解读Go语言的2018:怎么就在中国火成这样了?
Posted InfoQ
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了解读Go语言的2018:怎么就在中国火成这样了?相关的知识,希望对你有一定的参考价值。
今年真可谓是不平静的一年,前有人工智能国家级战略的发布,行业已经在大跨步的挺进,但人才缺口每天都在扩大;后有区块链技术从爆发式增长到大幅回落,无数程序员蜂拥而至,又在现如今变得手足无措。
那么,Go 语言在 2018 年这一年发展得又如何呢?它的下一步又将会怎样?且听笔者细细道来。
首先,笔者要说的是,在 TIOBE 于 2018 年 11 月份公布的编程语言排行榜中,Go 语言已然挤到了前 10 的位置。虽然这与去年同期的第 14 位看起来相差不大,但却是一个里程碑式的进步。
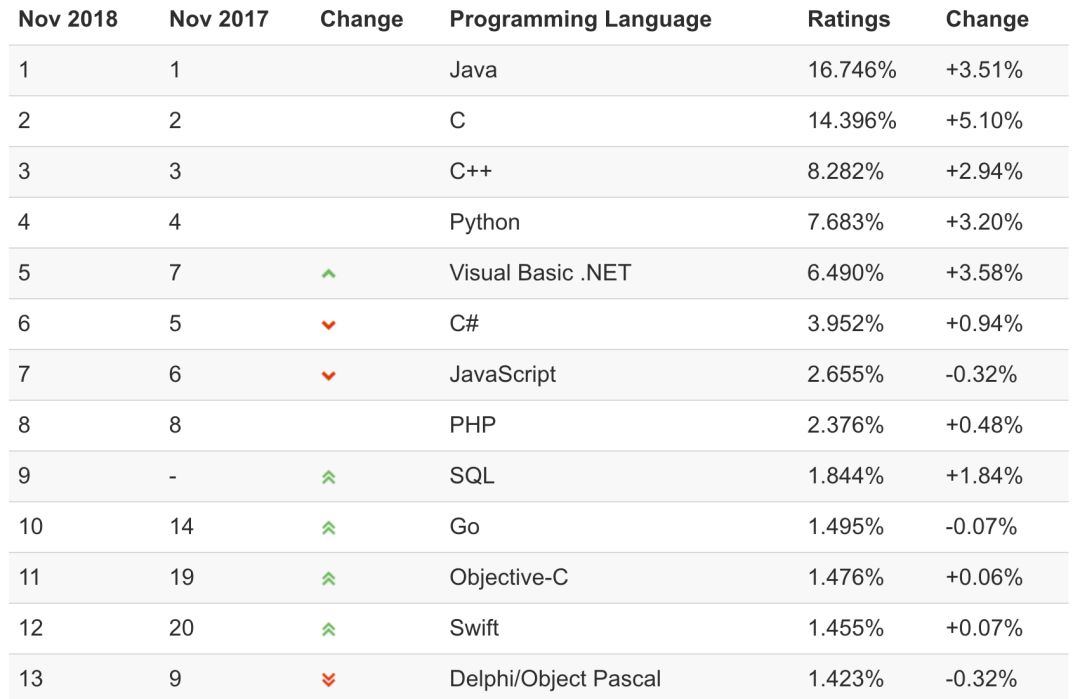
图 1:TIOBE Index for Nov 2018
从 Google Trends 提供的流行趋势统计来看,在过去的 12 个月里,Go 语言的流行也是持续升温的。
