图像识别之KNN算法的理解与应用
Posted 萌萌哒程序猴
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了图像识别之KNN算法的理解与应用相关的知识,希望对你有一定的参考价值。
KNN是最经典的机器学习算法之一。该算法既可以用于数据分类,也可以用于数据回归预测,其核心思路是在训练样本中寻找距离最接近待分类样本的K个样本。然后,如果目的是分类,则统计这K个样本中的各个类别数量,数量最多的类别即认为是待分类样本的类别;如果目的是回归预测,则计算这K个样本的平均值作为预测值。
图像识别,本质上也是数据分类,也即把每一张图像归类,因此KNN算法可以应用于图像识别。本文首先讲解KNN算法的原理,接着讲解Opencv中的KNN算法模块,然后再使用Opencv中的KNN算法模块对手写数字图像进行识别。
KNN算法主要包含以下几个要素:
1. 训练样本。训练样本就是预先准备好的数据集,该数据集必须包含所有可能的数据类别,而且数据集中的每个数据都有一个唯一的标签,用来标识该数据所属的类别。比如,待分类的图像有可能属于的类别包括鸟、狗、马、飞机、班车这5种类别,给5种类别依次编号0、1、2、3、4,那么训练样本必须包含这5种类别的图像,且训练样本中每一张图像都有一个范围在0~4之间的类别标签。
2. 待分类样本。也就是待分类的数据,比如一张图像,把该图像输入KNN算法之中,KNN算法对其进行分类,然后输出类别标签。
3. 样本距离。通常每一个样本都是一维向量的形式(二维、三维、多维数据都可以转换为一维向量)。衡量一维向量之间的距离,通常有欧式距离,余弦距离、汉明距离等,其中欧式距离又是最常用的距离度量方法。
假设样本A和样本B:
A=[a0 a1 a2 ... an]
B=[b0 b1 b2 ... bn]
那么样本A与样本B的欧式距离为:
4. K值。K值决定寻找训练样本中最接近待分类样本的样本个数,比如K值取5,那么对于每一个待分类样本,都从训练样本中寻找5个与其距离最接近的样本,然后统计这5个样本中各个类别的数量,数量最多的类别则认为是待分类样本的类别。K值没有固定的取值,通常在一开始取5~10,然后多尝试几次,根据识别的正确率来调整K值。
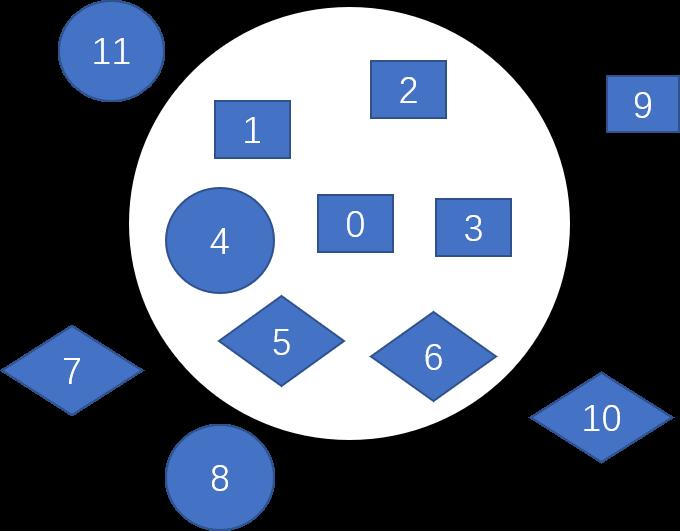
举一个简单的例子来说明KNN的分类思路,如下图所示,样本0为待分类样本,其可能的分类为矩形、圆形、菱形,取K=6,然后在所有训练样本中寻找与样本0最接近的6个样本:样本1、样本2、样本3、样本4、样本5、样本6。然后对这6个样本进行分类统计(每个训练样本是有标签的,所以知道其类别):3个矩形、2个菱形、1个圆形。矩形的数量最多,因此判定样本0为矩形。
讲完原理,下面我们开始讲Opencv3.4.1中KNN算法模块的应用。Opencv3.4.1中已经实现了该算法,并封装成类,我们只需要调用类的相关接口,并且把输入参数传入接口即可得到分类结果。调用接口的步骤如下:
1. 创建KNN类并设置参数。
const int K = 3; //取K值为3//创建KNN类cv::Ptr<cv::ml::KNearest> knn = cv::ml::KNearest::create();knn->setDefaultK(K); //设置KNN类的K值knn->setIsClassifier(true); //设置KNN用于分类knn->setAlgorithmType(cv::ml::KNearest::BRUTE_FORCE); //设置寻找距离最近的K个样本的方式为遍历所有训练样本,也即暴力破解的方式
2. 输入训练数据及其标签:
Mat traindata; //训练数据的矩阵Mat trainlabel; //训练数据的标签traindata.push_back(srcimage); //srcimage为Mat类型的1行n列的一维矩阵,将该矩阵保存到训练矩阵中trainlabel.push_back(i); //i为srcimage的标签,同时将i保存到标签矩阵中traindata.convertTo(traindata, CV_32F); //重要:训练矩阵必须是浮点型数据
3. 将训练数据与标签输入KNN模块中进行训练:
knn->train(traindata, cv::ml::ROW_SAMPLE, trainlabel);4. 训练之后,开始对待分类图像进行分类:
Mat result;//testdata为待分类图像,被转换为1行n列的浮点型数据//response为最终得到的分类标签= knn->findNearest(testdata, K, result);
下面,我们将Opencv的KNN模块应用于手写数字识别。在Opencv3.4.1的samples/data目录有一张1000*2000的手写数字图像,该图像包含了5000个20*20的小图像块,每个小图像块就是一个手写数字,如下图所示:

首先,我们写个程序把上图分割成5000个20*20的图像块。把相同的数字保存到同名文件夹中,比如数字0的小图像块保存到文件夹0中、数字1的小图像块保存到文件夹1中、数字2的小图像块保存到文件夹2中。
分割图像块的代码如下:
