慕课平台的后台数据可以爬取吗
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了慕课平台的后台数据可以爬取吗相关的知识,希望对你有一定的参考价值。
参考技术A 可以。软件已经给出一定的模板了,可以直接操作爬取;另外没有的可以输入链接爬取(教程里有)。.可以爬取网页显示的所有东西,包括:本网页的信息,该网页信息的链接网页,下一页(可设定页数,不设定可能停不下来,到最后重复提取后两三页)三种。
大多免费,具体什么花钱还没遇到。有教程,两个小视频,一共十分钟左右。
Node.js爬虫-爬取慕课网课程信息
第一次学习Node.js爬虫,所以这时一个简单的爬虫,Node.js的好处就是可以并发的执行
这个爬虫主要就是获取慕课网的课程信息,并把获得的信息存储到一个文件中,其中要用到cheerio库,它可以让我们方便的操作HTML,就像是用jQ一样
开始前,记得
npm install cheerio
为了能够并发的进行爬取,用到了Promise对象
//接受一个url爬取整个网页,返回一个Promise对象 function getPageAsync(url){ return new Promise((resolve,reject)=>{ console.log(`正在爬取${url}的内容`); http.get(url,function(res){ let html = \'\'; res.on(\'data\',function(data){ html += data; }); res.on(\'end\',function(){ resolve(html); }); res.on(\'error\',function(err){ reject(err); console.log(\'错误信息:\' + err); }) }); }) }
在慕课网中,每个课程都有一个ID,我们事先要把想要获取课程的ID写到一个数组中,而且每个课程的地址都是一个相同的地址加上ID,所以我们只要把地址和ID拼接起来就是课程的地址
const baseUrl = \'http://www.imooc.com/learn/\'; const baseNuUrl = \'http://www.imooc.com/course/AjaxCourseMembers?ids=\'; //获取课程的ID const videosId = [773,371];
为了使获取每个课程内容时并发执行,要使用Promise中的all方法
Promise //当所有网页的内容爬取完毕 .all(courseArray) .then((pages)=>{ //所有页面需要的内容 let courseData = []; //遍历每个网页提取出所需要的内容 pages.forEach((html)=>{ let courses = filterChapter(html); courseData.push(courses); }); //给每个courseMenners.number赋值 for(let i=0;i<videosId.length;i++){ for(let j=0;j<videosId.length;j++){ if(courseMembers[i].id +\'\' == videosId[j]){ courseData[j].number = courseMembers[i].numbers; } } } //对所需要的内容进行排序 courseData.sort((a,b)=>{ return a.number > b.number; }); //在重新将爬取内容写入文件中前,清空文件 fs.writeFileSync(outputFile,\'###爬取慕课网课程信息###\',(err)=>{ if(err){ console.log(err) } }); printfData(courseData); });
在then方法中,pages是每个课程的HTML页面,我们还得从中提取出我们需要的信息,需要使用下面的函数
//接受一个爬取下来的网页内容,查找网页中需要的信息 function filterChapter(html){ const $ = cheerio.load(html); //所有章 const chapters = $(\'.chapter\'); //课程的标题和学习人数 let title = $(\'.hd>h2\').text(); let number = 0; //最后返回的数据 //每个网页需要的内容的结构 let courseData = { \'title\':title, \'number\':number, \'videos\':[] }; chapters.each(function(item){ let chapter = $(this); //文章标题 let chapterTitle = Trim(chapter.find(\'strong\').text(),\'g\'); //每个章节的结构 let chapterdata = { \'chapterTitle\':chapterTitle, \'video\':[] }; //一个网页中的所有视频 let videos = chapter.find(\'.video\').children(\'li\'); videos.each(function(item){ //视频标题 let videoTitle = Trim($(this).find(\'a.J-media-item\').text(),\'g\'); //视频ID let id = $(this).find(\'a\').attr(\'href\').split(\'video/\')[1]; chapterdata.video.push({ \'title\':videoTitle, \'id\':id }) }); courseData.videos.push(chapterdata); }); return courseData; }
