图像识别与文本分类下
Posted 梓栋Code
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了图像识别与文本分类下相关的知识,希望对你有一定的参考价值。
1
介绍文本数据处理
在人工智能出现之前,人工智能处理结构化的数据(例如 Excel 里的数据)但是实际生活中大部分的数据都是非结构化的,例如:文章、图片、音频、视频在非结构数据中,文本的数量是最多的,他虽然没有图片和视频占用的空间大,但是他的信息量是最大的。为了能够分析和利用这些文本信息,我们就需要利用 NLP 技术,让机器理解这些文本信息,并加以利用。
每种动物都有自己的语言,机器也是!不同的语言之间是无法沟通的,比如说人类就无法听懂狗叫,甚至不同语言的人类之间都无法直接交流,需要翻译才能交流。那 NLP 就是人类和机器之间沟通的桥梁! 自然语言处理(NLP)就是在机器语言和人类语言之间沟通的桥梁,以实现人机交流的目的。人类通过语言来交流,狗通过汪汪叫来交流。机器也有自己的交流方式,那就是数字信息。
解决文本问题的难点:
语言是没有规律的,或者说规律是错综复杂的。
语言是可以自由组合的,可以组合复杂的语言表达。
语言是一个开放集合,我们可以任意的发明创造一些新的表达方式。
语言需要联系到实践知识,有一定的知识依赖。
语言的使用要基于环境和上下文。
英文示例:
Scientists study apple from space.(科学家在太空研究苹果 VS 科学家研究从太空来的苹果)
中文示例:下雨天留客天留我不留
下雨天留客, 天留, 我不留
下雨天, 留客, 天留, 我不留
下雨天, 留客, 天留我, 不留
下雨天, 留客天, 留我不留?
下雨天, 留客天, 留我?不留!
下雨天, 留客! 天! 留我不留?
下雨天留客, 天! 留我不?留!
...
2
词向量
无论是是机器学习还是深度学习在处理不同任务时都需要对 对象 进行向量化表示 词向量(Word Vector)或者词嵌入(Word Embedding)做的事情就是将词表中的单词映射为实数向量。
2.1 基于one-hot编码的词向量方法(离散式表示)
设计一个包含所有词的词表对每个词进行编号假设词表的长度为 n,则对于每一个词的表征向量均为一个 n 维向量,且只在其对应位置上的值为1,其他位置都是0。示例:
“话筒”表示为 [0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 ...]
“麦克”表示为 [0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 ...]
