性能调优案例 | 数据卸载看我的
Posted 厦开系统联盟
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了性能调优案例 | 数据卸载看我的相关的知识,希望对你有一定的参考价值。
Q
有没有什么比较快速高效的数据卸载方法和工具?
对于ORACLE数据库,数据卸载和装载最高效的工具当属数据泵(expdp/impdp),但它们只能用于ORACLE自身数据库的转储,不够通用。如果实际工作中需要将ORACLE数据库中的表卸载为文本文件,或是将文本文件数据装载到ORACLE数据库中,就需要另找高明了。
将文本文件装载到ORACLE中,建议采用我们之前介绍的SQL*LOADER(参见:),通过合理设置参数它将是我们数据装载的一把利器。
Q
如果想把ORACLE数据卸载为文本文件,可有什么高招?
随着业务的不断发展,数据库中的数据越来越多,数据的迁移也越来越频繁。实际工作中可能会碰到将ORACLE数据库中几十G、上百G,甚至TB级别的数据卸载为文本文件,这时对数据卸载的性能就有很高的要求。
 结合自身的工作经历,本文将为大家推荐一个专业的大数据量文本导出工具:sqluldr2。
结合自身的工作经历,本文将为大家推荐一个专业的大数据量文本导出工具:sqluldr2。
sqluldr2
sqluldr2可以到http://www.anysql.net中下载,它是楼方鑫使用C语言和OCI接口开发的一个工具,现已有多个版本更新,推荐使用linux版本。
本文将以linux64位的版本为例,介绍其用法和性能相关的参数设置,帮助大家高效完成数据卸载工作。


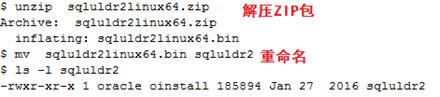
先将sqluldr2linux64.zip(84k)包上传到linux服务器的任一目录下,解压zip包,而后将sqluldr2linux64.bin重命名为sqluldr2:
sqluldr2 keyword=value [ keyword=value ......]
参数列表:


user:必输参数,源数据库的用户名密码和连接串;
sql和query参数二选一,如果整表导出,可以直接使用query=table_name;如果导出的表有字段选择和过滤条件,建议使用sql参数,先将select语句先编辑为一个文件,而后使用sql=select文件名;
field:指定字段的间隔符,比如使用竖线分割:field='|',还可以使用ASCII码表示,默认是逗号。record指定记录的分隔符,默认就是回车换行,大多情况不再指定。
file:指定卸载的文件名,为了便于区别,建议都进行有意义的命名。同时建议使用.gz后缀,这样卸载后的文件会压缩为gz文件,减少空间占用,也便于文件传输和保存。如果使用其他后缀名将不进行压缩。log记录卸载日志,也建议进行指定,便于后续查看卸载情况。
head:默认是NO,即不打印出字段名,一般卸载后需要进行文件装载的操作都使用NO,避免装载时报错。如果为了保存数据且便于后续查看,可以考虑设置为YES,它将会在文本文件的第一行显示字段名称。
parfile:如果参数比较多,还可编辑一个文件存放参数,而后直接使用parfile。
其他参数都是选填参数,可不设置。由于我们使用此工具,主要用于大数据量的卸载,因此重点关注和性能相关的几个参数:
array、read、hash、sort、serial,合理设置这些参数可以更好地发挥出sqluldr2的功效。
array:fetch队列的大小,默认是50,最大2000,建议设置为2000,减少fetch的次数,提高导出性能。
read:指定Oracle一次读取的数据块数,默认是DB_FILE_MULTIBLOCK_READ_COUNT的值,建议设置为128,即一次读取出128个数据块。
sort:指定排序区大小,建议设置为256。
hash:指定hash区大小,建议设置为256。
serial:建议设置为1,即全表扫描时使用direct path read,提高select的效率。
了解完sqluldr2的用法和参数后,我们就可以开始进行实战演练了。建议使用sql的写法,并将常用的参数编辑为文件保存,这样卸载将会更为灵活。
◇ 先编辑卸数的SQL语句:
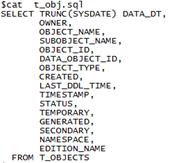
◇ 接着编辑一个存放参数的文件,后续可以考虑共用:

