性能调优案例
Posted mingyuewu
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了性能调优案例相关的知识,希望对你有一定的参考价值。
性能调优案例
| 时间 | 2021-09-02 |
|---|---|
| 环境 | centos7.6,jmeter,redis,mysql,java应用 |
一、jmeter的命令行使用
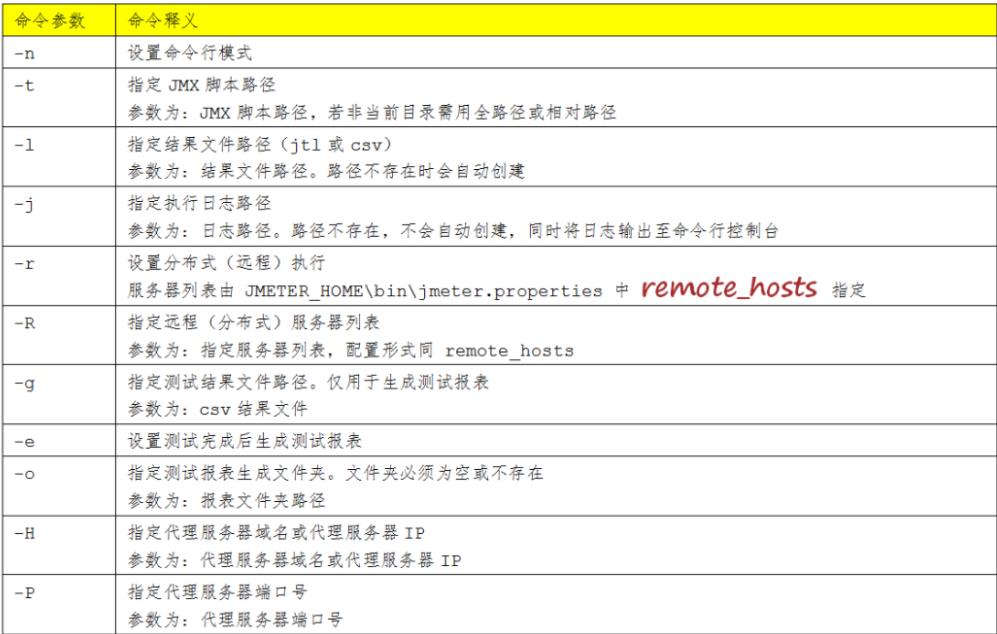
举例:
# 以命令行方式运行,执行test.jmx测试脚本,将测试结果保存到result.jtl中
jmeter -n -t test.jmx -l result.jtl
# 指定IP分布式运行
jmeter -n -t test1.jmx -R 192.168.10.25:1036 -l report\\01-result.csv -j report\\01-log.log
jmeter命令输出格式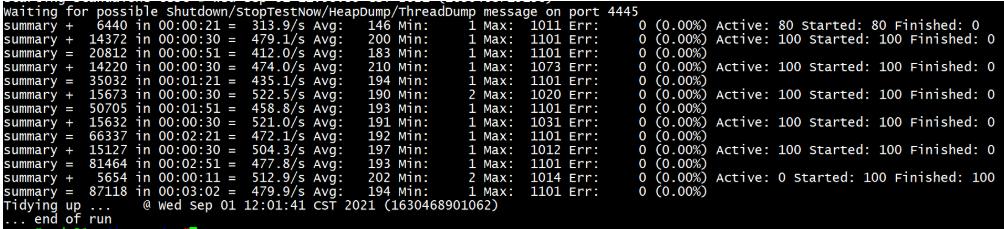
summary + 6440 in 00:00:21 313.9/s 代表 在21秒内执行了6440个测试用例,平均每秒执行313.9个,即TPS=313.9
6440/21=306.7 ,TPS是怎么计算的?