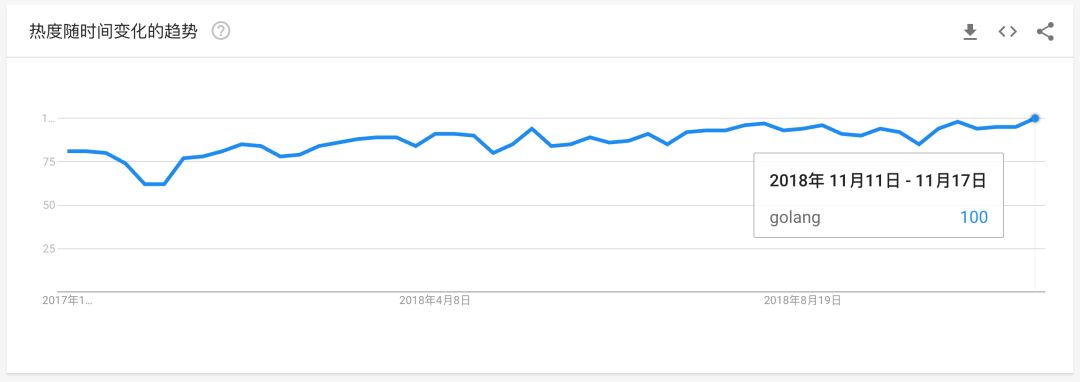
图 2: Google Trends - Golang 热度随时间变化的趋势
这种升温虽然并不算快,但是很持久。这对编程语言的生态环境和人才的发展是非常有利的。
此外,完全不出乎我们的意料:中国依然是 Go 语言爱好者最多的国家,没有之一。
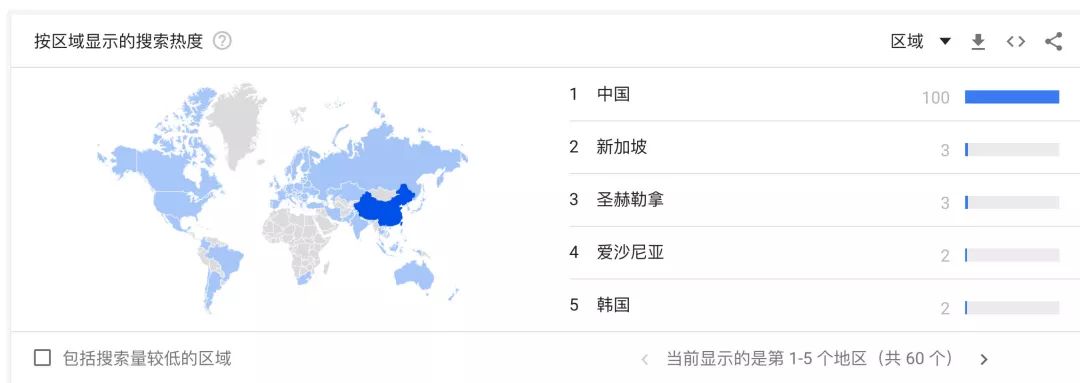
图 3: Google Trends - Golang 按区域显示的搜索热度
具有讽刺意味的是,作为 Go 语言诞生地的美国,仅排在了第 15 位。我们对先进技术和前沿科技的热衷绝对是不输他国的。下面,让我们再把尺度缩小到城市级别。
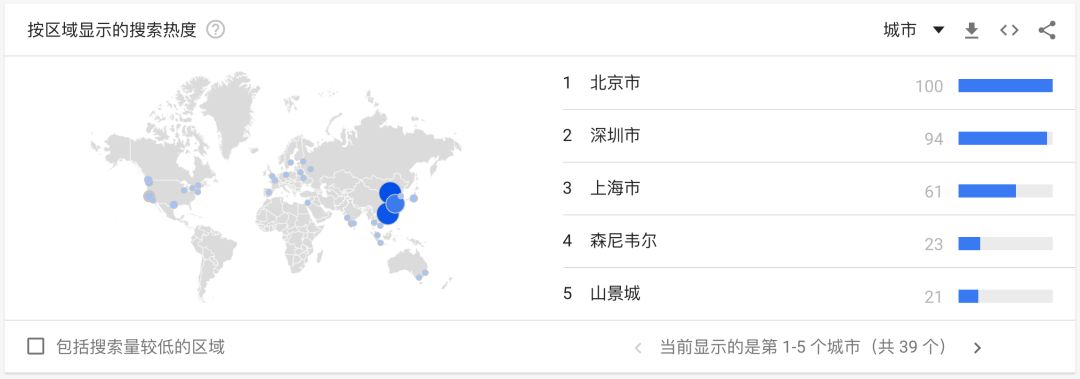
图 4 :Google Trends - Golang 按区域显示的搜索热度(城市)
显然,在我国,北京、深圳、上海这三个城市聚集了非常多的 Go 语言程序员和工程师。尤其是北京,简直是 Go 语言爱好者的圣地啊!
