干货分享:蚂蚁金服前端框架和工程化实践
Posted 支付宝技术
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了干货分享:蚂蚁金服前端框架和工程化实践相关的知识,希望对你有一定的参考价值。
在InfoQ 2019年举办的 GMTC 全球大前端技术大会上,蚂蚁金服高级技术专家陈成发表了《蚂蚁金服前端框架和工程化实践》的演讲,以下是本次演讲摘要。

框架发展历史

这是我们的框架发展时间线。
2015 年之前我们有 Sea.JS、Arale、SPM 开源技术方案,大家可以有所耳闻。
2015 年我们接入 React,从自研的 Roof 到 Redux 再到开源的 Dva,一步步验证我们的最佳实践,并把这些实践交给开源社区检验。
2017 年开始尝试了新一代的企业级前端框架,Umi 和 Bigfish,前者是从无线业务中长出来的,后者是从中台业务中长出来的。
一个团队出两个框架毕竟不是长久之计,后来老大直接把两拨人调到一个组,于是就愉快地合并在了一起。
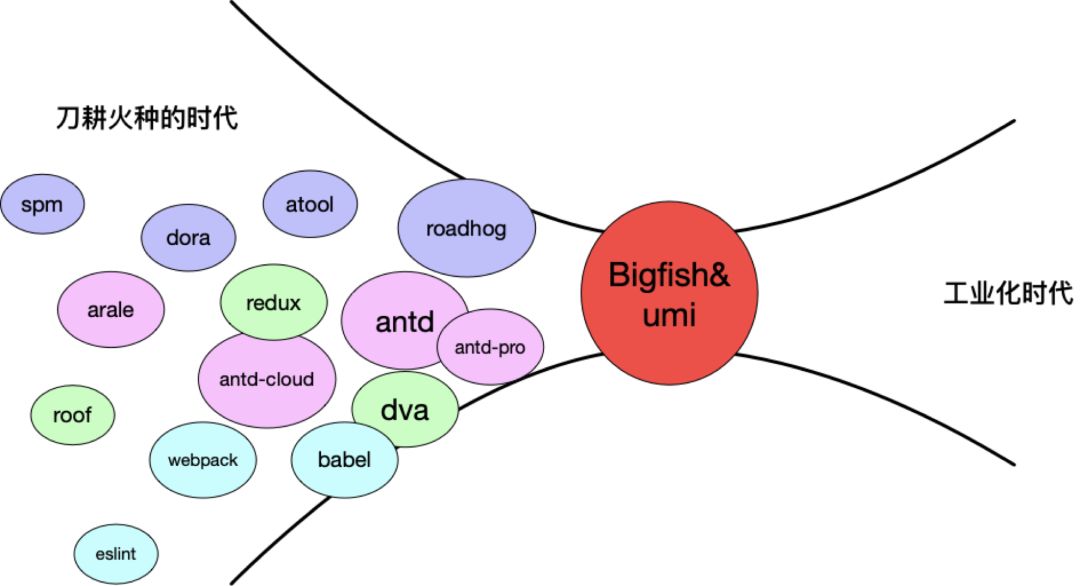
在 Umi 和 Bigfish 时代,我们从刀耕火种的时代跨入了工业化时代。因为在此之前,用户需要接触很多技术栈和细节,在 Umi 和 Bigfish 中,用户只要知道一个框架,剩下的全部不用了解。框架像一个魔法球,把各种技术栈吸到一起,加工后吐给用户,以此来支撑业务。
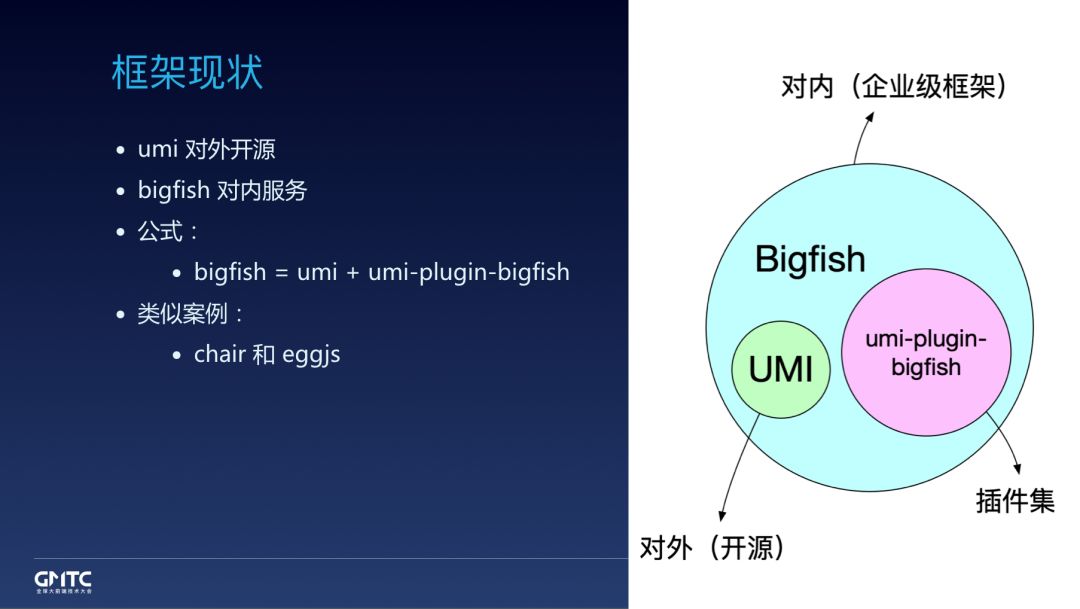
在两个框架合并之后,我们的现状是这样:
umi 对外开源,bigfish 对内服务内部同学。
bigfish 扔掉原有实现,改造成 umi + umi 插件集的一个架构。
我们不是第一个这么做的,类似的还有 eggjs 和 chair。这是一种很好的方式,开源和业务两不误。
那么,这是我们的框架终局吗?以及是否还有更好的方式?大家也可以思考下,后面在未来规划区域会有探讨。

这是一些蚂蚁的内部数据:
1100+ 内部应用数
新增产品 80% 都用此框架
包含 100+ 插件数量,社区够活跃,尤其是内部的
1500+ 内部使用者
目前来看,这个框架基本统一了内部的框架使用情况,不仅有不熟前端的 Java 开发,略熟前端的外包,还有资深的前端同学。要获得那么多同学的认可,并不是件容易的事。
为什么我们能成
那么,为什么我们能成?个人理解,我觉得有几个关键词:
人
业务
流程
开源
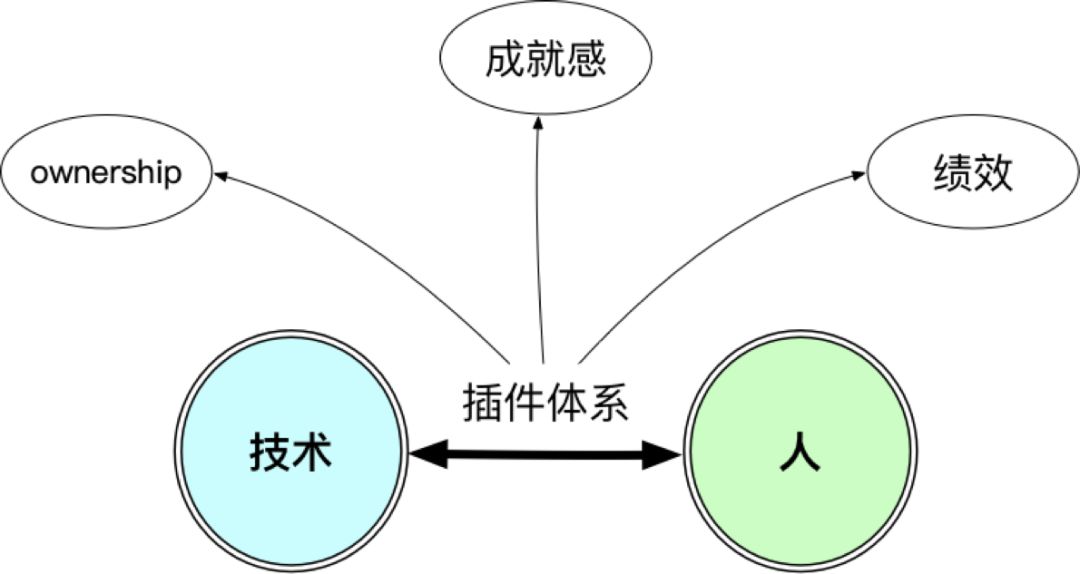
人是非常重要的一环,甚至比技术本身更重要一些。
那么别人为啥要用你的框架?首先,框架要好用,这是最基本的;然后,使用者尤其是资深的前端同学,还得在这上面找到自己的成就感和 ownership,另外如果绩效漂亮就更好了。总不能别人用你的框架,然后只有你自己一个人的绩效好,那是不会长久的。
