干货 | 金融级消息队列的演进 — 蚂蚁金服的实践之路
Posted 支付宝技术
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了干货 | 金融级消息队列的演进 — 蚂蚁金服的实践之路相关的知识,希望对你有一定的参考价值。
小蚂蚁说:
消息队列作为一个数据的集散中心,承载了越来越多的场景和数据,从最开始的 OLTP 到 OLAP,甚至再到物联网、人工智能、机器学习等场景,都有很大的想像空间。 在能力上,消息队列现在拥有了数据,拥有了算力,从承载数据走到理解数据。
蚂蚁金服也在思考给消息队列加入算法的能力,让算法走进消息队列,走向下一个阶段 :洞察数据。把这些能力综合起来,打造一个智慧的传输计算服务平台。
还有一个好消息,消息队列作为 SOFA (Scalable Open Financial Architecture )技术体系比较核心的组成部分,后续也会积极拥抱开源和社区。
本文根据蒋涛在 GIAC 2018 的主题分享《金融级消息队列的演进之路》整理编辑,将给大家分享蚂蚁金服消息队列发展过程中的故事,以及这个过程中的架构思考。
金融场景下的消息系统的关键需求
在蚂蚁金服,消息队列已经有十多年的历史了。在07、08年时,我们采用了 ESB 这样的方式来实现消息的机制。
那个时候遇到的最头疼的问题就是丢消息,排查和修复起来非常的痛苦。到了09年,和淘宝共建并上线了新的消息队列系统,丢消息的问题得到了有效的改善。
蚂蚁的业务具有金融级的属性,从这个角度,有哪些比较关键的需求呢? 集中表现为以下四点:
极高的可靠性
举个例子,通过消息去生成账单,如果这个消息不可靠,消息丢了,这个时候会发生什么样的情况呢?客户付了一笔钱,但是在账单或者消费记录里却看不到这笔记录,这个时候就非常困惑了。 因此极高的可靠性指的是:消息不能丢。
极强的一致性
极强的一致性在金融业务当中是非常关键和重要的。 假如做一笔转账操作,因为种种原因,比如网络抖动,转账失败了,如果一致性没有做好,可能还会收到一条做了一笔转账的通知,这个时候系统的数据就不一致了。
持续的可用性
持续的可用性,是指在希望用系统提供的服务能力的时候,这个服务一定是要可用的。 比如说双十一的时候,线上生成一笔订单需要支付,一定希望它能非常顺利的支付完成。再一个,现在线下的场景非常火,到超市去买东西,结账的时候也希望扫码支付要非常顺畅,这都是对可用性的要求。