至于北京博得头筹的原因,据笔者观察,首先肯定是:在北京的互联网公司很多,起码明显多于其他的一、二线城市。Go 语言如今在互联网公司中非常流行,即使有的公司高层并没有批准大规模地使用 Go 语言,但是工程师们都在做积极的尝试。
其次,北京做云计算的公司很多,不论是面向市场的公有云还是自建自用的私有云。说到云计算,我们就不得不提及开放平台技术、容器技术、集群管理技术,以及现在很火热的微服务(Microservices)和 Serverless 技术,等等。而这些,恰恰都是 Go 语言的专长。在这些方面,有很多成熟的基于 Go 语言的解决方案可供选择。
再次,北京的高科技创业公司非常多。他们往往没有历史包袱、勇于创造和尝试。在做技术选型的时候,他们也更容易选择 Go 语言。因为,Go 语言既拥有编译型编程语言固有的高运行效率,又具有解释型编程语言常有的高开发效率。而且,Go 语言还不像有些编程语言那样时不时地出现内斗、分裂等混乱情况,当然也没有无良的技术持有者吵闹着要对编程语言的商用进行收费。
Go 语言在语言规范的发展、版本的迭代和开发者生态的建设方面都非常的稳定,并有着良好的包容性和兼容性。保持简单、面向契约和利于协作是 Go 语言最突出的设计哲学。无论是做软件原型,还是用于小团队作战,又或是进行大规模的研发,Go 语言都会是很不错的选择。
最后,很多喜爱 Go 语言、致力于推广 Go 语言技术的个人开发者、技术团队、互联网公司以及知识服务厂商也都在北京。这都直接或间接地导致了 Go 语言在这座城市的流行。
好了,到这里,笔者相信你已经对 Go 语言在中国的流行有了一定的了解。下面,我们再来说说 Go 语言在 2018 年具体都有哪些进展。
首先说一下,关于 Go 语言在 2018 年之前的具体进展,笔者推荐你去看这几篇同系列文章,如下:
Go 语言官方团队在 2018 年 2 月正式发布它的 1.10 版本。不同于其他很多被称为版本帝的编程语言,到了这样一个版本号 10,Go 1 在语言规范方面已经几乎没有什么改动了,一些语法上的小小增强也并不值得我们特别关注。而在 2018 年 8 月发布的 Go 1.11 更是没有任何语言规范方面的变动。
Go 语言对于本身的向后兼容性保持得非常好,高版本对低版本中的语言语法、工具和标准库都不会有任何破坏。然而,Go 语言在其支持的操作系统方面还是很大刀阔斧的。这体现在,Go 1.10 不再支持 10.3 以下版本的 FreeBSD 和 8.0 以下版本的 NetBSD。并且,这个版本也是支持 OpenBSD 6.0、OS X 10.9 以及 Windows XP 和 Windows Vista 的最后一个版本。在这些操作系统之上编写或运行 Go 语言程序的开发者们要注意。
使用过 Go 语言的开发者们都知道,当把 Go 语言的预编译包解压到某个目录后,我们还需要至少设置两个环境变量——GOROOT 和 GOPATH。前者代表直接包含 Go 语言本身的那个目录路径,而后者则用于指定可放置第三方库和自有代码的工作区(或者说工作目录)的路径。
一个好消息是,自 Go 语言的 1.10 版本起,GOROOT 这个环境变量就没有必要设置了。如果我们不设置它,那么 Go 的标准工具会尝试以自身所在的目录为基础,自动地推断出 GOROOT 应该指向的目录路径。
另外,从这个版本开始,我们可以自行地设定 Go 语言的临时目录路径了,设定的途径是设置环境变量 GOTMPDIR。Go 语言的临时目录主要用于存放 Go 工具在编译或测试程序时产生的各种临时文件。在这之前,这些临时文件都会被存放到固定的地方,此地的具体路径会根据操作系统的不同而不同,一般会位于操作系统的临时目录的某个子目录下。自定义这个目录的好处在于,可以让我们方便地观察编译过程,并查看编译或测试的中间结果。
说到编译,笔者一定要提一下 1.10 版本的另一项改进,这与 go build 命令有关。以前,如果我们要强行地重新构建所有相关的代码包,那么就需要在运行这个命令的时候追加标记“-a”。而现在,我们无需这样做了。go build 命令会根据源码文件内容、构建标记和编译元数据,自动地决定什么时候应该重新构建那些代码包。这项工作再也不需要人工干预了。
