推荐综述 | 零样本图像识别
Posted 电子与信息学报
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了推荐综述 | 零样本图像识别相关的知识,希望对你有一定的参考价值。

小编今日推荐江西理工大学兰红教授团队发表于《电子与信息学报》2020年42卷第5期的综述:零样本图像识别。该文首先介绍零样本学习的关键技术和常用的数据集,然后梳理对比了零样本学习中几类具有代表性的模型性能,最后对当前面临问题进行总结并对未来可能的研究方向进行展望。欢迎品鉴!
题 目:零样本图像识别
作 者:兰红、方治屿
单 位:江西理工大学信息工程学院
关键词:零样本学习;深度卷积神经网络;视觉语义嵌入;泛化零样本学习
零样本学习研究可以追溯到2008年。在没有任何观测数据的情况下进行分类识别任务被称为零样本学习,其关键思想在于探索和利用未知类与已知类在语义或其他高层特征间的相关知识,从而达到知识迁移的目的。
零样本学习最大的特点就是在模型测试阶段使用的数据集从未出现在模型训练阶段的数据集中,表1列举了在计算机视觉领域几类常见机器学习方法与零样本学习之间的差异比较。
表1 机器学习方法对比表

图1给出了零样本学习的技术结构图。从图1可以看出,零样本学习是通过嵌入空间来建立已知类与未知类之间耦合关系,这也是零样本学习的核心。它利用原始图像提取特征向量构建特征空间,再利用类别标签提取图像对应类别的语义向量构建语义空间,然后结合特征空间和语义空间,分析两者之间的映射关系,构建嵌入空间。基于语义空间,在训练阶段使用已知类数据集学习图像与类别之间的关系,在测试阶段就可以利用该关系,先由图像特征预测对应的语义向量,再根据语义向量匹配图像所属类别。
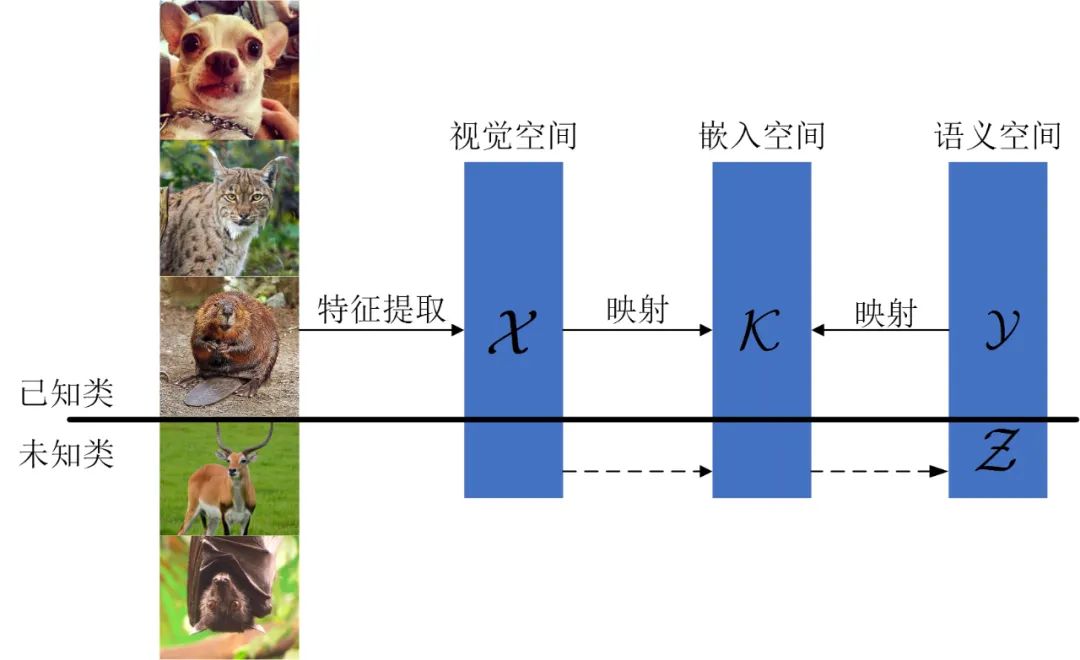
图1 零样本学习技术结构图
目前学者们在处理零样本学习问题中使用的普遍的步骤为:(1)提取视觉特征构建视觉空间;(2)提取语义特征构建语义空间;(3)实现视觉空间与语义空间之间的映射构建嵌入空间。
视觉特征
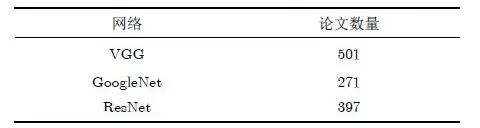
