tf性能调优神器
Posted Qunar技术沙龙
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了tf性能调优神器相关的知识,希望对你有一定的参考价值。
看了就要关注我哦!!

孟晓龙,2016年7月入职 Qunar,是机票事业部大数据AI解决方案的算法小驼,主要负责机票事业部机器学习相关的模型开发维护部署工作,喜欢读书,健身,打守望先锋。
本文主要介绍如何用 tensorboard 与 timeline 监控 tensorflow 的性能,可以直接引用最后的封装类
天下武功,唯快不破。机器学习解决方案也是如此,由于是一门实验性科学,No free lunch 定理告诉我们不同的超参、架构是否适合独特的数据集一直都是未知数,能否快速实验大量的 idea ,快速迭代解决方案一直都是提升效果的关键。因此才有各式分布式训练的使用,imageNet 可以一小时训练完成才如此的激动人心。
然而很多同学在使用 tensorflow 的时候会遇到诸如 GPU 使用率突然 10% ,然后等了好久的 0% ,突然 10% 反复交替,明显没有榨干 GPU 的性能,白白浪费了时间。那么这时候到底是哪里出现了问题呢?是数据读入的流程过慢,还是某个 Op 是性能瓶颈?然后我们来到了面向运气编程的环节。
PS:可能有些同学不知道如何查看 GPU 利用率,这里简单说下,会的可以跳过。在 linux 系统正确安装完 N卡 一系列的依赖后,直接使用 nvidia-smi 查看 GPU 的显存占用率与 GPU 利用率,但这是静态的,想要观看动态的数据可以用 watch -n 1 nvidia-smi 。具体的命令其他参数可以通过 -h 查看。
为了不再面向运气编程,我们需要一个监控器,可以监控 Op 的运行时间,找到造成性能瓶颈的原因,针对性的优化,那么有哪些方法可以进行监控呢?
当当当当, tensorboard 闪亮登场。一般大部分情况都只是使用它进行 graph 的查看,或者一些 loss/acc 之类的监控,其实 tensorboard 还可以监控运行运行时长。
在介绍使用方法之前,需要介绍两个类:
1.tf.RunOptions 2.tf.RunMetadata
其实他们都是 ProtocolMessage ,具体定义在如下可以找到:
https://github.com/tensorflow/tensorflow/blob/r1.8/tensorflow/core/protobuf/config.proto
(如果在 IDE 中是不会给出这两个里面有什么成员的,这时候就需要查看这个文件了,跟 GPUOptions 一样)
tf.RunOptins 有 TraceLevel 这个成员变量,还有4个常量: 1.FULL_TRACE 2.HARDWARE_TRACE 3.NOT_RACE 4.SOFTWARE_TRACE 他们控制了 trace 的一些东西。
tf.RunMetadata 中有三个成员: 1.stepstats 代表当前 step 的一些统计性的 trace 2.costgraph 表示运行时计算成本的图 3.partitiongraphs 代表 executors 的分区图
Ok,介绍完这两个 Protocol 后,我们看下 sess.run 的函数定义:
这里有 4 个入参,前两个大家都很熟悉了,后面两个就需要传入上面两个 Protocol 了,来个具体的例子。
这里有个需要注意的点,在 writer.addrun_metadata 输入第二个参数 tag 的时候需要每次的名字都不相同,一般可以用迭代轮数。
在 Tensorboard 中查看是这个样子:
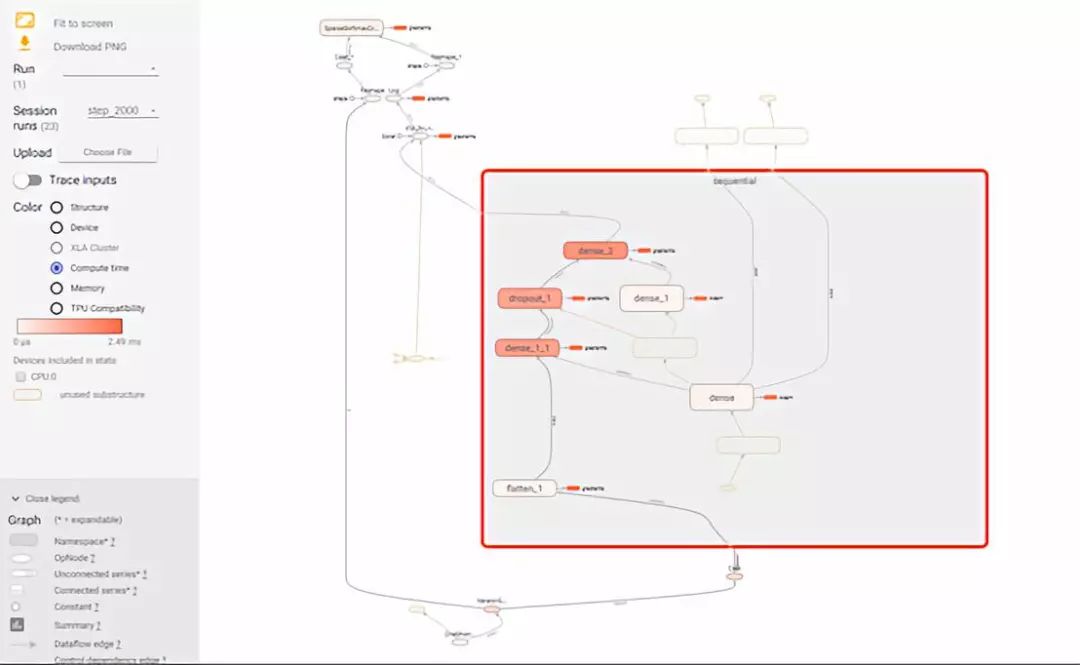
点击 compute time ,每个 op 是按照颜色来区分运行时间的,其实这时候已经足够解决大部分的问题了,那么有些同学可能想要知道每个 Op 精准的消耗时长,这时候就需要使用 timeline 了。
Timeline 定义在 tensorflow.python.client 中,这里我们看一个 stackOverflow 中的答案。
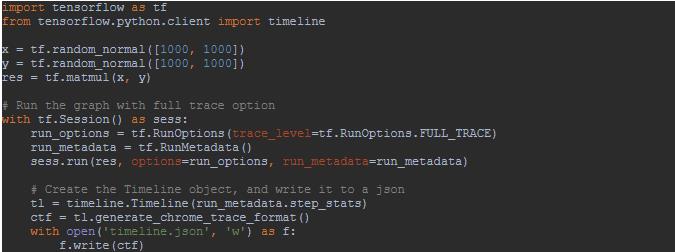
从上面代码可以看出 Timeline 的入参是 runmetadata 的 stepstats 成员,然后再导出可以用 chrome 读入的 json 格式。之后打开 chrome ,输入 chrome://tracing ,并点击 load 按钮,将刚才的 json 导入,就可以看到如下的页面:

右侧还有各种辅助的按钮,可以放大,观察某一部分等等操作,点击中间的某个颜色块还可以得到该块的上游连接线。
Ok,到现在为止我们已经可以得到各 Op 的耗时图了,那么这仅是一次 run 的图,如果想看看是不是多次运行的时间或者模式是不是一致,怎么办呢?在 chrome 中只记录了每个事件的定义与其运行时长,我们需要手动的合并多个 run 的统计数据,这里引用 Illarion Khlestov 的代码,如下:
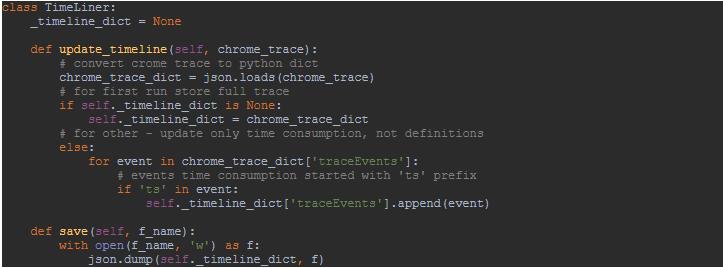
这样,我们就可以查看多次 run 的耗时图了,这里我们使用 mnist 的一个例子,单次运行时间图与多次运行时间图分别如下(个人感觉聚合是有点问题的,如果有懂的大神麻烦告知一下)


多次放大一部分,如下:

那么每次都搞这么一下,感觉好麻烦,那么可不可以封装成一个函数,每次传入规定的参数就可以得到这些结果呢?当然可以,我们可以封装成如下的函数:
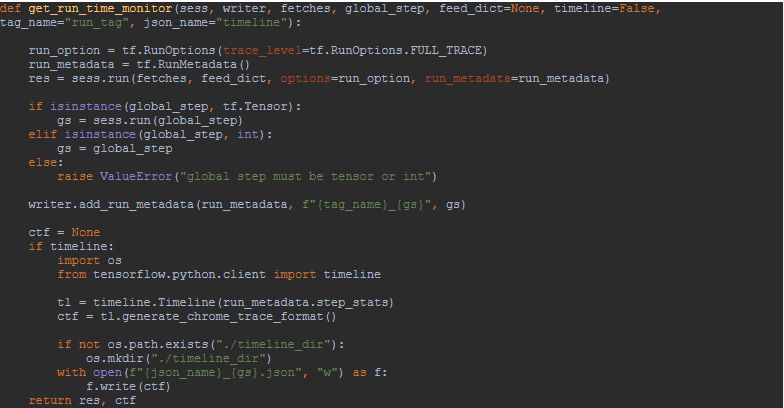
总结一下,我们从面向运气编程进化到可以监控 tensorflow 的性能,其中包括如何查看 GPU 利用率,如何使用 tensorboard 查看运行时长以及使用 timeline 得到具体时长数据。
最后,想跟大家讨论下,既然 chrome 可以查看时长数据,可不可以用它查看别的数据呢?它的 trace 的定义格式是什么样的呢?我们一般都是在服务器上运行 tensorflow 的代码,服务器一般是没有浏览器的,那么每次都要从服务器上拉 json 下来,有没有现成的工具更简单的完成这些重复工作呢?欢迎留言。
本人水平有限,如有谬误欢迎指导。 参考资料:
https://stackoverflow.com/questions/34293714/can-i-measure-the-execution-time-of-individual-operations-with-tensorflow/37774470#37774470
https://github.com/tensorflow/tensorflow/blob/r1.8/tensorflow/core/protobuf/config.proto
https://towardsdatascience.com/howto-profile-tensorflow-1a49fb18073d
https://github.com/ikhlestov/tensorflow_profiling
以上是关于tf性能调优神器的主要内容,如果未能解决你的问题,请参考以下文章