极高的性能
在蚂蚁金服,每天有千亿级的消息在流转,峰值的 TPS 也达到了千万级。在这么大的体量下,对性能的要求是非常高的。另外,从成本角度和用户的体验的角度,性能也是非常需要关注的地方。
对比经典的消息系统,需要建立哪些机制来满足以上的关键需求?
刚刚提到了金融场景下的四个核心的性能要求,那么具体如何来满足呢?
1. 如何做到极高的可靠性?
ACK 的机制。ACK 机制借鉴了 TCP 里面的思路,通过发送阶段、持久化阶段、投递阶段的 ACK 机制,保证了消息在流转路径的各个环节上的可靠性。
重试的机制,保证了消息在投递出去后,当消费端消费不成功的时候,还可以再次去消费。
通过存储层的持久化机制和可靠性机制来保证消息数据本身的可靠性。
2. 采用两阶段事务消息机制来保证极强的一致性
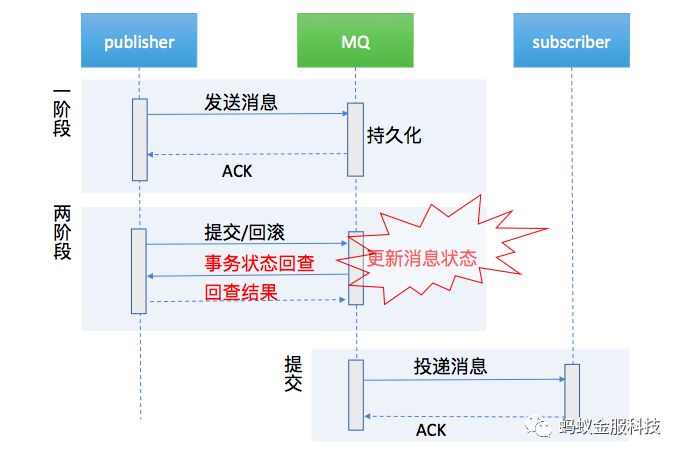
在第一阶段里面,把发消息和业务自己的业务操作放到本地事务中,发出来的是带有未提交状态的消息。 在第二阶段,会根据本地事务执行的情况来决定一阶段发出来的消息是提交还是回滚,如果是回滚,把消息删掉就好了,如果是提交,会去更新这个消息的状态,从未提交改成已提交,接着去做投递的动作。
如果第二阶段中的事务状态通知丢失了,消息服务端会去主动向消息发送端做事务状态回查,直到拿到明确的事务提交或者回滚的回查结果。
3. 持续的可用性的实现
在单机房的时代就在做提升可用性的事情。比如,在应用层面做了线程池的隔离,做了限流、熔断等等。在架构层面去做各种水平伸缩能力,在故障隔离层面做单点的隔离,做集群部署的隔离等等。这些手段提高了系统的可用性。
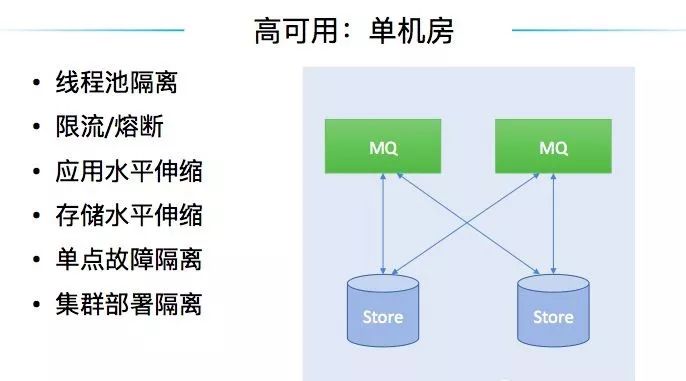
但是,由于受限于单机房部署的架构,当出现机房级别问题的时候,前面的手段就心有余而力不足了。
当然,同城双活架构可以通过业务流量在两个机房之间做切换,也可以通过数据层面的切换等手段来有效的解决机房单点的问题。
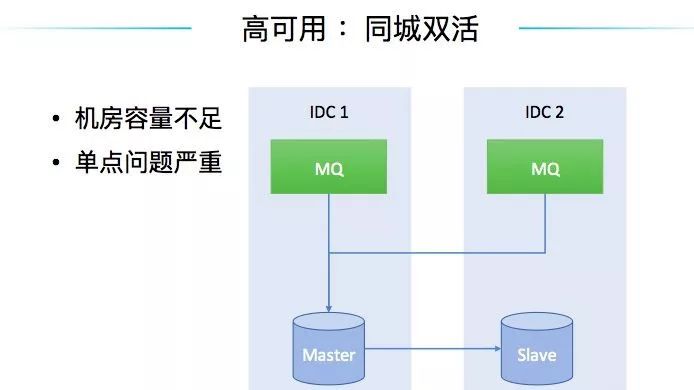
但是,随着业务增长,同城双机房模式在容量和容灾能力上也逐渐无法满足业务发展需求了。
面对同城双活也无法解决的情况,蚂蚁金服沉淀出异地多活 LDC 架构:
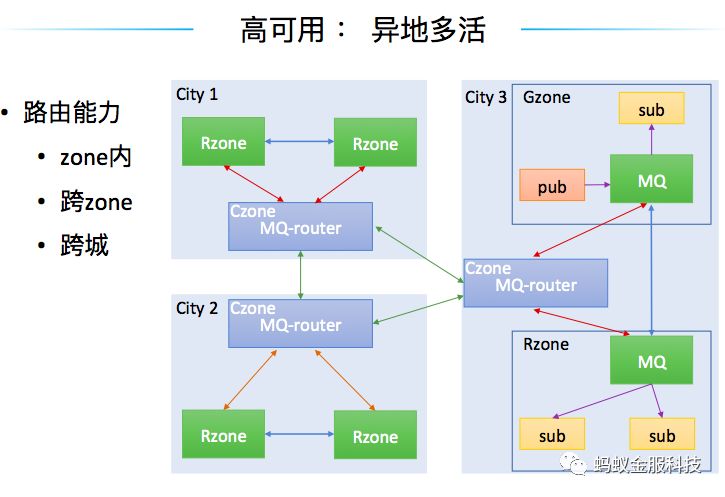
在 LDC 架构下,对消息队列有怎样的需求?