我们的解法是插件体系。

框架不是凭空而来的,需求来自于业务,所以用框架写业务的同学往往能发现框架不足的点,他们可以开发适用于自己业务的框架插件,反哺框架。如果这是通用需求,那就亮了。框架的内部开发群有 100+ 人,包含大量来自业务线的同学,这就是插件体系的好处,人人都能贡献。为了让写插件变得简单,我们给框架分了五层架构。
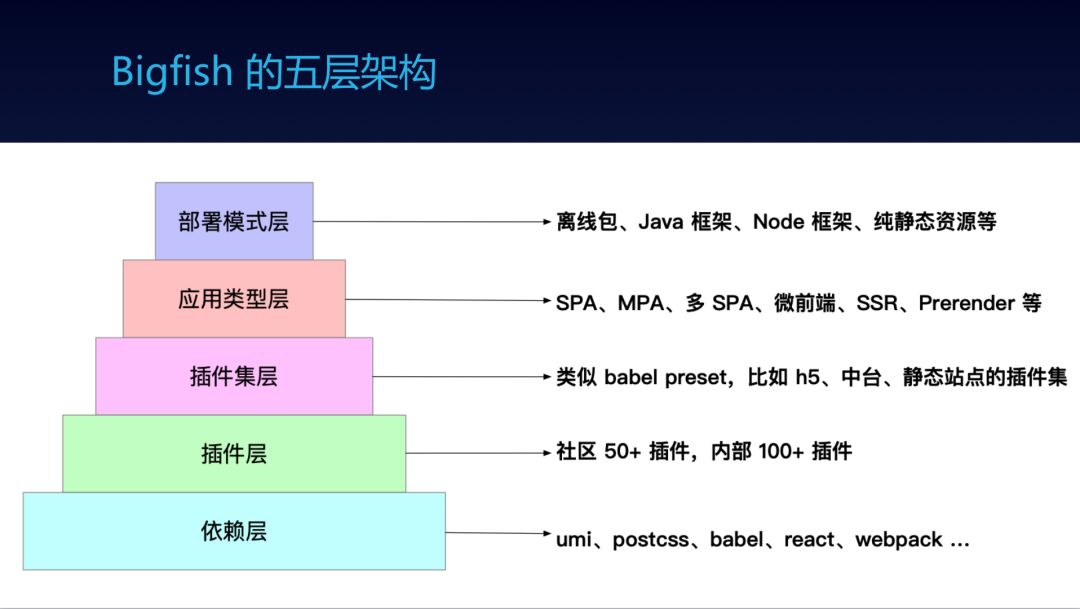
包含依赖层、插件层、插件集层、应用类型层和部署模式层,大家可在任何一层都可贡献代码,
可以写一个独立的功能插件,比如和某个服务的对接,比如扩展路由的某个功能,比如实现一套特殊的补丁方案;
可以做归类,把一系列插件整理到一个插件集里,适用于某一类的业务开发;
可以扩展应用类型,比如 SPA、MPA、微前端等等;
可以扩展部署模式,比如和不同的框架或平台做结合;
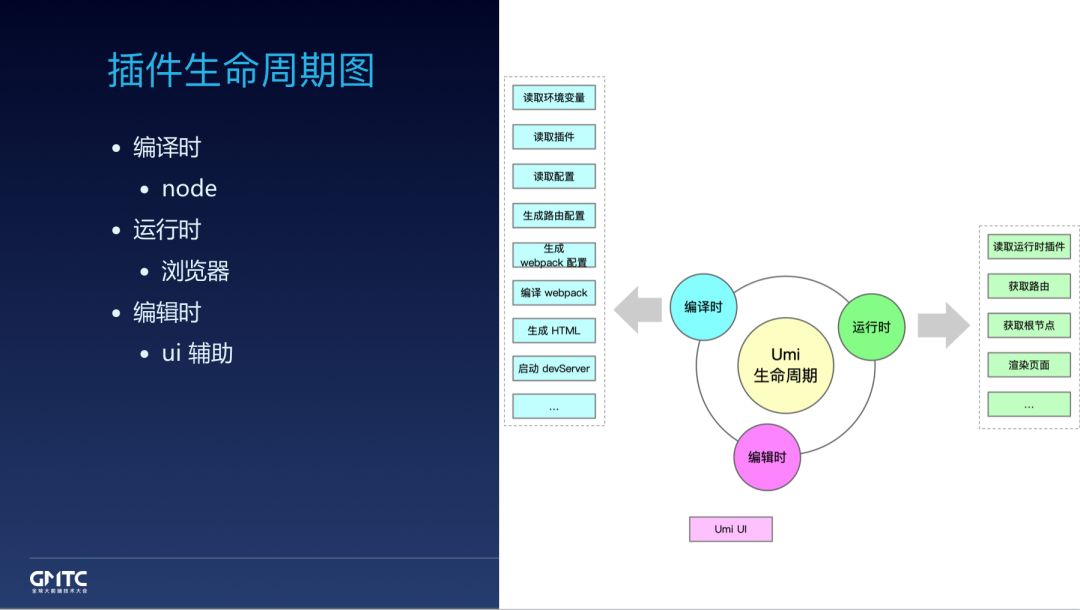
这是插件生命周期图,包含:
node 环境执行的编译时
浏览器上执行的运行时
ui 辅助层的编辑时
大部分插件体系只会考虑 node 编译时,我们加上运行时和编辑时的支持,赋予了插件更大的能力。具体做了什么就不展开了,没个框架都不同,但做的事情其实大体一致,往上说是 html、css、js,往下说还有各种工具的配置,比如 webpack、babel、postcss、dev 中间件 等等。
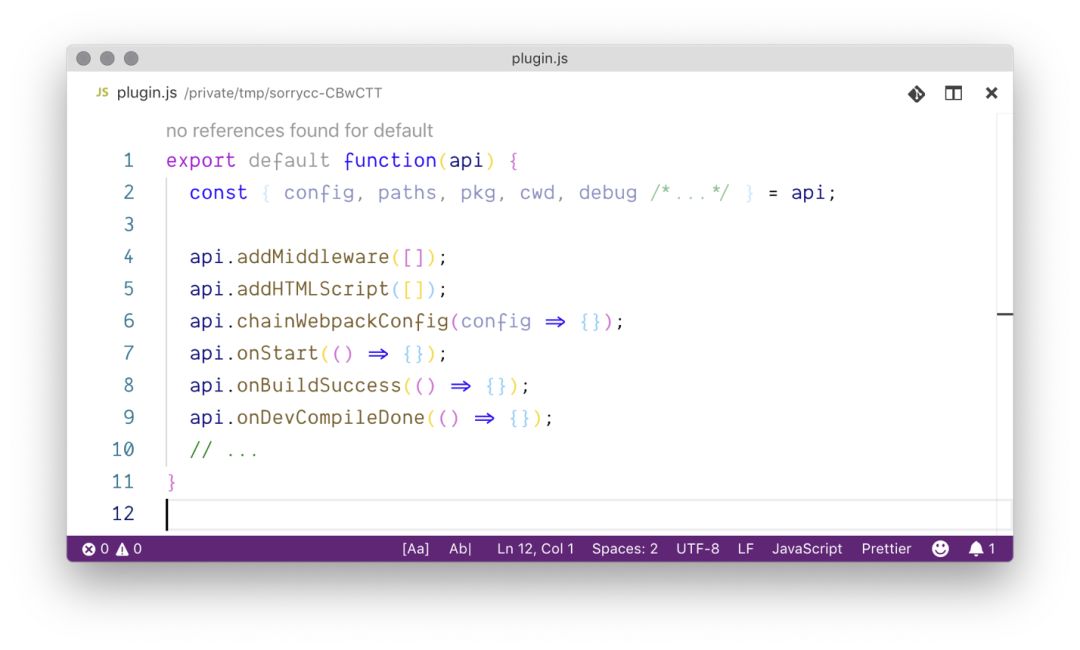
下面来看具体如何写一个插件,如果大家有写过 vue-cli 的插件,会发现很类似:
导出一个函数,第一个参数包含我们提供的能力。
可以添加、修改、绑定事件等等。
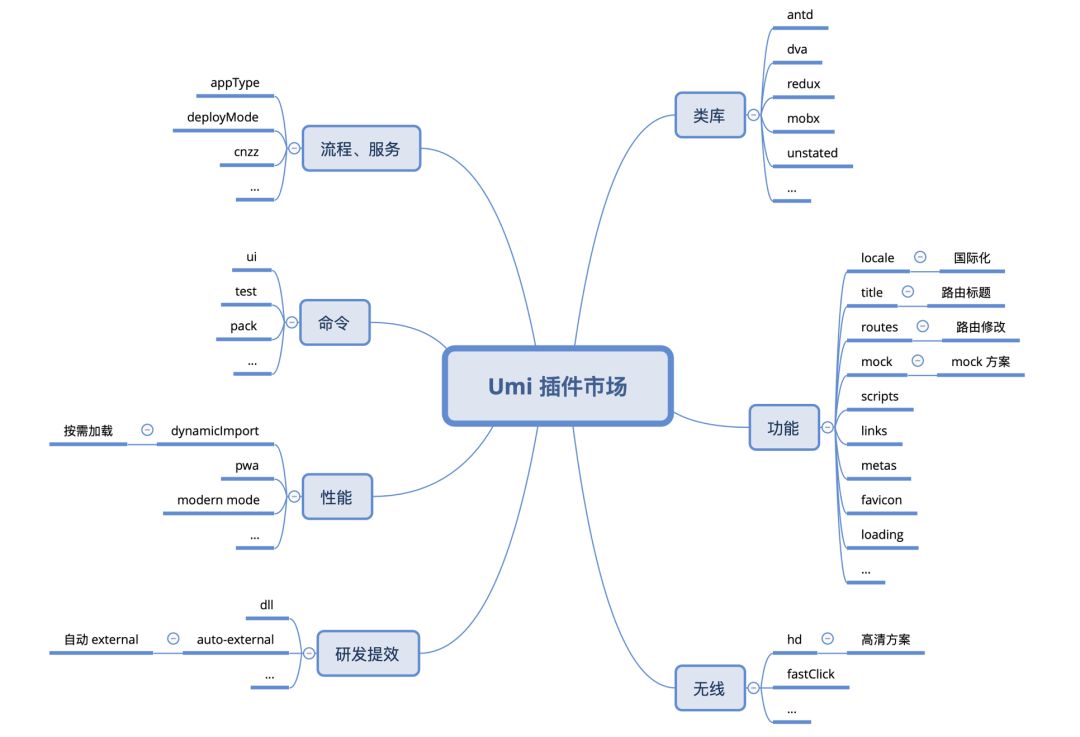
我们目前的部分插件,内部流程相关的就没有列出来了,内外加起来应该有 100 多个了吧。
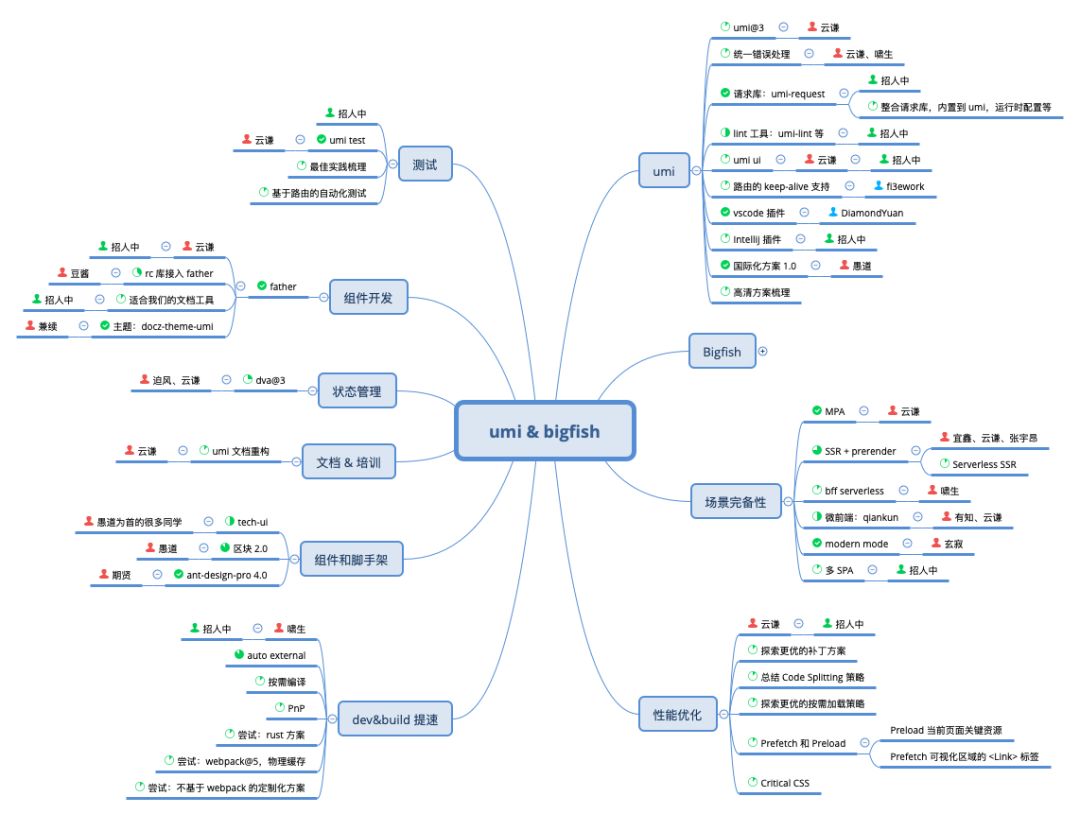
这是我们的分工表,基本上涉及到了框架和业务的方方面面,很多事情都是由不同的人来负责,大家的参与度也不错。
当然,人总是不够的,很多子项都还处于招人状态。
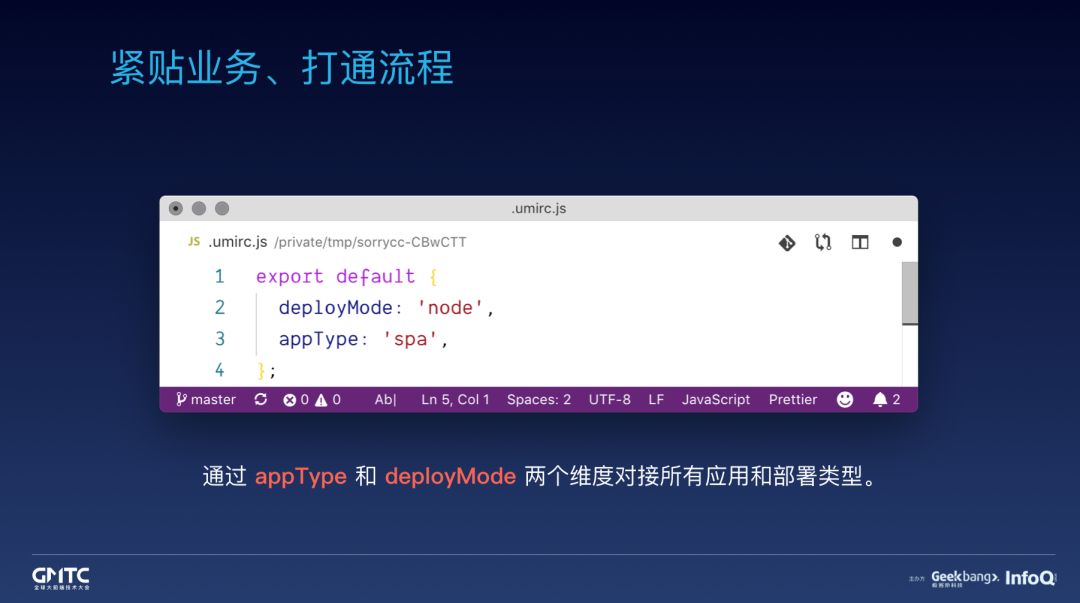
我们的框架能成,我觉得另一个重要的原因是我们不仅做功能,还做业务和流程。我不清楚大家是如何走流程的,包括如何切换应用类型,如何和各种后端服务和平台对接,反正我们的还是挺繁琐的。程序员的时间浪费在这里我觉得很不值,所以如果框架能解决这部分,应该会受到欢迎。
我们通过 appType 和 deployMode 两个维护来对接各种场景,用户只要配 deployMode: node 就能对接 node 框架,改成 java 就能对接 java 框架,背后的脏活累活交给框架做。