◇ 启动卸载进程:
./sqluldr2 test/test@testdbsql=t_obj.sql file=t_obj_0718.gz log=t_obj_0718.log parfile=par.txt
◇ 卸载日志:
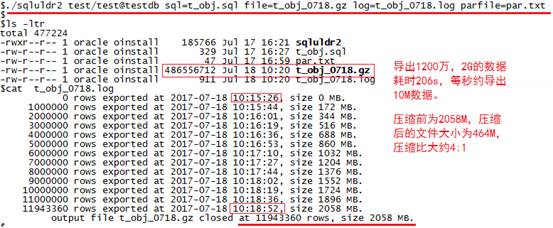
卸载2G的数据,耗时206s,这些时间都消耗在了哪里呢?先跟踪SQL的执行耗时,可以看到每次执行SELECT耗时42s:

因此卸数的主要耗时是在写文本文件、压缩文本文件上。想要提高性能建议使用网络带宽大、IO性能好的磁盘进行卸载操作。
为了获得压缩的时间消耗,我们测试下不压缩卸数的性能情况:
./sqluldr2 test/test@testdb sql=t_obj.sql file=t_obj_0718.dat log=t_obj_07182.log parfile=par.txt
不压缩卸数日志:
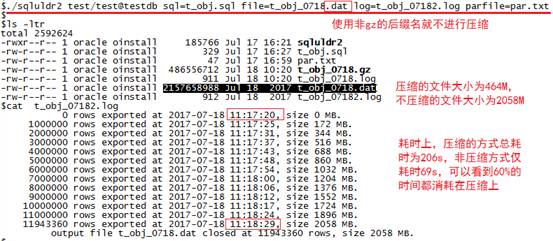
通过压缩与非压缩比较,可以计算出各步骤耗时:

可以看到大部分时间都耗在文件压缩上,如果文本文件可以不压缩,那将可节省大量的时间。

实际工作中,为了减少存储空间占用和加快网络传输,大多都需要进行压缩,那是否还有优化途径?
方法总比困难多,压缩期间的主要消耗是CPU资源,且一个压缩进程只会占用一个CPU资源,因此只要CPU个数足够多,可以考虑启动多个卸数进程,充分利用CPU资源来并行完成压缩。实测卸载效率和进程数量基本成正比。
而且如果要卸载的表比较大,卸载为一个文件,对应文件将会很大,并不是最优的选择。并行卸载可以将其拆分为多个文件,减少了每个文件的大小,更有利于文件传输和后续的数据导入。
并行卸载的实现也很简单,只需将select语句进行切分,让select语句抽取不同的数据,而后启动多个sqluldr2进程,分别卸载出对应的数据即可。如果select语句较为耗时,还可对select语句加上并行度,提升select查询效率。
我们取了一张2300万、近80G的表,分别启动1个2个4个6个进程进行测试:
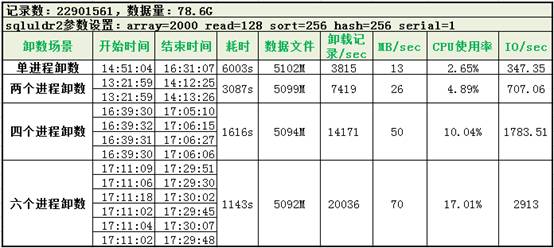

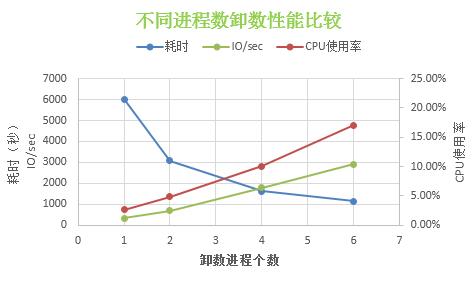
随着进程数的增加,耗时基本呈线性下降:1个进程6000s,2个进程就只需3000s,4个进程1600s,6个进程就仅需1100s,耗时大约是1个进程的1/6。服务器的CPU和IO资源随着进程数的增加也基本呈线性增长。6个进程时卸载效率达70MB/s,80G的数据20分钟左右就可卸载完成。
某系统存在将大表卸载为文本文件的需求,由于数据量大(200G左右),每次卸载需要10个小时。
我们推荐项目组使用sqluldr2工具,将参数设置为前面的建议值,并启用8个并行进行卸载,卸数耗时降低到了1.5小时,满足了2小时的时间窗口要求!


总结:
工欲善其事,必先利其器。本文主要是和大家介绍sqluldr2这个牛X的卸数工具,并介绍了一些提升卸载效率的方法!
1、善用sqluldr2工具
2、合理设置sqluldr2的参数
3、启动多个sqluldr2进程,并行完成数据卸载任务。
希望对大家后续在实际工作中碰到需要卸数的操作时能有所帮助!
厦门开发中心测试与推广支持处 系统与非功能小组出品
编辑:方妍
以上是关于性能调优案例 | 数据卸载看我的的主要内容,如果未能解决你的问题,请参考以下文章