MongoDB网络传输处理源码实现及性能调优——体验内核性能极致设计
Posted OPPO互联网技术
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MongoDB网络传输处理源码实现及性能调优——体验内核性能极致设计相关的知识,希望对你有一定的参考价值。
点击关注“OPPO互联网技术”,阅读更多技术干货
开源MongoDB代码规模数百万行,本篇文章内容主要分析MongoDB网络传输模块内部实现及其性能调优方法,学习网络IO处理流程,体验不同工作线程模型性能极致设计原理。另外一个目的就是引导大家快速进行百万级别规模源码阅读,做到不同大工程源码”举一反三”快速阅读的目的。
此外,MongoDB网络工作线程模型设计非常好,不仅非常值得数据库相关研发人员学习,中间件、分布式、高并发、服务端等相关研发人员也可以借鉴,极力推荐大家学习。
1. 如何阅读数百万级大工程内核源码
MongoDB内核源码由第三方库third_party和MongoDB服务层源码组成,其中MongoDB服务层代码在不同模块实现中依赖不同的third_party库,第三方库是MongoDB服务层代码实现的基础(例如:网络底层IO实现依赖asio-master库, 底层存储依赖wiredtiger存储引擎库),其中第三方库也会依赖部分其他库(例如:wiredtiger库依赖snappy算法库,asio-master依赖boost库)。
虽然MongoDB内核源码数百万行,工程量巨大,但是MongoDB服务层代码实现层次非常清晰,代码目录结构、类命名、函数命名、文件名命名都非常一目了然,充分体现了10gen团队的专业精神。
说明:MongoDB内核除第三方库third_party外的代码,这里统称为MongoDB服务层代码。
本文以MongoDB服务层transport实现为例来说明如何快速阅读整个MongoDB代码,我们在走读代码前,建议遵循如下准则:
1.1 熟悉MongoDB基本功能和使用方法
首先,我们需要熟悉MongoDB的基本功能,明白MongoDB是做什么用的,用在什么地方,这样才能体现MongoDB的真正价值。此外,我们需要提前搭建一个MongoDB集群玩一玩,这样也可以进一步促使我们了解MongoDB内部的一些常用基本功能。千万不要急于求成,如果连MongoDB是做什么的都不知道,或者连MongoDB的运维操作方法都没玩过,直接读取代码会非常不适合,没有目的的走读代码不利于分析整个代码,同时阅读代码过程会非常痛苦。
1.2 下载代码编译源码
熟悉了MongoDB的基本功能,并搭建集群简单体验后,我们就可以从github下载源码,自己编译源码生成二进制文件,编译文档存放于docs/building.md 代码目录中,源码编译步骤如下:
下载对应releases中对应版本的源码
进入对于目录,参考docs/building.md文件内容进行相关依赖工具安装
执行buildscripts/scons.py编译出对应二进制文件,也可以直接scons mongod mongos这样编译。
编译成功后的生产可执行文件存放于./build/opt/mongo/目录
在正在编译代码并运行的过程中,发现以下两个问题:
1. 编译出的二进制文件占用空间很大,如下图所示:
从上图可以看出,通过strip处理工具处理后,二进制文件大小已经和官方二进制包大小一样了。
2. 在一些低版本操作系统运行的时候出错,找不到对应stdlib库,如下图所示:
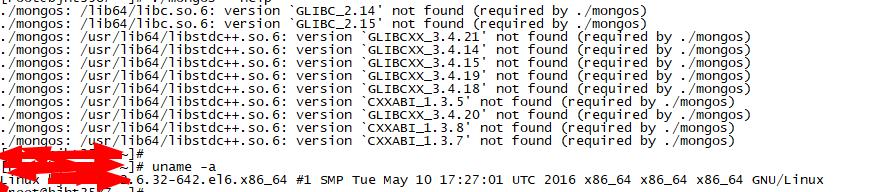

如上图所示,当编译出的二进制文件拷贝到线上运行后,发现无法运行,提示libstdc库找不到。原因是我们编译代码时候依赖的stdc库版本比其他操作系统上面的stdc库版本更高,造成了不兼容。
解决办法:编译的时候编译脚本中带上-static-libstdc++,把stdc库通过静态库的方式进行编译,而不是通过动态库方式。
1.3 了解代码日志模块使用方法,试着加打印调试
由于前期我们对代码整体实现不熟悉,不知道各个接口的调用流程,这时候就可以通过加日志打印进行调试。MongoDB的日志模块设计的比较完善,从日志中可以很明确的看出由那个功能模块打印日志,同时日志模块有多种打印级别。
1. 日志打印级别设置
启动参数中verbose设置日志打印级别,日志打印级别设置方法如下:
Mongod -f ./mongo.conf -vvvv
这里的v越多,表明日志打印级别设置的越低,也就会打印更多的日志。一个v表示只会输出LOG(1)日志,-vv表示LOG(1) LOG(2)都会写日志。
2. 如何在.cpp文件中使用日志模块记录日志
如果需要在一个新的.cpp文件中使用日志模块打印日志,需要进行如下步骤操作:

1.4 学会用gdb调试MongoDB代码
Gdb是linux系统环境下优秀的代码调试工具,支持设置断点、单步调试、打印变量信息、获取函数调用栈信息等功能。gdb工具可以绑定某个线程进行线程级调试,由于MongoDB是多线程环境,因此在用gdb调试前,我们需要确定调试的线程号,mongod进程包含的线程号及其对应线程名查看方法如下:
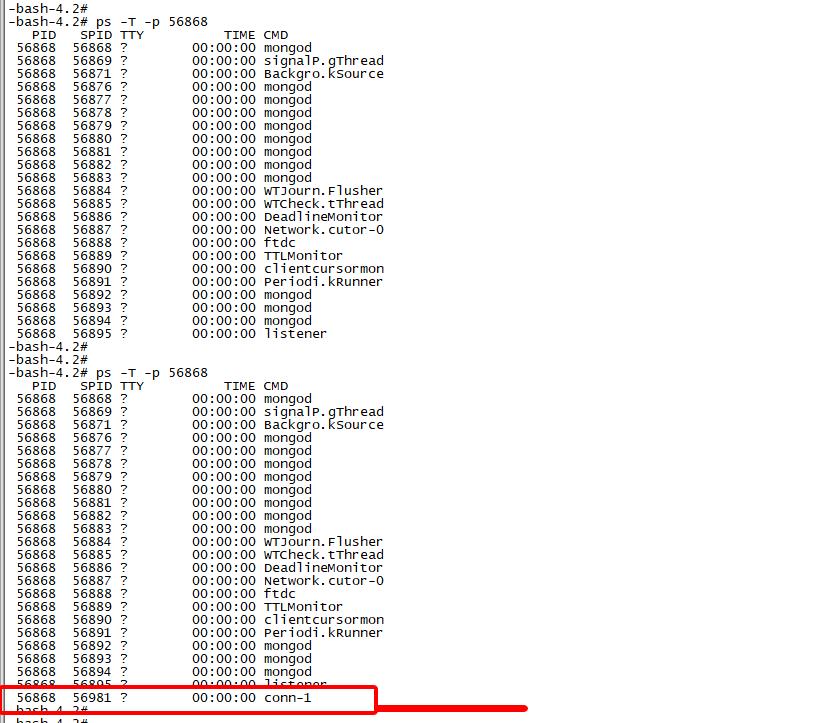
注意:在调试mongod工作线程处理流程的时候,不要选择adaptive动态线程池模式,因为线程可能因为流量低引起工作线程不饱和而被销毁,从而造成调试过程因为线程销毁而中断,synchronous线程模式是一个链接一个线程,只要我们不关闭这个链接,线程就会一直存在,不会影响我们理解MongoDB服务层代码实现逻辑。 synchronous线程模式调试的时候可以通过mongo shell链接mongod服务端端口来模拟一个链接,因此调试过程相对比较可控。
在对工作线程调试的时候,发现gdb无法查找到mongod进程的符号表,无法进行各种gdb功能调试,如下图所示:
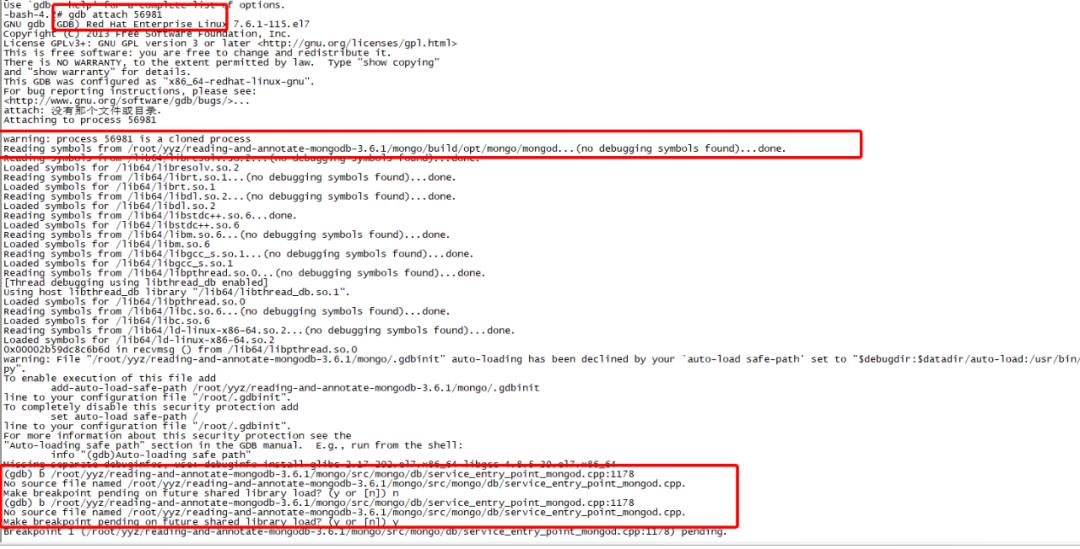
上述gdb无法attach到指定线程调试的原因是无法加载二进制文件符号表,这是因为编译的时候没有加上-g选项引起,MongoDB通过SConstruct脚本来进行scons编译,要启用gdb功能需要在scons编译代码的时候指定gdbserver选项:
scons --gdbserver=GDBSERVER -j 2。
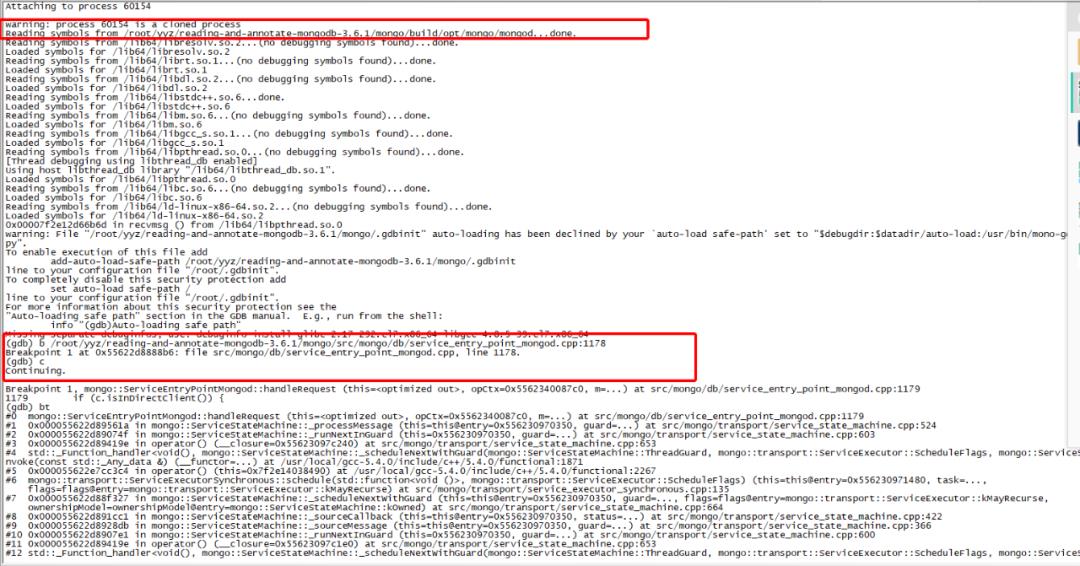
编译出新的二进制文件后,就可以gdb调试了,如下图所示,可以很方便的定位到某个函数之前的调用栈信息,并进行单步、打印变量信息等调试:
1.5 熟悉代码目录结构、模块细化拆分
在进行代码阅读前还有很重要的一步就是熟悉代码目录及文件命名实现,MongoDB服务层代码目录结构及文件命名都有很严格的规范。下面以truansport网络传输模块为例,transport模块的具体目录文件结构:

从上面的文件分布内容,可以清晰的看出,整个目录中的源码实现文件大体可以分为如下几个部分:
message_compressor_*网络传输数据压缩子模块
service_entry_point*服务入口点子模块
service_executor*服务运行子模块,即线程模型子模块
service_state_machine*服务状态机处理子模块
Session*回话信息子模块
Ticket*数据分发子模块
transport_layer*套接字处理及传输层模式管理子模块
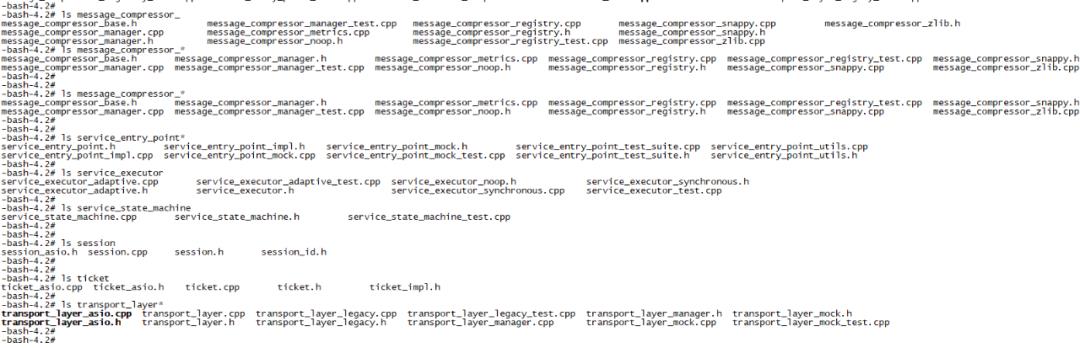
通过上面的拆分,整个大的transport模块实现就被拆分成了7个小模块,这7个小的子模块各自负责对应功能实现,同时各个模块相互衔接,整体实现网络传输处理过程的整体实现,下面的章节将就这些子模块进行简单功能说明。
1.6 从main入口开始大体走读代码
前面5个步骤过后,我们已经熟悉了MongoDB编译调试以及transport模块的各个子模块的相关代码文件实现及大体子模块作用。至此,我们可以开始走读代码了,mongos和mongod的代码入口分别在mongoSMain()和MongoDBMain(),从这两个入口就可以一步一步了解MongoDB服务层代码的整体实现。
注意:走读代码前期不要深入各种细节实现,大体了解代码实现即可,先大体弄明白代码中各个模块功能由那些子模块实现,千万不要深究细节。
1.7 总结
本章节主要给出了数百万级MongoDB内核代码阅读的一些建议,整个过程可以总结为如下几点:
提前了解MongoDB的作用及工作原理。