与此项改进相关的变化是,go build 命令现在总是会把最近的构建结果缓存起来,以便在将来的构建中重用。我们可以通过运行 go env GOCACHE 命令来查看缓存目录的路径。缓存的数据总是能够正确地反映出当时的源码文件、构建环境和编译器选项等的真实情况。一旦有任何变动,缓存数据就会失效,go build 命令就会再次真正地执行构建。因此,我们并不用担心缓存数据体现的不是实时的结果。实际上,这正是上述改进能够有效的主要原因。go build 命令会定期地删除最近未使用的缓存数据,但如果你想手动删除所有的缓存数据,运行一下 go clean -cache 命令就好了。
顺便说一下,对于测试成功的结果,go 命令也是会缓存的。运行 go clean -testcache 命令将会删除掉所有的测试结果缓存。不过别担心,这样做肯定不会删除任何的构建结果缓存,它们是两码事。
此外,设置环境变量 GODEBUG 的值也可以稍稍地改变 go 命令的缓存行为。比如,设置值为 gocacheverify=1 将会导致 go 命令绕过任何的缓存数据,而真正地执行操作并重新生成所有结果,然后再去检查新的结果与现有的缓存数据是否一致。
再来说 go install 命令。现在,go install 命令在默认情况下只会去安装我们明确指定的那些代码包。这些代码包依赖的那些包并不会被安装。这同样得益于构建结果缓存,它可以使安装的速度得到明显的提升。如果你想要强制地安装依赖包,那么请在运行命令的时候追加“-i”标记。
前面我们说过了,测试成功的结果也会被缓存。如果 go test 命令确定可以使用被缓存的结果,那么它打印出的内容也会出自于缓存。这时,被打印的内容中会包含“(cached)”字样。
另外,go test 命令现在会自动地运行 go vet 命令,以便在真正运行测试之前识别出一些程序编写方面的问题。我们都知道,go vet 命令用于对 Go 语言源码进行静态检查,并报告已发现的可疑问题。这些问题一般都是符合语法规则的,因此编译器无法查出它们。但是,它们很有可能代表了对某些程序实体(或者说 API)的错误使用。虽然 go vet 命令有时候并不能保证它报告的每一个问题都是真正的问题,但它却可以给予我们一份重要的参考,以便让我们在编程的过程中小心行事。
与 Go 语言提供的很多高级功能一样,我们也可以阻止 go test 命令自动运行 go vet 命令,这需要在运行前者的时候追加“-vet=off”这个标记。
最后,关于 go test 命令,还有两个值得注意的新标记——“-failfast”和“-json”。顾名思义,“-failfast”标记可以让 go test 命令一旦发现有测试失败的情况就立即忽略掉剩余的测试并终止运行。不过要注意,如果存在与失败的测试并发进行的测试的话,那么后者还是会继续运行直至完成的。“-json”标记对于程序测试的自动化大有裨益。它会让 go test 命令产生 JSON 格式的测试报告,这使得其他程序很容易读入和处理。
关于程序文档,只有一点需要我们注意。Go 1.11 是 godoc 命令支持命令行接口的最后一个版本。** 在未来的版本中,我们运行 godoc 命令的时候,它会启动一个 Web 服务器,以便让我们直接进入图形化界面进行文档查询。
现在,runtime/pprof 代码包中的 Lookup 函数已经支持了更加多样的参数值。这就意味着,Go 语言的程序性能分析现在可以生成和解读更多视角下的分析报告了。我们可以把这样的分析报告包含的内容叫做程序性能概要信息(简称概要信息),并把存储这些分析报告的文件叫做概要文件。
Lookup 函数可以生成的概要信息目前共有 6 种。这 6 种概要信息分别由字符串类型的参数值 goroutine、heap、allocs、threadcreate、block 和 mutex 代表。下面是它们代表的含义:
goroutine:收集当前正在使用的所有 goroutine 的堆栈跟踪信息。
