技能篇:linux服务性能问题排查及jvm调优思路
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了技能篇:linux服务性能问题排查及jvm调优思路相关的知识,希望对你有一定的参考价值。
参考技术A vmstat 和 pidstat。vmvmstat 可查看系统总体的指标,pidstat则详细到每一个进程服务的指标Swap 其实就是把一块磁盘空间或者一个本地文件,当成内存来使用。swap 换出,把进程暂时不用的内存数据存储到磁盘中,并释放这些数据占用的内存。swap 换入,在进程再次访问这些内存的时候,把它们从磁盘读到内存中来
当一个网络帧到达网卡后,网卡会通过 DMA 方式,把这个网络包放到收包队列中;然后通过硬中断,告诉中断处理程序已经收到了网络包。接着,网卡中断处理程序会为网络帧分配内核数据结构(sk_buff),并将其拷贝到 sk_buff 缓冲区中;然后再通过软中断,通知内核收到了新的网络帧。内核协议栈从缓冲区中取出网络帧,并通过网络协议栈,从下到上逐层处理这个网络帧
JVM性能调优实践——JVM篇
前言
在遇到实际性能问题时,除了关注系统性能指标。还要结合应用程序的系统的日志、堆栈信息、GClog、threaddump等数据进行问题分析和定位。关于性能指标分析可以参考前一篇JVM性能调优实践——性能指标分析。
JVM的调优和故障处理可以使用JDK的几个常用命令工具。因为本文是基于Docker容器内部的Springboot服务。需要调整一下docker容器的启动参数,才可以使用jmap等工具。jmap命令需要使用Linux的Capability的PTRACE_ATTACH权限。而Docker自1.10在默认的seccomp配置文件中禁用了PTRACE_ATTACH。目前使用的Docker version是17.04.0-ce。支持的Capability列表可以详看runtime-privilege-and-linux-capabilities。
调整Capability的方式也比较方便。可以如下直接在运行参数后面加 cap_add,cap-drop
$docker run --cap-add=ALL --cap-drop=MKNOD ...也可以在compose中增加:
cap_add:
- ALL
cap_drop:
- NET_ADMIN
- SYS_ADMINDocker容器中的服务进程
在排查问题时,一般是先通过JVM性能调优实践——性能指标分析中的几个命令来分析基础的服务器状态和信息。在微服务架构中,每台服务器部署着若干运行着服务的容器。在不能通过应用日志或者问题现象定位问题服务时,需要找到问题容器。
先通过TOP命令找到耗费关键资源的进程。
top - 11:45:13 up 318 days, 20:43, 2 users, load average: 0.15, 0.19, 0.18
Tasks: 172 total, 1 running, 171 sleeping, 0 stopped, 0 zombie
%Cpu(s): 3.1 us, 1.9 sy, 0.0 ni, 94.7 id, 0.0 wa, 0.0 hi, 0.3 si, 0.0 st
KiB Mem: 8175392 total, 7868636 used, 306756 free, 204400 buffers
KiB Swap: 0 total, 0 used, 0 free. 849564 cached Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
31399 root 20 0 3585612 806804 12228 S 3.0 9.9 548:20.94 java
6331 root 20 0 3445612 925660 15784 S 2.7 11.3 41:40.29 java
31122 root 20 0 3460712 888776 11568 S 2.0 10.9 484:19.31 java
31147 root 20 0 3288180 811476 12748 S 1.3 9.9 263:44.73 java
8506 root 20 0 3254088 750880 6116 S 1.0 9.2 760:45.19 java
22940 root 20 0 1029012 70584 23396 S 0.7 0.9 0:10.68 node
24550 root 20 0 1229088 43096 8712 S 0.7 0.5 160:15.74 node
7 root 20 0 0 0 0 S 0.3 0.0 606:49.74 rcu_sched
454 sshd 20 0 32792 1924 188 S 0.3 0.0 29:15.40 nginx
13721 root 20 0 25396 1956 1324 S 0.3 0.0 56:29.17 AliYunDunUpdate
16225 root 20 0 3072752 429296 6848 S 0.3 5.3 42:51.01 java
20795 root 20 0 2408848 75344 3960 S 0.3 0.9 2361:22 java
23581 root 20 0 16736 2676 2196 R 0.3 0.0 0:00.01 top
31352 root 20 0 206920 1488 1024 S 0.3 0.0 1:20.48 docker-containe
32000 root 20 0 3061760 403708 6548 S 0.3 4.9 127:01.39 java
... 省略其他信息因为Docker容器中还有java进程,所以需要找到具体的父子进程id.用ps -ef命令如下所示。第二列是PID(进程ID),第三列是PPID(父进程ID)。
$ps -ef |grep java
root 6310 6293 0 May21 ? 00:00:00 /bin/sh -c java -Dcontainer.host.ip=...
root 6331 6310 2 May21 ? 00:41:51 java -Dcontainer.host.ip= -server ...
root 8482 8465 0 Apr16 ? 00:00:00 /bin/sh -c java -Dcontainer.host.ip...
root 8506 8482 1 Apr16 ? 12:40:53 java -Dcontainer.host.ip= -server...