自己搭建集群提前学习下MongoDB集群的常用运维操作,可以进一步帮助理解MongoDB的功能特性,提升后期代码阅读的效率。
自己下载源码编译二进制可执行文件,同时学会使用日志模块,通过加日志打印的方式逐步开始调试。
学习使用gdb代码调试工具调试线程的运行流程,这样可以更进一步的促使快速学习代码处理流程,特别是一些复杂逻辑,可以大大提升走读代码的效率。
正式走读代码前,提前了解各个模块的代码目录结构,把一个大模块拆分成各个小模块,先大体浏览各个模块的代码实现。
前期走读代码千万不要深入细节,捋清楚各个模块的大体功能作用后再开始一步一步的深入细节,了解深层次的内部实现。
从main()入口逐步开始走读代码,结合log日志打印和gdb调试。
跳过整体流程中不熟悉的模块代码,只走读本次想弄明白的模块代码实现。
2. MongoDB内核网络传输transport模块实现原理
从1.5章节中,我们把transport功能模块细化拆分成了网络传输数据压缩子模块、服务入口子模块、线程模型子模块、状态机处理子模块、session会话信息子模块、数据分发子模块、套接字处理和传输管理子模块,总共七个子模块。
实际上MongoDB服务层代码的底层网络IO实现依赖asio库完成,因此transport功能模块应该是7+1个子模块构成,也就是服务层代码实现由8个子模块支持。
2.1 asio网络IO库实现原理
Asio是一个优秀网络库,依赖于boost库的部分实现,支持linux、windos、unix等多平台,MongoDB基于asio库来实现网络IO及定时器处理。asio库由于为了支持多平台,在代码实现中用了很多C++的模板,同时用了很多C++的新语法特性,因此整体代码可读性相比MongoDB服务层代码差很多。
服务端网络IO异步处理流程大体如下:
调用socket()创建一个套接字,获取一个socket描述符。
调用bind()绑定套接字,同时通过listen()来监听客户端链接,注册该socket描述符到epoll事件集列表,等待accept对应的新连接读事件到来。
通过epoll_wait获取到accept对应的读事件信息,然后调用accept()来接受客户的连接,并获取一个新的链接描述符new_fd。
注册新的new_fd到epoll事件集列表,当该new_fd描述符上有读事件到来,于是通过epoll_wait获取该事件,开始该fd上的数据读取。
读取数据完毕后,开始内部处理,处理完后发送对应数据到客户端。如果一次write数据到内核协议栈写太多,造成协议栈写满,则添加写事件到epoll事件列表。
服务端网络IO同步方式处理流程和异步流程大同小异,少了epoll注册和epoll事件通知过程,直接同步调用accept()、recv()、send()进行IO处理。
同步IO处理方式相对比较简单,下面仅分析和MongoDB服务层transport模块结合比较紧密的asio异步IO实现原理。
MongoDB服务层用到的Asio库功能中最重要的几个结构有io_context、scheduler、epoll_reactor。Asio把网络IO处理任务、状态机调度任务做为2种不同操作,分别由两个继承自operation的类结构管理,每种类型的操作也就是一个任务task。io_context、scheduler、epoll_reactor最重要的功能就是管理和调度这些task有序并且高效的运行。
2.1.1 io_context类实现及其作用
io_context 上下文类是MongoDB服务层和asio网络库交互的枢纽,是MongoDB服务层和asio库进行operation任务交互的入口。该类负责MongoDB相关任务的入队、出队,并与scheduler调度处理类配合实现各种任务的高效率运行。MongoDB服务层在实现的时候,accept新连接任务使用_acceptorIOContext这个IO上下文成员实现,数据分发及其相应回调处理由_workerIOContext上下文成员实现。
该类的几个核心接口功能如下表所示:
Io_context类成员/函数名 |
功能 |
备注说明 |
impl_type& impl_; |
MongoDB对应的type类型为scheduler |
通过该成员来调用scheduler调度类的接口 |
io_context::run() |
负责accept对应异步回调处理 |
1.MongoDB中该接口只针对accept对应IO异步处理 2.调用scheduler::run()进行accept异步读操作 |
io_context::stop() |
停止IO调度处理 |
调用scheduler::stop()接口 |
io_context::run_one_until() |
1. 从全局队列上获取一个任务执行 2. 如果全局队列为空,则调用epoll_wait()获取网络IO事件处理 |
调用schedule::wait_one() |
io_context::post() |
任务入队到全局队列 |
调用scheduler::post_immediate_completion() |
io_context::dispatch() |
1.如果调用该接口的线程已经运行过全局队列中的任务,则直接继续由本线程运行该入队的任务 2.如果不满足条件1条件,则直接入队到全局队列,等待调度执行 |
如果条件1满足,则直接由本线程执行 如果条件1不满足,则调用scheduler::do_dispatch () |
总结:
从上表的分析可以看出,和MongoDB直接相关的几个接口最终都是调用schedule类的相关接口,整个实现过程参考下一节scheduler调度实现模块。
上表中的几个接口按照功能不同,可以分为入队型接口(poll、dispatch)和出队型接口(run_for、run、run_one_for)。
按照和io_context的关联性不同,可以分为accept相关io(_acceptorIOContext)处理的接口(run、stop)和新链接fd对应Io(_workerIOContext)数据分发相关处理及回调处理的接口(run_for、run_one_for、poll、dispatch)。
io_context上下文的上述接口,除了dispatch在某些情况下直接运行handler外,其他接口最终都会间接调用scheduler调度类接口。
2.1.2 asio调度模块scheduler实现
上一节的io_context上下文中提到MongoDB操作的io上下文最终都会调用scheduler的几个核心接口,io_context只是起衔接MongoDB和asio库的链接桥梁。scheduler类主要工作在于完成任务调度,该类和MongoDB相关的几个主要成员变量及接口如下表:
scheduler类主要成员/接口 |
功能 |
备注说明 |
mutable mutex mutex_; |
互斥锁,全局队列访问保护 |
多线程从全局队列获取任务的时候加锁保护 |
op_queue<operation> op_queue_; |
全局任务队列,全局任务和网络事件相关任务都添加到该队列 |
3.1.1中的5种类型的任务都入队到了该全局队列 |
bool stopped_; |
线程是否可调度标识 |
为true后,将不再处理epoll相关事件,参考scheduler::do_run_one |
event wakeup_event_; |
唤醒等待锁得线程 |
实际event由信号量封装 |
task_operation task_operation_; |
特殊的operation |
在链表中没进行一次epoll获取到IO任务加入全局队列后,都会紧接着添加一个特殊operation |
reactor* task_; |
也就是epoll_reactor |
借助epoll实现网络事件异步处理 |
atomic_count outstanding_work_; |
套接字描述符个数 |
accept获取到的链接数fd个数+1(定时器fd) |
scheduler::run() |
循环处理epoll获取到的accept事件信息 |
循环调用scheduler::do_run_one()接口 |
scheduler::do_dispatch() |
任务入队 |
任务入队到全局队列op_queue_ |
scheduler::do_wait_one() |
任务出队执行 |
如果队列为空则获取epoll事件集对应的网络IO任务放入全局op_queue_队列 |
scheduler::restart() |
重新启用调度 |
实际上就是修改stopped_标识为false |