heap:收集与堆内存的分配和释放有关的采样信息,默认以在用空间(inuse_space)的视角呈现。
allocs:同样收集与堆内存的分配和释放有关的采样信息,但默认以已分配空间(alloc_space)的视角呈现。
threadcreate:收集一些特定的堆栈跟踪信息,其中的调用链上的代码都导致了新的操作系统线程的产生。
block:收集因争用同步原语而被阻塞的那些代码的堆栈跟踪信息。
mutex:曾经作为同步原语持有者的那些代码的堆栈跟踪信息。
另外,在用空间和已分配空间的区别是,前者指的是已经分配但还没有被回收的空间,而后者只关注分配出的空间,不论它们是否已经被回收。
注意,如果我们在运行 go test 命令的时候追加了标记“-memprofile”,那么该命令会通过底层的 API 以 allocs 为视角生成概要信息和概要文件。这相当于对从测试开始时的所有已分配字节进行记录,包含已经被垃圾回收器收回的那些字节。在 Go 1.11 版本之前,go test 命令在这种情况下采用的是 heap 视角。
最后,go tool pprof 工具已经可以正确地单独读取和处理所有种类的概要文件了。这得益于,从 Go 1.10 版本开始,block 和 mutex 视角下的概要信息已经完善。在这之前,我们使用 go tool pprof 查阅这两种概要文件的时候,还不得不同时指定相应程序的二进制文件。
需要特别注意,runtime 代码包中的 LockOSThread 函数和 UnlockOSThread 函数的行为已经发生了变化。我们都知道,前一个函数的功能是将当前的 goroutine 与那一时刻正在承载这个 goroutine 运行的操作系统线程进行绑定。在绑定之后,这个 goroutine 就只能由该操作系统线程运行了,反之,该操作系统线程也只能运行这一个 goroutine 了。显而易见,runtime. UnlockOSThread 函数的功能是解除上述绑定关系。当然了,这两个函数都只能作用于它们被调用时所在的那个 goroutine。
以前,runtime. LockOSThread 函数是幂等的。也就是说,无论我们在同一个 goroutine 中调用了它多少次,都只相当于调用了一次。另一方面,只要我们调用一次 runtime. UnlockOSThread 函数,就总是能够解除针对于当前 goroutine 的这种绑定。
但是,从 Go 语言的 1.10 版本开始,在我们想要完全解除绑定的时候,可能就需要调用多次 runtime. UnlockOSThread 函数才能够实现了。至于具体需要调用多少次完全取决于,当初在同一个 goroutine 中调用 runtime. LockOSThread 函数的次数。换句话说,只有进行相同次数的函数调用,才能让当前 goroutine 与某个操作系统线程之间的绑定关系完全解除。我们可以把现在的这种对应关系理解为是基于嵌套的,可以想象一下:当初包装了多少层纸箱,现在就要拆开多少层纸箱。
其实一直以来,有很多第三方 Go 语言库的作者都误以为对于这两个函数的调用就是基于嵌套关系的。不过无论怎样,我们现在都应该仔细检查代码并小心的应对了。
笔者认为,如果你确实需要进行这种绑定,那么就应该基于这两个函数封装一个数据结构。在这个数据结构中,至少应该包含一个用于记录调用 runtime. LockOSThread 函数次数的字段,以方便后续的解绑操作。
在 2018 年,对于 Go 语言的运行时系统来说,我们可以轻易感知到的变化基本上只有这一个。不过,非常多的改进和优化都在悄无声息的进行着,有的已经完成了,而有的还在进展之中。已完成的改进如:在通常情况下,我们传递给 runtime.GOMAXPROCS 函数的参数值已经不再受限了,只要它在 int32 类型可容纳的范围之内就可以。
在 Go 语言的 1.10 和 1.11 这两个版本中,官方团队与社区开发者们一起对标准库做了大量的改进。可喜可贺,社区开发者对 Go 语言的贡献次数现在已经超过官方团队了!