最后还有一个原因是我们做开源,我个人是比较热衷开源的,把自己的实现完全透明地展示给社区,包括之前写的工具和数据流方案,也都是从开源做起,因为我觉得开源相比在内网闭门造车,能带来很多好处。
代码质量,不写用例的代码不会有人愿意用。
Bugfix 和额外的代码贡献,社区很多人都是愿意参与的,在吸引到足够的人使用之后,框架内部的问题会更快暴露出来,还会有很多人愿意贡献代码和修复 Bug。
umi core developer group,我们还组织了社区的 umi developer 群,比如 vscode 插件、create-umi 等等的包,就是由社区同学主导维护的。
另外,开源做地好,也更容易获得内部同学的认可。包括之前做的 dva、现在的 umi,都不是一开始的内部首选,而是后来慢慢逆袭的。
框架大图
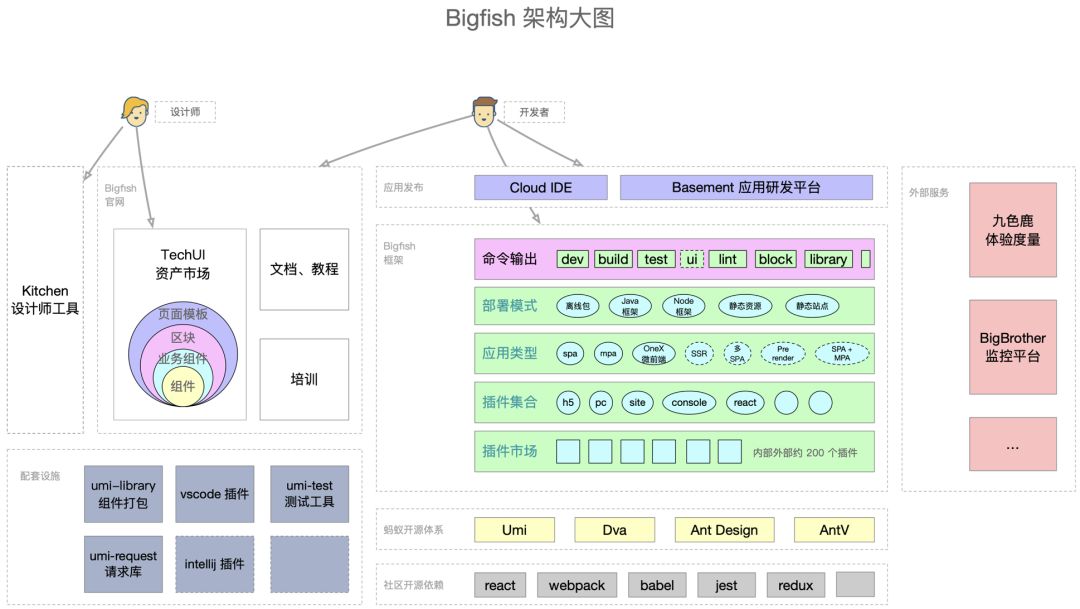
这是我们现在的框架大图:
中间从下往上是社区开源、蚂蚁开源、Bigfish 框架、应用发布流程。
框架层主要就是我们前面介绍的五层架构。
左上主要是资产市场,我们提效的主要手段之前,这在后面会展开介绍。
左下是工程方面的配套设施,编辑器插件、测试、lint 工具等等。
右边是对接的服务,通过框架插件,可实现配置式地对接外部服务,减少接入成本。
拳头功能
下面是我们的一些拳头功能。
资产市场
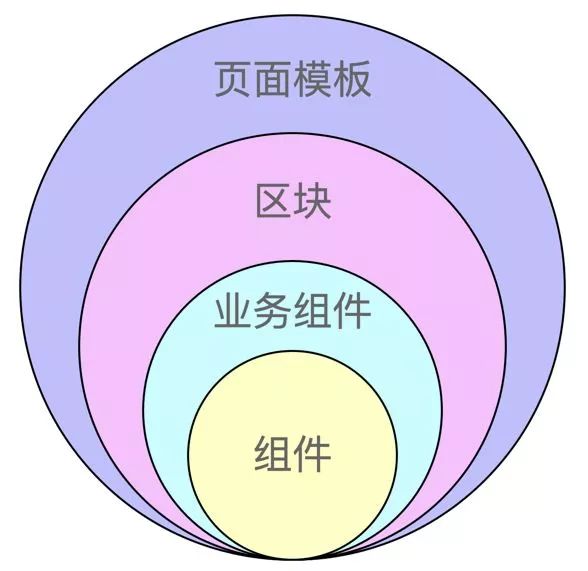
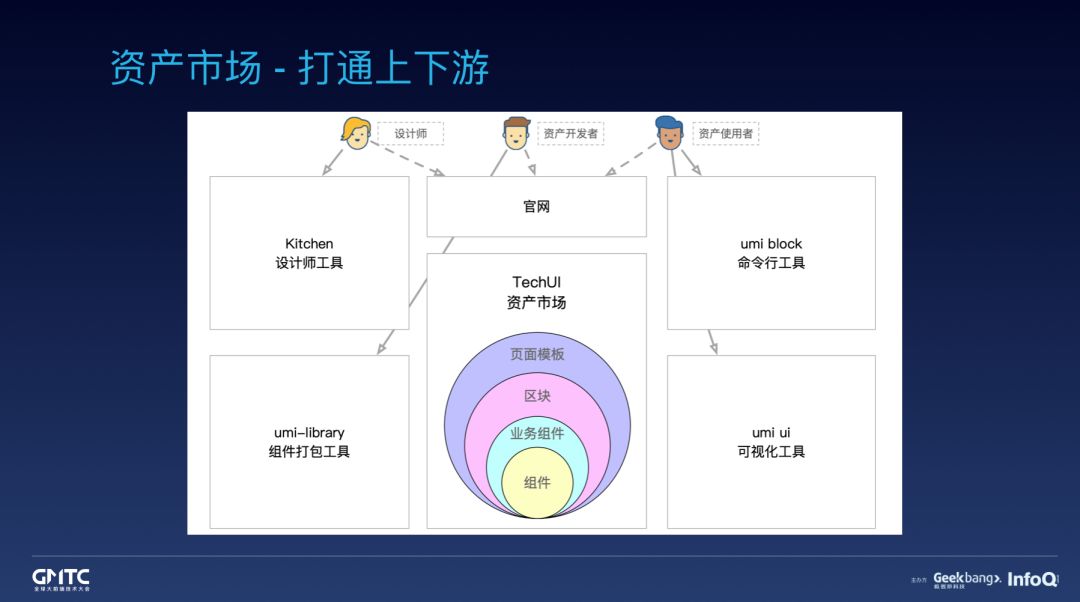
今年由于大形势的原因,我们比较重研发提效,最好是一个人能干 10 个人的活。关于提效,其中比较重要的是相同的代码不要重复写,要做提取和组件化。而资产市场就是做的这件事。为了更有效地复用,我们对资产市场分了四级:
组件,指通用组件,就是 antd,在下半年将要发布的 antd@4 里,我们会陆续提取更多通用组件到 antd 中。
业务组件,不能提取通用组件的,我们会提到内部统一的业务组件仓库中。
区块,由组件组成,可以想象成代码片段。
页面模板,由区块组成
我们可以借助工具把区块和页面模板添加到页面中:
通过 Umi UI(可视化方式)添加区块的样式。

区块方案其实不是一开始就这样,中间经历了几次迭代。
最初的思路来源是 angular 的一个 theme market,以及飞冰。
1.0 的版本时我们设计区块是页面级的,用户可以在一个页面里写组件、数据流方案、mock 等等,这样我们要做一个基于 antd 的 CRUD 页面就很简单,一个命令把区块拿进来,然后修修改改就完事了。
然后今年我们重新整理了区块方案,因为我们希望区块能更通用一些,比如可重复添加,可无限嵌套,支持区块集,可结合布局,支持可视化添加等等。