... 省略其他信息可以使用docker inspect查看容器内部信息,找到对应的容器实例的进程信息。如下即可打印当前宿主机的所有运行的容器实例的PID,为了方便映射,可以打印对应容器名字,或者容器ID:
## 打印容器pid和容器id
$docker ps -q | xargs docker inspect --format ‘{{.State.Pid}}, {{.ID}}‘ | grep "^${PID}"
## 打印容器pid和容器name
$ docker ps -q | xargs docker inspect --format ‘{{.State.Pid}}, {{.Name}}‘ | grep "^${PID}"
6310, /service-item
31369, /gateway-api
31094, /service-resource
31025, /service-trade
30916, /service-user
16204, /service-analytics
8482, /service-financial
... 省略其他信息
如果要分析最消耗内存的进程,对应的pid= 6331,其所在的docker进程id也即父进程id= 6310,可以定位出service-item服务最消耗内存资源。定位到服务之后,即可使用docker exec -it service-item ‘/bin/sh’查看容器内部信息。
JVM调优基础命令
在容器内部,就可以进一步使用jdk提供的jps、jstack、jstat、jmap等工具来进行jvm问题排查和调优。
jps[options] [hostid]
jps主要用来输出JVM中运行的进程状态信息。
- -q 输出类名、Jar名和传入main方法的参数
- -m 输出传入main方法的参数
- -l 输出main类或Jar的全限名
- -v 输出传入JVM的参数
如下查看运行的java进程信息,打印jar名以及运行main方法传入的参数:
/opt/app # jps -l -m
6 /opt/app/app.jar --server.port=8080
327 sun.tools.jps.Jps -l -m
jstat
jstat -<option> [-t] [-h<lines>] <vmid> [<interval> [<count>] jstat命令可以用于持续观察虚拟机内存中各个分区的使用率以及GC的统计数据。vmid是Java虚拟机ID,在Linux/Unix系统取进程ID。
如下面输出的信息,采样时间间隔为1000ms,采样5次:
/opt/app # jstat -gc 6 1000 5
S0C S1C S0U S1U EC EU OC OU MC MU CCSC CCSU YGC YGCT FGC FGCT GCT
1536.0 1536.0 1233.7 0.0 171520.0 169769.2 249344.0 57018.6 93912.0 91906.8 11264.0 10853.7 6224 47.439 5 3.423 50.863
1536.0 1536.0 1233.7 0.0 171520.0 169805.4 249344.0 57018.6 93912.0 91906.8 11264.0 10853.7 6224 47.439 5 3.423 50.863
1536.0 1536.0 0.0 1536.0 171520.0 3527.9 249344.0 60347.4 96728.0 94808.1 11520.0 11174.7 6225 47.453 5 3.423 50.876
1536.0 1536.0 0.0 1536.0 171520.0 4742.1 249344.0 60347.4 96728.0 94808.1 11520.0 11174.7 6225 47.453 5 3.423 50.876
1536.0 1536.0 0.0 1536.0 171520.0 7589.3 249344.0 60347.4 96728.0 94808.1 11520.0 11174.7 6225 47.453 5 3.423 50.876
上述各个列的含义:
- S0C、S1C、S0U、S1U:young代的Survivor 0/1区容量(Capacity)和使用量(Used)。0是FromSurvivor,1是ToSurvivor。
- EC、EU:Eden区容量和使用量
- OC、OU:年老代容量和使用量
- MC、MU:元数据区(Metaspace)已经committed的内存空间和使用量
- CCSC、CCSU:压缩Class(Compressed class space)committed的内存空间和使用量。
- YGC、YGT:young代GC次数和GC耗时
- FGC、FGCT:Full GC次数和Full GC耗时
- GCT:GC总耗时
可以通过分区占用量上看到,在第2-3秒之间发生了一次YGC。YGC次数+1,并且Survivor from区的内存空间从1233.7->0,Survivor from从0->1536。Eden区也释放了很多内存空间。其他变化的空间占用也有元数据区以及元数据区的压缩Class区。Compressed class space也是元数据区的一部分,默认是1G,也可以关闭。具体的jvm8内存分布不再详述。下一篇GC优化会再展开整理下。
如果只看gc的总统计信息,也可以用jstat -gcutil vmid查询:
/opt/app # jstat -gcutil 6
S0 S1 E O M CCS YGC YGCT FGC FGCT GCT
0.00 100.00 73.76 24.20 98.02 97.00 6225 47.453 5 3.423 50.876 - 1
- 2
- 3
jmap [option] pid
jmap可以用来查看堆内存的使用详情。内存各个分区可以通过jmap -heap pid来查看。得到的输出如下:
$jmap -heap 6
Attaching to process ID 6, please wait...
Debugger attached successfully.
Server compiler detected.
JVM version is 25.121-b13
using thread-local object allocation.
Parallel GC with 2 thread(s)
Heap Configuration:
MinHeapFreeRatio = 0
MaxHeapFreeRatio = 100
MaxHeapSize = 536870912 (512.0MB)
NewSize = 44564480 (42.5MB)
MaxNewSize = 178782208 (170.5MB)
OldSize = 89653248 (85.5MB)
NewRatio = 2
SurvivorRatio = 8
MetaspaceSize = 21807104 (20.796875MB)
CompressedClassSpaceSize = 1073741824 (1024.0MB)
MaxMetaspaceSize = 17592186044415 MB
G1HeapRegionSize = 0 (0.0MB)
Heap Usage:
PS Young Generation
Eden Space:
capacity = 170393600 (162.5MB)
used = 99020080 (94.43290710449219MB)
free = 71373520 (68.06709289550781MB)
58.11255821814904% used
From Space:
capacity = 4194304 (4.0MB)
used = 786432 (0.75MB)
free = 3407872 (3.25MB)
18.75% used
To Space:
capacity = 4194304 (4.0MB)
used = 0 (0.0MB)
free = 4194304 (4.0MB)
0.0% used
PS Old Generation
capacity = 255328256 (243.5MB)
used = 65264912 (62.24147033691406MB)
free = 190063344 (181.25852966308594MB)
25.561178783126927% used
39531 interned Strings occupying 4599760 bytes.Heap Configuration是堆内存的配置信息。可以通过运行参数改变。一般通过分析内存分布和使用情况以及GC信息,可以针对不同的应用不断调整到合适的堆内存分区配置。
Heap Usage可以看堆内存实时的占用情况。
使用jmap -histo[:live] pid查看堆内存中的对象的数目,占用内存(单位是byte),如果带上live则只统计活对象,如下:
/opt/app/logs # jmap -histo:live 6 | more
num #instances #bytes class name
----------------------------------------------
1: 127610 19132008 [C
2: 6460 4074512 [B
3: 37041 3259608 java.lang.reflect.Method
4: 125182 3004368 java.lang.String
5: 86616 2771712 java.util.concurrent.ConcurrentHashMap$Node
6: 70783 2265056 java.util.HashMap$Node
7: 17686 1967496 java.lang.Class
8: 15834 1448440 [Ljava.util.HashMap$Node;
9: 35360 1414400 java.util.LinkedHashMap$Entry
10: 21948 1231624 [Ljava.lang.Object;
11: 9940 1165728 [I
12: 986 1064480 [Ljava.util.concurrent.ConcurrentHashMap$Node;
13: 18685 1046360 java.util.LinkedHashMap
14: 30351 971232 java.lang.ref.WeakReference
15: 50340 805440 java.lang.Object
16: 13490 539600 java.lang.ref.SoftReference
17: 17705 513768 [Ljava.lang.String;
18: 18781 450744 org.springframework.security.access.method.DelegatingMethodSecurityMetadataSource$DefaultCacheKey
19: 20272 434456 [Ljava.lang.Class;
20: 17270 414480 java.beans.MethodRef
21: 23616 377856 java.lang.Integer
22: 11192 358144 java.util.LinkedList
23: 14911 357864 java.util.ArrayList
24: 5700 319200 java.beans.MethodDescriptor
以上示例的排序是按照占用内存字节数倒序的。class name列中”[C,[B,[I “是代表char,byte,int.”[L+类名”代表其他实例。这种写法跟Class文件的Java的类型表述含义是一致的。
在进行问题排查时,可以使用jmap把进程内存使用情况dump到文件中,或者dump**.hprof**文件,在本地使用MAT(Eclipse Memory Analyzer)进行分析。也可以直接用jhat分析查看。
/opt/app# jmap -dump:format=b,file=heapdump 6
Dumping heap to /opt/app/logs/heapdump ...