Avg 平均响应时间,Min 最短响应时间,Max最大响应时间
active:当前在执行的线程数,start:开始执行的线程数,finish:结束的线程数
第一条,in 00:00:21 active 80 代表有80个线程已启动,到第二行 in 00:00:30时active 为100 代表100个线程都已启动
线程数:模拟虚拟用户
请求数:这些虚拟用户发起的请求数量,请求数>线程数
二、JVM调优js、 jmap 、 jstat
(1)官网文档 https://docs.oracle.com/javase/1.5.0/docs/tooldocs/share/jmap.html
(2) Jmap命令
Java Virtual Machine Memory Map生成虚拟机的内存转储快照(heapdump)文件。jmap命令可以获得运行中的jvm的堆的快照,从而可以离线分析堆,以检查内存泄漏,检查一些严重影响性能的大对象的创建,检查系统中什么对象最多,各种对象所占内存的大小等等。可以使用jmap生成Heap Dump。
参考文档:https://blog.csdn.net/jiang_zf/article/details/79540234
-heap 显示Java堆详细信息,如使用哪种回收器、参数配置、分代状况等
-histo 显示堆中对象统计信息,包括类、实例数量和合计容量
查看java堆的使用情况
###开启卡关服务:先启动reids,rocketmq,mysql等中间件数据库,再开启卡管应用,查看应用的日志看启动是否正常
[root@iZbp1ecjj2jqnihvrx19piZ ehcServer]# jps # 查看使用JVM的进程
8027 Jps
7967 WrapperSimpleApp
[root@iZbp1ecjj2jqnihvrx19piZ ehcServer]# jmap -heap 7967
Attaching to process ID 7967, please wait...
Debugger attached successfully.
Server compiler detected.
JVM version is 25.231-b11
using thread-local object allocation.
Parallel GC with 2 thread(s) # gc(垃圾回收)线程默认cpu核心数
Heap Configuration: #堆内存初始化配置
MinHeapFreeRatio = 0 #-XX:MinHeapFreeRatio设置JVM堆最小空闲比率
MaxHeapFreeRatio = 100 #-XX:MaxHeapFreeRatio设置JVM堆最大空闲比率
MaxHeapSize = 1073741824 (1024.0MB) #-XX:MaxHeapSize=设置JVM堆的最大大小,默认1/4内存大小
NewSize = 357564416 (341.0MB) #-XX:NewSize=设置JVM堆的‘新生代’的默认大小
MaxNewSize = 357564416 (341.0MB) #-XX:MaxNewSize=设置JVM堆的‘新生代’的最大大小
OldSize = 716177408 (683.0MB) #-XX:OldSize=设置JVM堆的‘老生代’的大小
NewRatio = 2 #-XX:NewRatio=:‘新生代’和‘老生代’的大小比率
SurvivorRatio = 8 #-XX:SurvivorRatio=设置年轻代中Eden区与Survivor区的大小比值
MetaspaceSize = 21807104 (20.796875MB)
CompressedClassSpaceSize = 1073741824 (1024.0MB)
MaxMetaspaceSize = 17592186044415 MB
G1HeapRegionSize = 0 (0.0MB)
Heap Usage:
PS Young Generation
#新生代区内存分布,包含伊甸园区+1个Survivor区
Eden Space: #Eden区内存分布
capacity = 284164096 (271.0MB)
used = 149041648 (142.13719177246094MB)
free = 135122448 (128.86280822753906MB)
52.44914825552064% used
From Space:
capacity = 36700160 (35.0MB)
used = 36678544 (34.97938537597656MB)
free = 21616 (0.0206146240234375MB)
99.94110107421875% used
To Space:
capacity = 36700160 (35.0MB)
used = 0 (0.0MB)
free = 36700160 (35.0MB)
0.0% used
PS Old Generation
capacity = 716177408 (683.0MB)
used = 152398744 (145.3387680053711MB)
free = 563778664 (537.6612319946289MB)
21.279468229190496% used
26423 interned Strings occupying 2749688 bytes.