随着卷积神经网络和深度学习在计算机视觉领域取得巨大成果,如今对图像特征的提取更为有效的还是基于深度卷积神经网络的方法。自2014年以来基于深度卷积神经网络的方法被广泛应用于零样本至此在零样本学习中提取的视觉特征也开始由浅入深、语义相关性由低到高。表2给出了近5年内出现在AAAI, IPS和CVPR等顶级国际会议中关于零样本学习使用3种深度卷积神经网络的论文数量统计表。
表2 零样本学习中深度卷积神经网络使用情况统计表
语义特征
零样本学习之所以可以完成传统监督学习无法完成的对未知类识别的任务,关键因素就在于零样本学习除了将视觉特征用于识别外,还引入了语义特征,从而超越了互斥对象类之间的类边界。在零样本学习中,语义特征的提取一般独立于视觉特征的提取,不过近年来也有许多学者提出了端到端的网络统一了这两个过程。
零样本学习中主要的语义特征提取方法分为基于属性、基于词嵌入向量和基于知识图3种方法。目前视觉特征提取已经普遍采用基于深度卷积神经网络的方式获取,而语义特征的提取除了以上3种常用方法,学者们仍在不断提出新的方法:(1)出于类的视觉信息与图像本身的视觉特征结构更一致的考虑的方法;(2)充分利用文本信息提高细粒度对象类识别的性能的方法。
视觉-语义映射
视觉-语义映射是解决零样本学习问题必不可少的基石,是图像特征与语义向量之间的连接的枢纽。一旦建立好视觉-语义映射,便可以计算任意未知类数据和未知类原型之间的相似度,并基于该相似度对未知类进行分类。
有3种方式构建视觉-语义映射:(1)正向映射,在视觉端构建,将图片特征映射到语义向量空间,并在语义向量空间进行未知类识别;(2)反向映射,在语义端构建,将语义向量映射到图片特征空间,并在图片特征空间进行未知类识别;(3)公共映射,在公共端构建,将图片特征和语义向量映射到公共空间,并在公共空间内完成识别任务,3种映射方式如图2所示。
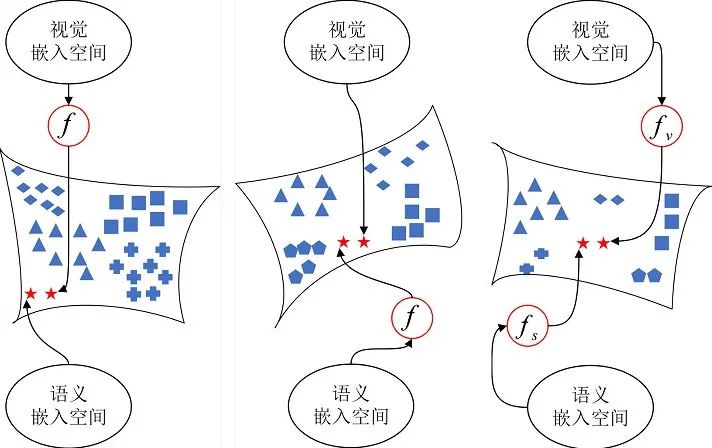
图2 3种视觉-语义映射示意图
常用数据集
在零样本学习领域有7个常用数据集,它们分别是AwA, CUB, aPY, SUN, Flower, Dogs和ImageNet。其中前6个数据集为小规模数据集,最后一个为大规模数据集。