Heap dump file created
/opt/app# jmap -dump:live,format=b,file=heapLive.hprof 6 jstack [option] pid
jstack可以用来查看Java进程内的线程堆栈信息。
-l long listings,会打印出额外的锁信息,在发生死锁时可以用jstack -l pid来观察锁持有情况
-m mixed mode,不仅会输出Java堆栈信息,还会输出C/C++堆栈信息(比如Native方法)
输出信息如下:
/opt/app # jstack -l 6
Full thread dump Java HotSpot(TM) 64-Bit Server VM (25.121-b13 mixed mode):
"elasticsearch[Oneg the Prober][listener][T#1]" #221 daemon prio=5 os_prio=0 tid=0x00007fc2a418a800 nid=0x195 waiting on condition [0x00007fc28318d000]
java.lang.Thread.State: WAITING (parking)
at sun.misc.Unsafe.park(Native Method)
- parking to wait for <0x00000000e29f88d0> (a java.util.concurrent.LinkedTransferQueue)
at java.util.concurrent.locks.LockSupport.park(LockSupport.java:175)
at java.util.concurrent.LinkedTransferQueue.awaitMatch(LinkedTransferQueue.java:737)
at java.util.concurrent.LinkedTransferQueue.xfer(LinkedTransferQueue.java:647)
at java.util.concurrent.LinkedTransferQueue.take(LinkedTransferQueue.java:1269)
