Scrapy爬取慕课网(imooc)所有课程数据并存入MySQL数据库
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Scrapy爬取慕课网(imooc)所有课程数据并存入MySQL数据库相关的知识,希望对你有一定的参考价值。
爬取目标:使用scrapy爬取所有课程数据,分别为
1.课程名 2.课程简介 3.课程等级 4.学习人数
并存入mysql数据库 (目标网址 http://www.imooc.com/course/list)
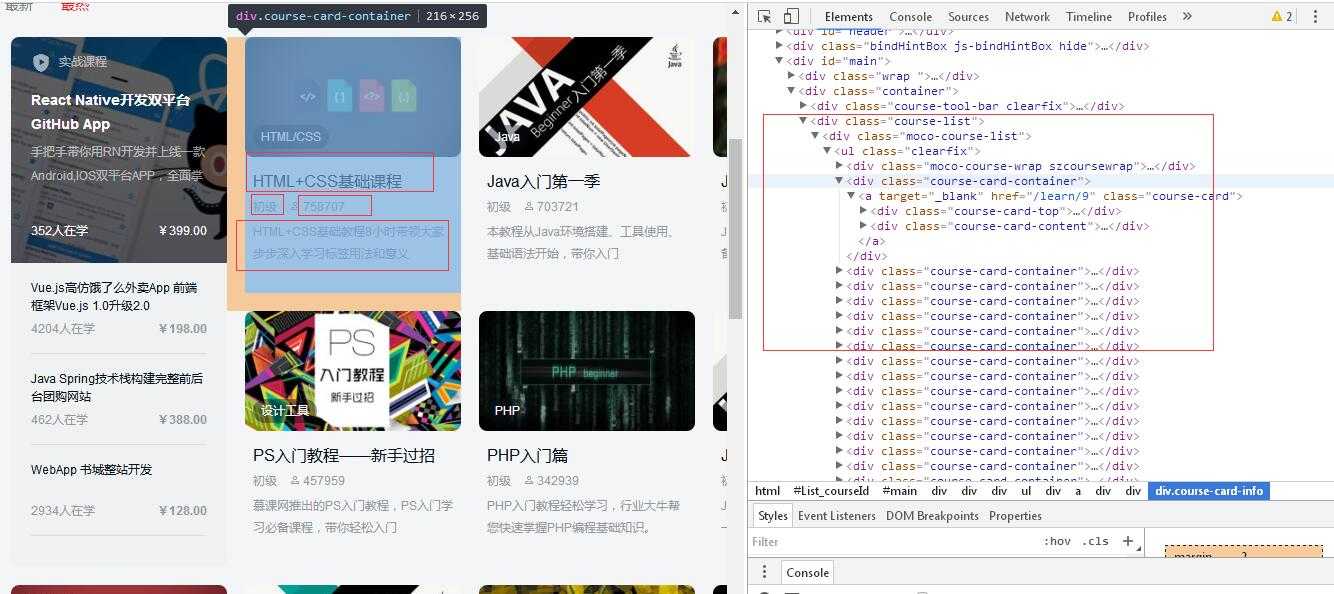
一.导出数据文件到本地
1.新建imooc项目
1 scrapy startproject imooc
2.修改 items.py,添加项目item
1 from scrapy import Item,Field 2 class ImoocItem(Item): 3 Course_name=Field()#课程名称 4 Course_content=Field()#课程内容 5 Course_level=Field()#课程等级 6 Course_attendance=Field()#课程学习人数
3.在 spiders目录下制作爬虫
vi imooc_spider.py
1 # -*- coding: utf-8 -*- 2 from scrapy.spiders import CrawlSpider 3 from scrapy.selector import Selector 4 from imooc.items import ImoocItem 5 from scrapy.http import Request 6 7 8 class Imooc(CrawlSpider): 9 name=‘imooc‘ 10 allowed_domains = [‘imooc.com‘] 11 start_urls = [] 12 for pn in range(1,31): 13 url = ‘http://www.imooc.com/course/list?page=%s‘ % pn 14 start_urls.append(url) 15 16 def parse(self,response): 17 item=ImoocItem() 18 selector=Selector(response) 19 Course = selector.xpath(‘//a[@class="course-card"]‘) 20 21 for eachCourse in Course: 22 Course_name = eachCourse.xpath(‘div[@class="course-card-content"]/h3[@class="course-card-name"]/text()‘).extract()[0] 23 Course_content = eachCourse.xpath(‘div[@class="course-card-content"]/div[@class="clearfix course-card-bottom"]/p[@class="course-card-desc"]/text()‘).extract() 24 Course_level = eachCourse.xpath(‘div[@class="course-card-content"]/div[@class="clearfix