AutoML 助力 AI 性能调优
Posted 谷歌开发者
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了AutoML 助力 AI 性能调优相关的知识,希望对你有一定的参考价值。
文 / Suyog Gupta 与 Mingxing Tan
数十年来,正如摩尔定律所述,通过缩小每个芯片内的晶体管尺寸,计算机处理器的性能每隔几年便可提升一倍。随着缩小晶体管尺寸的难度愈来愈大,业界开始将重点聚焦于开发针对特定领域的架构(如硬件加速器),以继续提升计算能力。机器学习领域尤为如此,人们致力于为神经网络加速构建专门的架构。讽刺的是,这些架构虽已在数据中心以及边缘计算平台稳步发展,但是很少有神经网络会特定优化,以充分利用这些底层硬件。
今天,我们高兴地宣布推出 EfficientNet-EdgeTPU,这是一系列源自 EfficientNets 的图像分类模块,经过自定义,可在 Google 的 Edge TPU(一个高能效的硬件加速器,开发者可通过 Coral Dev Board 和 USB 加速器使用)上运行,发挥最佳性能。通过此类模块自定义,Edge TPU 不仅可以提供实时图像分类性能,同时可以实现堪比数据中心中大尺寸计算密集型模型所能提供的精度。
注:EfficientNet-EdgeTPU
https://github.com/tensorflow/tpu/tree/master/models/official/efficientnet/edgetpu
使用 AutoML 为 Edge TPU 自定义 EfficientNets
经证明,EfficientNets 能够在图像分类任务中取得 SOTA(State Of The Art) 精度,同时大幅缩减模型大小,降低计算复杂性。为了构建专为利用 Edge TPU 的加速器架构而设计的 EfficientNets,我们调用了 AutoML MNAS 框架,并使用在 Edge TPU 上高效执行的构件块扩增了 EfficientNet 的初始神经网络架构搜索空间(下文详述)。我们还构建并集成了一个“延迟时间预测器”模块,通过在周期精确的架构模拟器上运行模型,可估算模型在 Edge TPU 上执行时的延迟时间。AutoML MNAS 控制器通过实现强化学习算法来搜索此空间,同时试图使奖励最大化,这是一个预测延迟时间和模型准确性的联合函数。根据以往经验,我们知道,当模型适合芯片上内存时,Edge TPU 的能效和性能往往可以最大化。因此,我们还修改了奖励函数,以便为满足此约束的模型提供更高的奖励。
注:AutoML MNAS 框架 链接
https://ai.googleblog.com/2018/08/mnasnet-towards-automating-design-of.html
强化学习 链接
https://en.wikipedia.org/wiki/Reinforcement_learning
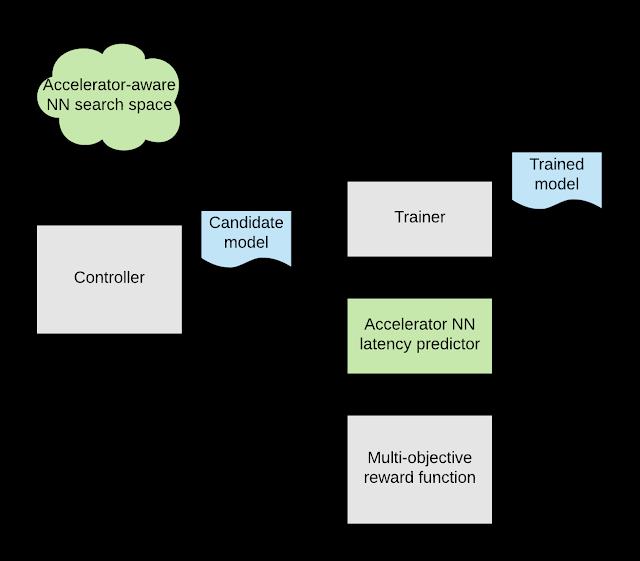
用于设计自定义 EfficientNet-EdgeTPU 模型的 AutoML 总体流程
搜索空间设计
执行上述架构搜索时,必须考虑到 EfficientNets 主要依靠深度可分卷积 (depthwise-separable convolutions),这种卷积可对常规卷积进行分解,从而减少参数数量和计算量。然而,针对某些配置,虽然计算量更大,但常规卷积可更高效地使用 Edge TPU 架构,且执行速度也更快。虽然手动制作使用不同构建块最佳组合的网络不无可能(尽管很枯燥),但使用这些经加速器优化的块扩增 AutoML 搜索空间是一种更具扩展性的方法。
注:深度可分卷积 链接
https://arxiv.org/abs/1610.02357
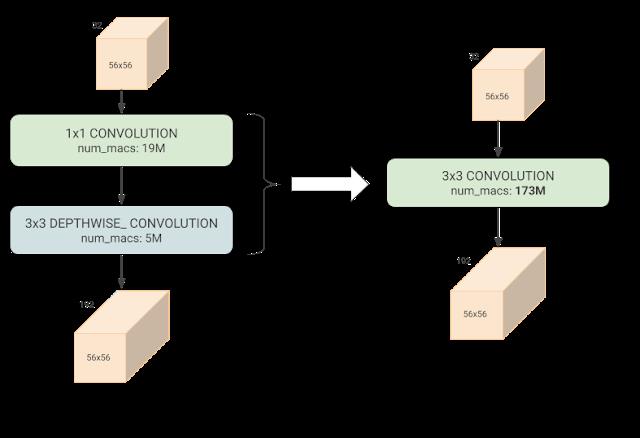
常规 3x3 卷积(右图)的计算(乘法和加法 (mac) 运算)量比深度可分卷积(左图)更多,但对于某些输入/输出形状,前者由于使用具有约三倍效果的硬件,因而在 Edge TPU 上的执行速度更快
有些模块,如 swish 非线性和 squeeze-and-excitation 块,是需要需要修改 Edge TPU 编译器才能获得完全支持。在搜索空间中移除它们,就可以产生很容易移植到 Edge TPU 硬件的模型。这些操作往往会略微提高模型质量,因此,从搜索空间将其清除后,我们可以有效指示 AutoML 去发现可弥补任何潜在质量损失的替代网络架构。
注:swish 非线性 链接
https://arxiv.org/pdf/1710.05941.pdf
squeeze-and-excitation 块 链接
https://arxiv.org/abs/1709.01507
模型性能