每个词都是茫茫 0 海中的一个 1。
这种词表示有两个缺点:
有序性问题:它无法反映文本的有序性。因为语言并不是一个完全无序的随机序列。比如说,一个字之后只有接特定的字还能组成一个有意义的词,特定的一系列词按特定的顺序组合在一起才能组成一个有意义的句子。
不能很好地刻画词与词之间的相似性:任意两个词之间都是孤立的。光从这两个向量中看不出两个词是否有关系,哪怕是话筒和麦克这样的同义词也不能幸免于难。
容易受维数灾难的困扰,高维情形下将导致数据样本稀疏,距离计算困难,这对模型的负担是很重的。
2.2 词嵌入(分布式表示)
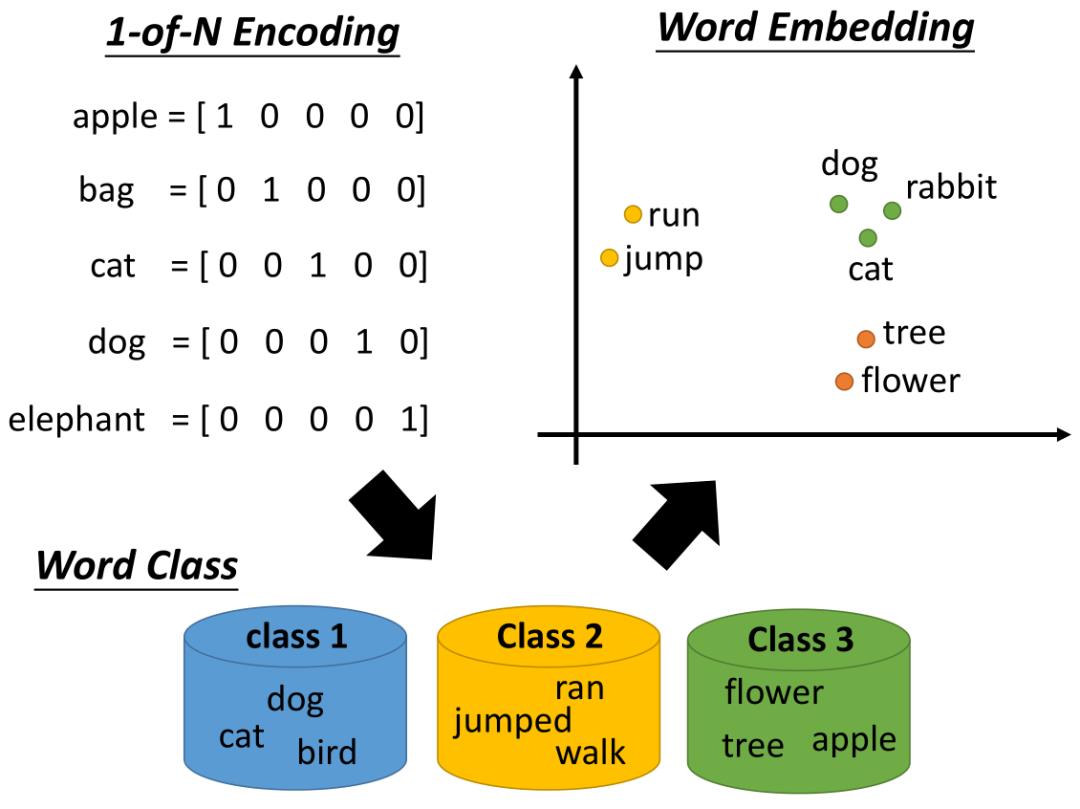
理论基础:上下文相似的词,其语义也相似。用低维向量来表示词义,为每种单词类型构建一个密集的向量(如下),以使其能够 很好地预测上下文中出现的其他单词
这种向量一般长成这个样子:[0.792, −0.177, −0.107, 0.109, −0.542, ...],也就是普通的向量表示形式。维度以 50 维和 100 维比较常见。
3
文本提取量
作用:对文本数据进行特征值化
sklearn.feature_extraction.text.CountVectorizer(stop_words=[])
返回词频矩阵
CountVectorizer.fit_transform(X) X:文本或者包含文本字符串的可迭代对象 返回值:返回sparse矩阵
CountVectorizer.inverse_transform(X) X:array数组或者sparse矩阵 返回值:转换之前数据格
CountVectorizer.get_feature_names() 返回值:单词列表
from sklearn.feature_extraction.text import CountVectorizer
data = ["life is short,i like like python", "life is too long,i dislike python"]
# 1、实例化一个转换器类
transfer = CountVectorizer()
# 2、调用fit_transform
data = transfer.fit_transform(data)
print("文本特征抽取的结果:
", data.toarray())
print("返回特征名字:
", transfer.get_feature_names())
3.1 如果我们将数据替换成中文?