at java.util.concurrent.ThreadPoolExecutor.getTask(ThreadPoolExecutor.java:1067)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1127)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)
at java.lang.Thread.run(Thread.java:745)
Locked ownable synchronizers:
- None
在线上问题排查线程锁信息时,jstack是个非常好用的工具,结合应用日志可以迅速定位到问题线程。
Java性能分析工具
对于Java性能调优,以前一直比较好用的工具是JRockit,JProfile(商业)等工具,但随着JDK7 up40版本之后,jdk会自带JMC(JavaMissionControl)工具。可以分析本地应用以及连接远程ip使用。提供了实时分析线程、内存,CPU、GC等信息的可视化界面。从jdk8 up40开始,JMC还提供了在运行时创建JFR记录(飞行记录器)。如果是全面分析heap dump,再综合使用MAT(Eclipse Memory Analyzer)。基本就可以做很多日常的性能调优以及线上问题排查了。下文简单介绍一些JMC,基于java version “1.8.0_60”。
Java Mission Control
在Mac上使用的话,需要先找到jdk中的jmc路径。
$find /Library/Java -name missioncontrol
在我本地的目录是/Library/Java/JavaVirtualMachines/jdk1.8.0_60.jdk/Contents/Home/lib/missioncontrol/。打开jmc之后,常用的话可以留在dock下面。
启动需要观察的应用,然后即可在JMC的MBean服务器中观察到综合信息如下:
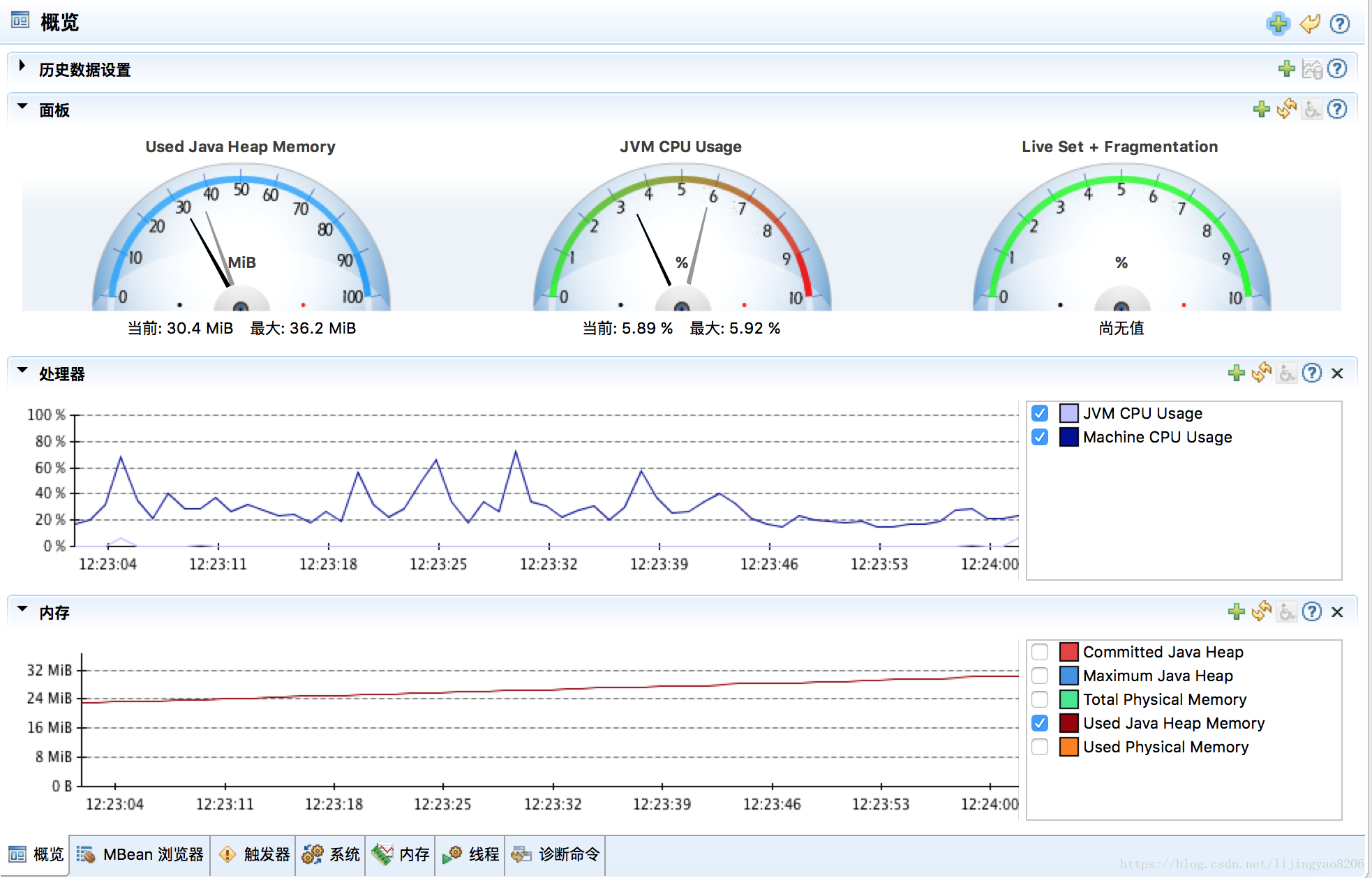
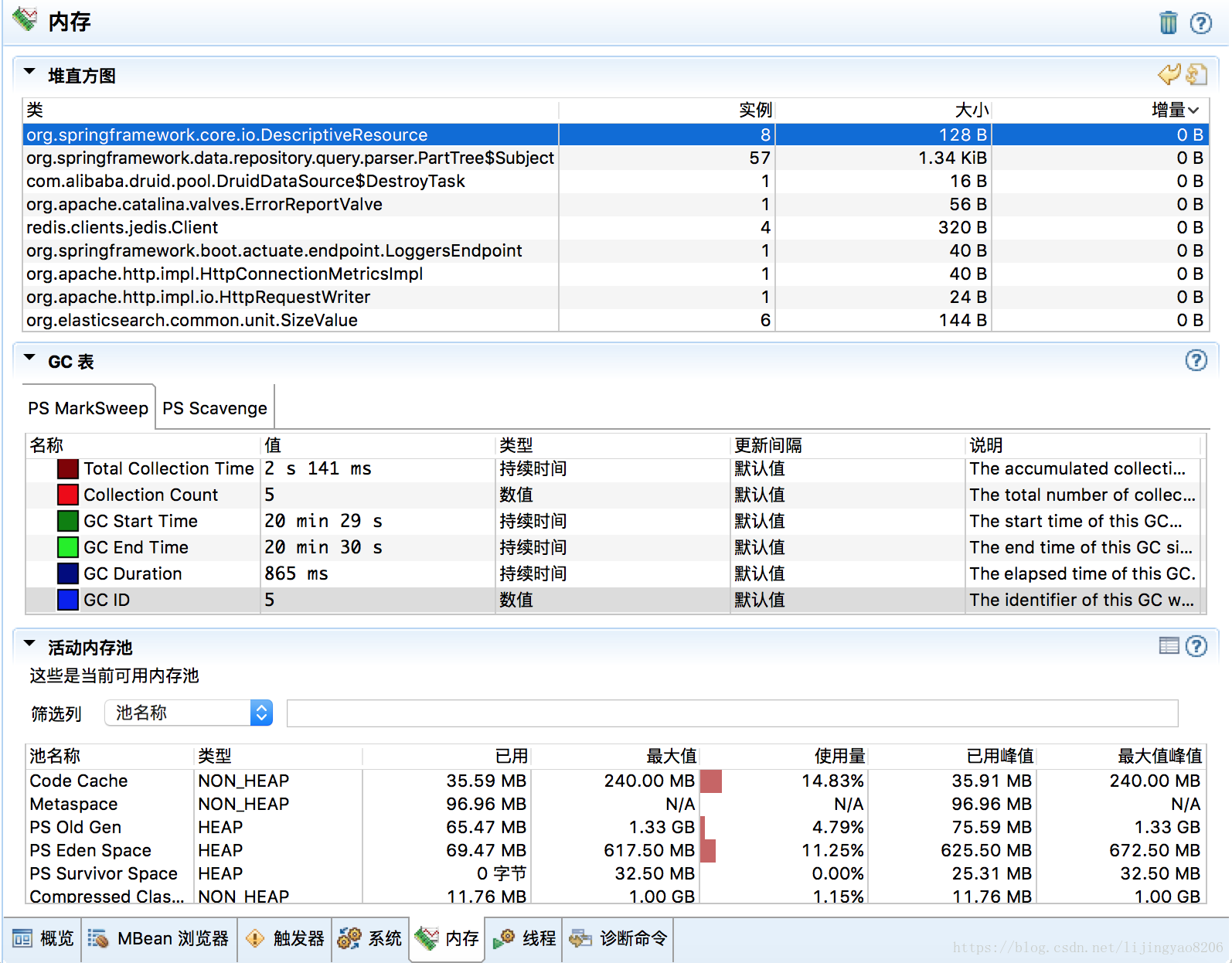
进一步观察内存以及GC的情况,视图如下,可以观察到运行时内存各个分区的占用率。对于“堆直方图”默认是不开启的,可以通过右上角的刷新值来启用,会影响性能。一般用于排查内存中的大对象的回收问题以及OOM问题时可以开启观察。
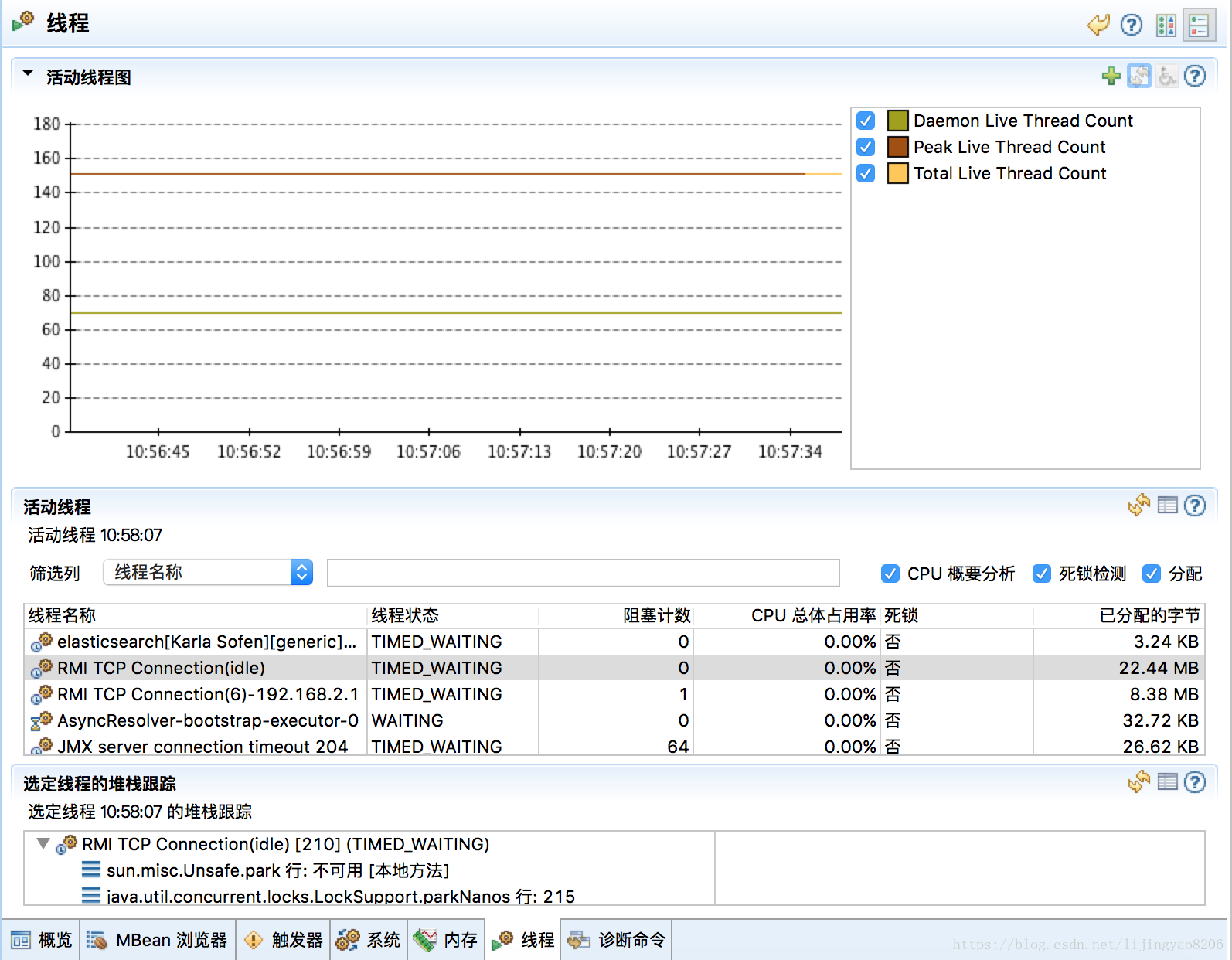
