Python中验证码识别的三种解决方案
Posted 吾非同
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python中验证码识别的三种解决方案相关的知识,希望对你有一定的参考价值。
在Python爬虫过程中,有些网站需要验证码通过后方可进入网页,目的很简单,就是区分是人阅读访问还是机器爬虫。验证码问题看似简单,想做到准确率很高,也是一件不容易的事情。为了更好学习爬虫,后续推文中将会更多介绍爬虫问题的解决方案。本篇推文将分享三种解决验证码的方法,如果你有比较好的方案,欢迎留言区讨论交流,共同进步。
1.pytesseract
pytesseract是google做的ocr库,可以识别图片中的文字,一般用在爬虫登录时验证码的识别,在安装pytesseract环境过程中会遇到各种坑的事情,如果你需要安装,可以按照如下流程去做,避免踩坑。下面以 mac为例。
1.安装方法
pip install pytesseract
2.此外,还需安装Tesseract,它是一个开源的OCR引擎,能识别100多种语言。
brew install tesseract
3.查看安装位置为
brew list tesseract
/usr/local/Cellar/tesseract/4.1.1/bin/tesseract
/usr/local/Cellar/tesseract/4.1.1/include/tesseract/ (19 files)
/usr/local/Cellar/tesseract/4.1.1/lib/libtesseract.4.dylib
/usr/local/Cellar/tesseract/4.1.1/lib/pkgconfig/tesseract.pc
/usr/local/Cellar/tesseract/4.1.1/lib/ (2 other files)
/usr/local/Cellar/tesseract/4.1.1/share/tessdata/ (35 files)
4.配置环境变量
export TESSDATA_PREFIX=/usr/local/Cellar/tesseract/4.1.1/share/tessdata
export PATH=$PATH:$TESSDATA_PREFIX
5.如何出现如下报错
'TesseractNotFoundError: tesseract is not installed or it's not in your PATH'
6.修改pytesseract.py的cmd
'tesseract_cmd = '/usr/local/Cellar/tesseract/4.1.1/bin/tesseract''
先验证一个简单的验证码
代码如下
from PIL import Image,ImageFilter
import pytesseract
path ='/Users/****/***.jpg'
captcha = Image.open(path)
result = pytesseract.image_to_string(captcha)
print(result)
结果输出
51188
再换一张试一下

输入代码后,结果错误输出为
1364
由此看出,pytesseract对于简单方法有效,并不像有些人写的这么好,当然可以通过灰度、二值等方法,效果并不是很理想,稍微复杂的需要寻找其他解决方案,如果解决上述问题呢,我们看下面的解决方案。
2.百度OCR接口
调用百度OCR接口(代码示例)
# encoding:utf-8
import requests
import base64
'''
通用文字识别(高精度版)
'''
request_url = "https://aip.baidubce.com/rest/2.0/ocr/v1/accurate_basic"
# 二进制方式打开图片文件
f = open('[本地文件]', 'rb')
img = base64.b64encode(f.read())
params = {"image":img}
access_token = '[调用鉴权接口获取的token]'
request_url = request_url + "?access_token=" + access_token
headers = {'content-type': 'application/x-www-form-urlencoded'}
response = requests.post(request_url, data=params, headers=headers)
if response:
print (response.json())
上述方案没解决的问题,调用此方法试一下,可以顺利解决。
7364
那么对于更复杂的验证码呢?

首先直接调用结果输出
Ygax6-
结果把干扰线识别出来Y和-,可以看出百度OCR接口对复杂验证码能识别,但是对干扰线的问题,无法解决。如何解决上述问题呢?对于复杂的验证码,我们是不能直接调用,我们先做一些预处理:灰度、二值化等。
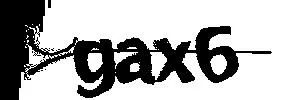
再次调用接口
gax6
上述问题得到了解决。对于超级变态的验证码如何解决呢?几个0?几个O?下面提供一种深度学习解决方案。

3.深度学习
深度学习验证码识别可能并不适合所有人,原因很简单,首先不是每个人都有算法基础。其次小编亲自测试来一下,cpu资源的消耗也非常高,如果你有云端资源可以跑一下。深度学习的验证码识别,我这边介绍一下解决方案的思路,目前企业级的验证识别更为复杂。
1.搭建基于keras框架的深度学习模型
from keras.models import *
from keras.layers import *
input_tensor = Input((height, width, 3))
x = input_tensor
for i in range(4):
x = Convolution2D(32*2**i, 3, 3, activation='relu')(x)
x = Convolution2D(32*2**i, 3, 3, activation='relu')(x)
x = MaxPooling2D((2, 2))(x)
x = Flatten()(x)
x = Dropout(0.25)(x)
x = [Dense(n_class, activation='softmax', name='c%d'%(i+1))(x) for i in range(4)]
model = Model(input=input_tensor, output=x)
model.compile(loss='categorical_crossentropy',
optimizer='adadelta',
metrics=['accuracy'])
2.模型训练
model.fit_generator(gen(), samples_per_epoch=51200, nb_epoch=5,
nb_worker=2, pickle_safe=True,
validation_data=gen(), nb_val_samples=1280)
3.测试模型
X, y = next(gen(1))
y_pred = model.predict(X)
plt.title('real: %s
pred:%s'%(decode(y), decode(y_pred)))
plt.imshow(X[0], cmap='gray')
4.结果展示
结论
验证码识别问题正如推文开头所说,看似简单,实际上远比想象的要复杂的多。
以上是关于Python中验证码识别的三种解决方案的主要内容,如果未能解决你的问题,请参考以下文章