评价指标
根据使用的数据集规模不同,零样本学习性能的评价指标也不同。
针对小规模数据集而言,主要的评价指标是分类精确度(acc)、精确率(precision)和召回率(recall),三者分别从不同角度对零样本学习性能进行评价。
针对大规模数据集而言,使用的评价指标为Flat hit @ k(f@k)和Hierarchical precision @k(hp@k)。
传统零样本学习(conventional Zero-ShotLearning, cZSL)是指在实验阶段仅使用已知类训练模型,仅使用未知类测试模型;泛化零样本学习(generalized Zero-Shot Learning, gZSL)则不再将测试数据强制认定为仅来自未知类,而是对测试数据的来源做更松弛化的假设(测试数据可以来自于所有类别中的任意对象类),两者是目前两种主流的实验评价配置方案。
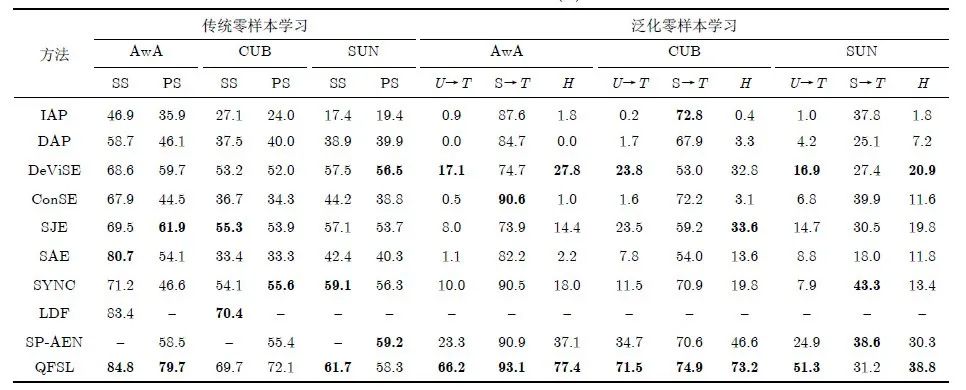
该文选取几个典型的和最新的零样本学习模型分别在传统零样本学习和泛化零样本学习设置下进行模型性能对比,为了便于统计各个模型的性能数据,本文选取了在零样本学习中使用最为广泛的3个数据集,分别为AwA, CUB和SUN。对比数据来源于引用算法的原始数据或其他论文实现并公布的结果,具体如表3所示。
表3 零样本学习性能比较(%)
除了存在传统监督学习中固有的过拟合问题外,学者们在研究过程中发现零样本学习所特有的新问题,主要有3种。
(1) 领域漂移:针对基于属性构建语义向量的模型而言,当同一种属性在不同的类别中,视觉特征表达可能差别很大。如图3所示的斑马和猪都有尾巴的属性,但是两者的尾巴的视觉特征相差很远,如果用斑马训练出来的模型将很难正确识别猪。目前最流行的解决办法是将映射到语义空间的样本再重建回去,这样学习到的映射就能保留更多的信息。
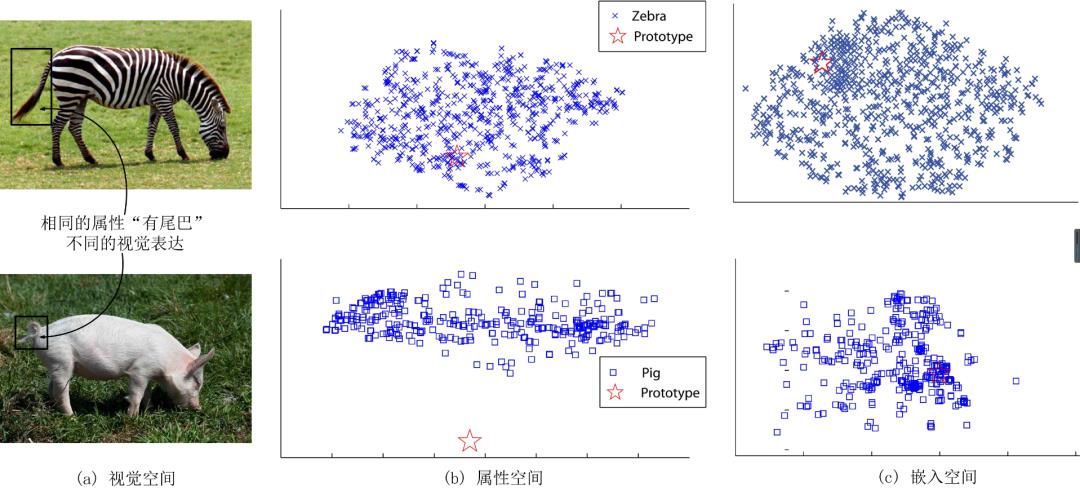
图3 领域漂移示例图
