显著提升图像识别网络效率,Facebook提出IdleBlock混合组成方法 Posted 2021-04-07 机器之心
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了显著提升图像识别网络效率,Facebook提出IdleBlock混合组成方法相关的知识,希望对你有一定的参考价值。
Facebook AI 近日一项研究提出了一种新的卷积模块 IdleBlock 以及使用该模块的混合组成(HC)方法。实验表明这种简洁的新方法不仅能显著提升网络效率,而且还超过绝大多数神经网络结构搜索的工作,在同等计算成本下取得了 SOTA 表现,相信这项研究能给图像识别网络的开发、神经网络结构搜索甚至其他领域网络设计思路带来一些新的启迪。
链接:https://arxiv.org/pdf/1911.08609.pdf
近年来,卷积神经网络(CNN)已经主宰了计算机视觉领域。
自 AlexNet 诞生以来,计算机视觉社区已经找到了一些能够改进 CNN 的设计,让这种骨干网络变得更加强大和高效,其中比较出色的单个分支网络包括 Network in Network、VGGNet、ResNet、DenseNet、ResNext、MobileNet v1/v2/v3 和 ShuffleNet v1/v2。
近年来同样吸引了研究社区关注的还有多分辨率骨干网络。
为了能够实现多分辨率学习,研究者设计出了模块内复杂的连接来处理不同分辨率之间的信息交换。
能够有效实现这种方法的例子有 MultiGrid-Conv、OctaveConv 和 HRNet。
这些方法在推动骨干网络的设计思想方面做出了巨大的贡献。
为了设计出更高效的 CNN,主流的发展方向有两个:
神经架构搜索(Neural Architecture Search,NAS)和网络剪枝(Network Pruning,NP)。
NAS 的思路是:
给定限量的计算资源,自动确定最佳的网络连接方式、模块设计和超参数。
超参数搜索(Hyperparameter searching)是机器学习领域内一大经典的研究主题,本文所指的 NAS 仅限定于搜索神经网络的连接方式和模块设计。
NP 的思路是:
给定一个经过预训练的网络,使用能够移除不重要连接的自动算法,从而降低计算和参数量。
不同于搜索连接方式的 NAS 以及 NP,EfficientNet 则为骨干网络提供了联合超参数:
深度缩放因子 d、宽度缩放因子 w、输入分辨率缩放因子 r,这被称为复合缩放因子。
基于 MobileNet v3 的一种变体,这些联合搜索的缩放因子让 EfficientNet 系列网络在计算成本(MAdds)或参数数量方面比所有之前的骨干网络高效 5 到 10 倍。
作者认为目前实现高效卷积网络的工作流程可以分成两步:
1)设计一种网络架构;
2)对该网络中的连接进行剪枝。