这是区块方案的迭代情况,一路踩着坑过来的。
资产市场不会凭空运转起来,或者说我们做了资产市场,大家就会按照这套方案用起来。比如一个产品,设计师不按照约定的规范来设计,那资产市场就成了摆设。所以,这是一件自上而下的事情,并且得拉上设计师同学一起做,才有可能做好。
在工具层面,我们需要打通上下游,同时兼顾三类角色的同学:
设计师,在设计师工具层同步资产市场,让大家在设计时就按照约定的方式走。
资产开发者,提供组件开发工具,包括组件的打包、文档、本地调试、测试、发布、自动生成 CHANGELOG 等等。
资产使用者,同时提供命令行和可视化工具,命令行是兜底方案,可视化的方式添加资产则更友好。
微前端
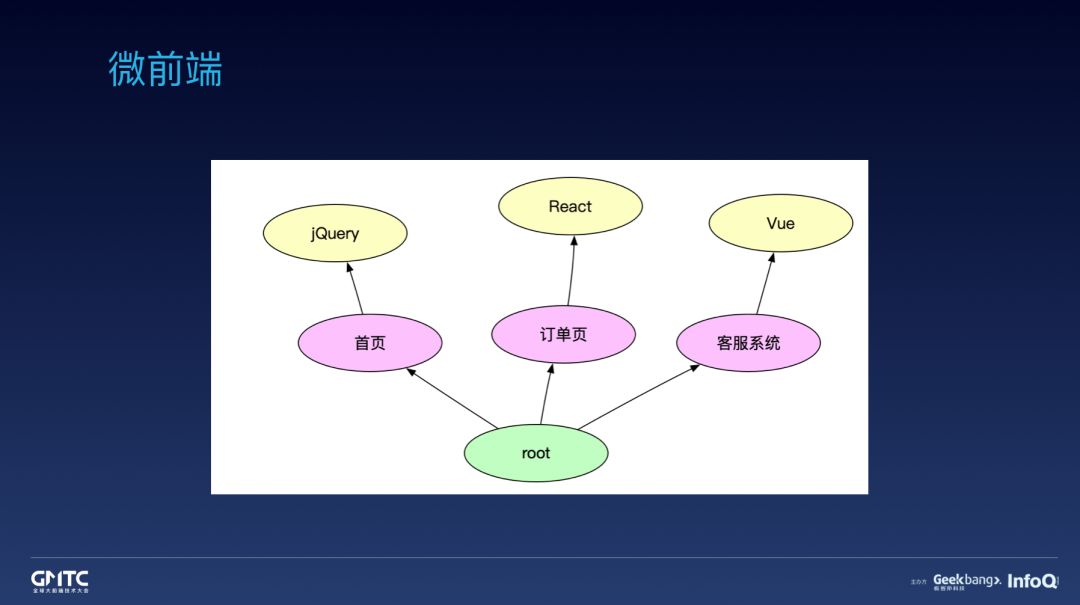
我们在微前端方面也有一些沉淀,并在生产环境有大量应用。
关于微前端是啥?首先大家想到的可能是一个解决多套技术栈共存的方案,比如首页用 jQuery,订单页用 React,客户系统用 Vue。这没错,但是一个相对狭义的理解。
一个问题是,如果我们的技术栈一致,那是否就不需要微前端方案了?不是!
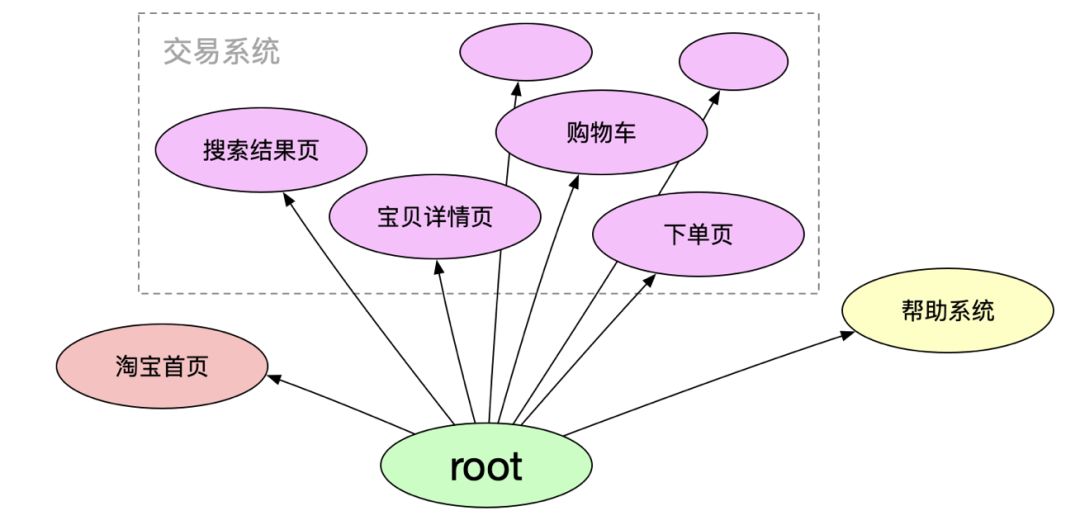
我对微前端的理解是,他不仅是个技术方案,更是个解决流程、组织架构等问题的方案。
比如淘宝网,可以简单理解成有淘宝首页、交易系统和帮助系统,这些系统是优先级的,并且在我们人力有限的情况下,我们会把资深的同学投入到重要的系统里,不重要的系统我们可能会通过外包或者购买的方式解决,但是一个底线是,不重要的系统不能影响重要的系统的运转。
要实现这一点,目前流行的有两种方式:
MPA(多页应用)
微前端
MPA 没啥好说,成本低,大家都爱用。但如果想要更好地体验,则不妨试试微前端。
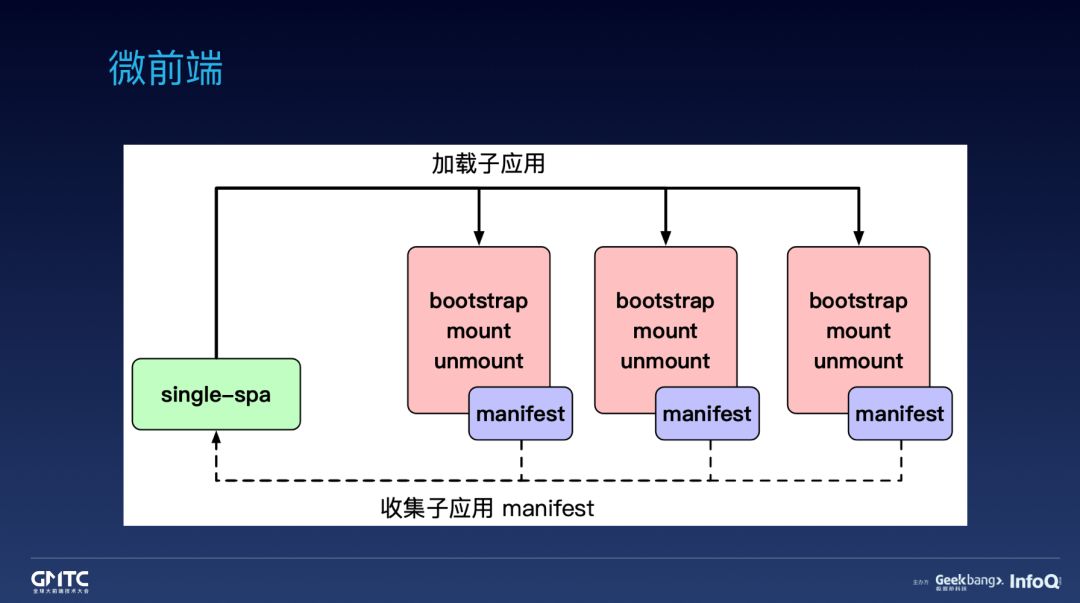
微前端的概念其实已经出来 3 年多了,但社区喊地比较多,给方案比较少,在生产环境应用地就更少了。
我们首先是基于 SingleSPA。
子应用提供 bootstrap、mount 和 unmount 三个生命周期方法。
主应用注册子应用并决定渲染哪个子应用。
这样能 Run 起来,但还只是玩具,要上到生产环境还远远不够,还需要解决很多关键的技术问题。

图中是我们结合实践总结出的关键技术问题。
JS 沙箱和 CSS 隔离,是为了让子应用之间互不影响。
Html Entry 和 Config Entry,是关于如何注册子应用信息。
按需加载、公共依赖加载和预加载,是关于性能的,这些很重要,否则虽然上了微前端,但性能严重下降,或者由于升级引起线上故障,就得不偿失了。
父子应用通讯,顾名思义,无需解释。
子应用嵌套 和 子应用并行 是微前端的进阶应用,在某些场景下会用到。