(2) 枢纽点:在高维空间中,某些点会成为大多数点的最近邻点,这是高维空间中固有的问题。由于一般的零样本学习模型最终分类使用的是KNN算法,所以枢纽点问题严重影响分类结果。该问题的解决方案有两个,一是若模型采用岭回归方式建立,则需要将视觉-语义映射方式改为反向映射;二是使用生成模型(自编码器和GAN等)生成测试集的样本,将零样本学习转变成传统的监督分类问题,避免K-NN操作,从而消除枢纽点问题。
(3) 语义间隔:由于表示视觉特征的图像与表示非视觉特征的语义经过特征提取之后,图像特征空间与语义空间中对应类别的流形不一致,导致直接学习两者之间的映射较为困难,从而引发语义间隔问题。
零样本学习领域拥有着巨大的潜力,同时伴随着很多挑战等待学者们的进一步研究,通过对现有文献的思考,本文列出以下未来零样本学习的研究方向:(1)在泛化零样本学习设置下如何提高模型的精确度和泛化能力;(2)如何提高细粒度零样本学习的识别精度;(3)怎样构建端到端的零样本学习模型;(4)如何联合少样本学习、开集识别等相关课题完善零样本学习;(5)如何逐步实现终身学习的目标。
兰 红:女,1969年生,教授,硕士生导师,主要研究方向为计算机视觉、图像处理与模式识别。
方治屿:男,1993年生,硕士生,研究方向为计算机视觉与深度学习。

本文系《电子与信息学报》独家稿件
内容仅供学习交流
版权属于原作者
欢迎大家关注转发!

编辑: 周隽凡、马秀强
校对:余蓉、刘艳玲
审核:陈倩
温馨提示

本文系《电子与信息学报》独家稿件,内容仅供学习交流,版权属于原作者。
本号发布信息旨在传播交流。如涉及文字、图片、版权等问题,请在20日内与本号联系,我们将第一时间处理。《电子与信息学报》拥有最终解释权。
号外

为促进学术交流,拉进编辑团队和作者,读者,专家之间的距离,电子与信息学报2021年正式开通4个微信学术讨论群啦,欢迎大同行小同行们扫码入群转发推荐扫码可选择通信与信号信息处理、网络与信息安全、自动化与模式识别、电路与系统技术等4个专业方向入口:

由于微信群既定机制,200人以后无法直接扫码,只能通过邀请入群。如此,请与您的好友互邀,更欢迎您通过加小编微信入群。进群请更改真实姓名+单位,欢迎把我们推荐给您的同行朋友们,大家一起寻找志同道合的伙伴!

《电子与信息学报》
官方订阅号
以上是关于推荐综述 | 零样本图像识别的主要内容,如果未能解决你的问题,请参考以下文章