在第一步,作者研究了人类专家设计的架构与搜索得到的架构之间的共同模式:
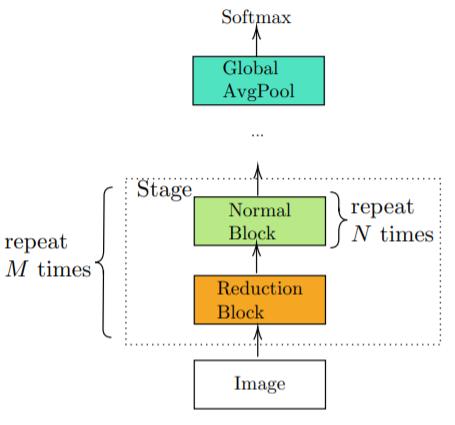
对于每种骨干网络,其架构都是由其普通模块和归约模块(reduction block)的设计所确定的。
他们的具体操作是在每一阶段开始时插入一个归约模块,然后反复堆叠普通模块。
每一阶段都重复多次,则每一阶段普通模块的数量可能各不相同。
作者将这种设计模式称为单调设计(Monotonous Design,下图 3)
举例来说,ResNet 是单调重复 Bottleneck 模块,ShuffleNet 是单调重复 ShuffleBlock,MobileNet v2/v3 和 EfficientNet 是单调重复 Inverted Residual Block(MBBlock),NASNet 是重复 Normal Cell,FBNet 是重复 MBBlock 的一种有不同超参数的变体。
作者表示,目前所有主流的网络模块都保证了完整的信息交换。
第二步会将某些连接剪枝去掉,这样就不能保证每个模块都有完整的信息交换了。
Facebook AI 的研究者在这篇论文中通过在网络设计步骤中考虑剪枝,为图像识别任务设计了一种更高效的网络。
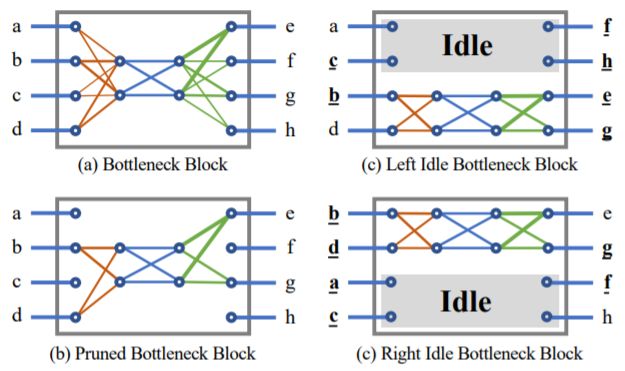
他们创造了一种新的模块设计方法:
Idle。
在 Idle 设计中,输入的一个子空间是不会进行变换的:
它只是会闲置并被直接传递给输出(下图 1)。
图 1: Idle 的设计思路。 Idle 设计中的信息交换应用在 Idle 模块之外。
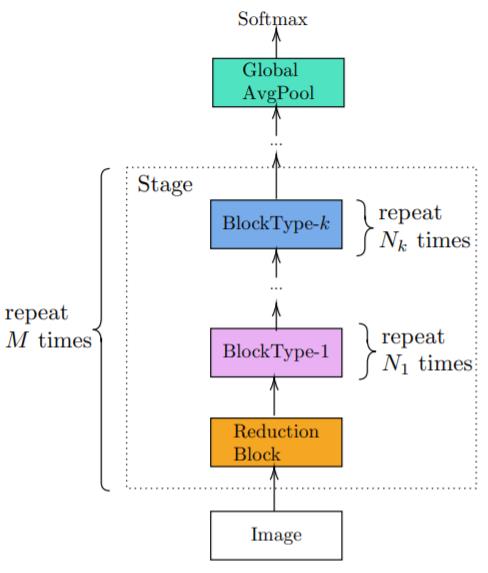
他们还突破了当前先进架构的单调设计限制,并将新提出的非单调式组成方法称为混合组成(Hybrid Composition/HC)方法(下图 4)。
初始的结果与预期相符:
如果单调地使用 IdleBlock 构建一个网络,则我们会得到一个准确度损失在可接受范围内的已剪枝网络。
如果使用 IdleBlock(和 MBBlock)进行混合构建,能够在显著节省计算的同时极大降低准确度损失。
但结果中还有出乎意料的发现:
通过利用 IdleBlock 混合组合后节省的计算来继续加大网络深度就可以得到同等计算下新的 SOTA 网络结构——而无需复杂的多分辨率设计或神经架构搜索。
下面简要展示了过去几种关键的卷积构建模块设计示意图:
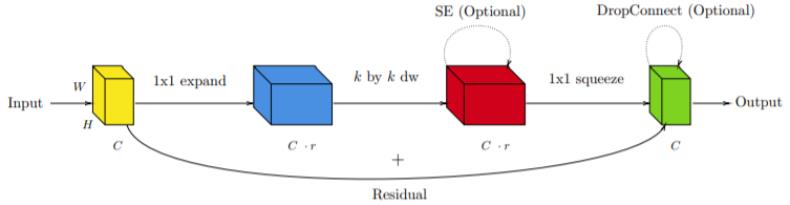
Bottleneck 模块的目标是减少空间卷积的计算量。
其中每个模块都由经过扩展的输入和输出构成,没有非线性。
残差连接位于经过扩展的表征之间。
逆向残差连接模块(Inverted Residual Block,MBBlock)的目标是从经过扩展的投射中提取出丰富的空间信息。
其中每个模块都由较窄的输入和输出构成,没有非线性。