from sklearn.feature_extraction.text import CountVectorizer
data = ["人生苦短,我喜欢Python", "生活太长久,我不喜欢Python"]
# 1、实例化一个转换器类
transfer = CountVectorizer()
# 2、调用fit_transform
data = transfer.fit_transform(data)
print("文本特征抽取的结果:
", data.toarray())
print("返回特征名字:
", transfer.get_feature_names())
3.2 jieba分词处理
import jieba
data = ["一种还是一种今天很残酷,明天更残酷,后天很美好,但绝对大部分是死在明天晚上,所以每个人不要放弃今天。",
"我们看到的从很远星系来的光是在几百万年之前发出的,这样当我们看到宇宙时,我们是在看它的过去。",
"如果只用一种方式了解某样事物,你就不会真正了解它。了解事物真正含义的秘密取决于如何将其与我们所了解的事物相联系。"]
# 将原始数据转换成分好词的形式
text_list = []
for sent in data:
cut_word = " ".join(list(jieba.cut(sent)))
text_list.append(cut_word)
print(text_list)
# 1、实例化一个转换器类
transfer = CountVectorizer()
# 2、调用fit_transform
data = transfer.fit_transform(text_list)
print("文本特征抽取的结果:
", data.toarray())
print("返回特征名字:
", transfer.get_feature_names())
3.3 Tf-idf文本特征提取
TF-IDF的主要思想是: 如果某个词或短语在一篇文章中出现的概率高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类TF-IDF作用:用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。
词频(term frequency,tf)指的是某一个给定的词语在该文件中出现的频率逆向文档频率(inverse document frequency,idf) 是一个词语普遍重要性的度量。某一特定词语的idf,可以由总文件数目除以包含该词语之文件的数目,再将得到的商取以10为底的对数得到
假如一篇文件的总词语数是100个
词语"非常"出现了5次,那么"非常"一词在该文件中的词频就是5/100=0.05。
计算文件频率(IDF)的方法是以文件集的文件总数,除以出现"非常"一词的文件数。
如果"非常"一词在 1,000 份文件出现过,而文件总数是 10,000,000 份的话,其逆向文件频率就是lg(10,000,000 / 1,0000)=3。
最后"非常"对于这篇文档的tf-idf的分数为 0.05 * 3=0.15
from sklearn.feature_extraction.text import TfidfVectorizer
import jieba
data = ["一种还是一种今天很残酷,明天更残酷,后天很美好,但绝对大部分是死在明天晚上,所以每个人不要放弃今天。",
"我们看到的从很远星系来的光是在几百万年之前发出的,这样当我们看到宇宙时,我们是在看它的过去。",
"如果只用一种方式了解某样事物,你就不会真正了解它。了解事物真正含义的秘密取决于如何将其与我们所了解的事物相联系。"]
# 将原始数据转换成分好词的形式
text_list = []
for sent in data:
cut_word = " ".join(list(jieba.cut(sent)))
text_list.append(cut_word)
print(text_list)
# 1、实例化一个转换器类
# transfer = CountVectorizer(sparse=False)
transfer = TfidfVectorizer(stop_words=['一种', '不会', '不要'])
# 2、调用fit_transform
data = transfer.fit_transform(text_list)
print("文本特征抽取的结果:
", data.toarray())
print("返回特征名字:
", transfer.get_feature_names())
4
项目实战
4.1 获取数据
该数据集名为 “Twenty Newsgroups” 。下面是这个数据集的官方介绍, 引自 网站:
Twenty Newsgroups 数据集是一个包括近 20,000 个新闻组文档的集合,(几乎)平均分成了 20 个不同新闻组。这 20 个新闻组集合已成为一个流行的数据集,用于机器学习中的文本应用的试验中,如文本分类和文本聚类。接下来我们会使用 scikit-learn 中的这个内置数据集加载器来加载这 20 个新闻组。或者,您也可以手动从网站上下载数据集,使用 sklearn.datasets.load_files 功能,并将其指向未压缩文件夹下的 20news-bydate-train 子文件夹。
数据集网址:http://www.cs.cmu.edu/afs/cs.cmu.edu/project/theo-20/www/data/news20.html
path = './datasets/5f983d133f8cc74de01353b5-momodel/20_newsgroup'
from sklearn import datasets
twenty_train = datasets.load_files(path,categories=categories)
# print(twenty_train)
print('加载完成!!!')
sklearn.datasets.load_files(container_path, description=None, categories=None, load_content=True, shuffle=True, encoding=None, decode_error='strict', random_state=0)
container_path: container_folder的路径;
load_content = True: 是否把文件中的内容加载到内存;
encoding = None: 编码方式。当前文本文件的编码方式一般为“utf-8”,如果不指明编码方式(encoding=None),那么文件内容将会按照bytes处理,而不是unicode处理。返回值:Bunch Dictionary-like object.主要属性有
data: 原始数据;
filenames: 每个文件的名字;
target: 类别标签(从0开始的整数索引);
target_names: 类别标签的具体含义(由子文件夹的名字category_1_folder等决定
from time import time
from sklearn.datasets import fetch_20newsgroups#引入新闻数据包
### 数据加载
print (u'加载数据...')
