梅隆大学实际上正致力于研究名为“呼吸凸轮”的计算机视觉应用。该应用配备了四个云连接摄像头,可以让用户监控和记录空气污染,甚至可以追溯到污染的源头。是的,它“看到”了空气质量。
然而,要想让机器做到人类无法做到的事情,我们必须首先使机器能够做到人类可以做的事情:看到并标记物体和生物。这是图像识别的主要功能。
Tensorflow是一个由Google开发人员创建的开源软件库,它将图像识别定义为计算机将图像或视频分解为像素,识别形状,以便“看到”这些图像的内容,并对它们进行分类的过程。
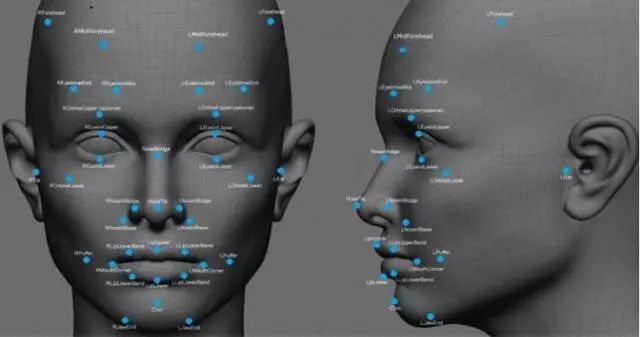
人脸识别中的图像识别 | Sebastian Anthony
例如,股票网站每天都有数百万张图片上传和数十亿的搜索量。通常,网站建设者必须为他们上传的每张照片添加标签和说明,以便与用户的搜索词匹配。通过安装图像识别应用,一旦图像传输到服务器,机器就可以自动识别图像中的人物或物体。然后,它可以自动对图像进行描述,比人类的描述更加具体,从而优化搜索引擎并改善用户体验。
如何实现图像识别?
目前,深度学习是最有可能让机器实现“看”的能力的技术。简单地说,深度学习就是一种机器学习框架,通过模仿人类的神经元系统,为计算机提供自主学习能力。因此,计算机可以准确识别图片中的内容,而无需根据指令安装手动编码的软件——但它需要大量数据才能完成识别。
因此,全世界都在致力于开发大量数据,其中最典型的例子就是ImageNet和PASCAL数据集。经过多年的努力,这些庞大且免费的数据集包含数百万张图像,每张图像都标记有图像内容相关的关键字。
1. ImageNet:由普林斯顿大学的研究人员于2009年创建,这个可视化数据集拥有从Flickr等搜索引擎收集的超过1400万个URL图像。在数据集创建过程中,工作人员和志愿者对提交的图片进行了详细地注释,并将其分类为约1000个对象类。
2. PASCAL:PASCAL由欧盟国家各大学联合创建,与ImageNet数据集相比,PASCAL相形见绌 —— 仅有20个对象类,共20,000个训练图像。
正如您可能已经从两者在类数量上的巨大差异中猜到的那样,PASCAL的分类更具通用性。相反,ImageNet注重图像识别技术发展一个关键特征:类间差异性——机器能够识别两张包含同一物种或物体的不同类型的图像,因此图像被分在不同的类别中。例如,虽然同一图片在PASCAL中仅属于“狗”这一类别,但它在ImageNet中可能被分类为“柯基犬”,“牧羊犬”或“哈巴狗”等类。
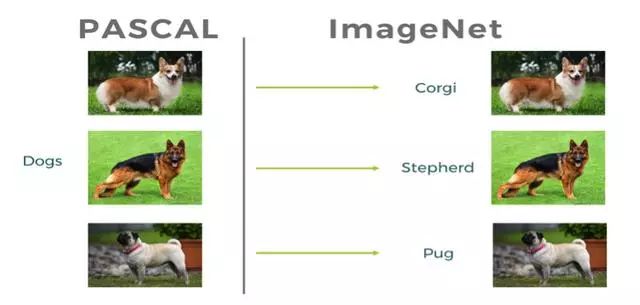
分类方法PASCAL vs. ImageNet | Savvycom Team
为什么要投资图像学习?