以上问题,我们都有解决方案,但可能有些还不完美,需要进一步尝试。
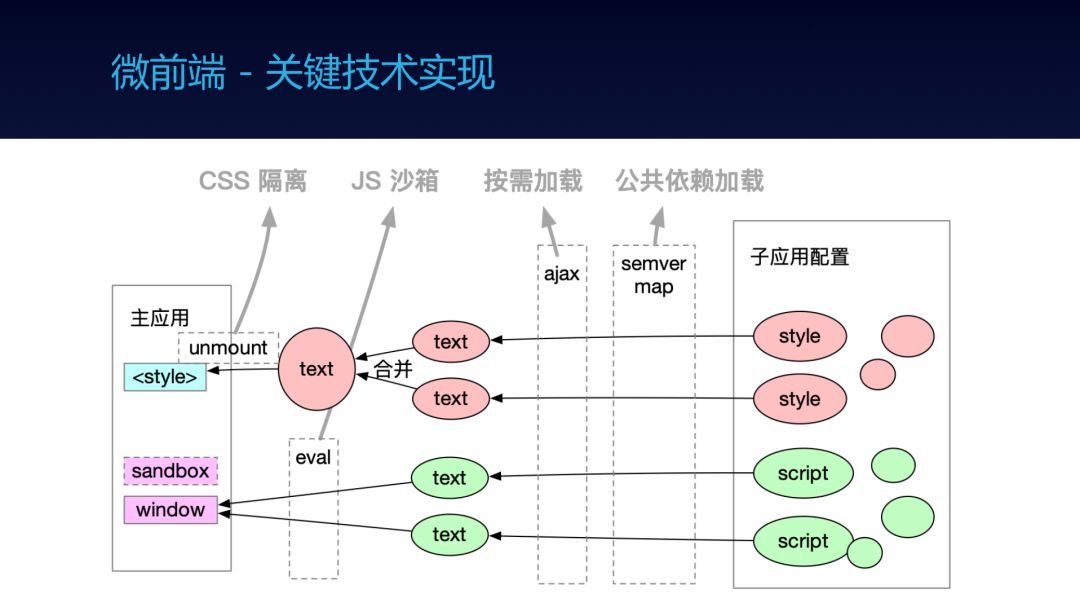
这是部分问题的实现原理。
首先子应用提供样式、脚本等配置,有内联也有外链。
先通过 SEMVER MAP 解决公共依赖不重复加载的问题,比如 antd、react 都只载一份。
然后通过 xhr 拉外链的样式和脚本,实现按需加载。
样式会合并成一份,通过
<style>写入到 DOM 结构,子应用 unmout 时删除,以此做到 CSS 隔离。脚本通过记录和 diff window 变量上的属性来取到子应用导出的生命周期方法,然后通过 eval + 基于 Proxy 实现的 Sandbox 实现 JS 沙箱。
更多实现细节,可以关注文章,分享之后我们会公布。

正如前面所言,我们热衷于开源,所以这套微前端方案在业务上验证过之后,我们就把他开源了:https://github.com/umijs/qiankun
内核取名为乾坤,意义是统一。
然后,搭配 umi 插件使用,效果会更好,比如我们建几个 umi 应用,配置一个为主应用,其他的为子应用,然后串起来就能跑了。

这句话不是我说的,大家如果有发现更好的方案,可以找 @有知 探讨下。
场景完备性
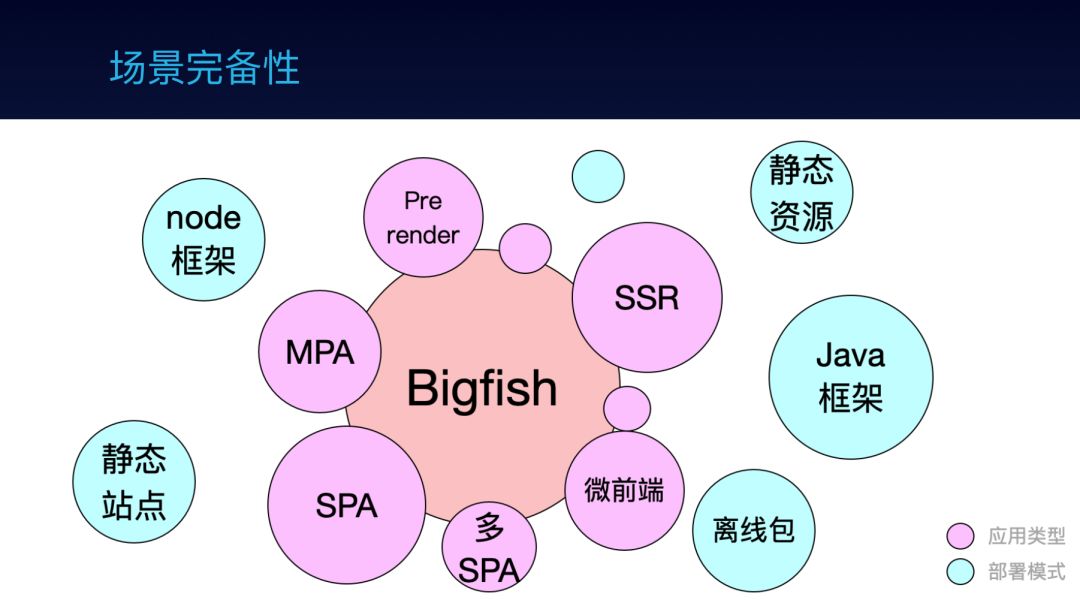
作为一个框架,你得有亮点;而作为一个企业级框架,你得满足需求。而要满足需求,该有的功能就必须有,亮不亮不管,得有,不能让框架成为业务需求的瓶颈。
红色的应用类型方面:
SPA 应该是目前用地最多的一种应用类型,但有时也会不满足需求。
比如运营页面,多个页面之间没有一点点关系,也不需要互相跳转,用 SPA 就没有意义,这时候 MPA 可能更适合。
比如语雀,我们的文档平台,他有前台、有后台、有 PC 端、有无线端,如果整体是一个 SPA,不仅尺寸大,公共依赖的提取是个问题,不同场景之间可能还会相互影响,这时候,多 SPA 的组合会更适合他。
微前端前面已经提过。
SSR 和 Prerender 则是为了更好的浏览器性能,顺便解决 SEO 的问题。
蓝色的部署模式方面:
Node 框架和 Java 框架是框架层的,我们需要通过 HTML 层与这些后端框架做一层对接。
离线包是指支付宝的手机应用钱包,让我们的应用可以快速打包成一个压缩包,上传到手机里。
等等。
当前端框架成为内部的一致选择之后,就会被推着去做很多业务方面的事情,适配各种场景的需求。不过好在我们有插件机制,上面大部分的需求都是业务方同学通过插件和我们一起实现的。
专题研究
除了拳头功能,要做一个框架,还不得不在一些专题上有深入的研究,很多知识点是需要彻底搞透的,这样才能知道如何设计更合适。
路由
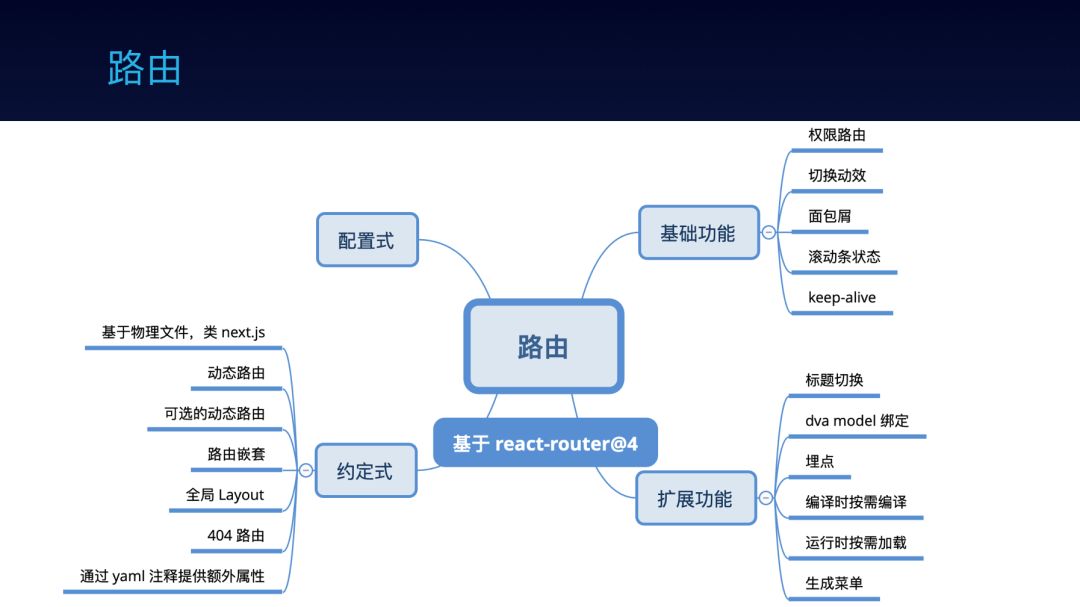