t_start = time()
## 不要头部信息
remove = ('headers', 'footers', 'quotes')
## 只要这四类数据
categories = 'alt.atheism', 'talk.religion.misc', 'comp.graphics', 'sci.space'
## 分别加载训练数据和测试数据
data_train = fetch_20newsgroups(data_home='./datas/',subset='train', categories=categories, shuffle=True, random_state=0, remove=remove)
data_test = fetch_20newsgroups(data_home='./datas/',subset='test', categories=categories, shuffle=True, random_state=0, remove=remove)
## 完成
print (u"完成数据加载过程.耗时:%.3fs" % (time() - t_start))
4.2 获取数据信息
data_train.keys()
data_train.target_names
data_train.data[0]
这些文件本身被读进内存的 data 属性中。另外,这些文件名称也可以容易获取到:
len(data_train.data)
监督学习需要让训练集中的每个文档对应一个类别标签。类别是每个新闻组的名称,也刚好是每个储存文本文件的文件夹的名称。
由于速度和空间上效率的原因 scikit-learn 加载目标属性为一个整型数列, 它与 target_names 列表中类别名称的 index(索引)相对应。每个样本的类别的整数型 id 存放在 target 属性中:
data_train.target[:10]
也可以通过如下方式取得类别名称:
for t in data_train.target[:10]:
print(data_train.target_names[t])
4.3 划分数据集
### 数据重命名
x_train = data_train.data
y_train = data_train.target
x_test = data_test.data
y_test = data_test.target
print('训练集的数量:',len(x_train))
print('测试集的数量:',len(y_test))
### 输出前 5个样本
print (u' -- 前5个文本 -- ')
for i in range(5):
print (u'文本%d(属于类别 - %s):' % (i+1, categories[y_train[i]]))
print (x_train[i])
print ('
')
4.4 数据处理
import numpy as np
from sklearn.feature_extraction.text import TfidfVectorizer #做 tfidf 编码
# 要求输入的数据类型必须是 list,list 中的每条数据,单词是以空格分割开的
vectorizer = TfidfVectorizer(input='content', stop_words='english', max_df=0.5, sublinear_tf=True)
x_train = vectorizer.fit_transform(data_train.data) # x_train是稀疏的,scipy.sparse.csr.csr_matrix
x_test = vectorizer.transform(data_test.data)
print (u'训练集样本个数:%d,特征个数:%d' % x_train.shape)
print (u'停止词:
')
print(vectorizer.get_stop_words())
## 获取最终的特征属性名称
feature_names = np.asarray(vectorizer.get_feature_names())
feature_names[20000:20010]
4.5 特征选择
## 特征选择
from sklearn.feature_selection import SelectKBest,chi2
ch2 = SelectKBest(chi2, k=1000)
x_train = ch2.fit_transform(x_train, y_train)
x_test = ch2.transform(x_test)
feature_names = [feature_names[i] for i in ch2.get_support(indices=True)]
feature_names[100:110]
4.6 训练模型
from sklearn.naive_bayes import MultinomialNB, BernoulliNB #引入多项式和伯努利的贝叶斯
model = MultinomialNB()
model.fit(x_train, y_train)
4.7 评估模型
from sklearn import metrics
## 模型效果评估
y_hat = model.predict(x_test)
train_acc = metrics.accuracy_score(y_train, model.predict(x_train))
test_acc = metrics.accuracy_score(y_test, y_hat)
print (u'训练集准确率:%.2f%%' % (100 * train_acc))
print (u'测试集准确率:%.2f%%' % (100 * test_acc))
实验报告
print(metrics.classification_report(y_test, y_hat, target_names = data_train.target_names))

以上是关于图像识别与文本分类下的主要内容,如果未能解决你的问题,请参考以下文章