看起来每个人都在这样做,不是吗?因为他们确实在这样做。
2012年,Qualcomm Connected Experiences公司首次推出Vuforia软件平台。该平台利用图像识别技术提供大量的AR和VR相关功能,使得移动应用程序开发人员能够随意扩展视野。

虚拟现实用户| Flickr
Facebook于2016年开始帮助盲人“看”照片和图像。通过使用图像识别,Facebook ios应用程序将为每张照片生成描述,并为用户大声朗读。
在今年早些时候,谷歌--世界上最值得关注的人工智能公司之一推出了Cloud AutoML--一种旨在简化AI在企业运营中的应用的工具。Cloud AutoML首先启动了图像识别功能,允许Google用户拖入图像并教会用户系统在Google云上识别图像。迪士尼和Urban Outfitters等公司已将其应用于网站搜索,使结果更符合用户需求。
谷歌 CloudAuto ML | Google
为什么有数十亿美元投入到这项技术?我们的猜测是图像识别潜力巨大。
图像识别是一个非常抽象的领域。但是,当应用于具体情境时,其改变企业的潜力是无可辩驳的。让我们看看各个行业和企业流程中图像识别的几种潜在应用:
1. 医疗保健:图像识别最突出的能力之一是协助创建增强现实(AR)——一种“将计算机生成的图像叠加在用户对现实世界的视角之上”的技术。如果给人工智能提供AR技术和包含疾病视觉提示的数据集,你将有一个永生难忘的医疗助理。有了它,医生就可以在检查期间获得患者伤口的的实时详细诊断建议或医疗文件。
2. 教育:图像识别可以让有学习困难或身体残疾的学生以他们能够感知的形式获得所需的教育。计算机视觉支持的应用程序可以提供文本到语音和图像到语音功能,帮助视力受损或有阅读障碍的学生“阅读”所提供的内容。
3. 食品和饮料:通过使用图像识别,智能手机上的简单应用可以获得Instagram和Facebook上图像的视觉提示,分析它们并提供实时数据。例如,根据这些照片,该应用程序可以告诉你新加坡的某家咖啡馆是您家人和朋友经常去的地方,还是一个举办疯狂聚会的场所。通过这种方式,用户可以一目了然地获得本地定制方案,而餐厅也可以有效地接触到目标受众。
4. 电子商务:想象一个用户在街上看到他们想买的东西,但他们找不到人问在哪里可以买到它,因此他拍了一张照片。然后,该用户将其上传到配备图像识别技术的电子商务网站。算法本身可以“看”图片,扫描数百万个可选项,并推荐一个看起来与客户所寻求的相同,至少是最接近的选项。这正是Savvycom在2018年3月创建新AI Lab时的初衷。现在,我们的工程师正在研发人工智能视觉搜索工具,以利用拥有数千种产品的大型电子商务数据集,扩大电商体验。
5. 企业流程管理:先进的图像识别系统还可以在企业经营时协助识别。例如,机器可以进行面部识别,这将取代传统身份证,来确定某人是否被授予执行某项任务的权利:如访问文件存储系统,参加会议或检查工作。然而,我们不得不承认,由于个人情感、化妆等因素的影响,“看”和“识别”人脸比识别物体要复杂得多。因此,Savvycom的目标是尽快在即将开展的项目中解决这个问题。
图像识别技术发展面临哪些障碍?
图像识别并非一个新领域,但放眼全局,它仍处于早期阶段。就像任何一个典型的成长中少年一样,在适应现实世界时也存在问题。
还记得“80%的组织表示他们在生产中应用了AI应用程序”吗?在这些应用了人工智能技术的公司中,约有33%的公司表示采用人工智能技术的最大障碍是不稳定性--不成熟且未经证实。34%认为很难招聘到合格的工程师,40%表示信息技术基础设施建设阻碍了人工智能技术的引进,且很容易对公司的财务造成不利影响。
资金也是一个重要影响因素。由于用于数据流编程的开源软件库越来越多,如Microsoft CNTK和Accord.Net,机器学习爱好者能够以极低的成本进行研究和学习。然而,并非所有问题都能得到解决,因为并非一切都是已知的。为了实现产品创意,要平衡预算,公司仍有很长的路要走。
有一种解决方案可以解决许多上述问题:外包。IT外包公司专注于技能和专业知识,能以可预测的管理成本提供高端工具和最佳实践操作。简而言之,他们知道自己在做什么。那是他们的工作。
总而言之,图像识别是计算机视觉时代到来的早期征兆。无论它将如何应用或将应用于哪些行业,图像识别技术永远不可能孤立发展。只有通过访问更多图片,实时数据,花费更多的时间和精力才能使其更加强大。只有认识到这一点,并充分利用这些联系的企业才可能在未来取得成功。
本文来源:互联网
免责声明:本文系网络转载或改编,版权归原作者所有。如涉及版权,请联系删除!
扫一扫,感谢关注“数智联盟(中国)”。
“中国制造2025”强国计划,我们一起行动,欢迎加入。
邮箱:liye@leisurei.cn
以上是关于图像识别技术综述的主要内容,如果未能解决你的问题,请参考以下文章