scheduler::stop_all_threads() |
停止调度 |
实际上就是修改stopped_标识为true |
2.1.3 operation任务队列
从前面的分析可以看出,一个任务对应一个operation类结构,asio异步实现中schduler调度的任务分为IO处理任务(accept处理、读io处理、写io处理、网络IO处理回调处理)和全局状态机任务,总共2种任务小类。
此外,asio还有一种特殊的operation,该Operastion什么也不做,只是一个特殊标记。网络IO处理任务、状态机处理任务、特殊任务这三类任务分别对应三个类结构,分别是:reactor_op、completion_handler、task_operation_,这三个类都会继承基类operation。
1. operation基类实现
operation基类实际上就是scheduler_operation类,通过typedef scheduler_operation operation指定,是其他三个任务的父类,其主要实现接口如下:
operation类主要成员/接口 |
功能 |
备注说明 |
unsigned int task_result_ |
Epoll_wait获取到的事件位图信息记录到该结构中 |
在descriptor_state::do_complete中取出位图上的事件信息做底层IO读写处理 |
func_type func_; |
需要执行的任务 |
|
scheduler_operation::complete() |
执行func_() |
任务的内容在func()中运行 |
2. completion_handler状态机任务
当MongoDB通过listener线程接受到一个新链接后,会生成一个状态机调度任务,然后入队到全局队列op_queue_,worker线程从全局队列获取到该任务后调度执行,从而进入状态机调度流程,在该流程中会触发epoll相关得网络IO注册及异步IO处理。一个全局状态机任务对应一个completion_handler类,该类主要成员及接口说明如下表所示:
completion_handler类主要成员/接口 |
功能 |
备注说明 |
Handler handler_; |
全局状态机任务函数 |
这个handler就相当于一个任务,实际上是一个函数 |
completion_handler(Handler& h) |
构造初始化 |
启用该任务,等待调度 |
completion_handler::do_complete() |
执行handler_回调 |
任务的内容在handler_()中运行 |
completion_handler状态机任务类实现过程比较简单,就是初始化和运行两个接口。全局任务入队的时候有两种方式,一种是io_context::dispatch方式,另一种是io_context::post。从前面章节对这两个接口的代码分析可以看出,任务直接入队到全局队列op_queue_中,然后工作线程通过scheduler::do_wait_one从队列获取该任务执行。
注意:状态机任务入队由Listener线程(新链接到来的初始状态机任务)和工作线程(状态转换任务)共同完成,任务出队调度执行由MongoDB工作线程执行,状态机具体任务内容在后面《状态机实现》章节实现。
3. 网络IO事件处理任务
网络IO事件对应的Opration任务最终由reactor_op类实现,该类主要成员及接口如下:
reactor_op类主要成员/接口 |
功能 |
备注说明 |
asio::error_code ec_; |
全局状态机任务函数 |
这个handler就相当于一个任务,实际上是一个函数 |
std::size_t bytes_transferred_; |
读取或者发送的数据字节数 |
Epoll_wait返回后获取到对应的读写事件,然后进行数据分发操作 |
enum status; |
底层数据读写状态 |
标识读写数据的状态 |
perform_func_type perform_func_; |
底层IO操作的函数指针 |
perform()中运行 |
status perform(); |
运行perform_func_函数 |
perform实际上就是数据读写的底层实现 |
reactor_op(perform_func_type perform_func, func_type complete_func) |
类初始化 |
这里有两个func: 1. 底层数据读写实现的接口,也就是perform_func 2. 读取或者发送一个完整MongoDB报文的回调接口,也就是complete_func |
从reactor_op类可以看出,该类的主要两个函数成员:perform_func_和complete_func。其中perform_func_函数主要负责异步网络IO底层处理,complete_func用于获取到一个新链接、接收或者发送一个完整MongoDB报文后的后续回调处理逻辑。
perform_func_具体功能包含如下三种如下:
通过epoll事件集处理底层accept获取新连接fd。
fd上的数据异步接收
fd上的数据异步发送
针对上面的三个网络IO处理功能,ASIO在实现的时候,分别通过三个不同的类(reactive_socket_accept_op_base、reactive_socket_recv_op_base、
reactive_socket_send_op_base)实现,这三个类都继承父类reactor_op。这三个类的功能总结如下表所示:
类名 |
功能 |
说明 |
reactive_socket_accept_op_base |
1. Accept()系统调用获取新fd 2. 获取到一个新fd后的MongoDB层逻辑回调处理 |
Accept()系统调用由perform_func()函数处理 获取到新链接后的逻辑回调由complete_func执行 |
reactive_socket_recv_op_base |
1. 读取一个完整MongoDB报文读取 2. 读取完整报文后的MongoDB服务层逻辑回调处理 |
从一个链接上读取一个完整MongoDB报文读取由perform_func()函数处理 读取完整报文后的MongoDB服务层逻辑回调处理由complete_func执行 |
reactive_socket_send_op_base |
1. 发送一个完整的MongoDB报文 2. 发送完一个完整MongoDB报文后的MongoDB服务层逻辑回调处理 |
Accept()系统调用由perform_func()函数处理 获取到新链接后的逻辑回调由complete_func执行 |
总结:asio在实现的时候,把accept处理、数据读、数据写分开处理,都继承自公共基类reactor_op,该类由两个操作组成:底层IO操作和回调处理。其中,asio的底层IO操作最终由epoll_reactor类实现,回调操作最终由MongoDB服务层指定,底层IO操作的回调映射表如下:
底层IO操作类型 |
MongoDB服务层回调 |
说明 |
Accept(reactive_socket_accept_op_base) |
ServiceEntryPointImpl::startSession,回调中进入状态机任务流程 |
Listener线程获取到一个新链接后MongoDB的回调处理 |
Recv(reactive_socket_recv_op_base) |
ServiceStateMachine::_sourceCallback,回调中进入状态机任务流程 |
接收一个完整MongoDB报文的回调处理 |
Send(reactive_socket_send_op_base) |
ServiceStateMachine::_sinkCallback,回调中进入状态机任务流程 |
发送一个完整MongoDB报文的回调处理 |
说明:网络IO事件处理任务实际上在状态机任务内运行,也就是状态机任务中调用asio库进行底层IO事件运行处理。
4. 特殊任务task_operation
前面提到,ASIO库中还包含一种特殊的task_operation任务,asio通过epoll_wait获取到一批IO事件后,会添加到op_queue_全局队列,工作线程从队列取出任务有序执行。每次通过epoll_wait获取到IO事件信息后,除了添加这些读写事件对应的底层IO处理任务到全局队列外,每次还会额外生成一个特殊task_operation任务添加到队列中。
为何引入一个特殊任务的Opration?