course-card-bottom"]/div[@class="course-card-info"]/span/text()‘).extract()[0] 25 Course_attendance = eachCourse.xpath(‘div[@class="course-card-content"]/div[@class="clearfix course-card-bottom"]/div[@class="course-card-info"]/span/text()‘).extract()[1] 26 item[‘Course_name‘] = Course_name 27 item[‘Course_content‘] = ‘;‘.join(Course_content) 28 item[‘Course_level‘] = Course_level 29 item[‘Course_attendance‘] = Course_attendance 30 yield item
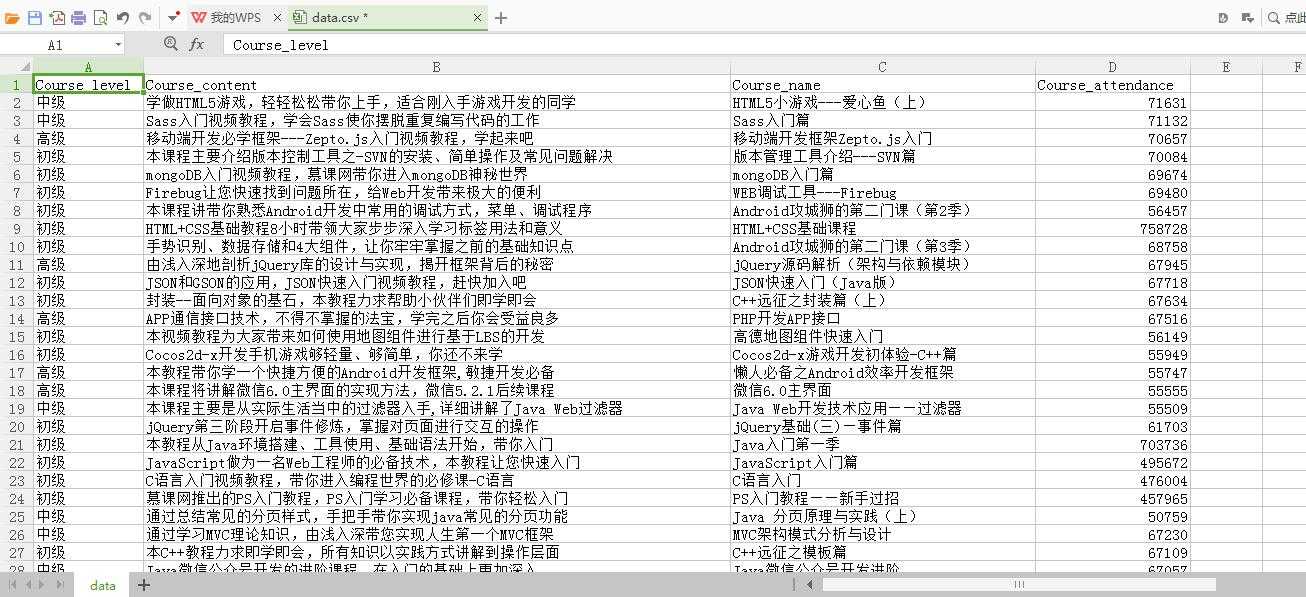
4.现在可以运行爬虫把数据导出来,现在以cvs格式测试
1 scrapy crawl imooc -o data.csv -t csv
查看文件
二.爬取数据并存入MySQL数据库
1.这里使用MySQL数据库存储数据,需要用到 MySQLdb包,确保已经安装
首先建立数据库和表
--创建数据库 create database imooc DEFAULT CHARACTER SET utf8 COLLATE utf8_general_ci; --创建表 create table imooc_info2( title varchar(255) NOT NULL COMMENT ‘课程名称‘, content varchar(255) NOT NULL COMMENT ‘课程简介‘, level varchar(255) NOT NULL COMMENT ‘课程等级‘, sums int NOT NULL COMMENT ‘课程学习人数‘ )
2.修改pipelines.py
1 # -*- coding: utf-8 -*- 2 3 # Define your item pipelines here 4 # 5 # Don‘t forget to add your pipeline to the ITEM_PIPELINES setting 6 # See: http://doc.scrapy.org/en/latest/topics/item-pipeline.html 7 8 9 import json 10 from twisted.enterprise import adbapi 11 from scrapy import log 12 import MySQLdb 13 import MySQLdb.cursors 14 import codecs 15 16 class ImoocPipeline(object): 17 def __init__(self): 18 self.file = codecs.open(‘imooc.json‘, ‘w‘, encoding=‘utf-8‘) 19 def process_item(self, item, spider): 