对于线程死锁、线程池资源方面的分析,可以到线程视图中观察活动线程。
Java飞行记录器(Java Flight Recorder)
Java 8 up40开始,可以使用JMC创建JFR记录。JFR可以采样分析收集Java应用程序以及JVM的信息, 它的最小开销小于2%,不会影响其他JVM优化。JFR不会记录所有方法调用,只会探测热点方法,但不包含Native方法的线程采样。如果要开启JFR,需要应用启动参数中添加:
-XX:+UnlockCommertialFeatures -XX:+FlightRecorder 一般还是建议本地调优和分析时使用。JFR可以提供固定时间的采样(默认是1min),以及持续时间的记录。它们都会dump到一个“.jfr”的文件中。
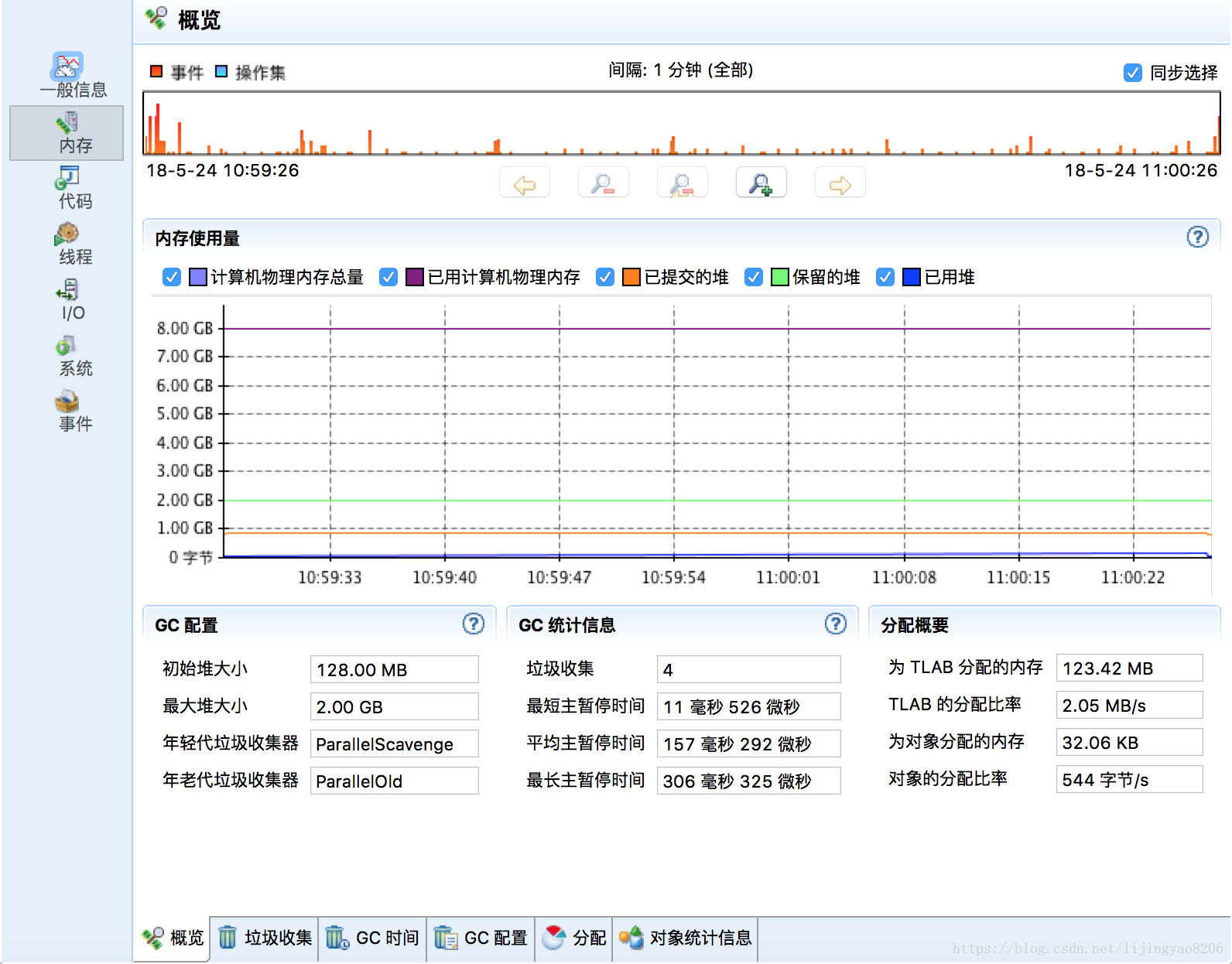
分析内存信息如下,可以看到内存使用量,以及基础的GC配置和统计信息:
详细分析内存情况时,需要进一步查看“内存分配”以及“对象统计信息”。其中“对象统计信息”也是默认不开启的,需要在创建jfr时选择“启用”如下:
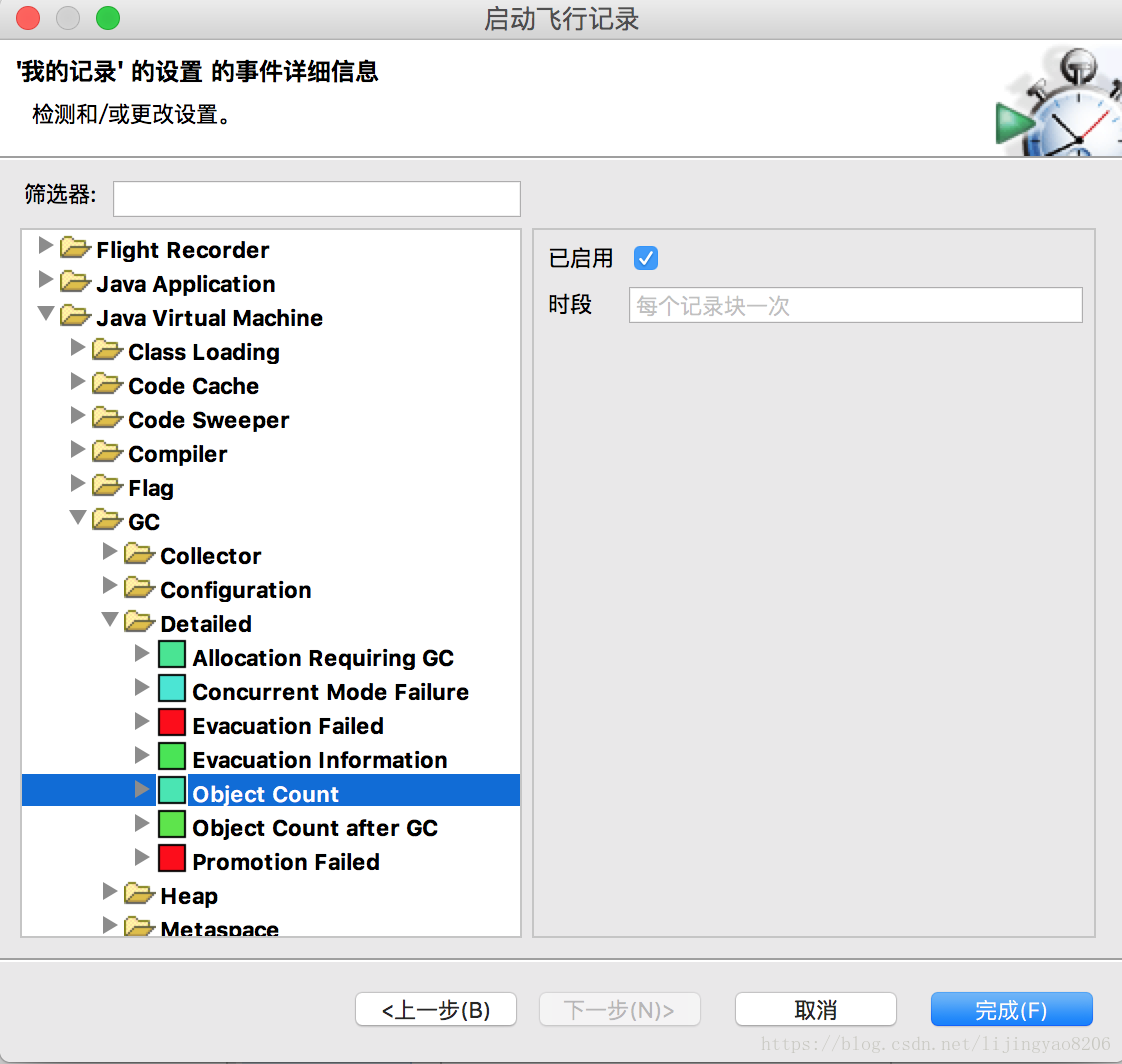
然后即可看到对象统计信息:
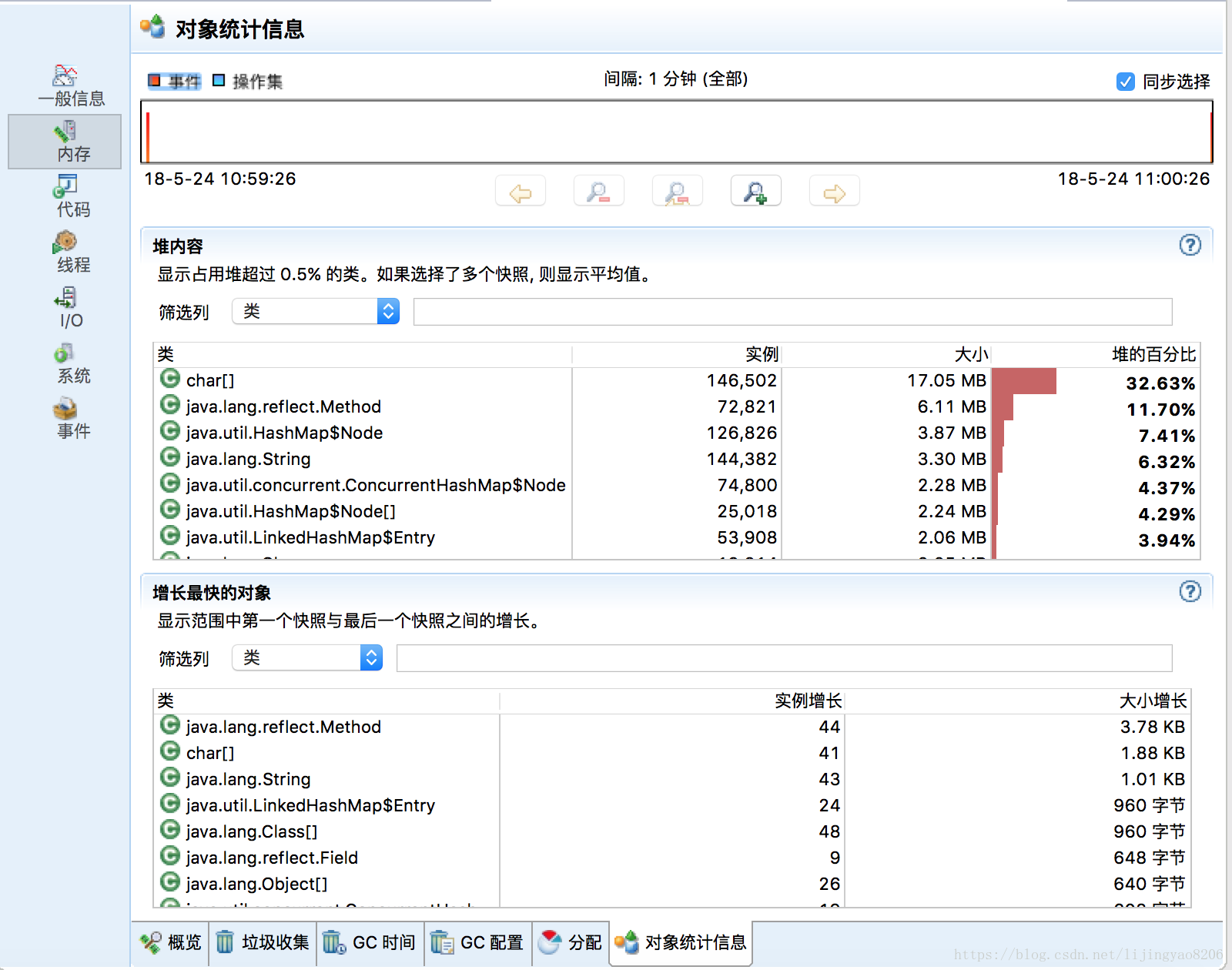
对于热点方法以及热点线程的采样分析图表也很直观,在分析一些循环调用时可以重点关注热点方法,对于有问题的热点方法可以进一步查看“堆栈跟踪”下的调用链:
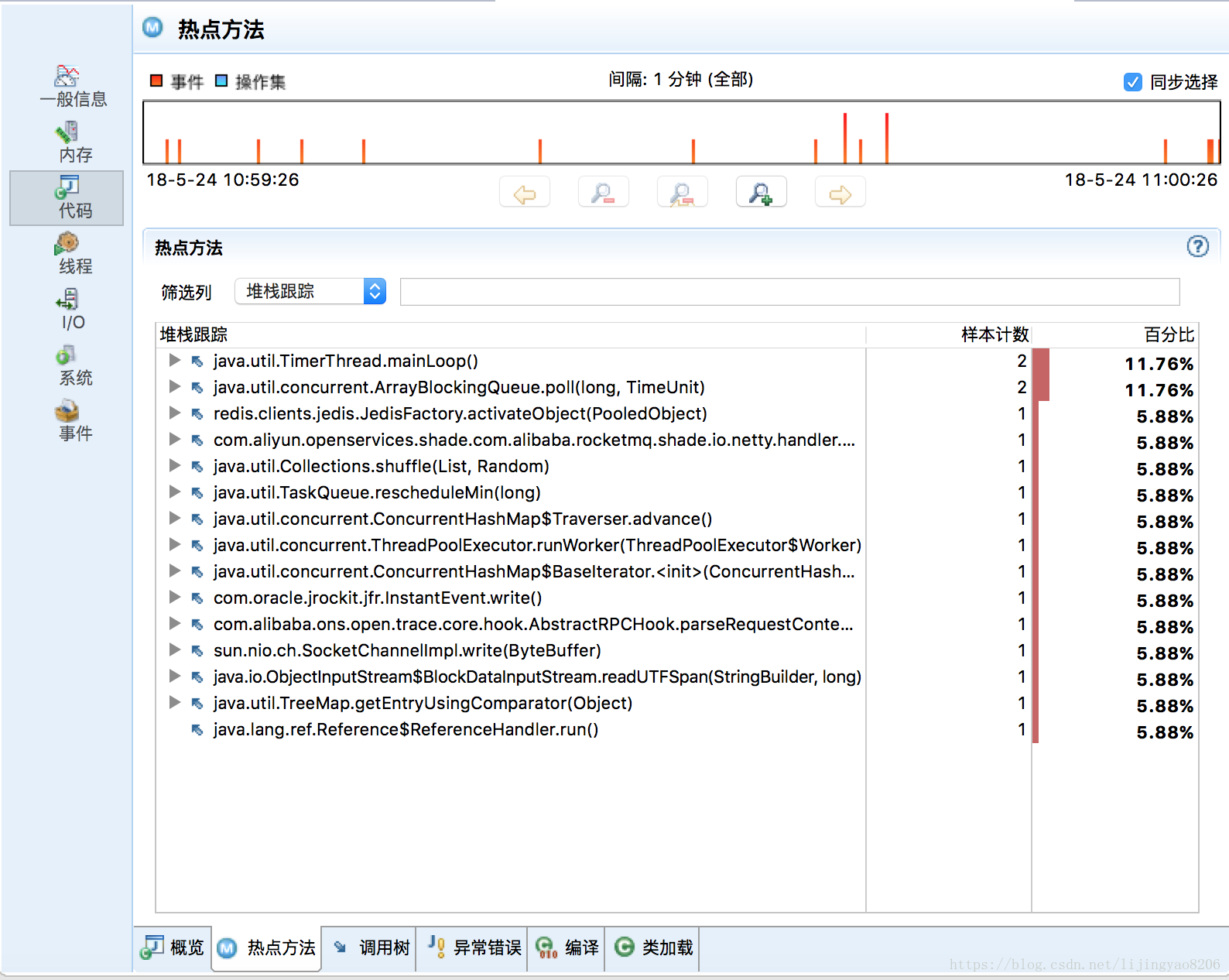
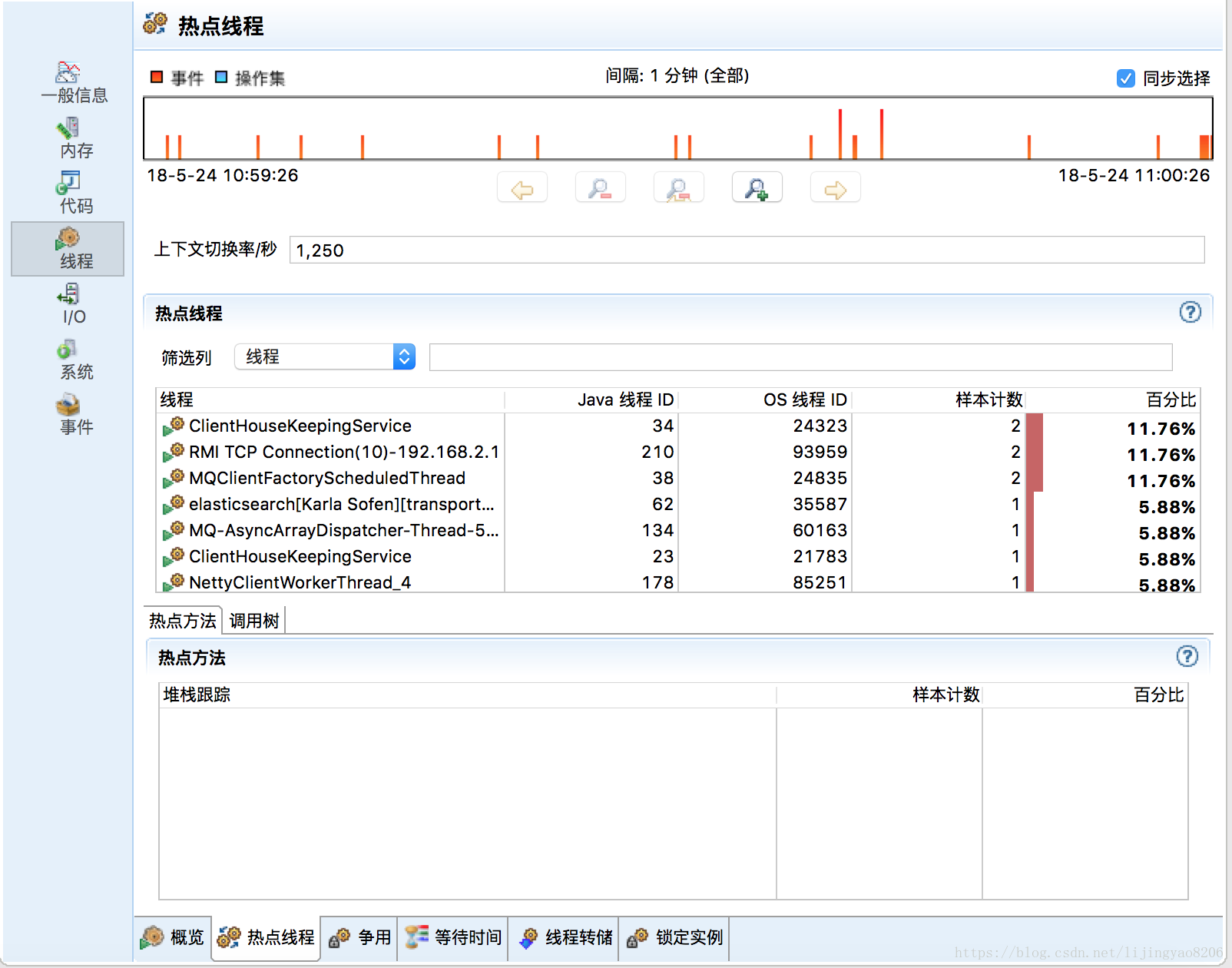
总结
本文主要介绍了java常用的性能优化和排查问题的工具,以及JavaMissionControl工具的一些功能。JMC是官方提供的免费工具,结合MAT,基本可以处理性能优化的80%场景。JMC还可以链接远程ip进行分析。但对于线上问题排查,还是建议使用jstat,jstack,jmap工具等,结合top、vmstat等快速排查和定位问题。
性能排查一般问题都集中在cpu、内存。前者分析线程,后者分析具体出现问题的内存分区。对于磁盘、IO等资源瓶颈需要综合很多业务场景进行具体定位。
还有一部分比较大的话题,就是GC,会在下一篇进行总结和整理。
以上是关于技能篇:linux服务性能问题排查及jvm调优思路的主要内容,如果未能解决你的问题,请参考以下文章