工作线程变量全局op_queue_队列取出任务执行,如果从队列头部取出的是特殊Op操作,就会立马触发获取epoll网络事件信息,避免底层网络IO任务长时间不被处理引起的"饥饿"状态,保证状态机任务和底层IO任务都能”平衡”运行。
asio库底层处理实际上由epoll_reactor类实现,该类主要负责epoll相关异步IO实现处理,鉴于篇幅epoll reactor相关实现将在后续《MongoDB内核源码实现及调优系列》相关章节详细分析。
2.2 message_compressor网络传输数据压缩子模块
网络传输数据压缩子模块主要用于减少网络带宽占用,通过CPU来换取IO消耗,也就是以更多CPU消耗来减少网络IO压力。
鉴于篇幅,该模块的详细源码实现过程将在《MongoDB内核源码实现及调优系列》相关章节分享。
2.3 transport_layer套接字处理及传输层管理子模块
transport_layer套接字处理及传输层管理子模块功能主要如下:
套接字相关初始化处理
结合asio库实现异步accept处理
不同线程模型管理及初始化
鉴于篇幅,该模块的详细源码实现过程将在《MongoDB内核源码实现及调优系列》相关章节详细分析。
2.4 session会话子模块
Session会话模块功能主要如下:
负责记录HostAndPort、新连接fd信息
通过和底层asio库的直接互动,实现数据的同步或者异步收发
鉴于篇幅,该模块的详细源码实现过程将在《MongoDB内核源码实现及调优系列》相关章节详细分析。
2.5 Ticket数据分发子模块
Ticket数据分发子模块主要功能如下:
调用session子模块进行底层asio库处理
拆分数据接收和数据发送到两个类,分别实现
完整MongoDB报文读取
接收或者发送MongoDB报文后的回调处理
鉴于篇幅,该模块的详细源码实现过程将在《MongoDB内核源码实现及调优系列》相关章节详细分析。
2.6 service_state_machine状态机调度子模块
service_state_machine状态机处理模块主要功能如下:
MongoDB网络数据处理状态转换
配合状态转换逻辑把一次MongoDB请求拆分为二个大的状态任务: 接收一个完整长度MongoDB报文、接收到一个完整报文后的后续所有处理(含报文解析、认证、引擎层处理、应答客户端等)
配合工作线程模型子模块,把步骤2的两个任务按照指定的状态转换关系进行调度运行
鉴于篇幅,该模块的详细源码实现过程将在《MongoDB内核源码实现及调优系列》相关章节详细分析。
2.7 service_entry_point服务入口点子模块
service_entry_point服务入口点子模块主要负责如下功能:
连接数控制
Session会话管理
接收到一个完整报文后的回调处理(含报文解析、认证、引擎层处理等)
鉴于篇幅,该模块的详细源码实现过程将在《MongoDB内核源码实现及调优系列》相关章节详细分析。
2.8 service_executor服务运行子模块,即线程模型子模块
线程模型设计在数据库性能指标中起着非常重要的作用,因此本文将重点分析MongoDB服务层线程模型设计,体验MongoDB如何通过优秀的工作线程模型来达到多种业务场景下的性能极致表现。
service_executor线程子模块,在代码实现中,把线程模型分为两种:synchronous线程模式和adaptive线程模型。MongoDB启动的时候通过配置参数net.serviceExecutor来确定采用那种线程模式运行mongo实例,配置方式如下:
net: //同步线程模式配置
serviceExecutor: synchronous
或者 //动态线程池模式配置
net:
serviceExecutor: synchronous
2.8.1 synchronous同步线程模型(一个链接一个线程)实现原理
synchronous同步线程模型,listener线程每接收到一个链接就会创建一个线程,该链接上的所有数据读写及内部请求处理流程将一直由本线程负责,整个线程的生命周期就是这个链接的生命周期。
1. 网络IO操作方式
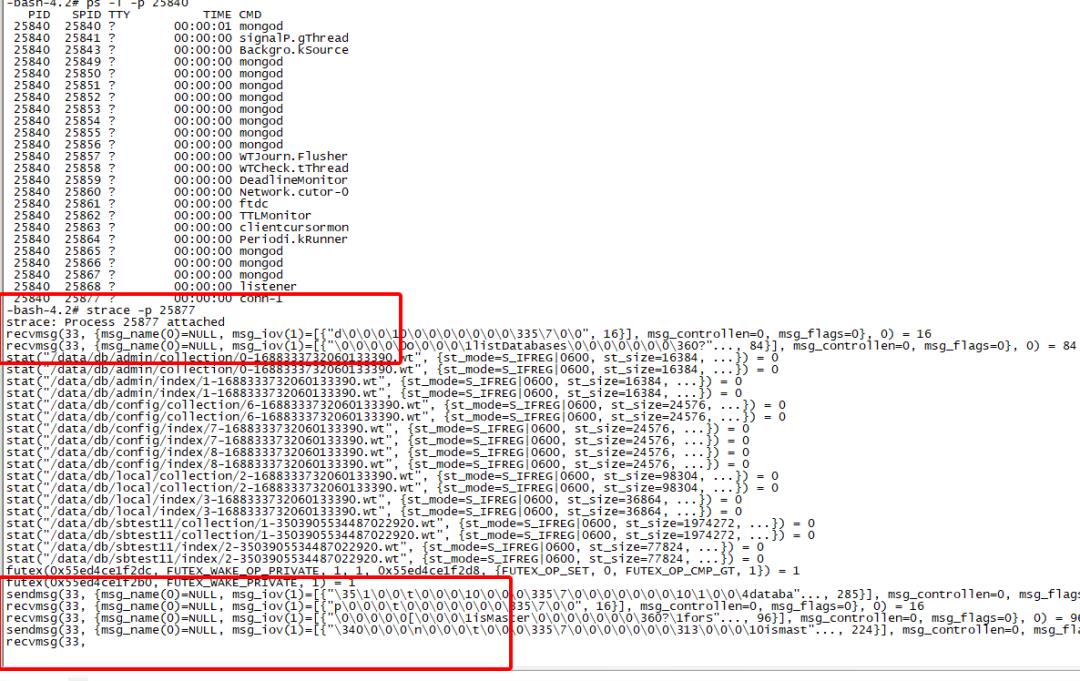
synchronous同步线程模型实现过程比较简单,线程循循环以同步IO操作方式从fd读取数据,然后处理数据,最后返回客户端对应得数据。同步线程模型方式针对某个链接的系统调用如下图所示(mongo shell建立链接后show dbs):
2. 性能极致提升小细节
虽然synchronous线程模型比较简单,但是MongoDB服务层再实现的时候针对细节做了极致的优化,主要体现在如下代码实现细节上面:

具体实现中,MongoDB线程每处理16次用户请求,就让线程空闲一会儿。同时,当总的工作线程数大于cpu核数后,每次都做让出一次CPU调度。通过这两种方式,在性能测试中可以提升5%的性能,虽然提升性能不多,但是充分体现了MongoDB在性能优化提升方面所做的努力。
3. 同步线程模型监控统计
可以通过如下命令获取同步线程模型方式获取当前MongoDB中的链接数信息:
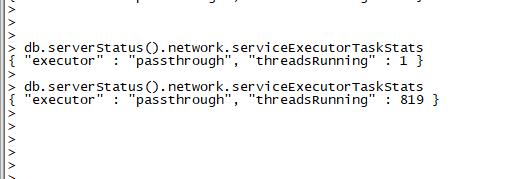
该监控中主要由两个字段组成:passthrough代表同步线程模式,threadsRunning表示当前进程的工作线程数。
2.8.2 adaptive异步线程模型(动态线程池)实现原理
adaptive动态线程池模型,内核实现的时候会根据当前系统的访问负载动态的调整线程数。当线程CPU工作比较频繁的时候,控制线程增加工作线程数;当线程CPU比较空闲后,本线程就会自动消耗退出。下面一起体验adaptive线程模式下,MongoDB是如何做到性能极致设计的。
1. 线程池初始化
MongoDB默认初始化后,线程池线程数默认等于CPU核心数/2,主要实现如下:

从代码实现可以看出,线程池中最低线程数可以通过adaptiveServiceExecutorReservedThreads配置,如果没有配置则默认设置为CPU/2。
2. 工作线程运行时间相关的几个统计
3.6状态机调度模块中提到,一个完整的客户端请求处理可以转换为2个任务:通过asio库接收一个完整MongoDB报文、接收到报文后的后续所有处理(含报文解析、认证、引擎层处理、发送数据给客户端等)。假设这两个任务对应的任务名、运行时间分别如下表所示:
任务名 |
功能 |
运行时间 |
Task1 |
调用底层asio库接收一个完整MongoDB报文 |
T1 |
Task2 |
接收到报文后的后续所有处理(含报文解析、认证、引擎层处理、发送数据给客户端等) |
T2 |
客户端一次完整请求过程中,MongoDB内部处理过程=task1 + task2,整个请求过程中MongoDB内部消耗的时间T1+T2。
实际上如果fd上没有数据请求,则工作线程就会等待数据,等待数据的过程就相当于空闲时间,我们把这个时间定义为T3。于是一个工作线程总运行时间=内部任务处理时间+空闲等待时间,也就是线程总时间=T1+T2+T3,只是T3是无用等待时间。
3. 单个工作线程如何判断自己处于”空闲”状态