void read_digital_img(void){char ad[128] = { 0 };int filename = 0, filenum = 0;Mat img = imread("digits.png");Mat gray;cvtColor(img, gray, CV_BGR2GRAY);int b = 20;int m = gray.rows / b; //原图为1000*2000int n = gray.cols / b; //裁剪为5000个20*20的小图块for (int i = 0; i < m; i++){int offsetRow = i*b; //行上的偏移量if (i % 5 == 0 && i != 0) //原图中每5行存储相同数字,因此过了5行要递增文件名{filename++; //递增文件名filenum = 0; //清零文件计数器}for (int j = 0; j < n; j++){int offsetCol = j*b; //列上的偏移量sprintf_s(ad, "%d/%d.jpg", filename, filenum++);//截取20*20的小块Mat tmp;gray(Range(offsetRow, offsetRow + b), Range(offsetCol, offsetCol + b)).copyTo(tmp);imwrite(ad, tmp); //将对应的数字图像块保存到对应名字的文件夹中}}}
运行上述代码之后,从0~9的文件夹都保存有对应数字的小图像块啦~不同数字的小图像块如下图所示。这时我们有0~9这10个文件夹,每个文件夹都有对应数字的500张小图像块,比如文件夹0中有500张不同手写风格的0数字图像。

下面我们使用每个文件夹下前400张图像作为训练图像,对KNN模型进行训练,然后使用该KNN模型对每个文件夹下后100张图像进行分类,并统计分类结果的准确率。
上代码:
void KNN_test(void){char ad[128] = { 0 };int testnum = 0, truenum = 0;const int K = 3; //设置K值为3cv::Ptr<cv::ml::KNearest> knn = cv::ml::KNearest::create(); //创建KNN类knn->setDefaultK(K);knn->setIsClassifier(true); //设置KNN用于分类knn->setAlgorithmType(cv::ml::KNearest::BRUTE_FORCE); //设置寻找距离最近的K个样本的方式为遍历所有训练样本,也即暴力破解的方式Mat traindata, trainlabel;for (int i = 0; i < 10; i++){for (int j = 0; j < 400; j++){sprintf_s(ad, "%d/%d.jpg", i, j);Mat srcimage = imread(ad);//把二维数据转换为一维数据srcimage = srcimage.reshape(1, 1); //Mat Mat::reshape(int cn, int rows = 0),cn表示通道数,为0则通道不变,rows表示矩阵行数traindata.push_back(srcimage); //srcimage为Mat类型的1行n列的一维矩阵,将该矩阵保存到训练矩阵中trainlabel.push_back(i); //i为srcimage的标签,同时将i保存到标签矩阵中}}traindata.convertTo(traindata, CV_32F); //重要:训练矩阵必须是浮点型数据knn->train(traindata, cv::ml::ROW_SAMPLE, trainlabel); //导入训练数据和标签for (int i = 0; i < 10; i++) //标签{for (int j = 400; j < 500; j++){testnum++; //统计总的分类次数sprintf_s(ad, "%d/%d.jpg", i, j);Mat testdata = imread(ad);testdata = testdata.reshape(1, 1); //将二维数据转换成一维数据testdata.convertTo(testdata, CV_32F); //将数据转换成浮点数据Mat result;int response = knn->findNearest(testdata, K, result); //寻找K个最邻近样本,并统计K个样本的分类数量,返回数量最多的分类的标签if (response == i) //如果得到的分类标签与真实标签一致,则分类正确{truenum++;}}}cout << "测试总数" << testnum << endl;cout << "正确分类数" << truenum << endl;cout << "准确率:" << (float)truenum / testnum * 100 << "%" << endl;}
运行上述代码,得到结果如下,可以看到,KNN算法对手写数字图像的识别(分类)的准确率还是比较高的。
由于手写数字图像包含的特征比较简单,因此KNN的识别准确率很高。实际上,对于一些复杂的图像,KNN的识别准确率是很低的。在下一篇文章中,我们将尝试使用KNN算法来识别更复杂的图像,并想办法提高识别的准确率,敬请期待!
以上是关于图像识别之KNN算法的理解与应用的主要内容,如果未能解决你的问题,请参考以下文章