首先,我们既支持配置式路由,也支持约定式路由。配置式是实际需要,约定式是理想:
约定式路由即以物理文件的路径作为路由,可减少冗余的配置层。
但是,这明显没有用 JSON 配置灵活,所以我们在命名上做了一些处理,实现 动态路由 和 嵌套路由。
还不够,比如要给路由加个 title 属性的配置,所以我们又允许通过 yaml 注释为路由提供额外的属性配置。
功能方面我们最先是参考 next.js 做的,但发现 next.js 只支持简单的路由功能,于是自己做了很多扩展,
权限路由,是否允许进入。
切换动效。
面包屑,根据路由生成面包屑。
滚动条状态,清空或保持。
keep-alive,来自 vue router,让路由切掉后不销毁。
由于我们是集中式的路由组织方式,并且管控了路由的渲染逻辑,所以基于路由就可以做很多事,
标题切换,基于路由的标题切换。
dva model 绑定,和按需加载。
埋点,路由切换时埋点。
编译时按需编译。
运行时按需加载,还有各种按需加载策略。
生成菜单,根据路由配置结合 antd 组件自动生成侧边栏菜单。
这个列表每次分享时都会增加,很有想象空间。

这里介绍一个大家可能感兴趣的点,基于路由的按需编译。就是比如我们有 1000 个页面,而调试时只要调其中的 5 个页面,那只编译这 5 个就是最理想的。
这有几种实现方式:
next.js 的,通过动态 entry 实现。
我们的,通过临时文件实现。
临时文件的实现是这样的,
先用 Loading 组件占位。
当用户访问指定 url 时,才把相应路由的组件替换进去。
虽然有些取巧,但简单有效。

我们的编译是基于 webpack 的,诚如大家所料,启动速度还是比较慢的,尤其是项目大了之后。为了让使用者体验更好,我们在这边也做了很多尝试,有正常的方式,也有不正常的方式。
正常的方式有:
dll,把不会修改到的部分打到 dll 里,避免重复打包。
hard-source,利用物理文件缓存,但由于作者不维护,此方案已废弃。
cache-loader、happypack。
external,比 dll 更有效的提速方案。
硬件升级,简单粗暴有效,有个案例是我们其中一个项目的 ci 需要 12 分钟,换了台机器后,只要 5 分钟,所以有时做很多努力,不如换台机器。
简化配置,只给当前项目需要的配置,比如多一个模块 resolve 规则,或者多载入不需要的 loader,都会降低编译速度。
按需编译,在前面介绍过了。
webpack@5,有时做很多努力,不如升个大版本提升大,参考 node 升级带来的性能提升。以 ant-design-pro 为例试验了下 webpack@5 的物理缓存能力,首次编译需要 37s,二次编译只要 4s!!
Plug'n'Play,和编译关系不大,但能提升依赖安装速度。