20 line = json.dumps(dict(item), ensure_ascii=False) + "\\n" 21 self.file.write(line) 22 return item 23 def spider_closed(self, spider): 24 self.file.close() 25 26 class MySQLPipeline(object): 27 28 def __init__(self): 29 self.dbpool = adbapi.ConnectionPool("MySQLdb", 30 db = "imooc", # 数据库名 31 user = "root", # 数据库用户名 32 passwd = "hwfx1234", # 密码 33 cursorclass = MySQLdb.cursors.DictCursor, 34 charset = "utf8", 35 use_unicode = True 36 ) 37 def process_item(self, item, spider): 38 query = self.dbpool.runInteraction(self._conditional_insert, item) 39 query.addErrback(self.handle_error) 40 return item 41 42 def _conditional_insert(self, tb, item): 43 tb.execute(""" insert into imooc_info2 (title,content,level,sums) values (%s,%s,%s,%s)""",(item[‘Course_name‘],item[‘Course_content‘],item[‘Course_level‘],item[‘Course_attendance‘])) 44 log.msg("Item data in db: %s" % item, level=log.DEBUG) 45 46 def handle_error(self, e): 47 log.err(e)
3.修改setting.py
加入MySQL配置,添加pipelines.py 内新建类
1 # start MySQL database configure setting 2 MYSQL_HOST = ‘localhost‘ 3 MYSQL_DBNAME = ‘imooc‘ 4 MYSQL_USER = ‘root‘ 5 MYSQL_PASSWD = ‘hwfx1234‘ 6 # end of MySQL database configure setting 7 ITEM_PIPELINES = { 8 ‘imooc.pipelines.ImoocPipeline‘: 300, 9 ‘imooc.pipelines.MySQLPipeline‘: 300, 10 }
4.开始爬虫
1 scrapy crawl imooc
查看数据库表数据,数据已经入库。
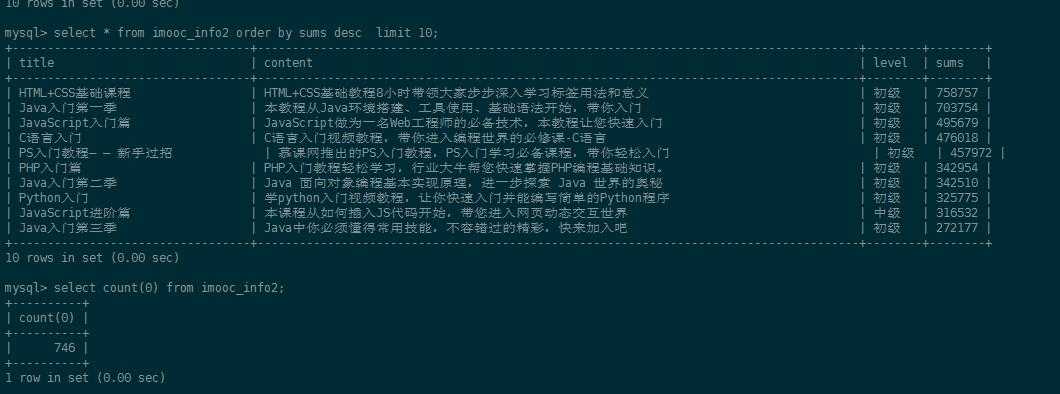
总结:scrapy简单的应用,还没考虑反爬虫、分布式等问题,还需要多练习。
以上是关于Scrapy爬取慕课网(imooc)所有课程数据并存入MySQL数据库的主要内容,如果未能解决你的问题,请参考以下文章