步骤2中提到,线程运行总时间=T1 + T2 +T3,其中T3是无用等待时间。如果T3的无用等待时间占比很大,则说明线程比较空闲。
MongoDB工作线程每次运行完一次task任务后,都会判断本线程的有效运行时间占比,有效运行时间占比=(T1+T2)/(T1+T2+T3),如果有效运行时间占比小于某个阀值,则该线程自动退出销毁,该阀值由adaptiveServiceExecutorIdlePctThreshold参数指定。该参数在线调整方式。
db.adminCommand({ setParameter: 1, adaptiveServiceExecutorIdlePctThreshold: 50} )
4. 如何判断线程池中工作线程“太忙”
MongoDB服务层有个专门的控制线程用于判断线程池中工作线程的压力情况,以此来决定是否在线程池中创建新的工作线程来提升性能。
控制线程每过一定时间循环检查线程池中的线程压力状态,实现原理就是简单的实时记录线程池中的线程当前运行情况,为以下两类计数:总线程数_threadsRunning、
当前正在运行task任务的线程数_threadsInUse。
如果_threadsRunning=_threadsRunning,说明所有工作线程当前都在处理task任务,这时候已经没有多余线程去asio库中的全局任务队列op_queue_中取任务执行了,这时候队列中的任务就不会得到及时的执行,就会成为响应客户端请求的瓶颈点。
5. 如何判断线程池中所有线程比较“空闲”
control控制线程会在收集线程池中所有工作线程的有效运行时间占比,如果占比小于指定配置的阀值,则代表整个线程池空闲。
前面已经说明一个线程的有效时间占比为:(T1+T2)/(T1+T2+T3),那么所有线程池中的线程总的有效时间占比计算方式如下:
所有线程的总有效时间TT1 = (线程池中工作线程1的有效时间T1+T2) + (线程池中工作线程2的有效时间T1+T2) + ..... + (线程池中工作线程n的有效时间T1+T2)
所有线程总运行时间TT2 = (线程池中工作线程1的有效时间T1+T2+T3) + (线程池中工作线程2的有效时间T1+T2+T3) + ..... + (线程池中工作线程n的有效时间T1+T2+T3)
线程池中所有线程的总有效工作时间占比 = TT1/TT2
6. control控制线程如何动态增加线程池中线程数
MongoDB在启动初始化的时候,会创建一个线程名为”worker-controller”的控制线程,该线程主要工作就是判断线程池中是否有充足的工作线程来处理asio库中全局队列op_queue_中的task任务,如果发现线程池比较忙,没有足够的线程来处理队列中的任务,则在线程池中动态增加线程来避免task任务在队列上排队等待。
control控制线程循环主体主要压力判断控制流程如下:
while {
#等待工作线程唤醒条件变量,最长等待stuckThreadTimeout
_scheduleCondition.wait_for(stuckThreadTimeout)
#获取线程池中所有线程最近一次运行任务的总有效时间TT1
Executing =_getThreadTimerTotal(ThreadTimer::Executing);
#获取线程池中所有线程最近一次运行任务的总运行时间TT2
Running =_getThreadTimerTotal(ThreadTimer::Running);
#线程池中所有线程的总有效工作时间占比 = TT1/TT2
utilizationPct = Executing / Running;
#代表control线程太久没有进行线程池压力检查了
if(本次循环到该行代码的时间 > stuckThreadTimeout阀值) {
#说明太久没做压力检查,造成工作线程不够用了
if(_threadsInUse == _threadsRunning) {
#批量创建一批工作线程
for(; i <reservedThreads; i++)
#创建工作线程
_startWorkerThread();
}
#control线程继续下一次循环压力检查
continue;
}
#如果当前线程池中总线程数小于最小线程数配置
#则创建一批线程,保证最少工作线程数达到要求
if (threadsRunning <reservedThreads) {
while (_threadsRunning <reservedThreads) {
_startWorkerThread();
}
}
#检查上一次循环到本次循环这段时间范围内线程池中线程的工作压力
#如果压力不大,则说明无需增加工作线程数,则继续下一次循环
if (utilizationPct <idlePctThreshold) {
continue;
}
#如果发现已经有线程创建起来了,但是这些线程还没有运行任务
#这说明当前可用线程数可能足够了,我们休息sleep_for会儿在判断一下
#该循环最多持续stuckThreadTimeout时间
do {
stdx::this_thread::sleep_for();
} while ((_threadsPending.load() >0) &&
(sinceLastControlRound.sinceStart()< stuckThreadTimeout)
#如果tasksQueued队列中的任务数大于工作线程数,说明任务在排队了
#该扩容线程池中线程了
if (_isStarved()) {
_startWorkerThread();
}
}
7. 实时serviceExecutorTaskStats线程模型统计信息
本文分析的MongoDB版本为3.6.1,其network.serviceExecutorTaskStats网络线程模型相关统计通过db.serverStatus().network.serviceExecutorTaskStats可以查看,如下图所示:
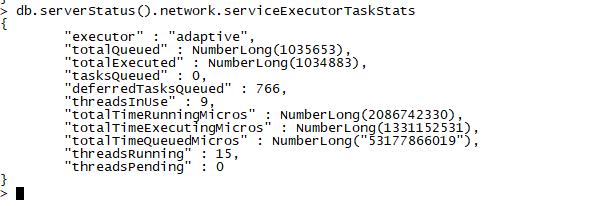
上图的几个信息功能可以分类为三大类,说明如下:
大类类名 |
字段名 |
功能 |
无 |
executor |
Adaptive,说明是动态线程池模式 |
线程统计 |
threadsInUse |
当前正在运行task任务的线程数 |
threadsRunning |
当前运行的线程数 |
|
threadsPending |
当前创建起来,但是还没有执行过task任务的线程数 |
|
队列统计 |
totalExecuted |
线程池运行成功的任务总数 |
tasksQueued |
入队到全局队列的任务数 |
|
deferredTasksQueued |
等待接收网络IO数据来读取一个完整MongoDB报文的任务数 |
|
时间统计 |
totalTimeRunningMicros |
所有工作线程运行总时间(含等待网络IO的时间T1 + 读一个MongoDB报文任务的时间T2 + 一个请求后续处理的时间T3) |
totalTimeExecutingMicros |