注意:在上面中将课程的学习人数设置为了0是因为学习课程人数是用Ajax动态获取,所以我在后面写了方法专门获取学习课程人数,其中用到的Trim()方法是去除文本中的空格
获取学习课程的人数:
//获取上课人数 function getNumber(url){ let datas = \'\'; http.get(url,(res)=>{ res.on(\'data\',(chunk)=>{ datas += chunk; }); res.on(\'end\',()=>{ datas = JSON.parse(datas); courseMembers.push({\'id\':datas.data[0].id,\'numbers\':parseInt(datas.data[0].numbers,10)}); }); }); }
这样就将想获取课程的学习人数都添加到了courseMembers数组中,在最后将学习课程的人数在赋值给相对应的课程
//给每个courseMenners.number赋值 for(let i=0;i<videosId.length;i++){ for(let j=0;j<videosId.length;j++){ if(courseMembers[i].id +\'\' == videosId[j]){ courseData[j].number = courseMembers[i].numbers; } } }
我们获取到了数据,就要把它按照一定的格式存到一个文件中
//写入文件 function writeFile(file,string) { fs.appendFileSync(file,string,(err)=>{ if(err){ console.log(err); } }) } //打印信息 function printfData(coursesData){ coursesData.forEach((courseData)=>{ // console.log(`${courseData.number}人学习过${courseData.title}\\n`); writeFile(outputFile,`\\n\\n${courseData.number}人学习过${courseData.title}\\n\\n`); courseData.videos.forEach(function(item){ let chapterTitle = item.chapterTitle; // console.log(chapterTitle + \'\\n\'); writeFile(outputFile,`\\n ${chapterTitle}\\n`); item.video.forEach(function(item){ // console.log(\' 【\' + item.id + \'】\' + item.title + \'\\n\'); writeFile(outputFile,` 【${item.id}】 ${item.title}\\n`); }) }); }); }
最后获取到的数据:
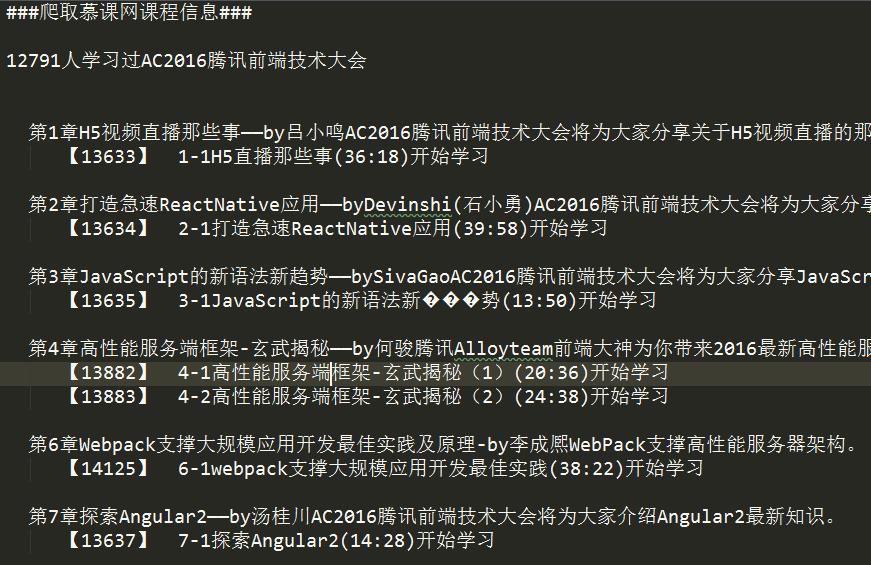
源码:
/** * Created by hp-pc on 2017/6/7 0007. */ const http = require(\'http\'); const fs = require(\'fs\'); const cheerio = require(\'cheerio\'); const baseUrl = \'http://www.imooc.com/learn/\'; const baseNuUrl = \'http://www.imooc.com/course/AjaxCourseMembers?ids=\'; //获取课程的ID const videosId = [773,371]; //输出的文件 const outputFile = \'test.txt\'; //记录学习课程的人数 let courseMembers = []; //去除字符串中的空格 function Trim(str,is_global) { let result; result = str.replace(/(^\\s+)|(\\s+$)/g,""); if(is_global.toLowerCase()=="g") { result = result.replace(/\\s/g,""); } return result; } //接受一个url爬取整个网页,返回一个Promise对象 function getPageAsync(url){ return new Promise((resolve,reject)=>{ console.log(`正在爬取${url}的内容`); http.get(url,function(res){ let html = \'\'; res.on(\'data\',function(data){ html += data; }); res.on(\'end\',function(){ resolve(html); }); res.on(\'error\',function(err){ reject(err); console.log(\'错误信息:\' + err); }) }); }) } //接受一个爬取下来的网页内容,查找网页中需要的信息 function filterChapter(html){ const $ = cheerio.load(html); //所有章 const chapters = $(\'.chapter\'); //课程的标题和学习人数 let title = $(\'.hd>h2\').text(); let number = 0; //最后返回的数据 //每个网页需要的内容的结构 let courseData = { \'title\':title, \'number\':number, \'videos\':[] }; chapters.each(function(item){ let chapter = $(this); //文章标题 let chapterTitle = Trim(chapter.find(\'strong\').text(),\'g\'); //每个章节的结构 let chapterdata = { \'chapterTitle\':chapterTitle, \'video\':[] }; //一个网页中的所有视频 let videos = chapter.find(\'.video\').children(\'li\'); videos.each(function(item){ //视频标题 let videoTitle = Trim($(this).find(\'a.J-media-item\').text(),\'g\'); //视频ID let id = $(this).find(\'a\').attr(\'href\').split(\'video/\')[1]; chapterdata.video.push({ \'title\':videoTitle, \'id\':id }) }); courseData.videos.push(chapterdata); }); return courseData; } //获取上课人数 function getNumber(url){ let datas = \'\'; http.get(url,(res)=>{ res.on(\'data\',(chunk)=>{ datas += chunk; }); res.on(\'end\',()=>{ datas = JSON.parse(datas); courseMembers.push({\'id\':datas.data[0].id,\'numbers\':parseInt(datas.data[0].numbers,10)}); }); }); } //写入文件 function writeFile(file,string) { fs.appendFileSync(file,string,(err)=>{ if(err){ console.log(err); } }) } //打印信息 function printfData(coursesData){ coursesData.forEach((courseData)=>{ // console.log(`${courseData.number}人学习过${courseData.title}\\n`); writeFile(outputFile,`\\n\\n${courseData.number}人学习过${courseData.title}\\n\\n`); courseData.videos.forEach(function(item){ let chapterTitle = item.chapterTitle; // console.log(chapterTitle + \'\\n\'); writeFile(outputFile,`\\n ${chapterTitle}\\n`); item.video.forEach(function(item){ // console.log(\' 【\' + item.id + \'】\' + item.title + \'\\n\'); writeFile(outputFile,` 【${item.id}】 ${item.title}\\n`); }) }); }); } //所有页面爬取完后返回的Promise数组 let courseArray = []; //循环所有的videosId,和baseUrl进行字符串拼接,爬取网页内容 videosId.forEach((id)=>{ //将爬取网页完毕后返回的Promise对象加入数组 courseArray.push(getPageAsync(baseUrl + id)); //获取学习的人数 getNumber(baseNuUrl + id); }); Promise //当所有网页的内容爬取完毕 .all(courseArray) .then((pages)=>{ //所有页面需要的内容 let courseData = []; //遍历每个网页提取出所需要的内容 pages.forEach((html)=>{ let courses = filterChapter(html); courseData.push(courses); }); //给每个courseMenners.number赋值 for(let i=0;i<videosId.length;i++){ for(let j=0;j<videosId.length;j++){ if(courseMembers[i].id +\'\' == videosId[j]){ courseData[j].number = courseMembers[i].numbers; } } } //对所需要的内容进行排序 courseData.sort((a,b)=>{ return a.number > b.number; }); //在重新将爬取内容写入文件中前,清空文件 fs.writeFileSync(outputFile,\'###爬取慕课网课程信息###\',(err)=>{ if(err){ console.log(err) } }); printfData(courseData); });
以上是关于慕课平台的后台数据可以爬取吗的主要内容,如果未能解决你的问题,请参考以下文章