由于这方面的改进繁多,也由于笔者在新近发布的极客时间专栏《Go 语言核心 36 讲》中已经详细讲解了不少,所以这里就不再赘述了。
我们再来说说 Go 1.11 的两个新实验吧,一个是对 WebAssembly 的实验性支持,另一个是推出由 dep 和 vgo 演化而来的依赖管理机制和新概念 module。
按照官方的描述,WebAssembly(缩写为 WASM)是一种二进制指令格式,它针对的是以堆栈为基础的虚拟机。WASM 有很好的可移植性,以便让 C++、Golang、Rust 等高级编程语言来操控它,并有能力部署到 Web 程序上。
用普通话来说,WASM 提供了一种途径,可以让我们用后端编程语言直接去编写 Web 页面中的逻辑。在 Go 1.11 中,我们可以很轻易地把 Go 语言源码文件转换为 WASM 格式的文件,然后在 Web 页面中通过寥寥几行 javascript 代码引用这个文件并把其中的逻辑发布到页面上。WASM 的 1.0 版本现在已经支持了绝大多数的主流网络浏览器,比如:Chrome、Firefox、Safari 等。如果想了解具体的玩法,你可以参看这个 wiki 页面。
笔者对 Go 语言官方的这种探索性实验一直都持赞成的态度,不论是前些年的移动端(android 和 ios)方向,还是今年的 Web 端(WASM)方向。不过,笔者依然觉得 Go 语言的优势在服务端,现在很明显,而且在可预见的未来也应该是如此。所以,对于这些多端探索,笔者建议大家“保持关注,积极试验,但不要偏移重心”。
相比之下,笔者倒是更加看好 Go 语言新放出的依赖管理机制。Go 语言爱好者们都知道,Go 语言在这方面一直是缺失的。虽然目前存在几个不错的第三方解决方案,但是没有一个是可以脱颖而出的,同时官方也一直没有给出一个统一的标准。
经过了一段时间的试验和演化,Go 语言官方的依赖管理机制终于脱胎于 dep 和 vgo。虽然其间存在一些摩擦和风波,但是结果终归是积极的。
在 Go 语言新的依赖管理机制中,module 是一个非常重要的概念。简单来说,module 象征着由某个 Go 语言代码包以及它依赖的代码包共同组成的一个独立单元。这里的 Go 语言代码包和它依赖的那些代码包都是版本化的。一个 module 的根目录下总是直接存有一个名为 go.mod 的文件。这个文件中会包含当前 module 的路径,以及它依赖的那些 module 的路径和版本号。如此一来,对于每一个版本的 module,它依赖的所有代码都会被固化下来。这对于后续的版本管理和 module 重建来说都是重要的基础。详情可以参看这里的 wiki 页面。
不过,不要忘了,Go 1.11 中包含的这个依赖管理机制是实验性的。其中的任何部分都有可能由于社区的反馈和官方的改进而变化。所以,你在正式使用它之前一定要考虑到后续可能存在的变更成本。虽然如此,笔者仍然会鼓励广大开发者们去积极使用和反馈。想象一下 maven 对于 Java 世界的重要性吧。笔者相信,我们心目中的 Go 项目依赖管理机制已经离此不远了。
笔者首先盼望的肯定是 Go 语言依赖管理机制的第一个稳定版,并且相信很多 Go 语言爱好者都是如此。但是,在笔者看来,这个稳定版本并不一定就会在 Go 语言的 1.12 版本中发布,虽然目标是这样的。
正如前文所述,Go 1.12 会从 godoc 命令中去掉命令行接口,而只保留基于 Web 的图形化查询界面。同时,它也不再允许开发者通过 GOCACHE 环境变量去禁用构建结果缓存。当然了,这个版本也会包含大量针对标准库的改进,详细内容可以到此版本的发布说明草稿中查看。
https://tip.golang.org/doc/go1.12
在去年我们就说过,Go 语言官方已经把 Go 2 的计划郑重地摆上了桌面。今年的进展是,Go 2 的设计草案已经发布了。
Go 语言作者之一 Robert Griesemer 不久前刚刚在官方博客发文称,Go 2 已经选择出备选新特性提案,进入提案反馈阶段,他呼吁社区积极参与进来,和官方团队一起改进 Go 语言设计。具体详情可以看 InfoQ 的报道《Go 2 提上日程,官方团队呼吁社区给新特性提案提交反馈》