(3)调优参数
调参默认标准:jvm默认xmx(最大堆内存)是机器内存1/4,gc线程默认cpu核心数,gc算法parallel
-Xmx3550m #JVM最大可用内存
-Xms3550m #设置JVM初始内存为3550m。此值可以设置与-Xmx相同,以避免每次垃圾回收完成后JVM重新分配内存。
USEG1GC UseParallelGC #GC的方式。一般用并行GC https://www.cnblogs.com/yuanzipeng/p/13374690.html
wrapper.java.additional.2=-XX:+UseParallelGC
wrapper.java.addtional.11=-Xms1g
wrapper.java.addtional.12=-Xmx1g
(4)检查调优情况jstat
动态查看:使用jstat统计一下jvm在内存回收中发生的频率耗时以及是否有full gc,使用这个数据来评估一内存配置参数、gc参数是否合理。YGC YGCT FGC FGCT
[root@iZbp1ecjj2jqnihvrx19piZ conf]# jps
16723 Jps
22046 WrapperSimpleApp
[root@iZbp1ecjj2jqnihvrx19piZ conf]# jstat -gc 22046
S0C S1C S0U S1U EC EU OC OU MC MU CCSC CCSU YGC YGCT FGC FGCT GCT
3584.0 3584.0 2304.0 0.0 342016.0 173818.6 699392.0 257431.9 81944.0 77727.9 9776.0 9054.6 530 17.479 3 1.521 19.001
#S0C:第一个幸存区的大小
#S1C:第二个幸存区的大小
#S0U:第一个幸存区的使用大小
#S1U:第二个幸存区的使用大小
#EC:伊甸园区的大小
#EU:伊甸园区的使用大小
#OC:老年代大小
#OU:老年代使用大小
#MC:方法区大小
#MU:方法区使用大小
#CCSC:压缩类空间大小
#CCSU:压缩类空间使用大小
#YGC:年轻代垃圾回收次数
#YGCT:年轻代垃圾回收消耗时间
#FGC:老年代垃圾回收次数
#FGCT:老年代垃圾回收消耗时间
#GCT:垃圾回收消耗总时间 (多少时间算正常呢?越少越好)
#参考文章:https://www.cnblogs.com/sxdcgaq8080/p/11089841.html
三、Redis调优
1 设置redis能够使用的的最大内存
maxmemory 2g
2 到达最大内存后的替换策略
#如果到达了最大内存,需要设置替换策略,(类比操作系统管理内存空间,LRU、FIFO等算法替换内存)
maxmemory-policy volatile-lru
当 Redis 内存使用达到 maxmemory时,需要选择设置好的 maxmemory-policy进行对老数据的置换。
(1) noeviction: 不进行置换,表示即使内存达到上限也不进行置换,所有能引起内存增加的命令都会返回error
(2)allkeys-lru: 优先删除掉最近最不经常使用的key,用以保存新数据
(3)volatile-lru: 只从设置失效(expire set)的key中选择最近最不经常使用的key进行删除,用以保存新数据
(4)allkeys-random: 随机从all-keys中选择一些key进行删除,用以保存新数据
(5)volatile-random: 只从设置失效(expire set)的key中,选择一些key进行删除,用以保存新数据
(6)volatile-ttl: 只从设置失效(expire set)的key中,选出存活时间(TTL)最短的key进行删除,用以保存新数据
疑问 key 的过期时间是在代码里设置的吗,过期时间设置为多少合适?如果不设置过期时间的话,感觉allkeys-lru算法比较合适。
选择maxmemory-policy的建议:
(1)在所有的 key 都是最近最经常使用,那么就需要选择 allkeys-lru 进行置换最近最不经常使用的 key,如果你不确定使用哪种策略,那么推荐使用 allkeys-lru
(2)如果所有的 key 的访问概率都是差不多的,那么可以选用 allkeys-random 策略去置换数据
(3)如果对数据有足够的了解,能够为 key 指定 hint(通过expire/ttl指定),那么可以选择 volatile-ttl 进行置换
3 如果业务不需要redis持久化,则关闭
RDB 默认开启,注释掉三行sava即可关闭
AOF 默认关闭 appendonly no