残差连接位于经过收窄的表征之间。
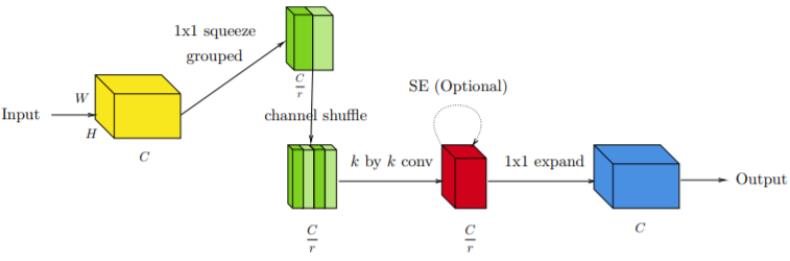
ShuffleBlock v1 是 Bottleneck 模块的一种扩展。
其未来减少收窄后的表征计算,引入一种分组式逐点运算,并在后面使用了通道混洗操作。
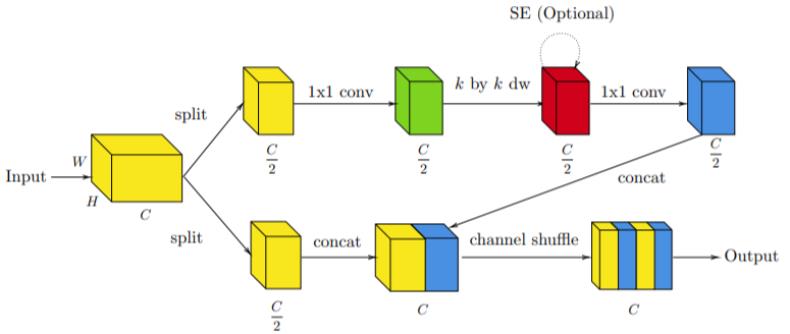
ShuffleBlock v2 移除了分组式逐点运算,而是使用分割来获取收窄的表征。
类似于 Bottleneck 模块和 ShuffleBlock v1,每个都由经过扩展的输入和输出构成。
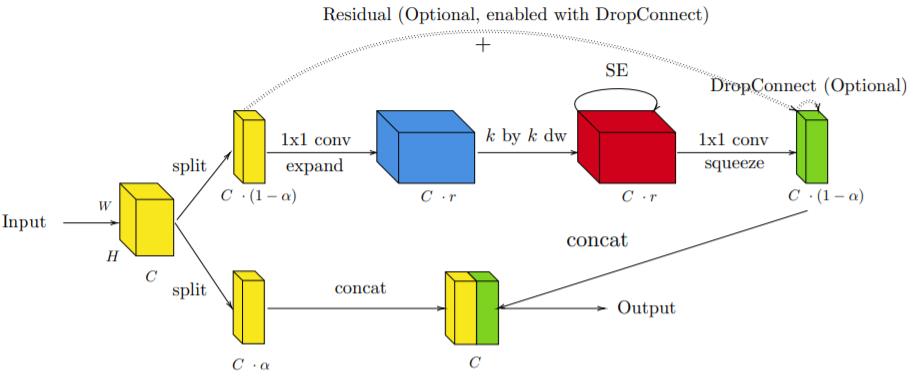
这篇论文提出了一种新的设计模式:
Idle,其目标是将输入的一个子空间直接传递到输出张量,而不经历任何变换。
上图 1 展示了 Idle 和网络剪枝的思路。
作者在 Idle 设计中引入了一个 Idle 因子 α ∈ (0, 1),它也可以被视为剪枝因子。
给定一个有 C 个通道的输入张量 x,张量会被切分为两个分支:
一个是包含 C · (1 − α) 个通道的主动分支 x_1,这会输出一个 C ·(1−α) 个通道的张量 y_1;
另一个是有 C · α 个通道的 Idle 分支 x_2,它会被直接复制到有 C 个通道的输出张量 y。
Idle 设计与 Residual connection, Dense connection 和 ShuffleBlock v2 的区别请参考原文。
首先,作者给出了在 ShuffleBlock v1/v2 和 MBBlock 上得到的一些直观结果和实验经验教训:
基于这些经验教训,本文提出了 MBBlock 的一种 Idle 化版本:
IdleBlock。
IdleBlock 有两种变体。
如果在基于两个分支构建输出张量时使用的连接函数是 concat(y1, x2),则称之为 L-IdleBlock(下图 9);
而如果使用的连接函数是 concat(x2, y1),则称之为 R-IdleBlock。
如果是信息交换模块之后紧跟着一个 IdleBlock,则 L-IdleBlock 和 R-IdleBlock 是等效的。
当堆叠两个或多个 IdleBlock 时,L/R-IdleBlock 单元的混合不同于 L/R-IdleBlock 单元的单调组成。
混合组成(HC)是一种全新的非单调式网络组成方法。
在混合组成中,网络的每个阶段都使用多种类型的构建模块进行非单调的组成。
这只有当不同模块的输入和输出维度限制一样时才能实现。
在使用 IdleBlock 的案例中,IdleBlock 和 MBBlock 都满足混合组成的输入和输出约束。
此外,一旦实现了 IdleBlock 和 MBBlock 的混合化,MBBlock 中的首个逐点卷积运算就可以帮助我们交换 IdleBlock 的两个分支的信息,而无需像在 ShuffleBlock 中一样执行显式的通道混洗操作。