上述神经架构搜索 (Neural Architecture Search,NAS) 生成一个基准模型,即 EfficientNet-EdgeTPU-S,该模型随后使用 EfficientNet 的 复合扩缩法 进行扩展,从而生成 -M 和 -L 模型。复合扩缩法选择最佳的输入图像分辨率扩缩、网络宽度和深度扩缩组合,从而构建更大、更精确的模型。-M 和 -L 模型可实现更高的精度,但延迟时间有所提高,参见下图。
通过为 Edge TPU 硬件提供专门的网络架构,EfficientNet-EdgeTPU-S/M/L 模型在延迟时间和精度方面的表现均超越 EfficientNets (B1)、ResNet 和 Inception。尤其是,我们的 EfficientNet-EdgeTPU-S 可以实现更高的精度,而其运行速度比 ResNet-50 快 10 倍
注:ResNet 链接
https://arxiv.org/abs/1512.03385
Inception 链接
https://arxiv.org/abs/1602.07261
有趣的是,NAS 生成的模型在网络初始部分十分广泛地使用了常规卷积,在初始部分,深度可分卷积在加速器上执行时往往有效性不如常规卷积。显然,这突出了一个事实:在优化通用 CPU 模型(例如减少运算总数)时通常进行的取舍并不一定是硬件加速器的最佳选择。此外,即使不使用高深运算,这些模型也可以获得高精度。与其他图像分类模型(如 Inception-resnet-v2 和 Resnet50)相比,EfficientNet-EdgeTPU 模型不仅更准确,而且在 Edge TPU 上的运行速度也更快。
这是首次使用 AutoML 构建经加速器优化的模型的实验。基于 AutoML 的模型自定义不仅可扩展至各种硬件加速器,还可用于依靠神经网络的不同应用。
从 Cloud TPU 训练到 Edge TPU 部署
我们已在 GitHub 代码库中公开 EfficientNet-EdgeTPU 的训练代码和预训练模型。我们使用 TensorFlow 的训练后量化工具(post-training quantization tool )将浮点训练模型转化为兼容 Edge TPU 的整型量化模型。对于这些模型,训练后量化效果很好,精度损失微乎其微(约 0.5%)。如需从训练检查点导出量化模型的脚本,请于文末获取。如需了解 Coral 平台的更新,请参阅 Google 开发者博客中的博文。如需完整参考材料和详细说明,请查看 Coral 网站。
致谢
特别感谢 Google Brain 团队的 Quoc Le、Hongkun Yu、Yunlu Li、Ruoming Pang 和 Vijay Vasudevan;Google Coral 团队的 Bo Wu、Vikram Tank 和 Ajay Nair;Google Edge TPU 团队的 Han Vanholder、Ravi Narayanaswami、John Joseph、Dong Hyuk Woo、Raksit Ashok、Jason Jong Kyu Park、Jack Liu、Mohammadali Ghodrat、Cao Gao、Berkin Akin、Liang-Yun Wang、Chirag Gandhi 和 Dongdong Li。
EfficientNets
https://ai.googleblog.com/2019/05/efficientnet-improving-accuracy-and.html
Edge TPU
https://coral.withgoogle.com/docs/edgetpu/faq/
Coral Dev Board
https://coral.withgoogle.com/products/dev-board
USB 加速器
https://coral.withgoogle.com/products/accelerator
GitHub 代码库
https://github.com/tensorflow/tpu/tree/master/models/official/efficientnet/edgetpu
训练后量化工具
https://www.tensorflow.org/model_optimization/guide/quantization
获取模型脚本
https://github.com/tensorflow/tpu/blob/master/models/official/efficientnet/edgetpu/README.md
Coral 平台更新相关
https://developers.googleblog.com/2019/08/coral-summer-updates-post-training.html
Coral 网站
https://coral.withgoogle.com/docs/
以上是关于AutoML 助力 AI 性能调优的主要内容,如果未能解决你的问题,请参考以下文章
为数据库性能调优插上 AI 的翅膀 | 调优测试框架 Matrix 团队访谈