redis关闭持久化后,每个redis请求不用刷盘,可提升性能
四、Mysql优化
调优标准:尽量少读磁盘和跨网络
1 sql语句优化
2 索引优化
3 配置优化
innodb_buffer_pool_size=3G
innodb_flush_log_at_trx_commit=2
sync_binlog=10
(1)innodb_buffer_size
innodb_buffer_size缓存的内容
数据缓存 – 这绝对是它的最重要的目的
索引缓存 – 这使用是的同一个缓冲池
缓冲 – 更改的数据(通常称为脏数据)在被刷新到硬盘之前先存放到缓冲
存储内部结构 – 一些结构如自适应哈希索引或者行锁也都存储在InnoDB缓冲池
innodb_buffer_size设置的大小
在一个独立的只使用InnoDB引擎的MySQL服务器中,根据经验,推荐设置innodb-buffer-pool-size为服务器总可用内存的50%~80%
更改innodb_buffer_size的命令
root身份
mysql> SET GLOBAL innodb_buffer_pool_size=size_in_bytes;
参考链接:https://blog.csdn.net/weixin_41782053/article/details/87269158
(2) innodb_flush_log_at_trx_commit (log_buffer何时写入磁盘内存映射cache)
mysql缓存(log_buffer)------------>磁盘内存映射(cache)----------------->磁盘
日志写入磁盘要经过两个缓存,一个是mysql自己的log_buffer,另一个是操作系统的磁盘内存映射缓存(磁盘和内存之间的cache)
mysql可以 调用 flush 主动将log buffer 刷新到磁盘内存映射,也可以调用 fsync 强制操作系同步磁盘映射文件到磁盘。还可以同时调用 flush + fsync, 将缓存直接落盘。
innodb_flush_log_at_trx_commit = 0 就是每秒调用 flush + fsync ,定时器Mysql自己维护。Mysql崩溃会丢失1s数据
innodb_flush_log_at_trx_commit = 1 就是实时调用 flush + fsync ,没法批处理,性能很低。
innodb_flush_log_at_trx_commit = 2 就是实时flush ,定时 fsync,定时器OS维护。操作系统崩溃会丢失1s数据
参考链接:https://blog.csdn.net/u010833547/article/details/109293213
(3) sync_binlog=0|n(磁盘内存映射何时写入磁盘)
sync_binlog=0 由操作系统决定什么时候写入,性能最好,风险最大。
当事务提交之后,MySQL不做fsync之类的磁盘同步指令刷新binlog_cache中的信息到磁盘,而让Filesystem自行决定什么时候来做同步,或者cache满了之后才同步到磁盘。
sync_binlog=n 每当提交n次事务后,mysql调用fsync将磁盘内存映射写入磁盘。
当每进行n次事务提交之后,MySQL将进行一次fsync之类的磁盘同步指令来将binlog_cache中的数据强制写入磁盘。
https://www.cnblogs.com/jpfss/p/10772952.html
五、报错及总结:
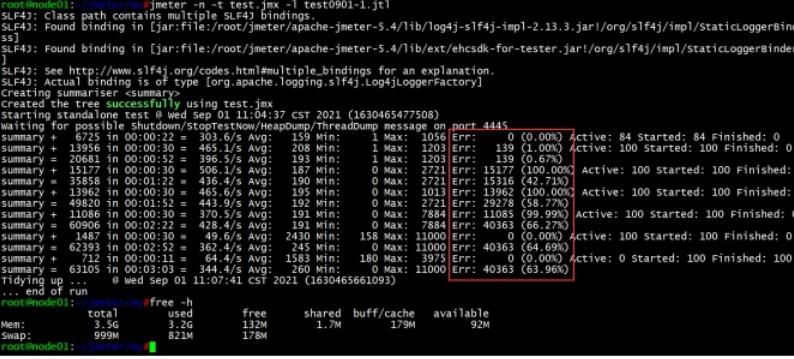
1 jmeter执行测试用例时,测试用例错误率高
可能是服务器资源不足。
2 压测的时候,nginx的日志access.log没有变化
df -h 磁盘满了, 或者nginx配置中没有开启日志,或者用户请求没有经过nginx 。
3 了解用户请求的路径
例如:
用户发出request请求------->Nginx-------->java应用------->redis缓存---------->mysql数据库
用户发出request请求-------->java应用---------->redis缓存----------->mysql数据库
4 压测执行流程
启动服务:启动中间件、数据库,再启动服务
检查服务:查看应用的日志验证启动成功
执行压测
查看请求的响应时间:比如在ngixn日志中加人$request_time
查看中间件、数据库的状态:比如jvm的GC次数时间,mysql的慢日志
查看系统硬件指标:CPU利用率,内存利用率,查找到较消耗资源的进程。
以上是关于性能调优案例的主要内容,如果未能解决你的问题,请参考以下文章