但是,混合组成又带来了另外的问题。
如果一个网络阶段包含 n 个 MBBlock 单元,则该 Idle 网络中 MBBlock 和 IdleBlock 的放置方式有 2^n 种候选组合,但需要探索的只是这些候选组合中的一小部分。
为了解决这个难题,研究者探索了 MBBlock 与 IdleBlock 的三种不同的混合组成配置:
Maximum、None 和 Adjacent。
具体解释请参阅原论文。
作者基于 ImageNet 2012 分类数据集进行了实验,结果表明了使用 IdleBlock 的混合组成的有效性。
表 1: 在 MobileNet v3 上应用不同混合组成配置的结果。 ★表示使用分布式训练。 None 配置是标准的 MobileNet v3。 Adjacent + 1 IdleBlock L/R 是用一个 L-IdleBlock 和一个 R-IdleBlock 替换一个 MBBlock 的配置。 当使用 IdleBlock 添加或替换 MBBlock 时,都使用了与被替换的 MBBlock 同样的 SE、通道和激活设置。
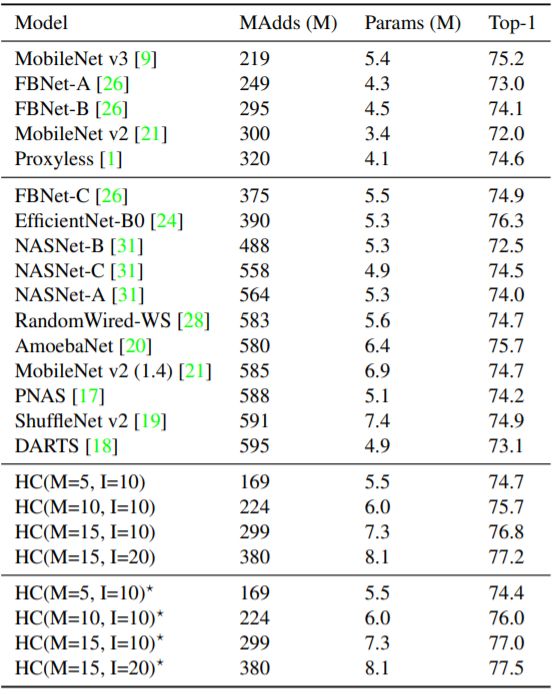
表 2: 在 MobileNet v3 上使用 IdleBlock 的混合组成与 SOTA 人类专家设计的网络与 NAS 网络之间的比较。 新方法的结果表示为 HC(M=x, I=y): M 是 MBBlock 的总数,I 是 IdleBlock 的总数。 ★表示使用了分布式训练。
表 3: 在 EfficientNet-B0 上应用不同混合组成配置的结果。 如 MobileNet v3 实验一样,SE、通道、非线性激活和 DropConnect 设置与被替换的 MBBlock 一样。
表 4: 使用了混合组成的 Efficient-B0 与当前最佳方法的比较。 ★ 表示新方法的结果; ◇表示来自 GluonCV 的结果; □ 表示使用 320 × 320 分辨率的图像训练和测试的网络。
另外,作者也进行了一些控制变量实验研究,让新方法的有效性得到了进一步的验证。
: 22 大领域、127个任务,机器学习 SOTA 研究一网打尽。
点击 阅读原文 ,立即访问 。
以上是关于显著提升图像识别网络效率,Facebook提出IdleBlock混合组成方法的主要内容,如果未能解决你的问题,请参考以下文章
谷歌 AI 新方法:可提升 10 倍图像识别效率,关键还简单易用
第四范式提出深度稀疏网络模型,显著提升高维稀疏表数据分类效果
Facebook提出DensePose数据集和网络架构:可实现实时的人体姿态估计
GraalVM在Facebook大量使用,性能提升显著!
GraalVM在Facebook大量使用,性能提升显著!
深度残差网络(DRN)ResNet网络原理