进阶优化的有:
auto-external,external 虽然效果好,但配置麻烦,所以我们封装了一个插件解决配置麻烦的问题。
uglifyjs hash cache,构建差不多 70% 时间是在做压缩,如果能把不需要压缩的不压缩,压缩过的不重复压缩,那会快很多。
“变态”优化的有:
我们现在都在用 webpack,大家也可以想想,我们是否一定要用 webpack?
我们目前是,三年之后可能就不是了。在上云的大环境下,云端跑 webpack 不仅成本高,而且效率低,我们可能会考虑低成本的方案,比如 codesandbox 或 stackbliz 的云编译方案,也有可能会借助 rust 提升编译器运行效率,现在社区已经有一些尝试了。
并且,随着浏览器的发展,已经可以在浏览器里用 esm 这种格式,所以未来也可能不再需要编译器或者只要做一层很薄的合并操作。

性能优化是每个框架和每个前端都逃不开的点,从我 10 年前做前端起就关注这个点了,到目前方法有些变化,但性能优化依然很重要。下面我们的一些尝试,
按需加载,通常是以路由为维度的,但这里还有些细节的点,比如加载到哪一层的路由,子路由是否应该合并到一个文件里,和路由相关的数据流文件和国际化文件如何按需加载,等等。
一键切框架,对于一些无线场景,切成小尺寸的 react 实现能大幅降低产物大小,但需格外小心兼容问题。
公共文件提取策略。
SSR + Prerender。
Prefetch 和 Preload。
modern mode,如果大家有听说过,对,就是 vue-cli 的那个 modern mode
目前为止,因为浏览器的差异,我们仍需处理浏览器的兼容问题。不过比第一代前端需要处理 IE6 的兼容问题已经好多了。
关于补丁方案:
组件不打补丁,这点上很多人有认知误区,组件会做语法转换,但不会包含补丁,因为包含补丁会造成冗余。
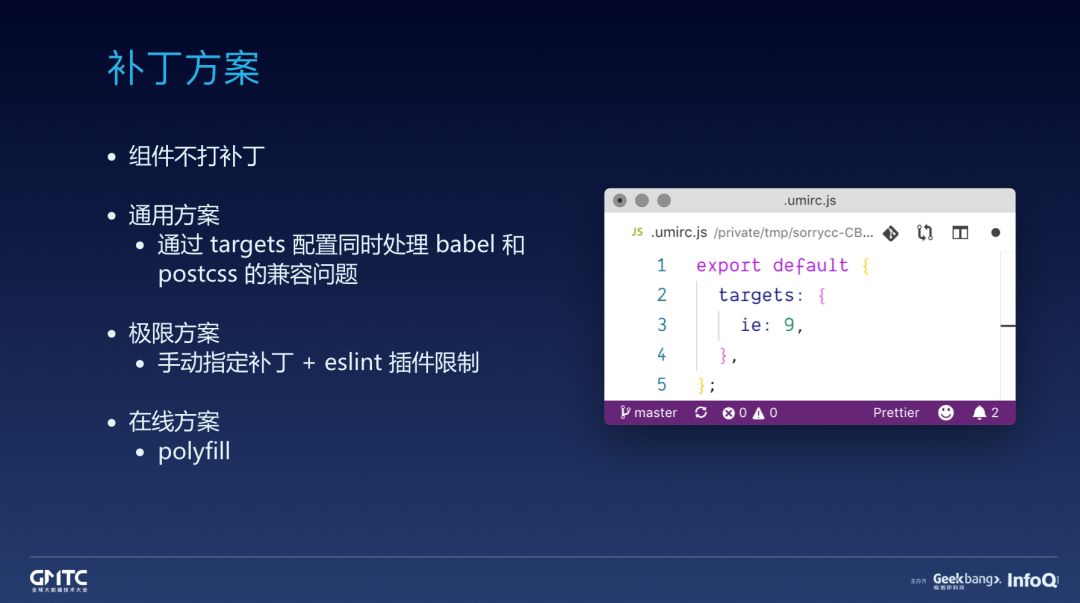
目前最常用的常规方案,如右图所示,通过 targets 配置配需要兼容啥浏览器的啥版本,实现上要注意需同时给到 babel 和 postcss,处理 JS 和 CSS。
某些场景会很在意性能,多一个字节都舍不得,比如无线,他们会追求 极限方案,强制写死就打某几个补丁,然后通过 eslint 插件限制不能使用需要补丁的那些 es 语法,用了就报错。
最后是我个人理解的终极方案,在线补丁服务 + 本地特性检测,本地特性检测可以保证特性的最小化,在线补丁服务可以区分浏览器差异,保证特性浏览器下载固定补丁列表时的最小化。
编辑器插件是框架非常重要的配套设施,很多功能在框架层其实没法做,尤其是用了大量的约定之后,编码时会损失代码提示方面的支持,利用编辑器插件就能弥补这一点。
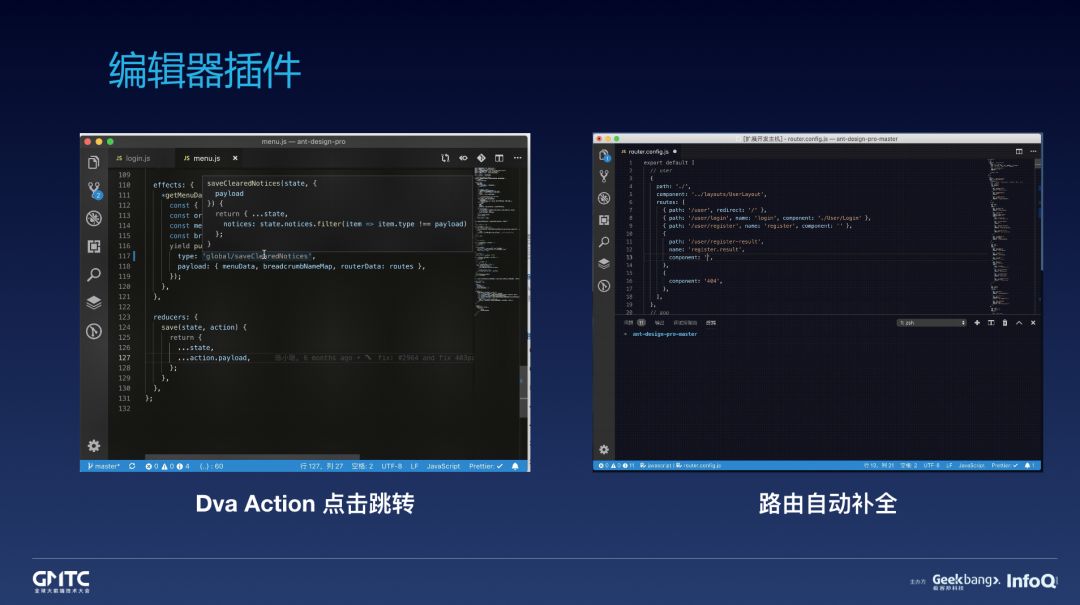