也就是T2+T3,MongoDB内部响应一个完整MongoDB耗费的时间 |
|
totalTimeQueuedMicros |
线程池中所有线程从创建到被用来执行第一个任务的等待时间 |
上表中各个字段的都有各自的意义,我们需要注意这些参数的以下情况:
threadsRunning- threadsInUse的差值越大说明线程池中线程比较空闲,差值越小说明压力越大
threadsPending越大,表示线程池越空闲
tasksQueued- totalExecuted的差值越大说明任务队列上等待执行的任务越多,说明任务积压现象越明显
deferredTasksQueued越大说明工作线程比较空闲,在等待客户端数据到来
totalTimeRunningMicros- totalTimeExecutingMicros差值越大说明越空闲
上面三个大类中的总体反映趋势都是一样的,任何一个差值越大就说明越空闲。
在后续MongoDB最新版本中,去掉了部分重复统计的字段,同时也增加了以下字段,如下图所示:

新版本增加的几个统计项实际上和3.6.1大同小异,只是把状态机任务按照不通类型进行了更加详细的统计。新版本中,更重要的一个功能就是control线程在发现线程池压力过大的时候创建新线程的触发情况也进行了统计,这样我们就可以更加直观的查看动态创建的线程是因为什么原因创建的。
8. MongoDB-3.6早期版本control线程动态调整动态增加线程缺陷1例
从步骤6中可以看出,control控制线程创建工作线程的第一个条件为:如果该线程超过stuckThreadTimeout阀值都没有做线程压力控制检查,并且线程池中线程数全部在处理任务队列中的任务,这种情况control线程一次性会创建reservedThreads个线程。reservedThreads由adaptiveServiceExecutorReservedThreads配置,如果没有配置,则采用初始值CPU/2。
那么问题来了,如果我提前通过命令行配置了这个值,并且这个值配置的非常大,例如一百万,这里岂不是要创建一百万个线程,这样会造成操作系统负载升高,更容易引起耗尽系统pid信息,这会引起严重的系统级问题。
不过,不用担心,最新版本的MongoDB代码,内核代码已经做了限制,这种情况下创建的线程数变为了1,也就是这种情况只创建一个线程。
9. adaptive线程模型实时参数
动态线程模设计的时候,MongoDB设计者考虑到了不通应用场景的情况,因此在核心关键点增加了实时在线参数调整设置,主要包含如下7种参数,如下表所示:
参数名 |
作用 |
adaptiveServiceExecutorReservedThreads |
默认线程池最少线程数 |
adaptiveServiceExecutorRunTimeMillis |
工作线程从全局队列中获取任务执行,如果队列中没有任务则需要等待,该配置就是限制等待时间的最大值 |
adaptiveServiceExecutorRunTimeJitterMillis |
如果配置为0,则任务入队从队列获取任务等待时间则不需要添加一个随机数 |
adaptiveServiceExecutorStuckThreadTimeoutMillis |
保证control线程一次while循环操作(循环体里面判断是否需要增加线程池中线程,如果发现线程池压力大,则增加线程)的时间为该配置的值 |
adaptiveServiceExecutorMaxQueueLatencyMicros |
如果control线程一次循环的时间不到adaptiveServiceExecutorStuckThreadTimeoutMillis,则do {} while(),直到保证本次while循环达到需要的时间值。 {}中就是简单的sleep,sleep的值就是本配置项的值。 |
adaptiveServiceExecutorIdlePctThreshold |
单个线程循环从全局队列获取task任务执行,同时在每次循环中会判断该本工作线程的有效运行时间占比,如果占比小于该配置值,则本线程自动退出销毁。 |
adaptiveServiceExecutorRecursionLimit |
由于adaptive采用异步IO操作,因此可能存在线程同时处理多个请求的情况,这时候我们就需要限制这个递归深度,如果深度过大,容易引起部分请求慢的情况。 |
命令行实时参数调整方法如下,以adaptiveServiceExecutorReservedThreads为例,其他参数调整方法类似:
db.adminCommand( { setParameter: 1,adaptiveServiceExecutorReservedThreads: xx} )
MongoDB服务层的adaptive动态线程模型设计代码实现非常优秀,有很多实现细节针对不同应用场景做了极致优化,鉴于篇幅,该模块的详细源码实现过程将在《MongoDB内核源码实现及调优系列》相关章节详细分析。
3. 不同线程模型性能多场景PK
前面对线程模型进行了分析,下面针对Synchronous和adaptive两种模型设计进行不同场景和不同纬度的测试,总结两种模型各种的使用场景,并根据测试结果结合前面的理论分析得出不同场景下那种线程模型更合适。
测试纬度主要包括:并发数、请求快慢。本文的压力测试工具采用sysbench实现,以下是这几种纬度的名称定义:
并发数:也就是sysbench启动的线程数,默认一个线程对应一个链接
请求快慢:快请求就是请求返回比较快,sysbench的lua测试脚本通过read同一条数据模拟快请求(走存储引擎缓存),内部处理时延小于1ms。 慢请求也通过sysbench测试,测试脚本做range操作,单次操作时延几十ms。
sysbench慢操作测试原理: 首先写20000万数据到库中,然后通过range操作测试,range操作比较慢,慢操作启动方式:
测试硬件资源,容器一台,配置如下:
1. CPU=32
2. 内存=64G
3.1 场景一、低并发场景+快请求测试
Sysbench并发线程数70测试结果如下图所示(上图为adaptive模式,下图为Synchronousm线程模式):
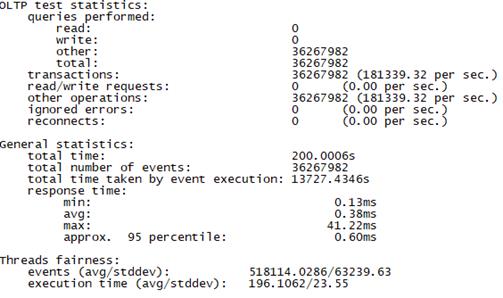
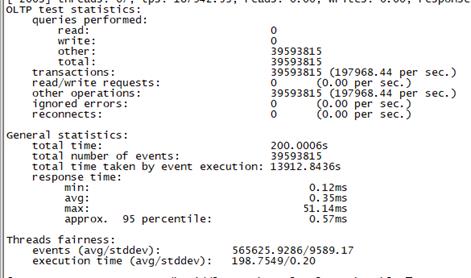
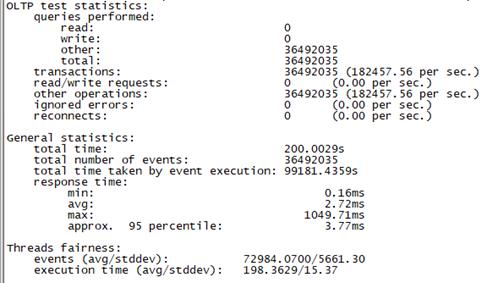
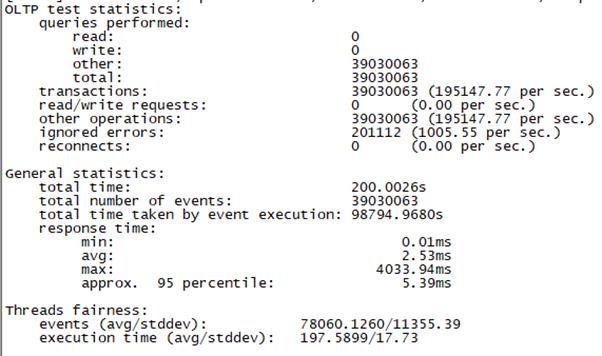
Sysbench并发线程数500测试结果如下图所示(上图为adaptive模式,下图为Synchronousm线程模式):
Sysbench并发线程数1000测试结果如下图所示(上图为adaptive模式,下图为Synchronousm线程模式):
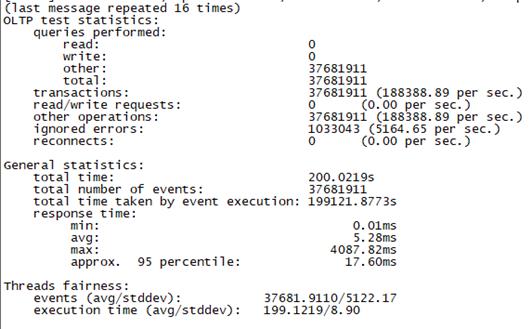
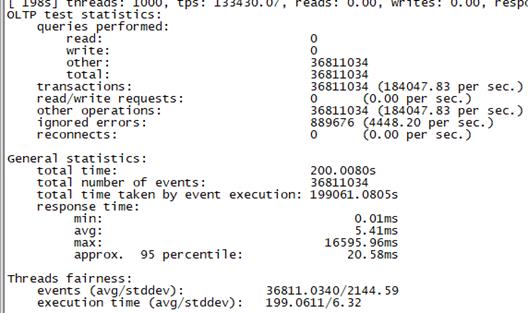
3.2 场景二、低并发场景+慢请求测试
Sysbench并发线程数30测试结果如下图所示(上图为adaptive模式,下图为Synchronousm线程模式):