目前来看,Go 2 将会主要解决三个问题,即:错误处理、错误值以及对泛型自定义的支持。
从多年前开始,很多 Go 程序开发者就已经在抱怨 Go 语言在错误处理方面的丑陋了。Go 函数的多返回值使我们可以在返回一般结果值的同时携带错误值。这是一个很亮眼的特性,可以让我们重视错误,并总是进行明确的处理。不过,这也带来了一个问题。我们在调用这样的 Go 函数之后,不得不先用 if 语句检查错误值是否为 nil,然后才能进行下一步处理。如果在我们的程序中有很多这样的代码,那么显然是很丑陋的。
不过,笔者认为,这很多都是开发者在程序设计方面存在问题导致的。然而,我们也并不能否认,Go 语言的这种错误处理方式是很多程序变得丑陋的导火索。不论怎样,Go 语言官方已经开始正视这个问题并在着手解决了。
与之相关的一个问题就是错误值的设计。我们知道,只要实现了 error 接口的数据类型就都可以被称为错误类型,它们的值就可以被称为错误值。创造一个错误值的方式有很多,调用 errors.New 函数、调用 fmt.Errorf 函数,以及使用值的字面量,等等。这恰恰使我们在对错误种类做判断的时候不得不仔细地选择判断方式,是检查错误值的类型?还是判断它是否等于某个已存在的错误值?又或者是对错误描述进行匹配?这显然增加了错误处理的成本。从草案上来看,已经有一些显著的成果了,我们还是拭目以待吧。
关于泛型,笔者并不想多说。允许泛型的自定义显然可以增强编程语言的表达能力,并且在一些场景下可以显著地减少重复的代码。不过,怎样将它设计好,并用优雅的方式展现出来,是一个很复杂的问题。在相应的草案中,Go 语言官方给出了一个看起来还不错的方案,但是依然可能存在变数。希望官方能够参考 C++、Java、Rust、Swift 等编程语言的设计,取其精华、去其糟粕吧。
关于详细的 Go 2 设计草案,大家可以到这里查阅。
https://go.googlesource.com/proposal/+/master/design/go2draft.md
笔者在今年明显的感觉到,关注 Go 语言的各路人马又变多了。这体现在了几个方面。首先,以 Go 语言为主题的 meetup 明显增多。无论是哪个技术组织发起的,参与的人都不在少数。而且,这样的 meetup 已经在更多的一、二线城市中出现了。
其次,互联网上的 Go 语言中文资料(比如博客、教程、电子书等)也明显增多,不论是免费的还是收费的,虽然水平各不相同,但是显然大家都在进行积极的探索和分享。
最后,很多主打技术培训的公司和组织都已经对 Go 语言进行了重点的关注,并开发出了自己的培训产品或服务,包括线上的知识付费产品、线下的面授课程,以及目标各有不同的开源项目,等等。笔者也有幸参与其中,并在极客时间开设了专栏《Go 语言核心 36 讲》。
不过,随着 Go 语言逐渐得到各方的广泛关注,盗版和抄袭也日益猖獗。笔者在这里呼吁,希望大家能够尊重原创作者的辛勤劳动和知识产权,拒绝盗版、抵制抄袭!只有这样才能够让作者们更加积极地产出优秀的内容,我们的学习环境才能更美好,技术社区才能因此向着健康、壮大的方向发展。
以上,就是我对 Go 语言在 2018 年发展的简要回顾和对其未来发展的展望。希望能够借此促使大家对 Go 语言和我们国内的技术社区有更多的关注。
作者介绍
郝林,国内知名的 Go 语言技术布道者,GoHackers 技术社群的发起人和组织者。他也是极客时间专栏《Go 语言核心 36 讲》的作者,以及图灵原创图书《Go 并发编程实战》的作者。他曾在轻松筹任大数据负责人,同时负责大数据部门和主站的后端技术团队。
点一下好看试试微信的新功能?
以上是关于解读Go语言的2018:怎么就在中国火成这样了?的主要内容,如果未能解决你的问题,请参考以下文章
调查了 10,975 位 Go 语言开发者,我们有了这些发现!
Go 语言发布 2018 调查报告,最被诟病问题竟然是......