以转账为例,在异地多活的架构下,收款方跟转账人可能在一个逻辑 Zone 里面,也可能不在一个逻辑 Zone 里面,甚至他们可能都不在一个城市。这样带来一个最重要、最核心的需求就是消息队列需要具有非常灵活、非常强大的路由能力,可以做Zone内的路由,可以做同城跨Zone的路由,也可以做跨城跨 Zone 的路由。
在实现上,如果发现这个消息是要做同城跨 Zone 的路由,在消息服务端做了一个打通,通过服务端做转发,当发现是跨城场景的时候,通过一个叫 MQ-router 的系统,对跨城的链路做了一个收敛,也对城市级部署的逻辑做了一个收口,所有需要经过跨城的逻辑全部收口到这样一个系统当中,统一并灵活的支撑了异地多活的架构。
在 LDC 架构下面,消息有趣的应用场景
有一类会员信息数据,比较有特点:
访问量非常大,把它放到缓存里面,降低对后端数据库的压力。
在一次业务请求当中,对这个数据可能有非常多次的访问,所以对数据访问的延迟非常敏感。如果这类数据需要跨城才能访问到的话,跨城带来的延时对业务而言是非常难以接受的。因此就要求这类数据从本城市就能够访问到,每个城市都需要有全量的这类数据。
这类数据对变更的时效性非常敏感。数据变更了,需要非常快的感知到。如果依靠数据库层面的复制机制来做这件事情,会有大概秒级的延迟。
于是,我们设计了一个基于消息的方案,来实现一个城市级的缓存更新的机制。重点给 MQ-router 增加了广播的能力。当这类数据发生变更的时候,以消息的方式发出来,通过 MQ-router 以广播的形式发送到所有城市去,这样就达到了多个城市的缓存实时更新的效果。
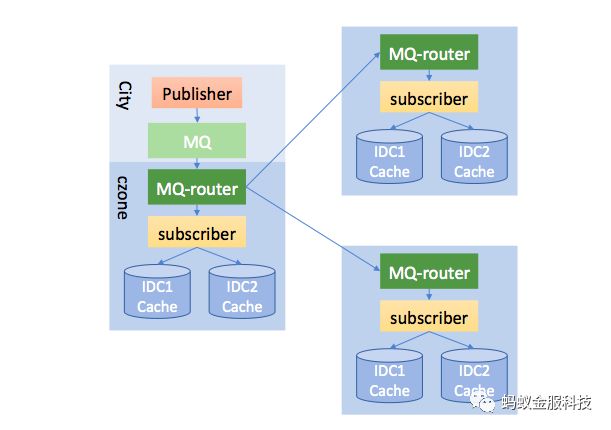
4. 性能方面是持续在打磨的一件事情
消息队列基于 SEDA 模式来实现,引入了自研的高性能网络通信层 SOFABolt来提高消息通信的性能。除此传统的优化手段之外,也在调研和思考更先进的一些方式,比如硬件结合的方式,像DPDK、RDMA这样的技术,去追求更极致的性能。
拥抱大数据时代,我们做了拉模式的消息队列
有很长一段时间,消息队列的研发工作都是围绕着交易、支付、账务等OLTP的业务展开。所以一直在打磨消息队列在OLTP场景下的功能。比如,通过数据库存储保证消息可靠性,通过推的模式提高消息的实时性等。 随着业务场景的扩展,特别是大数据时代的到来,越来越多的OLAP场景出现了。这个时候前面的这些做法,特别是推的这种模式就遇到很多的困难。
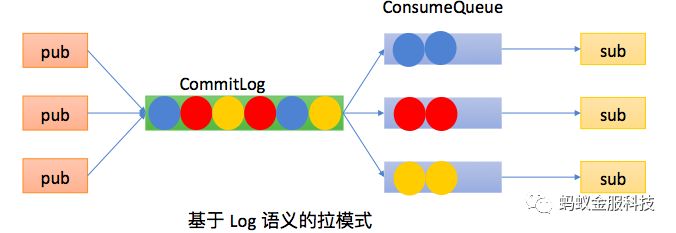
到了这个阶段,我们去做了基于Log语义的拉模式的消息队列。 拉模式消息部署在物理机上,通过顺序写本地磁盘的方式去实现拉的语义。在一定时间内比较有效的支持了OLAP这种场景的需求。
走向计算存储分离的架构,从挂盘模式到 API 模式
随着拉模式的推广,很多 OLTP 的场景也逐渐的采用了拉模式,提出了很多新的需求。比如 OLTP 对数据可靠性要求比较高,对本地文件存储可靠性的问题就非常关注。
由于是基于物理机部署,也遇到很多运维上的难点,比如成本、机型等等的一些问题。特别是物理机机型变化非常多,每次采购可能都不一样,非常难以做标准化。在做容量规划、缩容扩容这些事情时会遇到非常多的困难。
消息是比较重 IO 轻计算的模型,在物理机上就会表现出非常明显的资源配比不均衡的问题。往往是磁盘已经不够用了,但 CPU 还很空闲。基于物理机的运维也很复杂,资源利用率不高、容量规划不好做、扩容缩容困难等问题凸显。