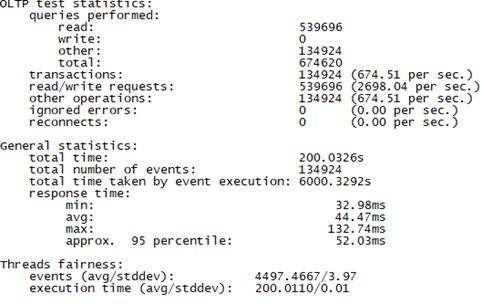
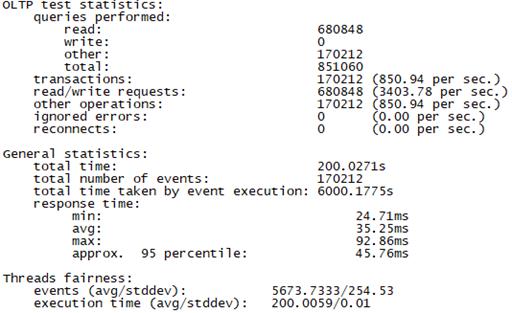
Sysbench并发线程数500测试结果如下图所示(上图为adaptive模式,下图为Synchronousm线程模式):
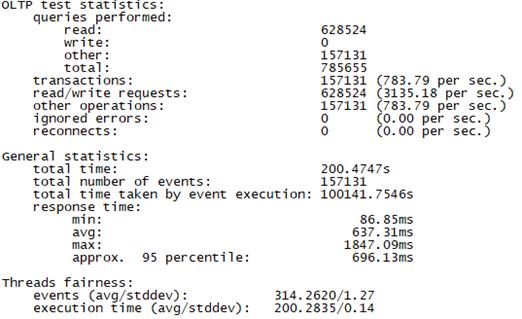
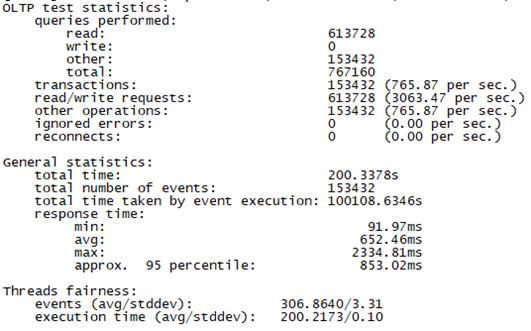
Sysbench并发线程数1000测试结果如下图所示(上图为adaptive模式,下图为Synchronousm线程模式):
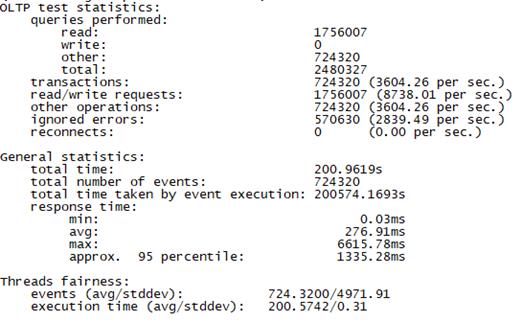
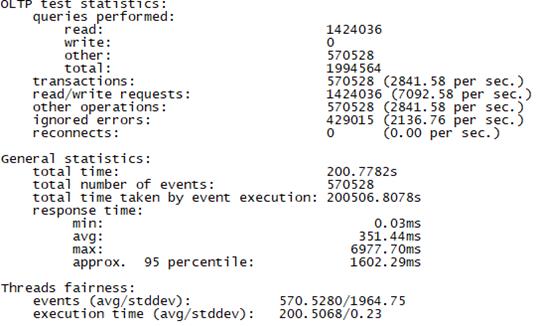
3.3 场景三、高并发场景+快请求测试
Sysbench并发线程数5000测试结果如下图所示(上图为adaptive模式,下图为Synchronousm线程模式):
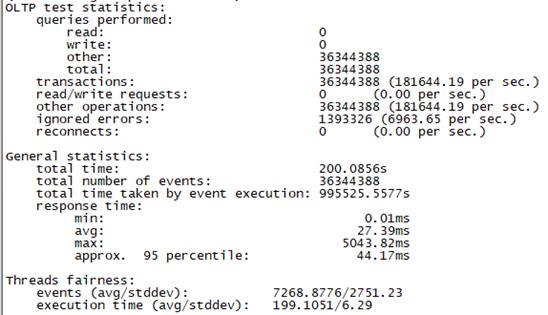
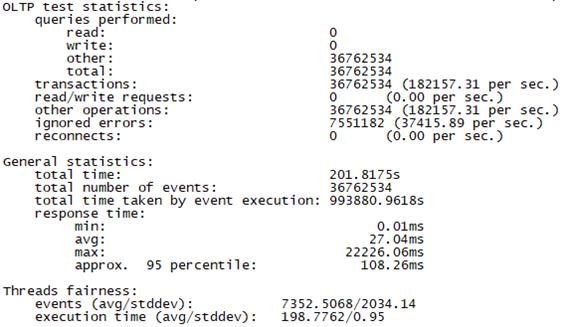
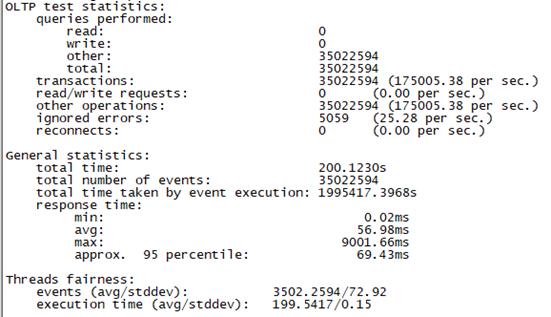
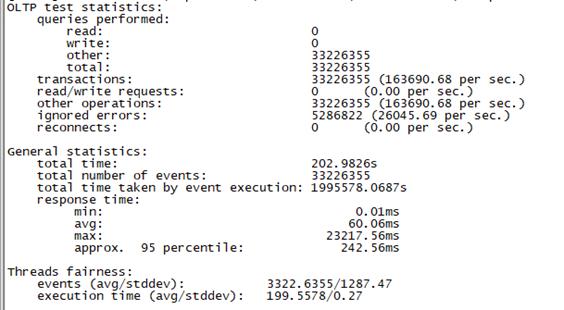
Sysbench并发线程数10000测试结果如下图所示(上图为adaptive模式,下图为Synchronousm线程模式):
测试中发现30000并发的时候synchronousm模式实际成功的连接数为24000,如下图所示:

为了测试相同并发数的真实数据对比,因此把adaptive模式的测试并发线程数调整为24000测试,同时提前把adaptive做如下最低线程数调整:
db.adminCommand( { setParameter: 1,adaptiveServiceExecutorReservedThreads: 120} )
两种测试数据结果如下(上图为adaptive模式,下图为Synchronousm线程模式):
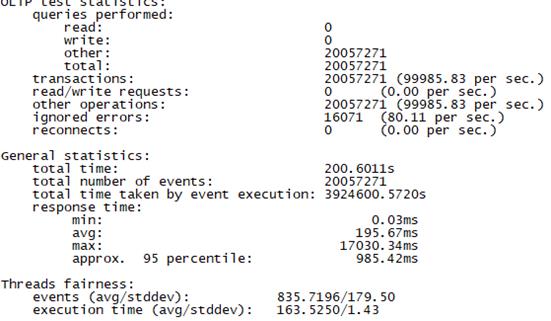
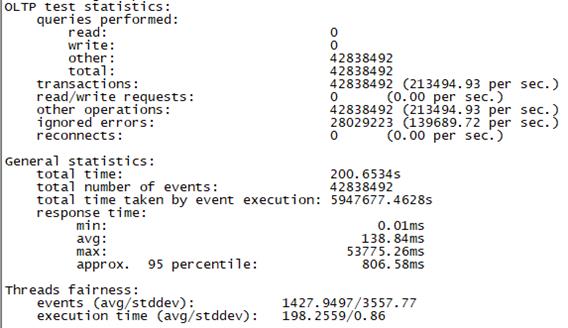
3.4 场景四、高并发场景+慢请求测试
Sysbench并发线程数5000测试结果如下图所示(上图为adaptive模式,下图为Synchronousm线程模式):
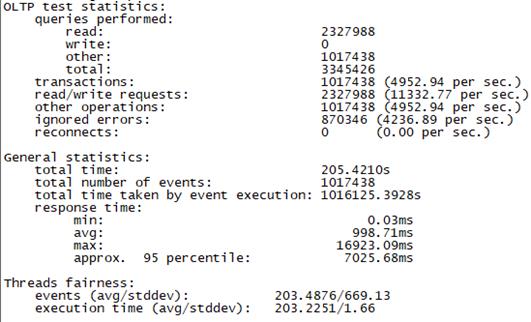
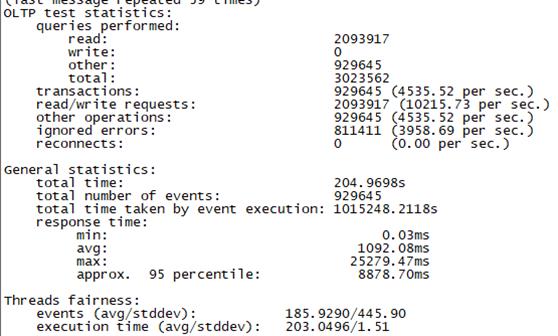
Sysbench并发线程数10000测试结果如下图所示(上图为adaptive模式,下图为Synchronousm线程模式):
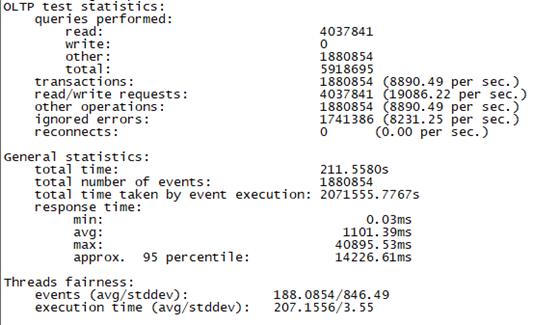
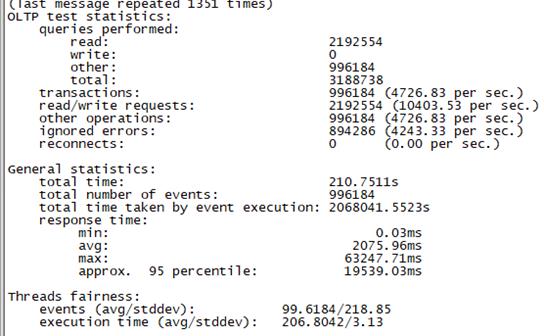
Sysbench并发线程数20000测试结果如下图所示(上图为adaptive模式,下图为Synchronousm线程模式):
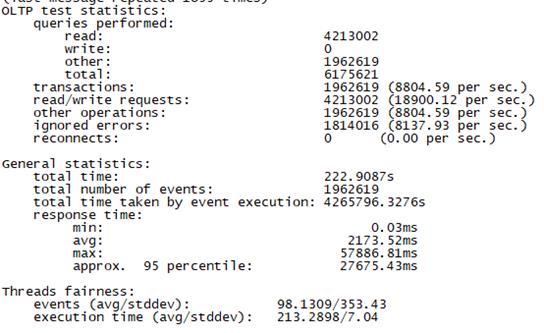
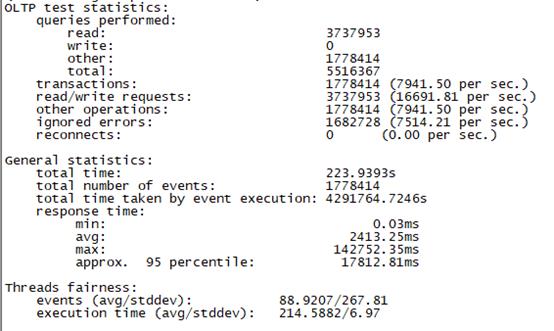
3.5 测试总结
上面的测试数据,汇总如下表:
测试场景 |
线程模式 |
测试结果 |
70线程+快请求 |
Synchronous |
总tps(包含异常请求):19.8W/s,错误请求总数:0,平均时延:0.35ms 95百分位时延:0.57ms,最大时延:51ms |
Adaptive |
总tps(包含异常请求):18.1W/s,错误请求总数:0,平均时延:0.38ms 95百分位时延:0.6ms,最大时延:41ms |
|
500线程+快请求 |
Synchronous |
总tps(包含异常请求):19.5W/s,错误请求总数:0,平均时延:2.53ms 95百分位时延:5.39ms,最大时延:4033ms |
Adaptive |
总tps(包含异常请求):18.2W/s,错误请求总数:0,平均时延:2.7ms 95百分位时延:3.77ms,最大时延:1049ms |
|
1000线程+快请求 |
Synchronous |
总tps(包含异常请求):18.4W/s,错误请求总数:4448/s,有效请求tps:17.9W/s,平均时延:5.41ms , 95百分位时延:20.58ms,最大时延:16595ms |
Adaptive |
总tps(包含异常请求):18.8W/s,错误请求总数:5000/s,有效请求tps:18.3W/s, 平均时延:5.28ms , 95百分位时延:17.6ms,最大时延:4087ms |
|
5000线程+快请求 |
Synchronous |
总tps(包含异常请求):18.2W/s,错误请求总数:7000/s,有效请求tps:17.5W/s,平均时延:27.3ms , 95百分位时延:44.1ms,最大时延:5043ms |
Adaptive |
总tps(包含异常请求):18.2W/s,错误请求总数:37000/s,有效请求tps:14.5W/s,平均时延:27.4ms , 95百分位时延:108ms,最大时延:22226ms |
|
30000线程+快请求 |
Synchronous |
总tps(包含异常请求):21W/s,错误请求总数:140000/s,有效请求tps:6W/s,平均时延:139ms ,95百分位时延:805ms,最大时延:53775ms |
Adaptive |
总tps(包含异常请求):10W/s,错误请求总数:80/s,有效请求tps:10W/s,平均时延:195ms, 95百分位时延:985ms,最大时延:17030ms |
|
30线程+慢请求 |
Synchronous |
总tps(包含异常请求):850/s,错误请求总数:0,平均时延:35ms 95百分位时延:45ms,最大时延:92ms |
Adaptive |
总tps(包含异常请求):674/s,错误请求总数:0,平均时延:44ms 95百分位时延:52ms,最大时延:132ms |
|
500线程+慢请求
|
Synchronous |
总tps(包含异常请求):765/s,错误请求总数:0,平均时延:652ms 95百分位时延:853ms,最大时延:2334ms |
Adaptive |
总tps(包含异常请求):783/s,错误请求总数:0,平均时延:637ms 95百分位时延:696ms,最大时延:1847ms |
|
1000线程+慢请求 |
Synchronous |
总tps(包含异常请求):2840/s,错误请求总数:2140/s,有效请求tps:700/s,平均时延:351ms 95百分位时延:1602ms,最大时延:6977ms |
Adaptive |