举两个例子,
比如,dva 的数据流方案基于 redux,而 redux 的 action 是基于字符串,很难利用 TypeScript 特性做自动提示。借助 vscode 插件即可做到这一点。
再比如,umi 的路由配置是指向路由组件的路径字符串,框架层做不到提示补全,借助 vscode 插件也可以做到。

测试方面基本上和大家都一样,包含单测、UI 测试、e2e 测试和集成测试,基本方案是基于 Jest + test-react-library + Puppeteer。
但是,大家都知道业务同学很忙,没有太多时间写测试。所以我们如果能有个基于路由的自动化测试方案,让业务不写代码也能确保每个路由都能正常运行,也是个不错的选择。
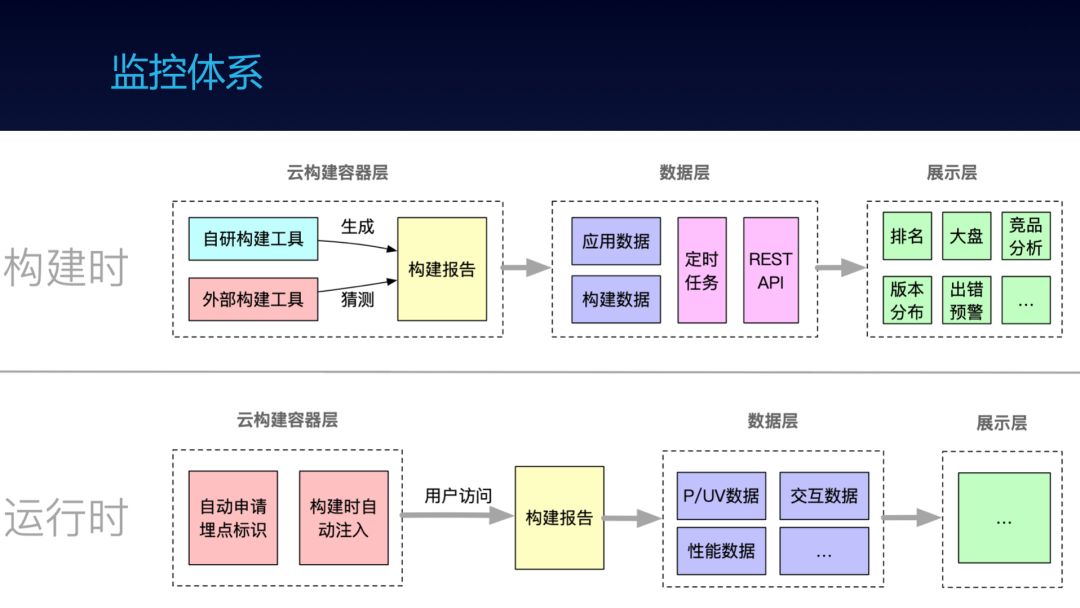
这是我们的监控体系,有了数据,才能知己知彼,有的放矢。
分构建时和运行时。
构建时在云构建容器层去生成构建报告,我们自研的工具比较好办,但就算在蚂蚁内部,也还是其他工具的存在,比如直接用 webpack 做构建的,或者基于 webpack 封装的。对于这些非自研的构建,我们会用猜测的方式,来定位出他是有什么工具进行构建。
数据层会跑大量的定时任务去做数据清理,提供够展示层。展示层提供排名、大盘、版本分布、竞品分析、出错预警等信息。
运行时没啥特别的,大家的方法都差不多。有一点值得一提的是我们会在云构建平台去自动申请埋点标识并在构建时自动注入,让用户免去埋点标识的申请,所有产品自动就会有数据支撑。
这是一些构建时的数据展现示例。
未来和规划
Bigfish + Umi 的内外结合的方式目前看起来还不错,但毕竟是两个团队妥协后的方案,在我们需要服务外部 ISV 时暴露了一些问题:
Bigfish 是内网框架,绑了很多内部服务,不能直接给 ISV 用。
umi 给 ISV 又会存在一些差异。
虽然底层都是 umi,但内外网同学的使用方式还是有很大差别的,导致我们的方案对外时会有额外的成本,以及我们自己在文档等方面的投入上都需要做两次。差异主要是:
配置不完全一致。
文档不统一。
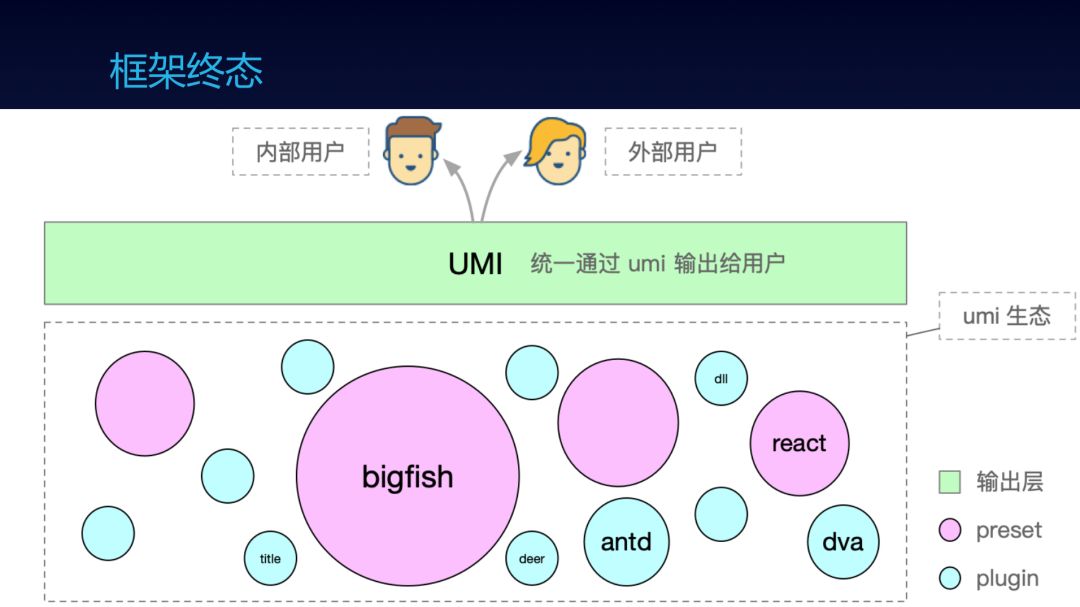
所以,我们要 让内外网的框架方案保持一致。
内部同学也统一用 Umi。
修改 Umi 的插件配置方式,和内部保持一致。
Umi 增加 Preset 的概念,之前的 Bigfish 框架提供 umi-preset-bigfish 服务内部同学。
修改后的这一版是我能预见的框架终态。
- END -
以上是关于干货分享:蚂蚁金服前端框架和工程化实践的主要内容,如果未能解决你的问题,请参考以下文章
第1784期React + Typescript 工程化治理实践
深度 | 蚂蚁金服自动化运维大规模 Kubernetes 集群的实践之路