在做这件事情的时候,我们一开始采取了一种比较轻量的方式,称之为挂盘的模式。 通过挂载的方式,将分布式文件系统挂在消息队列应用上面。这个做法的好处是应用系统本身基本上不需要做什么改造。消息数据透明的写到了分布式文件系统上,依靠分布式文件系统提供的三副本高可靠的能力来保障消息数据的可靠性。
在这个阶段还做了一件事情,就是把消息应用的规格做了标准化。可以去制定类似8C、16G、1T 这样的规格,有了标准规格,就可以比较准确的测算某个规格可以顶多少TPS的消息量,这样做容量规划就很容易了。 这个模式上去之后,承载了一些业务,也接受了双十一大促的考验。
于是,我们开始了计算存储分离的第二阶段:API 模式,在性能上有了一个比较明显的提升。 这个模式下,消息服务端要做比较大的改动,趁着这个机会,也做了很多功能方面的增强。比如,加入了对全局固定分区的支持,还有发送幂等与强顺序的能力等。 同时,把数据落地也做了一个改变,原先数据全部集中在一个commit log中,转移到了队列里面去。这样带来的好处是可以在队列级别做更细粒度的配置和管控。
这个架构整体而言是一个相对比较完善的计算存储分离的架构了。在应用层面也做了很多可扩展的设计。
整体上,计算存储分离的模式给消息队列打下比较好的基础,可以跟蚂蚁金服全站的运维模式做很好的适配。
让计算走进消息队列,赋予消息队列计算能力
消息队列承载了越来越多的消息数据,大量的数据流进来再流出去。都说在大数据时代,数据就是金钱,但是可以发现这么多的数据流过消息队列,却没有淘到金。
通过思考这个问题,发现非常关键的一点是因为一直在用一种比较传统的方式去看待消息队列,认为它是消息的一个通道,消息流进来再流出去,使命就结束了。在这样的思路下,着力打造的是它的传输能力,它的存储能力,它的可靠性等。但是却忽略了在大数据时代非常重要的一个能力,就是计算的能力。
带着这个问题去看业界的一些发展,得到了很多新的思路。特别是从Kafka身上得到了很多的启发。
于是我们决定让计算走进消息队列,以 streaming 方式为消息队列增加了一种计算能力,实现了一个轻量级的非中心式的计算框架,既可以嵌入客户端,也可以嵌入消息的服务端,做一些轻量级的计算,支持一些比较通用和轻量的算子和多种计算窗口语义。
至此,消息队列有了传输、存储和计算的能力
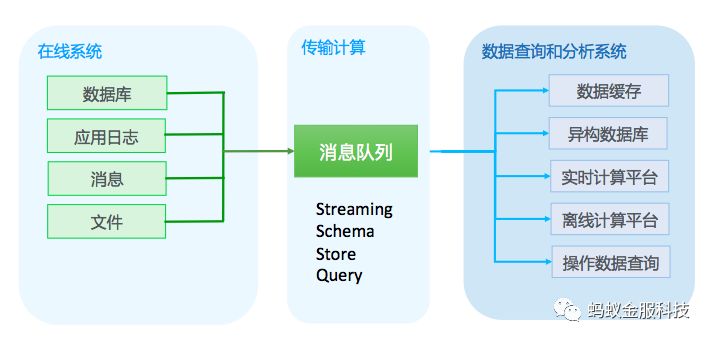
基于这些能力,把消息队列往更大的层面上去推进,构建一个数据传输计算平台。不断丰富消息队列能力,不断拓展越来越丰富的数据源,获取越来越多样的数据,并且把消息投递到更多的目的地去。在传输过程中对消息进行计算,以获得更多计算带来的价值。
总结
通过前面的回顾,我们可以看到,消息队列作为一个数据的集散中心,承载了越来越多的场景和数据。
在能力上,消息队列现在拥有了数据,拥有了算力,正在走过一条从承载数据到理解数据的道路。接下来,我们也在思考给消息队列加入算法的能力,让算法走进消息队列。 这样就可以向下一个阶段 -- 洞察数据再迈出一步,就可以把这些能力综合起来,去打造一个智慧的传输计算服务平台。这样消息数据不仅是流转过消息队列,还可以经过更多的计算和加工,更轻快更实时的发挥更大的价值。
交流社群

欢迎访问 http://github.com/alipay 了解更多 SOFA 开源信息(也可阅读原文查看),共同打造SOFAStack 。更多最新分布式架构干货,请长按关注下方二维码了解一下~

— END —
蚂蚁金服科技,只为分享干货
您的转发是对我们最大的支持
欢迎在文章下方留言与我们进行交流哦~
以上是关于干货 | 金融级消息队列的演进 — 蚂蚁金服的实践之路的主要内容,如果未能解决你的问题,请参考以下文章