总tps(包含异常请求):3604/s,错误请求总数:2839/s,有效请求tps:800/s, 平均时延:277ms 95百分位时延:1335ms,最大时延:6615ms |
|
5000线程+慢请求 |
Synchronous |
总tps(包含异常请求):4535/s,错误请求总数:4000/s,有效请求tps:500/s,平均时延:1092ms 95百分位时延:8878ms,最大时延:25279ms |
Adaptive |
总tps(包含异常请求):4952/s,错误请求总数:4236/s,有效请求tps:700/s,平均时延:998ms 95百分位时延:7025ms,最大时延:16923ms |
|
10000线程+慢请求 |
Synchronous |
总tps(包含异常请求):4720/s,错误请求总数:4240/s,有效请求tps:500/s,平均时延:2075ms 95百分位时延:19539ms,最大时延:63247ms |
Adaptive |
总tps(包含异常请求):8890/s,错误请求总数:8230/s,有效请求tps:650/s,平均时延:1101ms 95百分位时延:14226ms,最大时延:40895ms |
|
20000线程+慢请求 |
Synchronous |
总tps(包含异常请求):7950/s,错误请求总数:7500/s,有效请求tps:450/s,平均时延:2413ms 95百分位时延:17812ms,最大时延:142752ms |
Adaptive |
总tps(包含异常请求):8800/s,错误请求总数:8130/s,有效请求tps:700/s,平均时延:2173ms 95百分位时延:27675ms,最大时延:57886ms |
3.6 不同线程模型总结
根据测试数据及其前面理论章节的分析,可以得出不同业务场景结论:
低并发场景(并发数小于1000),Synchronous线程模型性能更好。
高并发场景(并发数大于5000),adaptive动态线程模型性能更优。
adaptive动态线程模型,95分位时延和最大时延整体比Synchronous线程模型更优。
并发越高,adaptive相比Synchronous性能更好。
并发越高,Synchronous线程模型错误率相对更高。
空闲链接越多,Synchronous线程模型性能越差。(由于时间问题,该场景未来得及测试,这是官方的数据总结)
此外,短链接场景(例如php相关业务),adaptive模型性能会更优,因为该模型不会有链接关闭引起的线程销毁的开销。
为什么并发越高,adaptive动态线程模型性能比Synchronous会更好,而并发低的时候反而更差,原因如下:
Synchronous模型,一个链接一个线程,并发越高,链接数就会越多,系统负载、内存消耗等就会更高。
低并发场景下,链接数不多,Synchronous模式线程数也不多,系统CPU调度几乎不会受到影响,负载也影响不大。而在adaptive场景下,由于asio库在设计的时候,任务放入全局队列op_queue_中,工作线程每次获取任务运行,都会有锁竞争,因此在低并发场景下性能不及adaptive模式。
3.7 adaptive动态线程模式在线调优实践总结
前面3.6.2章节讲了adaptive线程模型的工作原理,其中有8个参数供我们对线程池运行状态进行调优。大体总结如下:
参数名 |
作用 |
adaptiveServiceExecutorReservedThreads |
如果业务场景是针对类似整点推送、电商定期抢购等超大流量冲击的场景,可以适当的调高该值,避免冲击瞬间线程池不够用引起的任务排队、瞬间创建大量线程、时延过大的情况 |
adaptiveServiceExecutorRunTimeMillis |
不建议调整 |
adaptiveServiceExecutorRunTimeJitterMillis |
不建议调整 |
adaptiveServiceExecutorStuckThreadTimeoutMillis |
可以适当调小该值,减少control控制线程休眠时间,从而可以更快的检测到线程池中工作线程数是否够用 |
adaptiveServiceExecutorMaxQueueLatencyMicros |
不建议调整 |
adaptiveServiceExecutorIdlePctThreshold |
如果流量是波浪形形式,例如上一秒tps=10万/S,下一秒降为几十,甚至跌0的情况,可以考虑调小该值,避免流量瞬间下降引起的线程瞬间批量消耗及流量上升后的大量线程创建 |
adaptiveServiceExecutorRecursionLimit |
不建议调整 |
4. Asio网络库全局队列锁优化,性能进一步提升
前面的分析可以看出adaptive动态线程模型,为了获取全局任务队列op_queue_上的任务,需要进行全局锁竞争,这实际上是整个线程池从队列获取任务运行最大的一个瓶颈。
优化思路:我们可以通过优化队列和锁来提升整体性能,当前的队列只有一个,我们可以把单个队列调整为多个队列,每个队列一把锁,任务入队的时候散列到多个队列,通过该优化,锁竞争及排队将会得到极大的改善。
优化前队列架构:
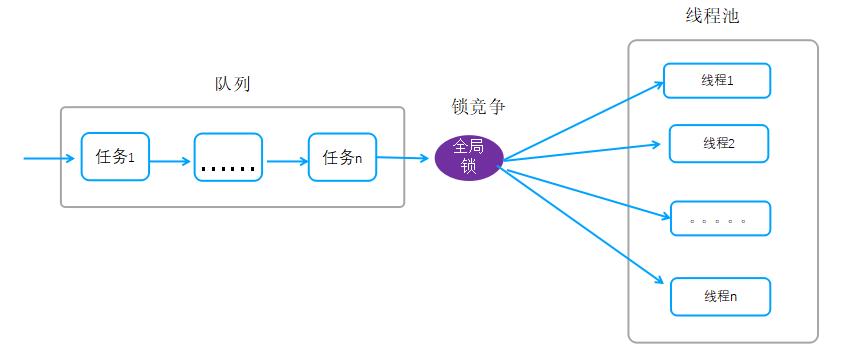
优化后队列架构:
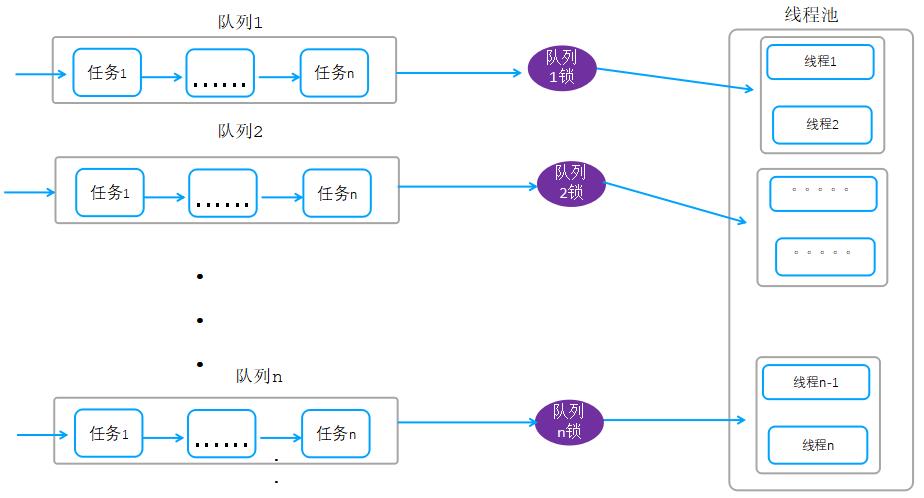
如上图,把一个全局队列拆分为多个队列,任务入队的时候按照hash散列到各自的队列,工作线程获取获取任务的时候,同理通过hash的方式去对应的队列获取任务,通过这种方式减少锁竞争,同时提升整体性能。
5. 网络传输模块源码详细注释
鉴于篇幅,transport模块的详细源码实现过程将在《MongoDB内核源码实现及调优系列》相关章节详细分析。
网络传输各个子模块及Asio库源码详细注释详见:
https://github.com/y123456yz/reading-and-annotate-MongoDB-3.6.1/blob/master/README.md
本文MongoDB对应的sysbench代码目录(该工具来自Percona,本文只是简单做了改动):
https://github.com/y123456yz/reading-and-annotate-MongoDB-3.6.1/tree/master/mongo/sysbench-MongoDB
Sysbench-MongoDB对应的lua脚本目录:
https://github.com/y123456yz/reading-and-annotate-MongoDB-3.6.1/tree/master/mongo/sysbench-MongoDB/sysbench/tests/MongoDB
关于作者
杨亚洲:前滴滴出行技术专家,现任OPPO数据库团队负责人,一直专注于分布式缓存、高性能服务器、数据库、中间件等相关研发。后续会持续分享《MongoDB内核源码设计及性能调优实践》。
☆ END ☆
更多技术干货
扫码关注
OPPO互联网技术
以上是关于MongoDB网络传输处理源码实现及性能调优——体验内核性能极致设计的主要内容,如果未能解决你的问题,请参考以下文章